
循环神经网络RNN
一.简介:
1.背景:模型是由数据驱动的,模型是用来处理数据的,最常见的数据形式有:图像和数值,这些可以用CNN或传统的DNN来进行处理,注意:这些网络结构实际是对样本特征进行提取和组合,每层的输出都是独立的,也就是说每层中的特征间都无关系,因为参数不一样,就算最后进行特征组合,也是在空间位置上将这些局部特征组合成全局特征,由于我们人类认知这些样本的角度也是从全局到局部再到全局,所以这些cnn之类的网络结构可以有好的结果,但是对于一种数据,我们人类认知的角度不是全局-局部-全局,就是时序数据,我们对这些时序数据的处理是联系上下文,比如:我打开冰箱,放入大象,关上冰箱。若要预测‘关上’,若是cnn,则会从全局到局部到全局,认为‘冰箱’出现两次,大概率填‘冰箱’或和‘大象’有关的东西,肯定不是‘关上’,因为‘关上’不是它的特征,它也不能提取这些东西,对于这种数据,人类是联系上下文,前面有‘打开冰箱’这个动作,那‘冰箱’的状态是‘开’,那对应到后面,就应该冰箱的状态变为‘关’。即:对于时序模型,cnn是根据全局特征'冰箱'或局部特征‘大象’来进行预测,而rnn是根据上下文环境状态‘打开’来进行预测。
2.时序数据:一组数据表现事物状态的变化,即数据前后有关联,比如:音乐、文本、视频、序列...
3.RNN(Recurrent Neural Network)循环神经网络:
(1)名字由来:‘神经网络’表示这是遵循神经网络结构的:有一个输入层、若干隐藏层和一个输出层,每层有若干神经元,层与层之间有联系;而循环表示其中是有某样东西是重复使用的,即神经元---cell,而常规神经网络中神经元是各不相同的--因为参数不一样;
(2)cell:神经元/单元/元件/细胞,一个有输入和输出的小组件,与常规神经网络中神经元概念类似,不同的是,在RNN中:【1】一个神经元不仅接收输入值,还接收其他的值作为输入,比如状态值--state;【2】一个神经元不仅能得到输出值,还输出新的状态值;【3】同一层的各个神经元的标准输入权重参数U、状态输入参数W、标准输出权重参数V一样(权重共享);【4】每个cell只与一个输入序列直接关联


其中:f和g为激活函数,可以添加偏置b,x和state一般为一个向量
(3)RNN的一层:由一个cell循环组成,上标 (i)表示某一层第i个神经元。注意:单次一层的全部输出为一个样本,即X【x(1),x(2),x(3)...】,而不是单个x(i),而单个的x(i)一般是一个向量,代表一个样本中的某个属性,而若X为序列数据,则表示x(i)和x(j)有关联,所以x(i)的输入是有顺序的,所以我们又将x(i)的输入称为不同时间步的输入,每时间步的状态由前几次的状态和该次的输入共同决定,状态state存储了之前输入的信息,也被成为网络的记忆。

(4)RNN常见模式:RNN的本质是循环使用神经单元,并且常处理的是序列数据,默认神经元之间是有关联的。但是根据输入和输出要求不同,RNN具体分为以下几种模式
【1】1:1单对单:每个cell接收一个输入,输出一个输出,而且这个输出一般是下一个cell的输入,也就是说每次传入的样本对应初始的x
【【例】】唐诗生成:对于每句唐诗,先将其转化为数学形式,每个词对应一个向量,每句唐诗对应一个矩阵,输入唐诗第一个词向量,预测生成下一个词向量,与唐诗标签作损失,再利用这个生成的词向量,将其作为第二个cell的输入,又得到对第三个词的预测,依次下去...唐诗生成实则是对一个个cell进行单个输入并输出单个值,每个cell的输入间无序列关系,每个输出之间有关联,所以可以看作1:1,当然要说它是其他的模式也可以,并无严格规定。
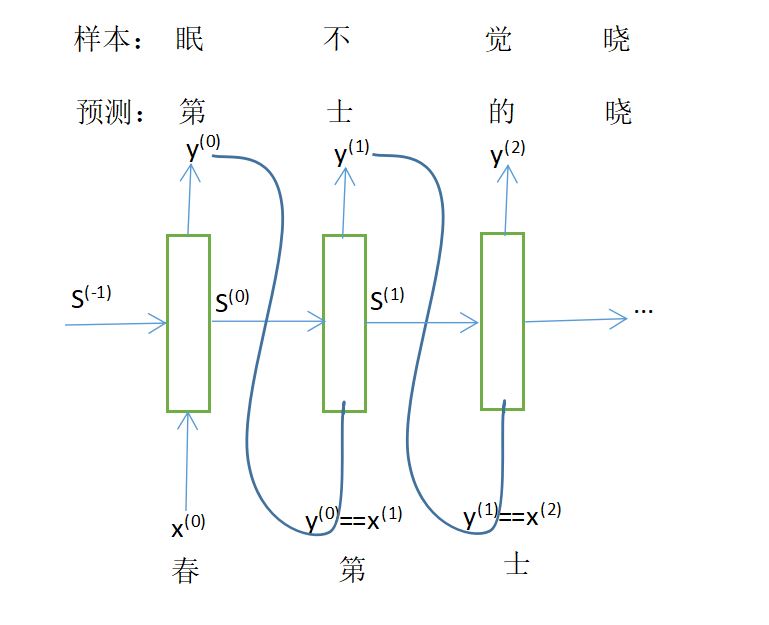
【2】1:n单对多:每层接收一个输入,即一层上所有cell接收同一个输入,输出多个值,常用于生成数据,如:类别/单样本生成序列数据(语言句词、语音)
【【例】】图像生成标题:先将图像提取特征,变成语义向量,再将这个语义向量输入到每个cell中,得到若干值,与样本标签向量作损失
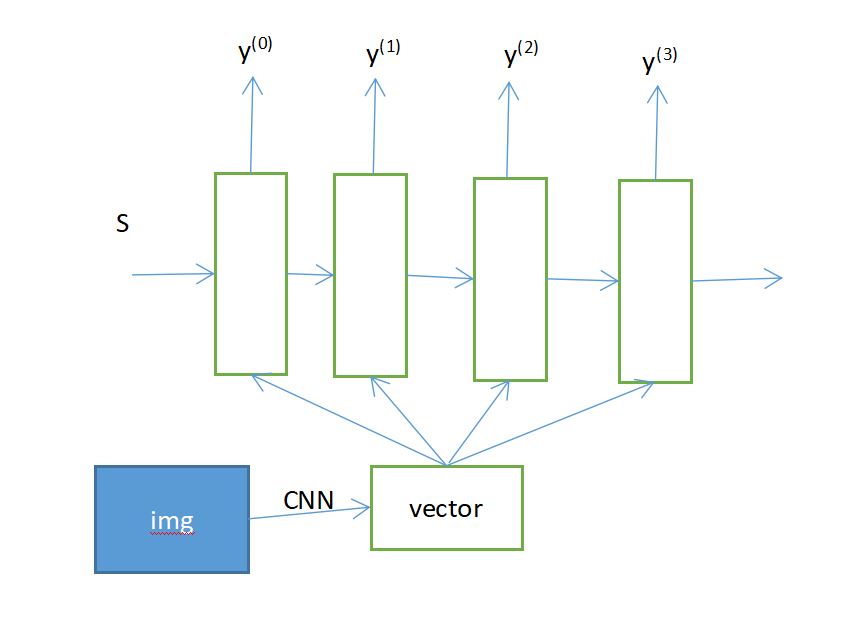
【3】n:1多对单:输入一个序列数据,输出的是单个的值,而不是一组序列值,常用于分类、预测
【【例】】情感分析、股票预测、标题生成图像、文本分类、情感分析、类别判定...
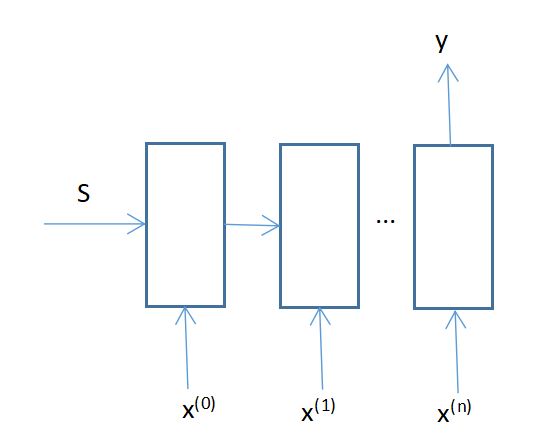
【4】n:n多对多:一组序列数据输出一组同样长度的序列数据,常用于等长序列的变换
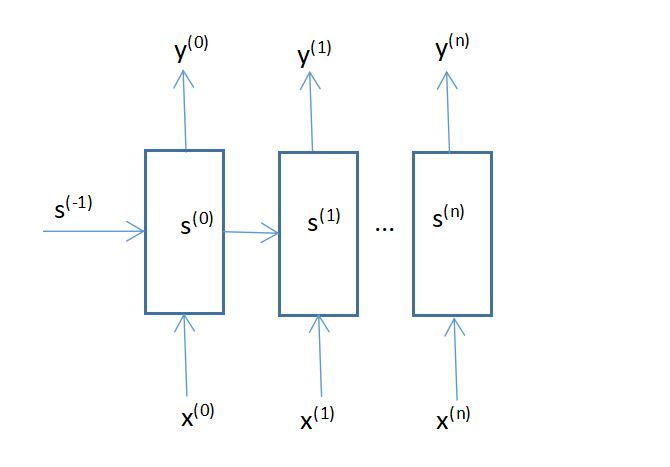
【5】m:n多对多:输入和输出的序列是不同长度的,是不定长的,常用于机器翻译、阅读理解、文本摘要、语言识别

【6】m:n的变体:也就是编码-解码结构、一些变体,比如注意力机制、transformer等
二.原理
1.记忆性:每个cell的计算:每个cell先根据传入的值--前个cell的状态和当前cell的输入值,计算当前的状态值s‘,再根据实际需求判断是否要根据状态计算输出值。其中state表示前面时间步的信息集合,state使得每个cell间有了关联,当前cell的信息包含了前面输入的信息和当前输入的信息,也就是说,网络中的cell有了记忆功能。
2.提取特征:权重共享:
(1)减少参数量
(2)类似CNN,CNN中使用卷积核进行特征提取,增加在不同大小图像上的适用性,RNN中每个时间步都在做同一件事,也就是说,通过权重共享,cell对序列数据进行了特征提取
(3)权重共享可以使模型接收不定长数据
三.模型训练和推理
1.前向计算:计算时,由于要使用到上个cell计算输出的state,所以前向计算是一步一步来的
(1)输入:根据具体问题使用具体的RNN模式,一般若是输入序列数据,会设定最大序列长度l,过长的样本剪切,过段的样本占位补齐,每个序列元素的长度C,样本数N,此时输入为一个三维张量
(2)输出:根据具体问题使用具体的RNN模式,有时输出是一个值--使用softmax,有时是一个向量,再加上N这个维度
2.损失计算:将输出与标签作损失,根据需求使用不同的损失函数,各个输出的损失相加
3.反向更新参数:
(1)计算梯度:由于参数共享的机制,RNN模型损失函数的表达式明显是复合函数,也就是说,计算某个时间步的梯度需要计算当前时间步的梯度,还需要计算之前每个时间步的梯度,即:某个时间步的梯度为之前及此刻所有时刻的梯度之和,而又要计算所有损失的梯度,再对所有时间步的梯度相加
如y = x+x^2+x^3 实际需要计算三次梯度,再将这三次梯度相加,得到最终的梯度
(2)所有时刻结束后更新参数U、W、V
4.推断:输入测试样本,得到输出值
四.重要的点
1.特点:能较好的提取时间序列的特征、网络包含记忆性、权重共享
2.缺陷:
(1)梯度消失:和深层神经网络类似,RNN中也存在连乘偏导,sigmoid函数会加快梯度消失,而tanh比sigmoid好一些,可以用tanh,其次,梯度消失并不直接作用于使得参数无法更新,而是使得参数更新的梯度并不是最优梯度,导致模型不能收敛到最优解,因为计算的梯度是前各个时刻的梯度之和,总归在临近几层,梯度存在,而较远时刻的梯度会消失,导致最终更新的梯度只是部分梯度,也就是,模型最后可能只有短期记忆
(2)梯度爆炸:一样存在,而且由于权重累乘,比bp神经网络更明显,因为RNN权重共享,并不像常规神经网络那样,有几率相互抵消,所以程序会出现数值溢出等情况
(3)RNN设计出来的目的是为了处理时间序列模型,若传入非完全存在时间关联的数据,它的效果有待讨论。
(4)RNN的训练依赖状态的向后传播,神经元之间有直接联系,所以一般难以像传统网络那样并行计算,比如CNN设定的是特征间独立
3.其他注意点
(1)一般用RNN来处理时间序列数据,但并不是表示其他模型不能处理时间序列模型,而且RNN也可以处理非序列模型
五.RNN及其变种
1.RNN:循环使用某个组件cell,权重共享、网络具有记忆性
2.Bidirectional RNN双向RNN:考虑上下文
(1)简述:传统RNN实际上对某个时刻进行输出时,参考的是之前输入的信息,但是可能之后的信息对该时刻有影响,也就是,对某个时刻进行输出时,要联系上下文
(2)对比RNN的改进:在RNN中只有从前往后的state传递,而BiRNN在原隐藏层还设置了一个从后往前的state,这样某个时刻的输出y就依赖于此刻输入+此刻之前的信息state+此刻之后的信息state‘

3.LSTM(Long Short-Term Memory)长短期记忆网络
(1)简述:由于RNN存在梯度消失的问题(梯度传到很远之前的时刻会消失),所以RNN实际上只有短期记忆,所以LSTM希望通过加入对长期记忆的注重来使模型考虑更多的信息,有效减缓梯度消失;改进了简单的cell结构,使用门结构来构建细胞的长期依赖,具体的指构建一个长期state来尽可能存储序列数据的信息,也就是说,本来RNN中存在一个state试图记忆当前时刻之前的所有信息,但是由于梯度消失,这个state只能记忆此刻之前的短期信息,并未达到记忆很远之前信息的效果,因此,引入一个记忆长期信息的state,达到原来想要的效果,也就是LSTM。
(2)对比RNN:引入了长期记忆细胞
https://www.jianshu.com/p/9dc9f41f0b29
【1】遗忘门--长期记忆:决定长期记忆的信息保留多少,使用sigmoid函数,和输入+短期记忆有关
【2】更新门--长期记忆:决定当前时刻哪些信息需要被长期记忆,先将当前+短期的信息使用tanh转为长期记忆信息,使用sigmoid决定这些信息有多少被加入原长期记忆中,得到新的长期记忆,输出
【3】输出门--短期记忆和输出:将更新后的长期记忆使用tanh作变换为短期记忆,再根据当前+短期的信息使用sgmoid决定输出多少短期记忆或输出
(3)激活函数
【1】sigmoid:输出为0~1,常用于信息的保留多少
【2】tanh:输出为-1~1,常用于信息的转换,使对信息的处理,也有缩放数据的意思
4.GRU:
(1)简介:GRU更像是LSTM的改进,将长期和短期两个状态,变成一个状态,同时存储长期和短期状态,通过门结构,减缓了RNN中的梯度消失,所以更简单,而且有效,而LSTM相对来说更加强大
(2)对比LSTM:GRU效果不差,而且模型简单,易于训练,变成了两个门,重置门和更新门都是用来用于控制作用,使用sigmoid函数,将输入和状态进行转换,用门决定是否要更新记忆细胞的信息,决定什么时候更新
【1】重置门:根据重置门,对状态和输入进行处理(保留之前状态多少信息+现有信息),使用tanh,重置了当前时刻的state信息
【2】更新门:根据更新门,对当前时刻state信息和之前时刻传入的state信息相结合,通过更新们的sigmoid值,进行权重相加,输出此刻及之前所有时刻的state信息
六.相关应用
常用于涉及序列相关的数据的任务,如:语音识别、机器翻译等,也可用于常规任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号