
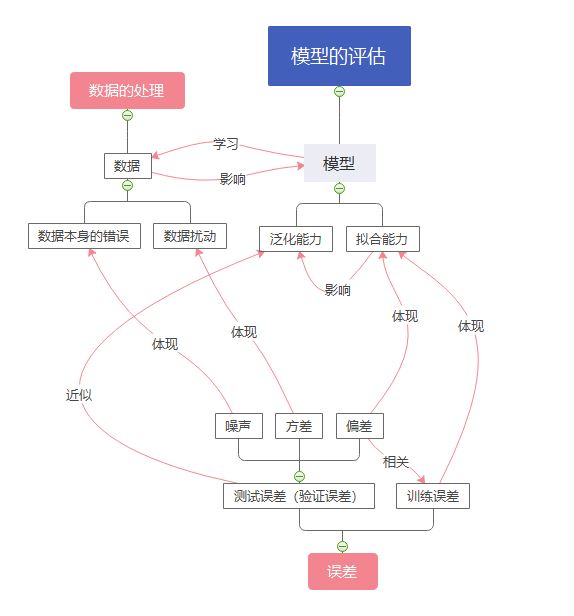
关于模型
模型是对数据的学习,必不可少
一.基本概念
1.模型也被称为学习器(假设/算法),是指能从已有的数据中学习到所需知识的数学模型。
2.相关概念
(1)归纳偏好(inductive bias):机器学习算法在学习过程中对某种类型假设的偏好,比如:存在多个模型能反映训练样本,但是它们对于新的样本却有不同的输出,表示不同模型对不同假设的偏好,也就是说一个数据集能训练出很多不同的模型,取决于训练数据时的假设
(2)奥卡姆剃刀原则(Occam's razor):若有多个假设与观察一致,则选最简单的那个模型
(3)没有免费的午餐’定理(No Free Lunch Theorem)(NFL):在所有问题同等重要的情况下,无论学习算法怎样,他们的期望性能相同,没有一种机器学习算法是适用于所有情况的。也就是说:同一模型在不同问题上的表现不同,同一问题不同模型的表现也不同
3.模型假设和随机性:首先我们的目标是对数据建立合理的数学模型来表现其真实规律,但是我们是不知道真实模型的,因此只能先提出一些假设,通过某些手段(训练数据和评估模型)来验证这些假设,选择其中最好的作为最终真实模型的近似,所以我们一直处理的是‘假的模型’,但是我们的数据是真实的观测值,而模型是对所有数据中某个真实规律的通用表现,假设该真实规律为一个真实值,则观测的数据值就是真实值+误差,而误差又具有随机性,因此我们一般假定训练数据是服从某种分布的随机变量,则真实规律的反映(预测值)也是服从某种分布的一个随机变量,对于模型中的其他变量而言,比如:模型参数的估计值也是服从某种分布的一个随机变量。所以数学模型虽然是看起来固定的表达式,实际上是随机变量的假设。
二.具体问题具体建模
1.模型分类:按照学习的数据分类,
(1)监督学习(supervised learning):数据有标签信息。
【1】分类:标记信息呈现离散状态。KNN、朴素贝叶斯、逻辑回归、随机森林、支持向量机、决策树、神经网络
【2】回归:标记信息呈现的是连续值。线性回归、Adaboost、Gradient Boosting、神经网络
【3】分类问题实际是回归问题:对类别的概率进行回归
(2)无监督学习(unsupervised learning):数据无标记信息,给定一些数据,自动找出数据的结构、规律,关联规则的抽取
【1】聚类:自动对数据进行分类,手动给定类的标记。k-means
(3)半监督学习(Semi-Supervised Learning):是监督学习与无监督学习相结合的一种学习方法。使用大量未标记的数据以及少量标记数据。
2.对问题进行具体分析,进行数据可视化,根据数据特点或者明显规律,建立合适的模型,对模型不断评估和改进,确定最终模型
三.设定模型的评估指标
1.误差:对于某个数据集,模型的实际预测输出与样本的真实输出之间的差异,这个差异可以用数学表达式来表达,即差异可以数字化,因此模型可以进行评估,模型之间可以进行比较
(1)对于回归问题:均方误差、均方根对数误差、误差绝对值、范数等
(2)对于分类问题:
【1】查准率(precision)和查全率(recall):‘检索出的信息有多少比例是用户感兴趣的’(预测对的中实际对的有多少),和‘用户感兴趣的信息有多少被检索出来’(实际对的中预测对的有多少),两者互为矛盾,两者你增我减

【2】P-R曲线:根据样例是正例的可能性进行排序,排在前面的是学习器认为"最可能 “是正例的样本,排在最后的则是学习器认为"最不可能"是正例的样本。若一个学习器的P-R图被另一个学习器p-R图覆盖,则可断言后者性能优于前者
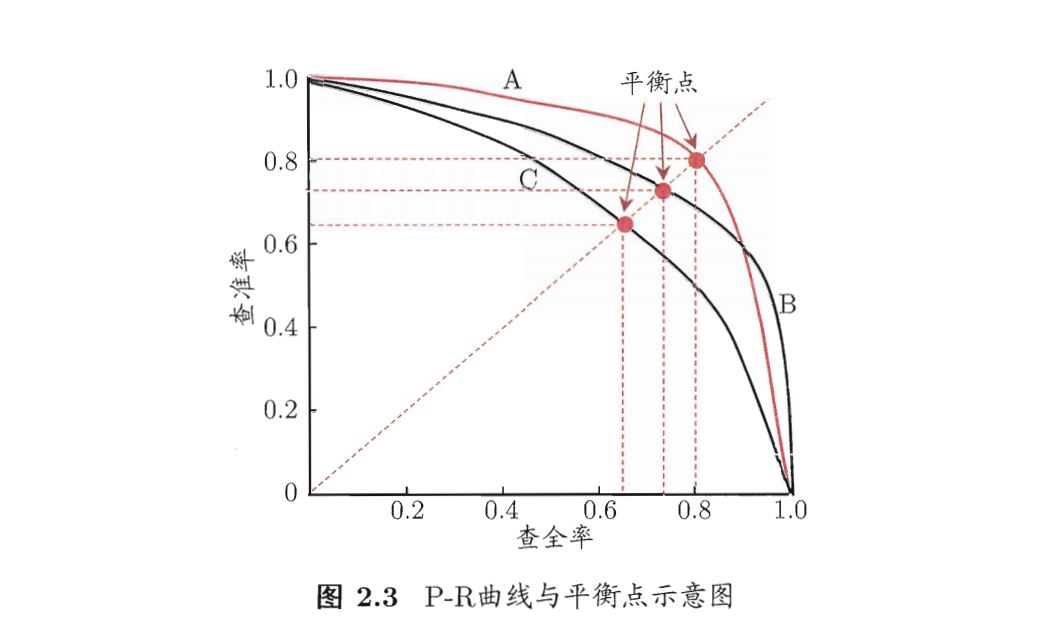
【3】平衡点(BEP)(break-even point):查准率=查全率时的取值,可以作为学习器之间的度量
【4】F1度量:是基于查准率与查全率的调和平均 (harinonic mean)定义的,表达出对查准率/查全率的不同偏好
【5】ROC和AUC:
【【1】】很多时候,我们通过模型只能得到一个预测值,若要对它进行分类,往往是把预测值和设定的某个阈值进行比较,大于的正例,小于的为反例,那么这个预测值其实表达了它属于正例的概率(它属于负例的概率),表明它最可能属于哪一类。
【【2】】我们根据模型的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横(假正例率FPR),纵坐标(真正例率TPR)作图,得到“ROC曲线”。
【【3】】若一个模型的ROC曲线被另一个模型的包住,则代表后者性能更好,若两者有交叉,则比较曲线下的面积(AUC),AUC越大相比较说模型越好。


2.设定合适的单指标:
(1)多指标变为单指标:一般而言,模型的评估指标可以设定很多个,但是在模型选择时,这些指标可能会互相冲突(一个模型在某个指标上表现好,在另一个指标上表现不好),则难以判别两个模型的好坏,因此把多个标准合并为一个标准很有必要,能使模型更清晰明确
【1】满足和优化法-----若要评估n个指标,选择其中一个指标作为优化指标。其余作为满足指标(即约束条件),通过去除不满足条件指标的模型,对剩余的模型在优化指标上进行比较,选出其中最好的。
(2)指标的人类主观性:我们设立的指标根据的是人的主观想法,而且指标有很多种,因此对于某个问题,我们不一定能设立完美的与之相匹配的指标,所以由此得到的所谓的‘好的算法’也有可能在真实情况下表现差,此时需要不断尝试重新设置指标,重新迭代模型
(3)数据集的是否正确性:指标是和数据集、模型联合起来使用的,用来评估算法的性能,然后决策。于是,有时候就算指标设定对了,若数据集不对,真正好的模型的指标表现也会差。
四.模型选择
1.初始建模的选择:由于不同学习算法学得的模型具有不同的特点和偏好,我们可以根据问题、数据可视化、经验来进行建模选择
2.模型的选择标准:
(1)模型表现好:我们的目的是通过已有的数据训练出一个模型,使之能在真实使用的未知数据集上表现良好
(2)泛化误差低:我们设定泛化误差为模型在未知数据集上的误差,则该误差越低,模型表现越好
(3)测试误差低:若保证测试集的独立性(不参与建模过程)与真实性(与我们将使用的真实数据分布一致),则我们把测试误差作为近似的泛化误差,这也是我们能够直接计算得出的结果
3.比较检验:检验模型在测试集上的性能能否代替泛化性能
(1)性能的比较:
【1】我们希望比较的是泛化性能,然而我们只能得到测试误差,两者未必相同
【2】测试集的性能和测试集本身可能有很大关系,而且不同测试集会有不同结果。
【3】机器学习算法具有随机性,这导致测试结果也有随机性。
(2)统计假设检验的意义在于让我们认为在测试集上表现好的模型的泛化性能在统计意义上也表现好,以及这个把握有多大。
(3)假设检验:表面意思---检验假设
【1】首先提出一个假设(对模型泛化错误率分布的判断或猜想)-----------我们是不知道泛化错误率的,但是我们知道测试错误率,而且直观上,两者接近的可能性比较大,两者相差很远的可能性小,因此我们可以根据测试错误率估计推断出泛化错误率的分布。
【【1】】在测试集上计算错误率实际上是一个随机事件(因为测试集具有随机性),则测试错误率实际上是可观测的一个随机变量,每次计算测试错误率都可得到一个观测值,而我们需要得到的是真实错误率,很明显,在多次观测后,靠近真实错误率的测试错误率多,远离真实错误率的测试错误率少,也就是说单次测得的测试错误率有较大的可能接近真实错误率,这也与测试错误率这个随机变量服从正太分布(一般来说,均值可能为真实错误率)的假设是一致。
【【2】】既然测试错误率的概率成正太分布,我们假设模型的泛化错误率,若泛化错误率在正太分布的均值附近,表明我们假设的泛化错误率是正确的,若假设的泛化错误率远离均值,则代表我们假设的泛化错误率有问题,这时候我们会拒绝假设,也就是泛化错误率不会是我们假设的值,但泛化错误率一般是一个值,一次次拒绝一个值还剩的是一个无穷的空间,因此我们一般对泛化错误率的假设为其在某个区间。
【【3】】置信区间:就是根据观测值,真实值大概率所在的区间,相当于真实值和观测均值的误差范围,我们一般设定这个范围占总体范围的概率为95%,也就是说我观测100次测试误差,有95次都靠近真实值。置信区间的计算公式取决于所用到的统计量。
【【4】】显著性水平通常称为α(希腊字母alpha),代表可能犯错的概率,绝大多数情况会将α设为0.05,那么置信度则是0.95或95%。
【【5】】Pr-value:假定值、假设机率。就是一种概率,表示在原假设为真的前提下出现极端情况的概率。根据样本算出来的。就是如果我们的假设成立,那么出现极端情况的概率,若P值小于显著性水平,则代表真实误差是极端的情况,p-value越小,表明结果越显著,说明错误拒绝假设的概率很低,则我们有理由相信假设本身就是错误的,而非检验错误导致则拒绝假设,则我们拒绝假设。
【2】选定统计方法,由样本观察值按相应的公式计算出统计量的大小,如X2值、t值等
【3】根据统计量的大小及其分布确定检验假设成立的可能性P的大小并判断结果

4.模型选择流程:
(1)根据问题选择一些不同的模型进行建模,比如svm、线性模型、决策树等,或不同超参数的相似模型。模型的不同原因在两个方面:一是数学表达式的不同导致模型的不同,二是超参数设置的不同导致模型不同
(2)通过在训练集学习数据,快速迭代得到一些训练好的模型,此时这些模型都已经确定了参数,表明这些模型已经得到第一步优化
(3)在训练集和开发集上对他们进行评估,先去除训练误差大(偏差大)的模型,然后选择开发误差最小(方差小)的模型作为最终选择的模型,对其进行分析和改进,最后在测试集上评估
五.模型训练
1.目的:我们用数据训练模型的目的是使得模型的泛化误差尽量低,而泛化误差受到数据和模型拟合能力的双重影响,数据的影响在于真实性和未知性,难以掌控,而拟合能力通俗地说就是使模型经过各个数据点的能力,我们训练的作用就在于不断增强模型的拟合能力。
2.代价函数和损失函数
(1)两者表示训练集上预测值和真实值的差距,主要表现模型的拟合能力,两者都是模型参数的函数;不同在于:损失函数(loss)是对于单个样本而言,代价函数(cost function)是对于整个数据集而言的所有损失值的平均
(2)通过最小化代价函数来提高模型拟合能力,最小化代价函数实际上是最优化问题,可以用各种优化器求解模型参数
(3)常用损失函数:
【1】分类问题
【【1】】0-1损失函数:预测值和目标值不相等为1,否则为0
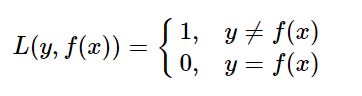
【【2】】对数损失
![]()
【【3】】Hinge损失
![]()
【【4】】交叉熵损失:交叉熵有利于区别两个类别概率的差异,并且能够获取全局最优解。通常结合softmax
![]()
【2】回归问题
【【1】】平方损失函数
![]()
【【2】】绝对值损失函数
![]()
【3】注意:分类问题不用回归问题的MSE是因为它是一个非凸函数,有多个极小值
(5)常用代价函数
【1】均方误差/平方损失/L2 损失:只考虑误差的平均大小,不考虑其方向,如果我们的数据容易出现许多的异常值,则不应使用这个它
![]()
【2】均方根代价函数:能够直观观测预测值与实际值的离散程度
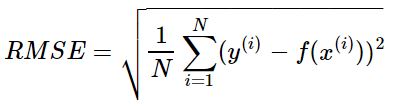
【3】平均绝对误差/L1损失函数:对异常值更加稳健
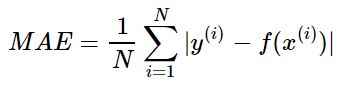
【4】交叉熵代价函数:分类问题的代价函数,实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近
![]()
3.优化器
(1)优化器是在机器学习中用来求解最优化代价函数问题的,本质是最优化问题的求解方法
(2)正规方程法:采用类似求偏导的方法直接求解模型参数
【1】特点:不需要学习率;但需要求矩阵;如果特征很多,速度会很慢
【2】可能出现的问题:求解矩阵时可能有时候要求解逆矩阵,但奇异矩阵是不可逆的矩阵(有多余特征或特征数量大于样例数),这时可以通过删除线性相关的特征或正则化的方法使之可逆,但效率低大
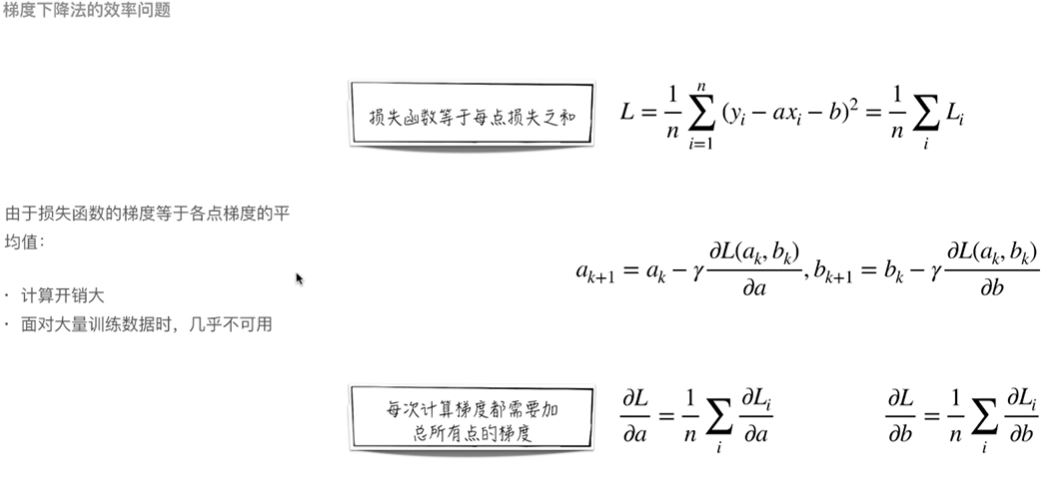
(3)梯度下降法(GD):给定函数参数的初值,让其不断延参数变化幅度最快的方向(梯度)变动,从而不断更新参数,由于梯度变化幅度是由快到缓,因此为梯度下降法
【1】梯度:一个矢量(有方向的偏导),表示函数在点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向变化最快,变化率最大。
【2】代价函数的最优化问题一般是最小化,目标是求最小值点,若该函数为凸函数,则一定有最小值,若函数为非凸函数,则求解到的可能是极小值
【3】梯度下降法有一个关键超参数------学习率(步长)
【【1】】学习率:指参数每次变动的大小;(梯度指参数每次变动的方向)
【【2】】学习率设定应适中:若过大,则代价可能随迭代次数而上升(冲过极小值点)或上升下降循环,不会收敛,不会下降,而且梯度下降依赖泰勒展开,这是在局部成立的,所以不能过大;若过小,则收敛需要的步数变多,收敛速度变慢
【4】若在极小值点的临近范围是一个凸函数,极小值点梯度为0,在其左边,点的梯度大于0,在其右边,点的梯度小于0,而且根据泰勒展开式(函数某一点的值和他附近的值之间的关系),梯度非0的每个点都可以在它的附近找到一个更小值点,因此参数可以从初值开始,延梯度方向搜索更小值点,参数的迭代公式(p'=p-r*f' 其中p为前参数,p‘为更新后的参数,r为学习率>0,f’为p的梯度)用减号(-),
【5】迭代停止的判断条件:1)达到一定的迭代次数;2)设定一个迭代的收敛阈值(不可取)
【6】注意:
【【1】】一般来说,如果代价随着迭代次数的增长而减小并收敛,则表示梯度下降成功
【【2】】不同初值下降的结果可能不同
【【3】】若有多个参数,则要同时更新才是梯度下降(非同步更新-----交叉,新的值放到旧的更新中),而且计算梯度时,若函数不可微,则无法计算偏导
【【4】】要考虑不同特征值取值范围大小的影响,特征缩放可使梯度下降的速度变快(迭代次数变少):使不同特征的取值范围尽可能相近。采用方法:缩放特征范围(加减乘除)或均值归一化(特征值/(特征最大值-特征最小值)):把特征变成具有均值0的特征,(x=(x-u)/s,x是特征,u是特征的平均值,s是特征值范围或标准差),若两个特征取值相差较大,则下降可能会来回地波动折线下降,这会导致下降的时间变得很长,
【【5】】若有鞍点(不是极小值,也不适合最小值,梯度为0 ),梯度下降法会在这点失效,模型参数不会进行更改,模型停止迭代,返回值
【【6】】若有山谷(在一个狭长的区域内梯度几乎等于0,但两边的梯度绝对值很大,相当于学习速率过大),则参数会来回震荡
【【7】】损失函数对于某个参数的偏导为该参数下降最快的方向,又因为代价函数是所有样本点的损失的和,所以对于某个参数的偏导,其实是每个样本点对于该参数的偏导,求和,然后取平均
【7】分类和区别
【【1】】标准梯度下降(Gradient Descent):由于最优化代价函数是所有样本的损失之和,所以计算一个梯度时实际要计算各个样本点的损失函数的梯度再把它们加起来平均,
【【【1】】】优点:不需要求解逆矩阵,对于凸函数,可以求解到最优值,有严格的理论证明,能够求解最优化问题(就算模型很复杂)
【【【2】】】缺点:可能达到局部最优点或鞍点,数据多时计算开销大,学习率的影响大,速度慢,选择合适的学习率是一个挑战(不能太大太小)
【【2】】随机梯度下降法(Stochastic Gradient Descent):每次计算梯度时,随机地选择一个样本点进行梯度的计算
【【【1】】】优点:每次更新的计算量变小,速度快
【【【2】】】缺点:每次迭代的方向不一定正确,参数更新具有高方差,从而导致损失函数剧烈波动,下降不稳定,需要的迭代次数多,永远不会收敛到最小值,在最小值附近波动
【【3】】批量梯度下降法(Batch Gradient Descent):每次选择一定数量的样本点进行梯度计算,取平均值作为下降的梯度,由于每次样本不同但是分布相似,所以下降的总体趋势向下,但不是每次都向下,平均了SGD和GD的优点和缺点。关于batch-size的选择:考虑到电脑内存设置和使用方式,设置2次方比较快速(64,128,256,512 )
【8】优化策略:每轮训练打乱样本顺序、bn、早期停止、正则化


(4)动量方法(momentum)(变化梯度为梯度的均值估计):本次变化考虑历史变化,(上一次迭代的改变量视为速度,此次迭代的梯度视为加速度,),梯度保持相同方向的维度的动量不停地增加,梯度方向不停变化的维度的动量不停地减少,因此可以得到更快的收敛速度并减少振荡。
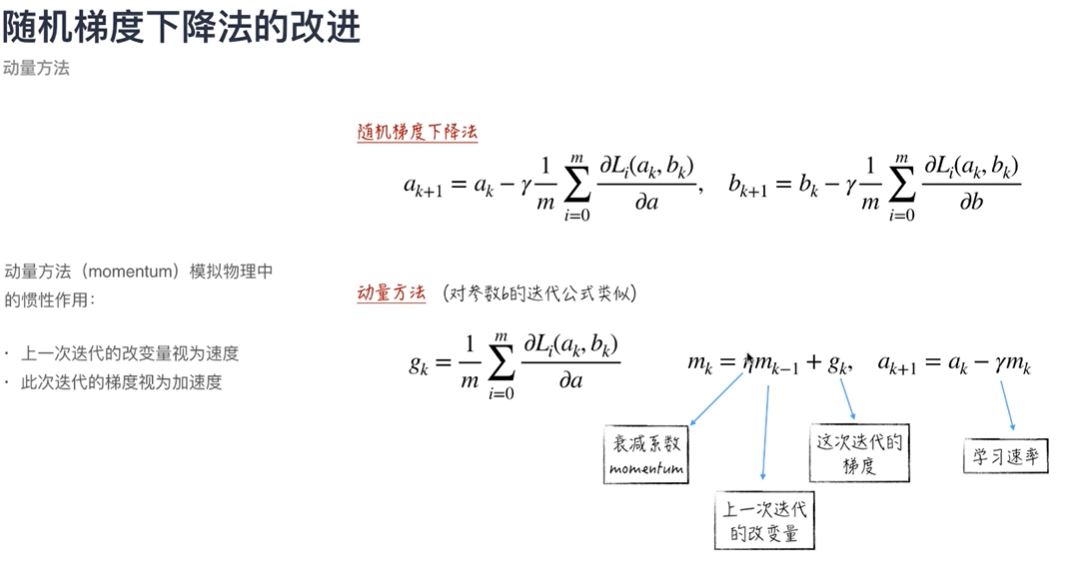
【1】解释:本来参数的改变为原参数减去步长乘以梯度,现在这个变动浮动变为步长乘以梯度+一个值,这个值引入了动量(0-1间),乘以上次的变动幅度,也就是说,上次转60度走20米(v(t-1)),本次本应该转90度走30米(学习率*梯度),但是引入动量变量(γ),是两者间进行一个平衡,这次可能走75度25米(vt),这实质上是考虑了历史梯度,就是说这次的变化应和上次有关,动量系数表示有多少关联。其次,相比于GD,当当前梯度为0时,变化率为0,GD停止,而若是动量方法,此时变化量受到之前变化的影响和当前梯度的影响,也就是变化率不为0,避免了鞍点的陷阱,相当于惯性。
【2】优点:减少了梯度下降的变化幅度,平均中和了纵轴方向的梯度,横向趋于最优解的速度加快,既减少震荡,又大方向不变(本次梯度下降方向),从而保证了效率和正确的收敛,避免了鞍点的陷阱
【3】缺点:梯度下降的那些缺点
【4】补充:指数衰减移动加权平均:加权(给不同观测值添加权重)、移动平均(用最近的数据来预测未来的变化趋势),指数衰减(一个观测值的加权系数随时间或迭代次数呈指数式递减,越靠近当前时刻的数值加权系数就越大),用at=β*a(t-1)+(1-β)vt,vt表示当前观测值,at表示在t之前的观测移动加权均值,β为参数,表示之前的均值的影响权重,可知:随着时间或迭代次数的影响,每个观测值的权重呈指数式递减,与靠近当前时间点,权重越大。β越大,at的值更大地取决于前面的a(t-1),它的权重的衰减越缓慢,达到同一权重需要的迭代次数更多。偏差修正:初始时,权重相差较大,导致真实平均值和我们用指数加权计算的平均值相差很大,此时不能很好估计均值,所以用at/(1-β^t)代替at,当t小 时,此时进行偏差修正,把整个权重和降低了(不是1),当t很大时,偏差修正和原来无差别。
(5)AdaGrad:增加了一个学习率递减系数,这个递减系数由之前所有更新的反向梯度的平方的和来决定。即学习率都要除以历史梯度总和的平方根,因此分母增大,所以实际上AdaGrad的学习率始终是在减小。
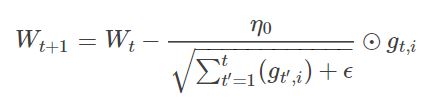
【1】优点:不需要人为的调节学习率,它可以自动调节,梯度大时学习率大,梯度小时学习率小,适用于数据稀疏或者分布不平衡的数据集
【2】缺点:梯度一直变小,相当于最后会导致梯度消失,导致在到达全局最优前算法就停止了,降速太快而且没有办法收敛到全局最优
(6)RMSProp(Root Mean Square Prop)(梯度平方的滑动平均开根--均方根):修改了AdaGrad的梯度积累为指数加权的移动平均,即计算了梯度平方的估计,使得其在非凸设定下效果更好,学习率除以前t次的梯度平方的均值的平方根。其次,相比于动量方法震荡幅度大到小,该方法震荡幅度不会太大,因为计算了均方根,纵轴上的更新要被一个较大的数相除,消除了摆动幅度大的方向,变动变小,而水平方向的更新则被较小的数相除,变动相对来说更大。关于震荡幅度变小,从数学角度,原梯度除以一个同样数量级的数(梯度平方的均值开根号)(可以证明:y= a/sqrt(a**2+z)的关于a的导数的绝对值小于等于1),可知现在的变化率比原来梯度的变化率小。
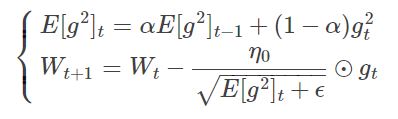
【1】优点:避免了学习率越来越低的的问题,而且能自适应地调节学习率,常用于序列问题,文本分类,序列分类
(7)Adam:集合了Momentum优化(梯度均值估计)和RmsProp的想法(梯度均方根估计),对于历史梯度较小的模型参数,放大当前的更新步伐,反之则变小,对于改变慢的,放大步伐。学习率建议为0.001,对超参数鲁棒,与RMSprop相比,增加了偏差校正和动量(由于移动指数平均在迭代开始的初期会导致和开始的值有较大的差异)

(8)比较总结:无脑Adam,偶尔RMSProp,其他能不用尽量不用
【1】Adam 一般是最好的选择
【2】RMSprop:处理非平稳目标时的rnn

4.模型训练的一般流程:对于一个模型来说,确定超参数和数学公式后,初始化模型参数,设置代价函数和优化器,把数据代入模型,计算代价函数,根据优化方法更新模型参数,不断重复迭代,得到最终的较好的模型参数,以此确定最终训练完的模型。对于许多训练完的模型,评估他们的效果,选择其中最好的作为最终备选模型
六.模型分析
1.数学模型的组成
(1)特征(因变量):数据的属性,随机变量
【1】模型幻觉:不相关的特征被加入模型里,且被认为与预测结果有相关性。解决:加入惩罚项削弱模型参数对变量的影响或假设检验
(2)模型参数:模型训练时自动更新的参数,比如权重、支持向量、系数等,也是随机变量
【1】通过模型学习数据,利用优化方法解决最优化代价函数问题,从而更新模型参数,超参数影响模型参数的估计
【2】模型参数在模型训练初始阶段设定初值,在单次训练完成后更新值,
【3】参数的不同只意味着具体模型的不同,但是抽象的模型框架还是一样,比如线性模型y=ax,a不同代表不同的线,但模型的整体特点仍相似
【4】如果一个模型的参数不显著,应该将其排除,重新建模
(3)超参数:自己手动设定的参数,比如学习速率、迭代次数、隐藏层的层数、每层神经元的个数、正则项参数等
【1】根据问题手动设定和调整,无法从数据中得出
【2】超参数的设定在建模前,超参数的选择就是模型的选择,因为不同超参数有时候意味着不同模型,比如神经网络中的层数
【3】调参是指对不同超参数的搜索,但是很多超参数都是实数域取值,因此超参数的调整费时费力,可以依靠经验
(4)预测值:模型预测值,随机变量
【1】模型内生性:我们不知道预测变量的变化多少是由真实观测变量引起的,有多少是由误差引起的,若误差和观测变量相关,则会引发内生性
【【1】】来源: 遗漏变量(它使得模型中随机扰动项其实是为未被观测到的变量和真实扰动项的组合,这就导致模型中变量和随机扰动项相关)
【【2】】来源:度量误差:我们用的是观测值进行建模,观测值是真实值+e,则模型中的x和模型中的e相关
【【3】】来源:因变量和自变量互为因果,同时发生
2.模型本身的能力
(1)拟合能力:模型对于数据的学习能力,是指在数据集上模型经过数据点的能力,主要表现为真实值和预测值的差距,而且模型的拟合能力是对于整个数据集空间的拟合,而不仅仅是对训练数据集的拟合,包括对已知数据(训练数据)的拟合和对未知数据(测试数据)的拟合
【1】模型的拟合能力体现在对数据的学习上,但是数据包括我们需要的信息(对泛化能力有作用的信息)和不需要的信息,若我们没有学到需要的信息,就会导致我们我们不能很好地进行预测(欠拟合),若我们学到很多不需要的数据,就会导致我们预测的错误(过拟合),因此,我们需要对数据进行适当的学习
【2】过拟合(overfitting):学习器把训练样本学的太好,以至于把训练样本所包含的不太一般的性质都学到了,这样会导致泛化性能下降,无法彻底避免,只能缓解
【3】欠拟合(underfitting):学习能力低下,对训练样本的一般性质尚未学好,学习不充分导致泛化能力下降,比较好克服
【4】例:比如对于树叶的训练,过拟合可能会误以为树叶都是有锯齿(其实是样本自身的特性),欠拟合可能会误以为绿色的都是树叶(学习不充分)
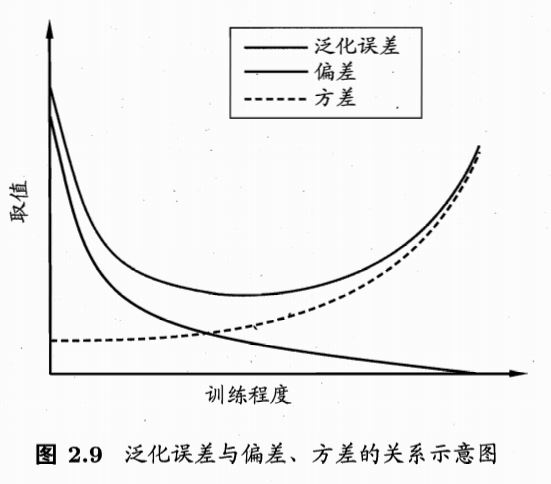
(2)泛化能力:模型在真实的未知数据集上的表现,是由模型的学习数据的能力(算法的拟合能力-偏差)、数据的充分性(数据扰动所造成的影响-方差)以及学习任务本身的难度(噪声)所共同决定的,而泛化误差体现泛化能力,所以泛化误差可以分解为偏差、方差和噪声之和,泛化能力可以用偏差/方差来解释。
![]()
【1】噪声:表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即任务本身的难度
【2】偏差:在数学中,在一组数据中,偏差是指随机变量对于数学期望的偏离程度。在机器学习中,偏差度量了学习算法的期望预测与真实结果的偏离程度。
【【1】】偏差针对期望预测与真实值的差值,主要体现了模型对未知数据的拟合能力,强调模型的学习能力,所以泛化能力包含拟合能力
【【2】】偏差小:模型学习充分,但是可能过拟合;偏差大:模型学习不充分,肯定欠拟合
【3】方差:在数学中,在一组数据中,方差是每个样本值与样本均值之差的平方值的平均数,方差体现一组数据的离散程度。在机器学习中,方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
【【1】】方差针对所有预测值的离散程度,强调数据的扰动能力
【【2】】方差小:模型稳定;方差大:模型不稳定
【4】求解偏差--方差:
【【1】】选择一条样例作为测试样例,x--y
【【2】】选用一种模型M(已确定超参数,为确定模型参数),利用交叉验证法(n个相同大小的(训练集,验证集)),训练数据集得出n个具体的模型M1...Mn(超参数和参数都确定)
【【3】】让这些模型对样例进行预测,得出n个预测值y1...yn,则有期望预测(对相同大小、不同训练集下的同一样本的预测值取均值,而不是对一次训练的所有样本的预测值取均值)y_mean=(y1+...+yn)/n
【【4】】这个样例的偏差:期望预测与真实值的差距:|y_mean-y|
【【5】】这个样例的方差:不同训练集下的预测值减去期望预测的平方均值,即(|y1-y_mean|^2+|y2-y_mean|^2+...|yn-y_mean|^2)/n
【5】理解:偏差-方差分析代表了我们对于模型M泛化能力的分析,模型M的泛化能力是体现在整个数据集上的,而不仅仅在训练集上,我们可以通过训练数据确定参数使模型M变成Mi,具体的模型Mi对于数据也有偏向(一个模型Mi可能在这个训练子集上表现好,在另一个训练子集上表现差),因此仅仅在一个训练子集上得出的模型Mi并不能代表这个模型M真正的泛化能力,所以我们让模型M对于相同大小的不同训练子集进行学习,需要注意的是我们所说的模型的好坏是指针对某个具体的机器学习问题,一个确定了超参数,未确定参数的模型M的好坏,而不是全确定的具体模型Mi,Mi的表现好坏不能代表M的好坏,而且每次由M训练所得的模型Mi可能不同,但是我们通过衡量Mi来简介衡量M。对于一个样例,我们用所有Mi预测结果的期望来代表M对于该样例x的预测,则该预测与真实值之间的差距(偏差)代表了M的拟合能力(预测的准确性)。Mi对于x的预测是不同的,如果所有的预测值都互相接近,即在一定小的范围内,这说明模型M在整个数据的任意一个子训练集都能预测到一个较小的范围内,预测稳定,这表示训练数据的不同对模型M的影响小,此时方差(预测的离散程度)小;反之,若预测值分布广泛(东一个西一个),说明模型M对于x的预测对数据的依赖性大(数据稍有变动,预测值就有较大变动),模型不稳定,此时方差大(预测值的离散程度大)。
3.模型的表现
(1)模型在不同数据集上的表现:我们用误差来表示数据集上模型的表现,根据不同数据集,误差可以更具体地分为:训练误差+训练/开发误差+开发误差+测试误差,一般而言,这四个误差的值是从小到大的
【1】训练误差:是指模型在训练数据集上的真实值和预测值的差异,主要体现了模型对于训练数据的拟合能力,越小代表拟合能力越强。
【【1】】误差可以分解为方差+偏差+噪音,噪音不论,方差表示数据扰动造成的影响,而训练集一般而言很大,所以就表示训练误差中方差的影响很小,所以训练误差是以偏差为主导的,主要体现模型对已知数据的拟合能力,所以我们一般对训练误差不谈偏差/方差分析,只要一心最小化训练误差,即增大拟合能力。
【【2】】训练误差的大小,在判断给定的问题是否是一个容易学习的问题上,具有一定的意义。
【2】训练/开发误差:是指模型在训练/开发集上的的真实值和预测值的差异
【【1】】训练/开发集和训练集同分布,其上的误差可以分解为偏差和方差,偏差是由于和训练集同分布所继承的,方差是由于和训练集不同导致的数据扰动对模型的影响。因此,训练误差和训练/开发误差之间的差距体现了方差。
【3】开发误差:是指模型在开发集上的的真实值和预测值的差异
【【1】】由于开发集和训练集的数据分布可能不一致,所以开发误差不仅包括训练/开发集的偏差和方差,还可能包括数据不平衡导致的差距
【4】测试误差:是指模型在测试集上的的真实值和预测值的差异
【【1】】测试误差为泛化误差的近似,可以近似地体现模型的泛化能力,测试误差的降低是我们的目标,
【【2】】一般而言,测试集和开发集的分布相同,但是测试集是不参与模型训练和选择的,只作为最终模型的评估,而开发集参与模型的开发,因此测试误差处理包含开发集的误差,还包括开发集拟合度带来的误差
(2)其他表现:
【1】贝叶斯误差:某个模型能达到的理论最低误差,一般不为0,但是近0,因为数据中总会有噪音之类的影响。
【2】人类的表现:我们设计一个机器学习系统的目的在于用机器来替代人类的工作,这就导致人与机器的比较,我们训练和改进模型的目的也在于使模型的表现能达到甚至超过人类的表现。一般而言,随着对模型训练和改进的程度的加深,模型的误差会降低,模型表现接近人类的表现,这个过程相对来说比较快,因为我们知道怎么改进模型才能让它达到人类的标准。若模型的表现超过了人类,此时模型表现的增长率就会降低,一是因为我们人类的表现本身就接近贝叶斯误差,模型可改进的空间变小,二是因为我们也不知道怎么才能更有效的改进,这超过了人类的认知水平。人类误差一般是真实统计出来的。
【3】人类水平误差:人类水平参差不齐,我们把其中表现最好的作为人类水平误差,也作为贝叶斯误差的近似,但注意:实际中,只要系统的表现达到普通的水平,就可以使用,系统就有了价值。
【4】泛化误差:泛化误差是我们的最终目标,测试误差和其毕竟是有差距的,我们运用假设检验计算近似替代的可信度。
4.模型复杂度对模型性能的影响
(1)模型复杂度对偏差/方差的影响
【1】模型简单,拟合能力差(偏差大),模型受到数据的变动的影响小(方差小)
【2】随着模型变复杂,模型拟合能力增强,但是数据的变动对其的影响变大(比如x到x^3对应2到8)
【3】模型复杂,拟合能力强(偏差小),模型对于数据扰动敏感(方差大)
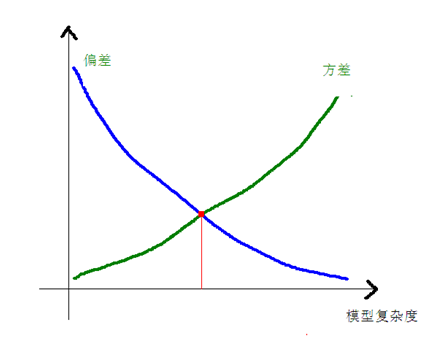
(2)模型复杂度对数据集误差的影响
【1】随着模型复杂度的增加,拟合能力增强,偏差减小,数据扰动增强,方差变大,所以由偏差占主导的训练误差从大渐渐变小,而根据偏差/方差分析得到的测试误差由大先变小再变大
【2】对于训练误差,拟合能力的增强速度是由快到慢的,随着模型复杂度的提升,拟合能力的增强越来越难,因此训练误差下降趋势趋于平缓
【3】对于测试误差,根据偏差/方差分析,随着模型复杂度的提升,首先是增强拟合能力比较容易,所以此时偏差占主导,所以是下降趋势;而当拟合能力提升到一定程度时,数据扰动的影响变大,也就是出现过拟合的情形,方差增长的速度比偏差下降的速度大,方差占主导,此时测试误差呈上升趋势
【4】根据偏差/方差分析,测试误差是包含训练误差的,所以测试误差整体大于训练误差
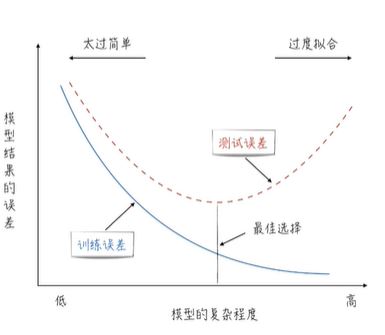
5.训练程度对于模型表现的影响
(1)训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差大,方差小,泛化误差中偏差占主导
(2)随着训练程度的加深,学习器的拟合能力逐渐增强,偏差一直降低,训练数据发生的扰动渐渐能被学习器学到,方差一直上升;前期增强拟合能力比较容易,泛化误差中偏差占主导,后期数据扰动的影响增强,方差占主导
(3)训练充分时,学习器的拟合能力非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,容易出现过拟合,此时偏差小,方差大,泛化误差中方差占主导
6.训练数据量对数据集误差的影响-学习曲线
(1)训练程度和训练数据量是不同的:训练程度主要指训练迭代的加深对模型性能的改变,而训练数据量主要指输入的样本总数
(2)学习曲线:判断某一个学习算法是否处于偏差-方差问题,从而判断它是否过拟合或欠拟合
【1】数据量少时,模型很容易就拟合了训练数据集,因此训练误差小,而由于数据量少导致模型不能有效学习整个数据集的特点,只是学到了训练数据集的自身的特点,所以预测不准未知数据,偏差大,此时数据扰动的影响也大,方差大,所以验证误差很大
【2】因为误差是所有数据的误差总和,所以训练误差随着数据量的增大而上升,又由于模型的拟合能力增强,所以单个训练样本的误差成下降趋势,因此训练误差成梯度下降的上升趋势;数据量的增大使得模型的拟合能力增强,但是增强的速度一直下降,达到一定程度,模型的拟合能力难以再提高,整个数据集的偏差上升速度有快到慢,而数据扰动造成的影响也是一直在降低,但由于数据量的增大使得模型变稳定,所以方差降低速度由大到小趋于稳定,所以验证误差为由快到慢的下降趋势(因为验证误差中还是方差占主导)
【3】数据量达到一定程度,训练出的模型趋于稳定,由于验证误差包括一部分训练误差,所以训练误差小于验证误差。
(3)训练误差代表偏差,验证误差和训练误差之间的差距表示方差
【1】正确的学习曲线:对于一个适当模型来说(既无欠拟合,又无过拟合),偏差小,方差小
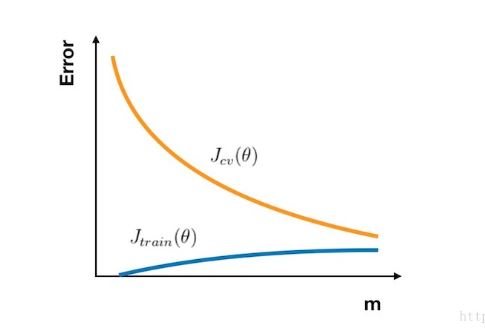
【2】高偏差模型:偏差大,则训练误差大,欠拟合
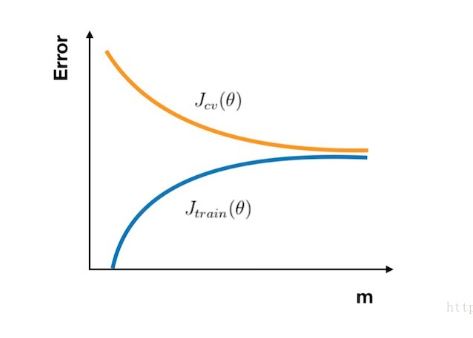
【3】高方差模型:过拟合,拟合能力强,偏差小,则训练误差小,泛化能力弱,方差大,则训练误差和验证误差间的距离大
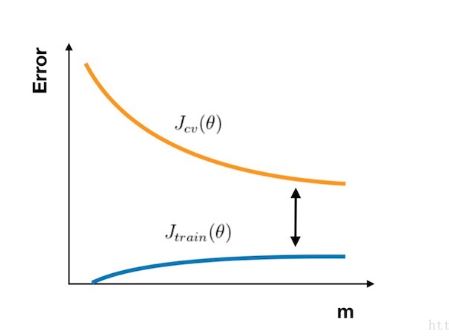
7.正则化参数对数据集误差的影响
(1)正则化参数:是对模型参数的惩罚,随着正则化参数的增大,对模型参数的惩罚增大,相当于降低了模型的复杂度,模型拟合能力降低,对应训练误差一直增大
(2)若模型是过拟合的,模型复杂度的降低,相当于先降低拟合能力,提升泛化性能;再继续的话,模型可能由过拟合变为欠拟合,因此验证误差先降再升
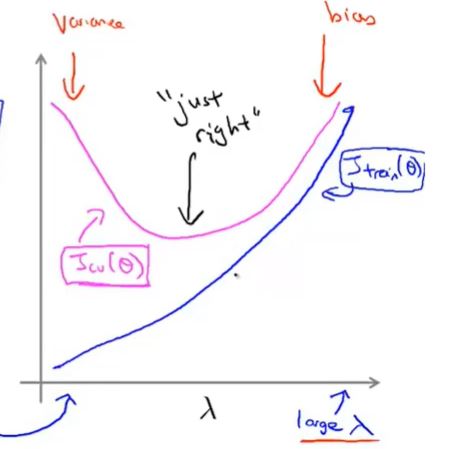
8.总结
(1)训练误差大-偏差大-欠拟合-模型简单-λ太大-训练不充分-训练集小
(2)训练误差小,验证误差大-高方差-模型复杂-λ太小或没有-训练太充分-过拟合
(3)模型训练对模型的影响:对于一个模型来说,刚开始:高方差、高偏差;随着数据的训练,拟合能力增强,偏差降低;开始训练时,训练数据不足,则训练数据的扰动不足以使模型改变,此时方差变化不大,偏差在泛化能力中占主导;随着训练量的增加,则数据扰动被模型学到,方差占主导。最后,训练数据过量,此时模型拟合能力过强,则轻微的数据扰动都会对模型发生明显变化,若属于训练数据本身的特性被模型学到,则模型的泛化能力会降低,即过拟合。
七.模型改进
1.改进目标和原则
(1)正交化-最大化收益规则:对一个训练完的模型,对它某个方面的改进不影响其他方面,让模型可改进的各个部分互不相关,每次选择能最大化提高模型性能的部分进行改进
(2)改进的目标:得到泛化性能较好的模型,泛化性能分析--误差分析--偏差/方差分析
2.可改进的各个部分
(1)可避免偏差:训练误差和人类水平误差的差距。表示我们可以对模型的提升还有多少,这部分的偏差是可以通过某些方法而避免的
【方法】增强模型拟合能力,比如训练更大的神经网络,跑久一点的梯度下降,选择更好的优化算法、增加训练时间、超参数选择
(2)方差:训练集和训练/开发集的分布一致,则方差为训练误差和训练/开发误差之间的差距
【方法】降低拟合能力,提高正则化参数、更多训练数据、数据增强、不同的网络架构、超参数选择
(3)数据不平衡:若开发集和训练集的分布不一致,即相对于训练集来说,开发集多了很多数据噪声,这对模型来说,相当于错误的数据(噪声),因此数据不平衡为开发误差和训练/开发误差的差距
【方法】从测试集或开发集中取出一部分放入训练集、人工地进行误差分析,来了解训练集和开发集的具体差异、人工合成数据
(4)开发集的过拟合程度:开发集和测试集的差距
【方法】重新定义开发集、更大的开发集
(5)比较检验:泛化误差和测试误差的差距
【方法】改变评估标准或开发、测试集
(6)误差分析:算法没能达到人类表现时,人工检查错误和分析错误,提出想法并检验是否值得去做
3.误差分析:算法没能达到人类表现时,人工检查错误和分析错误。
(1)检验算法所犯的错:真实标记为y1,算法标记为y2。人工找出这些错误并分析预测错误的原因。
(2)检验数据的错误:把真实标记为y1错误标记为y2。人工检验这些错误
(3)方法:在验证集中,找一组错误样本,做个表格,标记各个错误类别,统计所有错误类型的百分比(包括标记错误类),按百分比从大到小进行模型的改进。
(4)开发集是用来选择模型的,对于标记错误的这些数据,若在验证集上严重影响了评估算法的性能,那么就应该花时间去修正。
【1】先看整体的开发集误差,再看这个误差中真实错误类别的占比,再看其他各个类型错误所占比
【2】若要修正,要验证集和测试集一起进行修正,保证同分布。
【3】不仅要检查错误的样本,也要检查正确的样本,因为可能是运气分类正确的,但是这样的耗费代价高,
【4】训练数据没必要,因为它很大,标记错误对它的影响不过是和开发、验证集分布不同,这可以有其他方法进行修正。
4.高偏差:模型拟合能力弱,模型简单,
(1)引入更多的相关特征,采用多项式特征-------使模型变复杂,增大拟合能力
(2)减小正则化参数---------减小对模型的惩罚力度,相当于提高模型复杂度
5.高方差:模型泛化能力弱,1)数据训练不足导致数据扰动不能被模型学的(训练完的模型验证误差明显大于训练误差),2)数据训练过量,拟合能力过强导致模型学得训练数据自身的特性
(1)采集更多的样本数据-----增加训练量---1)
(2)减少特征数量,去除非主要的特征--------使模型变简单,降低拟合能力对泛化能力的影响-----2)
(3)增加正则化参数-----------增大对模型的惩罚力度,相当于降低模型的复杂度-----2)
6. 欠拟合(高偏差,高方差):模型拟合能力差导致泛化能力差
(1)提高模型复杂度(增加特征,添加非线性变换...)
(2)如果有,减小正则化参数
7.过拟合(高偏差、低方差):拟合能力过强导致泛化能力差
(1)若数据训练不足,则增加数据量
(2)降低模型复杂度(选择合适模型,减少特征,减少训练次数,选择合适特征,采用dropout方法,减少迭代次数,增大学习率,添加噪声数据,剪枝....)
(3)如果没有,则添加正则化参数;如果有,增大正则化参数
(4)数据清洗(降低数据噪声的影响)
8.正则化改进:在最小化经验误差函数(代价)上加约束,用来平衡损失函数和模型参数
(1)我们对于代价函数的目的是最小化它以提高模型的拟合能力,但是这容易导致过拟合,因此想到通过降低模型复杂度降低模型的泛化能力,在代价函数后加入惩罚项(正则项)实际上是对模型参数的惩罚,代价函数前面是为了更好的拟合训练集,提高拟合能力,后半部分则变成最小化模型参数和正则化参数的组合,实际上表示我们要获得何种性质的模型(当然是复杂度低的模型),我们要在两者之间进行平衡,正则化参数是超参数,实际上是对模型参数的惩罚,也是对模型的惩罚,若设置过大,表示惩罚力度高,模型参数需要接近0才能尽可能降低代价函数,此时模型变得简单(直线)(欠拟合),若设置过小,表示近乎无惩罚,即我们不关注模型的复杂度,起不到过拟合的作用
(2)正则化项 :对于复杂模型,我们希望去除某些特征来降低模型复杂度,很明显我们应该尽量去除不相关的特征,也就是在模型中使他们前面的系数接近0,但由于我们不知道选择哪些特征相关性低,所以修改代价函数来缩小每一个参数----正则化项 λ∑θ2
(3)正则化参数:控制两个不同目标之间的取舍:1)更好的拟合训练集;2)保持参数尽量小,保持模型简单,避免过拟合
(4)正则化参数的选择:不大不小1)太大,表示惩罚程度高,参数接近0,模型(直线)(欠拟合),偏差过大;2)太小:起不到处理过拟合的作用
(5) L1正则化(L1范数):让原目标函数加上了所有特征系数绝对值的和来实现正则化,更适用于特征选择
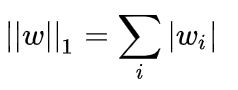
(6)L2正则化(L2范数):让原目标函数加上了所有特征系数的平方和来实现正则化,可以产生稀疏权值矩阵,即产生一个稀疏模型,更适用于防止模型过拟合
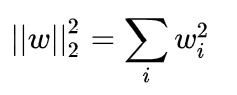
(7)正则化线性回归:梯度下降:相当于把参数往0移动一点(变小一点点),再进行和以前一样的操作;正规方程:矩阵不可逆问题得到解决,因为正则化参数大于0
(8)正则化和标准化:参数的大小和特征的取值有关,也和是否有正则项有关,若无正则项,标准化后得到的参数值可以反映不同特征对于预测的贡献,可以用于特征筛选,若有正则项,其实是对较大参数的惩罚,而忽略小的参数,这对于量纲影响的参数来说是不合理的,此时需要使用标准化使得特征同等看待。
9.其他
(1)若开发和测试集误差小于训练集误差,说明开发集分布比训练集分布容易
(2) 一般不用停止训练的策略,这可能会改善开发集的表现,同时也会影响对训练集的拟合,不符合正则化原则
(3)更具体的流程
【1】对处理完的数据集进行划分:训练集+开发集+测试集,记得预留一部分训练数据当做训练/开发集,用于检验数据不平衡问题;
【2】定义一个模型的评估标准,最好是单实数指标;
【3】快速选择一些模型在训练集上进行训练,去除在训练集上表现很差的模型;
【4】再把剩余的模型在开发集上进行评估,选择其中表现最好的模型;
【5】绘制学习曲线进行最终模型的偏差/方差分析,并进行改进;
【6】若怎么都降不下方差,可能是出现了数据不平衡问题,用训练/开发集进行检验并改进;
【7】若模型没达到人类表现,可以进行误差分析,人工检验和分析错误,改进模型;
【8】在测试集上评估改进后的模型,将其投入到实际中使用;
【9】若此时表现好的模型在实际使用时表现差,则说明目标错误了,评估标准无法评估算法间的优劣,此时应该改变评估标准或改变开发集或测试集,重头再来;
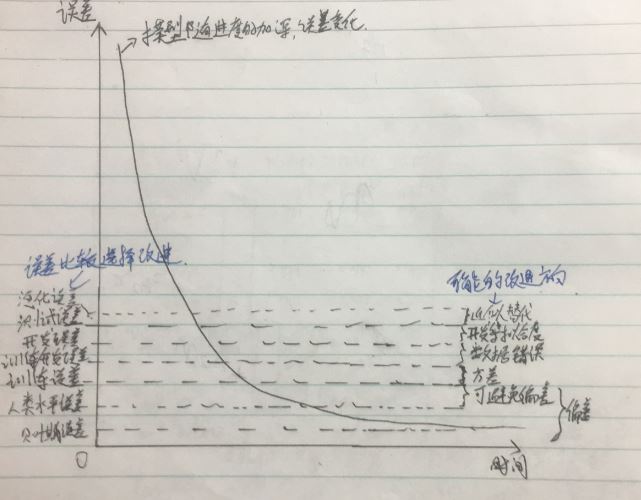
【10】若在实际中表现好,说明在此时模型可以投入使用,但是最好模型每过一段时间重新训练提升一次。
八.模型非线性变换
1.所有模型的基础都是线性模型,是线性模型和非线性变化的组合
2.激活函数----数学上的复合函数
(1)激活函数用于对模型进行转换,若模型为f(x),激活函数为g(x),则转换后的模型为g(f(x))
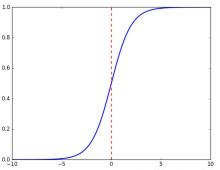
(2)Sigmoid函数(Logistic函数):
特点:把输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用作输出层,而且求导容易。但由于其软饱和性,容易产生梯度消失,导致训练出现问题。其输出并不是以0为中心的。
![]()
(3)Tanh函数:解决了输出不是0均值的问题
![]()
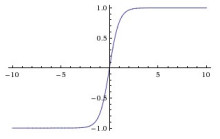
(4)Relu函数:解决了梯度消失问题 (在正区间),计算速度非常快,只需要判断输入是否大于0,收敛速度远快于sigmoid和tanh,ReLU的输出不是0均值,某些神经元可能永远不会被激活,导致相应的参数永远不能被更新
2)Dead ReLU Problem
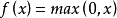
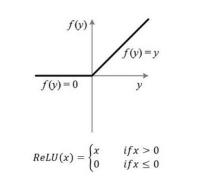
(5)ELU (Exponential Linear Units) 函数:解决了relu的问题,但计算量大
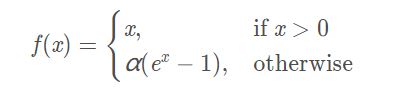
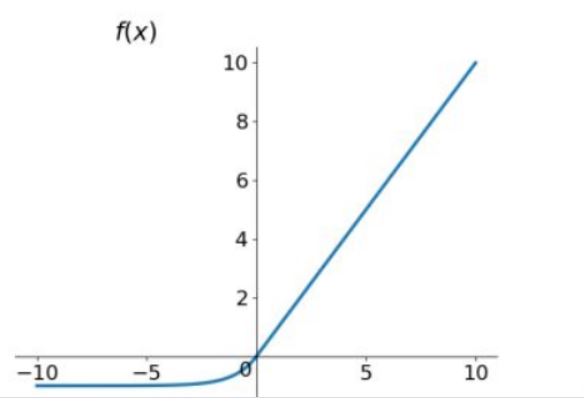
(6)一般来说,elu>relu>tanh>sigmoid
七.相关代码
1.构建模型


1 # 关于keras构建模型############################# 2 # keras是关于构建和训练神经网络模型的模块,本质上是基于线性模型的 3 # (1)通过组装图层的方式来构建模型。Sequential():多个网络层的线性堆叠建模: 4 # 【1】直接使用Sequential进行顺序添加层 5 # model = tf.keras.Sequential( 6 # [ # 顺序模型的第一层有时要知道知道它的输入尺寸,而其他层不需要,因为模型的其他层会自动获得输入尺寸,但要设置输出尺寸(神经网络数) 7 # tf.keras.layers.Flatten(input_shape=(28, 28)), # 模型第一层为输入层, 8 # tf.keras.layers.Dense(128, activation='relu'), # 中间为隐藏层,可以有多层 9 # tf.keras.layers.Dense(10) # 最后一层为输出层 10 # ] 11 # ) 12 # 【2】一层层顺序添加 (推荐) 13 model = tf.keras.models.Sequential() # 选择模型流程框架,Sequential顺序结构,表明以下层的添加是顺序进行的 14 model.add(tf.keras.layers.Dense(64, input_shape=(627,1),activation='relu')) 15 # 关于input_shape,利用元组来表示输入数据的维度,第一个数表示样本集的维度(样本总数),第二个数表示每个样本的维度(特征总数), 16 # 第三个表示每个特征的维度(特征长度)例如,考虑一个含有32个样本的batch,每个样本都是10个向量组成的序列,每个向量长为16,则其输入维度为(32,10,16), 17 model.add(tf.keras.layers.Dense(10)) 18 19 # 各种层: 20 # Dense层:全连接层,必要参数-输出维度,可选参数:偏置项、激活函数、输入维度、约束项、正则项、初始化权重和偏值 21 # Flatten层:用来把多维的输入一维化,常用在从卷积层到全连接层的过渡 22 # Activation层:单独的激活层,可以使用已有的激活函数或定义新的激活函数,输入输出shape一样 23 # Dropout层 :Dropout将在训练过程中每次更新参数时按一定概率(rate)随机断开输入神经元,Dropout层用于防止过拟合 24 # Reshape层:用来将输入shape转换为特定的shape 25 # 其他还有卷积层、池化层、递归层、嵌入层等 26 print(model.summary()) # 查看网络结构 27 ##################### 28 Model: "sequential" 29 _________________________________________________________________ 30 Layer (type) Output Shape Param # 31 ================================================================= 32 dense (Dense) (None, 627, 64) 128 33 _________________________________________________________________ 34 dense_1 (Dense) (None, 627, 10) 650 35 ================================================================= 36 Total params: 778 37 Trainable params: 778 38 Non-trainable params: 0 39 _________________________________________________________________ 40 None
1 # (2)自定义模型结构(处理具有非线性拓扑的模型,具有共享层的模型以及具有多个输入或输出的模型) 2 # 【1】通过层之间的调用关系定义层之间的关系,从而定义模型结构 3 inputs = tf.keras.Input(shape=(627,1)) # input表示输入层,要表明输入的维度 4 x1 = tf.keras.layers.Dense(64)(inputs) # 先定义层,再进行调用:对于各个层之间,B(A)表示层B调用A,即层A的输出为B的输入 5 outputs = tf.keras.layers.Dense(10,activation='softmax')(x1) 6 model1 = tf.keras.Model(inputs=inputs,outputs=outputs) # 构建模型,指定输入层和输出层 7 print(model1.summary()) 8 # 【2】每个图层就是一个小的模型,也就是说模型与层可以互相调用,注意上一层的输出维度要和这层的输入维度一样 9 x2 = model1(inputs) 10 model2 = tf.keras.Model(inputs, x2) 11 print(model2.summary()) 12 # 【3】多输入和多输出模型 13 x = tf.keras.layers.concatenate([x1,x2]) #把两层链接为一层,该层的输出维度为所有层的输出维度和 14 # 定义一个多输入所输出模型: 15 # model = keras.Model(inputs=[title_input, body_input, tags_input], 16 # outputs=[priority_pred, department_pred]) 17 # 【4】共享层:多个模型或层调用同一层 18 19 # (3)绘图 20 # tf.keras.utils.plot_model(model, 'my_first_model_with_shape_info.png', show_shapes=True) 21 # plt,show() 22 ---------------------- 23 Model: "model" 24 _________________________________________________________________ 25 Layer (type) Output Shape Param # 26 ================================================================= 27 input_1 (InputLayer) [(None, 627, 1)] 0 28 _________________________________________________________________ 29 dense (Dense) (None, 627, 64) 128 30 _________________________________________________________________ 31 dense_1 (Dense) (None, 627, 10) 650 32 ================================================================= 33 Total params: 778 34 Trainable params: 778 35 Non-trainable params: 0 36 _________________________________________________________________ 37 None 38 Model: "model_1" 39 _________________________________________________________________ 40 Layer (type) Output Shape Param # 41 ================================================================= 42 input_1 (InputLayer) [(None, 627, 1)] 0 43 _________________________________________________________________ 44 model (Model) (None, 627, 10) 778 45 ================================================================= 46 Total params: 778 47 Trainable params: 778 48 Non-trainable params: 0 49 _________________________________________________________________ 50 None
1 # 自定义层:找不到需要的层,就自己写 2 class MyLayer(tf.keras.layers.Layer): 3 #A(m,n)*B(n,p)=C(m,p)中的B,其中A为输入样本,B为该层的权重向量,C为输出,m为样本数,p为输出维度,n为输入维度 4 def __init__(self, output_dim, **kwargs): 5 self.output_dim = output_dim #初始化设定输出的维度p 6 super(MyLayer, self).__init__(**kwargs) #继承父类 7 8 def build(self, input_shape): 9 # 为该层创建一个可训练的权重向量B和W.作为内核向量, 10 self.kernel = self.add_weight(name='kernel', 11 shape=(input_shape[1], self.output_dim), #指明矩阵形状 12 initializer='uniform', #指明初始化方式 13 trainable=True) #指明可训练 14 15 def call(self, inputs): 16 #定义前向传播 17 return tf.matmul(inputs, self.kernel) #两个矩阵相乘 ,A(m,n)*B(n,p)=C(m,p) 18 19 def get_config(self): 20 #序列化 21 base_config = super(MyLayer, self).get_config() 22 base_config['output_dim'] = self.output_dim 23 return base_config 24 25 @classmethod 26 def from_config(cls, config): 27 return cls(**config) 28 29 model = tf.keras.Sequential([MyLayer(10)])
1 # class MyModel(tf.keras.Model): 2 # def __init__(self, num_classes=10): 3 # super(MyModel, self).__init__(name='my_model') # 继承父类 4 # self.num_classes = num_classes 5 # 6 # # 自定义神经层. 7 # self.dense_1 = layers.Dense(32, activation='relu') 8 # self.dense_2 = layers.Dense(num_classes) 9 # 10 # def call(self, inputs): 11 # # 在call方法中定义前向传播,并定义层之间的调用关系 12 # x = self.dense_1(inputs) #dense1层调用输入层 13 # return self.dense_2(x) 14 # 15 # model = MyModel(num_classes=10)
2.模型编译
1 # 模型编译---设置模型训练和评估的相关参数(优化器、损失函数、监控指标)################## 2 model.compile(optimizer=tf.optimizers.RMSprop(learning_rate=0.2), # 优化器 3 loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True), #最小化损失函数 4 metrics=[tf.metrics.mean_absolute_error,tf.metrics.Precision()]) #要监控的指标列表 5 6 # 优化器:SGD随机梯度下降(以及拓展动量法等);RMSprop一般用于训练循环神经网络RNN;Adagrad自动调整参数;Adadelta;Adam;Nadam等 7 # 损失函数:mean_absolute_error均方误差;CategoricalCrossentropy(from_logits=True)多元交叉熵--多分类问题; 8 # binary_crossentropy二元交叉熵--二分类问题;mean_absolute_error绝对值均差;hinge等 9 # 评估指标:mean_square_error:MSE均方误差;tf.metrics.AUC;Precision准确率等 10 # 另外:自定义优化器、损失函数、评估指标----输入(真实值,预测值) 11 # def mean_pred(y_true, y_pred): 12 # return keras.backend.mean(y_pred) 13 # def basic_loss_function(y_true, y_pred): 14 # return tf.math.reduce_mean(tf.abs(y_true - y_pred)) 15 # 类化: 16 # #class WeightedBinaryCrossEntropy(keras.losses.Loss): 17 # def __init__(self, pos_weight, weight, from_logits=False, 18 # reduction=keras.losses.Reduction.AUTO, 19 # name='weighted_binary_crossentropy'): 20 # super().__init__(reduction=reduction, name=name) 21 # self.pos_weight = pos_weight 22 # self.weight = weight 23 # self.from_logits = from_logits 24 # def call(self, y_true, y_pred): 25 # ce = tf.losses.binary_crossentropy( 26 # y_true, y_pred, from_logits=self.from_logits)[:,None] 27 # ce = self.weight * (ce*(1-y_true) + self.pos_weight*ce*(y_true)) 28 # return ce 29 #####################
3.模型训练
1 train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)) 2 validation_dataset = train_dataset.shuffle(buffer_size=1024).batch(64) 3 # 回调函数:用于在训练期间自定义和扩展其行为,使用回调函数来观察训练过程中网络内部的状态和统计信息。 4 callbacks = [ 5 # Interrupt training if `val_loss` stops improving for over 2 epochs 6 tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'), 7 # Write TensorBoard logs to `./logs` directory 8 tf.keras.callbacks.TensorBoard(log_dir='./logs') 9 ] 10 # 模型训练--可设置相关训练参数 - 11 train_model = model.fit(train_dataset, #第一第二个参数为训练样本及标签 12 epochs=5, #epoch ,整个训练集循环训练的次数 13 batch_size=32, # 每次训练的样本数 14 callbacks=callbacks, # 回调函数 15 validation_data=validation_dataset #设定验证集 16 ) 17 18 print(train_model.history.keys()) # 可以通过history中的keys获得训练中的相关数据 19 plt.plot(train_model.epoch,train_model.history.get('loss')) #可视化作图
4.模型评估
1 # 模型评估 2 #evaluate逐次计算,返回误差值和评估标准值 3 model.evaluate(x=test_image, y=test_label, #测试集评估的样本及标签,数组或多维数组 4 batch_size=32, #每次评估的样本数。如果未指定,默认为 32 5 )
5.模型预测
1 #predict预测 2 model.predict(x=test_image.iloc[:10,1:-1], #Numpy 数组列表 3 batch_size=None, 4 verbose=0, #日志显示模式,0 或 1 5 steps=None) #声明预测结束之前的总步数(批次样本)
6.模型保存和读取
1 # 保存权重到检查点 2 model.save_weights('./weights/my_model') 3 # 读取模型的状态(权重),恢复模型,前后模型要一致 4 model.load_weights('./weights/my_model') 5 6 ########用hdf5格式保存和读取 7 model.save_weights('my_model.h5', save_format='h5') 8 model.load_weights('my_model.h5') 9 ####################################################### 10 ####1.json形式 11 import json 12 import pprint 13 json_string = model.to_json() #将模型序列化 14 pprint.pprint(json.loads(json_string)) #以json形式保存模型 15 fresh_model = tf.keras.models.model_from_json(json_string) #读取模型 16 ####2.yaml形式 17 yaml_string = model.to_yaml() #保存 18 fresh_model = tf.keras.models.model_from_yaml(yaml_string)#读取 19 ######################################################## 20 21 # 以HDF5格式存储整个模型,包括权重值,模型的配置,甚至优化器的配置 22 model.save('my_model') 23 model = tf.keras.models.load_model('my_model') #创建相同的模型
7.估算器:对特征或模型方法之类的做快速评估,常用于确定最佳策略
1 #估算器 2 # 数据集读取 3 train_path = r'./datas/iris/iris_training.csv' 4 test_path = r'./datas/iris/iris_test.csv' 5 df_train_first = pd.read_csv(train_path) 6 df_test = pd.read_csv(test_path) 7 print(df_train_first.head(), df_train_first.dtypes, df_train_first.describe(), sep='\n') # 查看数据概览 8 df_train, df_validation = train_test_split(df_train_first, test_size=0.2) 9 10 11 # ###特征工程########################## 12 # 1.创建输入训练和输出预测的数据的函数,主要进行特征构建和提取,并从原df数据中划分出预测标签列 13 def input_evaluation_set(data,label=-1): 14 features = {'SepalLength': data.iloc[:, 0], 15 'SepalWidth': data.iloc[:, 1], 16 'PetalLength': data.iloc[:, 2], 17 'PetalWidth': data.iloc[:, 3], 18 'new_feature': data.iloc[:,0] + data.iloc[:,1]} 19 labels = data.iloc[:, label] 20 return features, labels 21 22 23 # 2.处理特征,将他们都转为数字型特征,进行声明(告诉模型怎样运用特征),主要是对定性变量和定量变量的处理,也可以进行特征构建 24 def create_feature_columns(): 25 feature_columns = [] # 创建在模型中要用到的特征列 26 NUMERIC_COLUMNS = ['SepalLength','SepalWidth','PetalLength','PetalWidth','new_feature'] 27 for feature_name in NUMERIC_COLUMNS: 28 feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32)) 29 return feature_columns 30 31 32 # 3.把df数据转化为容易训练或估计的tf专用数据类型Dataset,并对训练和估计时的一些参数进行设置 33 def input_fn(features, labels, training=True, batch_size=256): 34 """关于训练和估计时的一些参数,并把df数据转化为容易训练或估计的tf专用数据类型Dataset""" 35 dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels)) 36 if training: 37 dataset = dataset.shuffle(1000).repeat() # 如果在训练模式下混淆并重复数据 38 return dataset.batch(batch_size) 39 # ############################################### 40 41 42 train_features, train_labels = input_evaluation_set(df_train) 43 validation_features, validation_labels = input_evaluation_set(df_validation) 44 test_features, test_labels = input_evaluation_set(df_test) 45 46 # 设定所需特征(代表模型结构),构建模型 47 feature_columns = create_feature_columns() # 声明在模型中使用的所有变量 48 classifier = tf.estimator.BoostedTreesRegressor(feature_columns = feature_columns,hidden_units=[30, 10],n_classes=3) 49 50 # 利用数据训练模型。 51 classifier.train( 52 input_fn=lambda: input_fn(train_features, train_labels, training=True), 53 steps=5000) 54 55 # 评估模型 56 eval_result = classifier.evaluate( 57 input_fn=lambda: input_fn(test_features, test_labels, training=False)) 58 print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result)) 59 60 #预测 61 # expected = ['Setosa', 'Versicolor', 'Virginica'] 62 # predict_x = { 63 # 'SepalLength': [5.1, 5.9, 6.9], 64 # 'SepalWidth': [3.3, 3.0, 3.1], 65 # 'PetalLength': [1.7, 4.2, 5.4], 66 # 'PetalWidth': [0.5, 1.5, 2.1], 67 # }
八.总结
#未更新

 浙公网安备 33010602011771号
浙公网安备 33010602011771号