Direction of Arrival Based Spatial Covariance Model for Blind Sound Source Separation
基于信号协方差模型DOA的盲声源分离[1]。
在此基础上,作者团队于2018年又发布了一篇文章,采用分级和时间差的空间协方差模型及非负矩阵分解的多通道盲声源分离[2]。
摘要
本文通过对短时傅立叶变换混合信号的源空间协方差矩阵(SCM)的估计,解决多通道麦克风阵列的声源分离问题。在许多传统的音频分离算法中,源混合参数的估计是在每个频率仓分别进行的,因此容易产生误差,导致源估计的次优。本文提出一个由加权DoA核组成的SCM模型,并且权重只依赖于源信号的方向。在该算法中,源的空间特性在所有频率上进行了联合优化,使得源估计更加一致,减小了高频空间混叠的影响。提出的SCM模型由两部分组成:用于幅值的线性模型,及基于复值非负矩阵分解(CNMF)框架的参数估计。仿真实验中,通过客观的分离质量指标评价,表明该算法的分离质量优于现有的两种分离方法。
信号模型
定义声音源分离模型,为提出SCM模型和CNMF算法说明其空间处理背景。主要包括源混合模型说明,信号及其SCM定义,卷积混合模型在空间协方差域的解释。
源信号混合模型
阵列在时域得到源信号与空间响应卷积混合的混合信号,表示为:
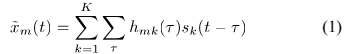
其中等式左边表示由K个源信号混合而成的第m个麦克风采集得到的混合信号,m=1,...M,时域采样索引为t。第k个源信号到第m个麦克风的空间响应表示为一个混合滤波器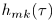 ,并且单通道源信号表示为
,并且单通道源信号表示为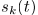 。
。
上式可以近似地在STFT域表示为在每个frequency bin的瞬时混合模型如下:
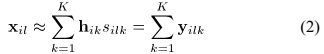
其中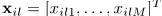 是
是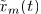 的STFT,并且分析窗长度为N=2I-1,其中正值DFT bin frequencies 表示为i=1,...I,并且STFT frame索引表示为l=1,...,L。在每一个frequency bin内,混合滤波器
的STFT,并且分析窗长度为N=2I-1,其中正值DFT bin frequencies 表示为i=1,...I,并且STFT frame索引表示为l=1,...,L。在每一个frequency bin内,混合滤波器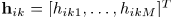 ,源信号的STFT为
,源信号的STFT为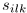 ,观测信号
,观测信号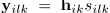 。因为经过源信号空间响应的主混响的能量忽略,有效长度为数百毫秒的混合滤波器
。因为经过源信号空间响应的主混响的能量忽略,有效长度为数百毫秒的混合滤波器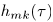 在频域经过数十毫秒的分析窗之后作用良好。
在频域经过数十毫秒的分析窗之后作用良好。
信号表示
本文提出的方法使用在每个时频点计算的SCMs表示信号。空间协方差计算将混合信号的绝对相位转换为每一对麦克风的相位差。幅度平方根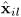 在时频点(i,l)表示为:
在时频点(i,l)表示为:
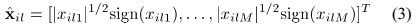
从阵列采集信号向量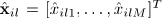 得到单时频点的SCM表示为矢量积形式如下:
得到单时频点的SCM表示为矢量积形式如下:

其中等式左边在每个时频点(i,l)由观测值幅度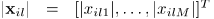 组成,在其对角线
组成,在其对角线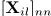 上。非对角线元素
上。非对角线元素 表示每一个麦克风对(n,m)的幅度相关和相位差
表示每一个麦克风对(n,m)的幅度相关和相位差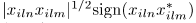 。
。
空间协方差域的卷积混合模型
由公式(2)定义的卷积混合模型在SCM域表示为:
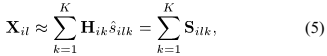
其中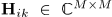 为每个源信号的空间协方差矩阵,表示
为每个源信号的空间协方差矩阵,表示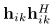 。复值单通道频谱
。复值单通道频谱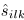 为相关的源信号幅度谱,可以得到实值功率谱
为相关的源信号幅度谱,可以得到实值功率谱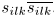 。
。
由于使用平方根STFT计算观测值的SCMs,我们用幅度谱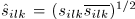 表示源信号。SCMs近似正定,因为源信号近似不相关却稀疏,表示在一个时频点只有一个源信号是正值。使用由式(3)-(5)定义的SCM域时,从参数估计的角度来看,源信号的绝对相位并不重要。在此我们只对所有麦克风对的相位差进行建模。
表示源信号。SCMs近似正定,因为源信号近似不相关却稀疏,表示在一个时频点只有一个源信号是正值。使用由式(3)-(5)定义的SCM域时,从参数估计的角度来看,源信号的绝对相位并不重要。在此我们只对所有麦克风对的相位差进行建模。
采用DOA核叠加的SCM模型
Time-difference of Arrival
TDOA和阵列的结构有关,考虑图1的阵列结构,有一对麦克风n和m位于xy平面,位置分别为n和m。
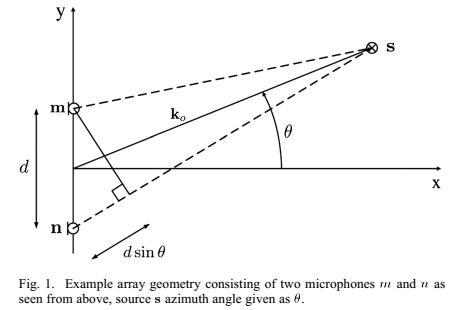
单位向量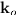 从阵列中心p指向观测方向。简单起见,设原点为阵列中心,则
从阵列中心p指向观测方向。简单起见,设原点为阵列中心,则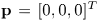 。在球坐标系中,观测方向由仰角
。在球坐标系中,观测方向由仰角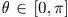 和方位角
和方位角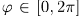 ,固定半径为1。我们定义
,固定半径为1。我们定义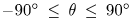 和
和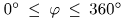 。
。
假设在远场模型下,平面波到达阵列,阵列中心点为p,麦克风n的TDOA为:
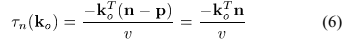
其中v是速度,每一个观测方向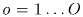 转换为TDOA,后面会转换为STFT域的相位差的线性插值。公式(6)中的TDOA等于在频域中
转换为TDOA,后面会转换为STFT域的相位差的线性插值。公式(6)中的TDOA等于在频域中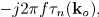 的相位差。相位差非常明确,除非空间混叠频率
的相位差。相位差非常明确,除非空间混叠频率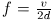 ,此时d表示阵列中最小的麦克风间距。
,此时d表示阵列中最小的麦克风间距。
我们定义麦克风对(n,m)的TDOA为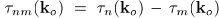 ,在每个频率索引
,在每个频率索引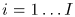 对应每个麦克风对
对应每个麦克风对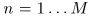 的相位差可以表示为矩阵
的相位差可以表示为矩阵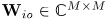 。文中定义其为DOA kernel矩阵:
。文中定义其为DOA kernel矩阵:
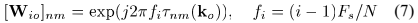
其中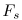 表示为采样率和N表示STFT长度。
表示为采样率和N表示STFT长度。
DOA kernels的叠加
假设点声源,消音室环境采集信号,一个单独的DOA kernel足够表述一个声源的SCM。然而,因为表面和物理的回声以及衍射等,需要一个更复杂的模型。对于SCM建模,文中提出一种DOA kernels的加权线性组合,可以在接收阵列周围均匀采样单位球面。每个DOA kernel的增益表述各个采样方向的信号功率。
定义一个固定观测方向的集合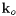 ,空间采样。每个频率
,空间采样。每个频率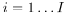 的每个观测方向
的每个观测方向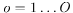 的DOA kernels用
的DOA kernels用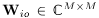 表述,并且通过公式(7)计算得到。
表述,并且通过公式(7)计算得到。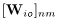 表示麦克风对(n,m)的相位差表示的复数TDOA。
表示麦克风对(n,m)的相位差表示的复数TDOA。
声源的空间表述为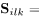
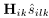 ,由幅值
,由幅值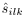 组成,并且和源SCM
组成,并且和源SCM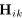 混的。则SCM 模型等价于多个DOA kernels的加权组合如下:
混的。则SCM 模型等价于多个DOA kernels的加权组合如下:

其中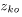 是对应于DOA kernels在每个观测方向的方向权系数。
是对应于DOA kernels在每个观测方向的方向权系数。
基于SCM模型的复值NMF
本部分主要是关于一种BSS算法,结合基于NMF的源幅值模型和基于DOA kernel的SCM模型,得到一个 complex valued NMF模型(CNMF)。
提出BSS算法能够联合地,使用SCM模型跨frequencies估计源的SCMs,以及使用方向性权系数(和frequency独立)估计源空间特征。算法框架如图4:
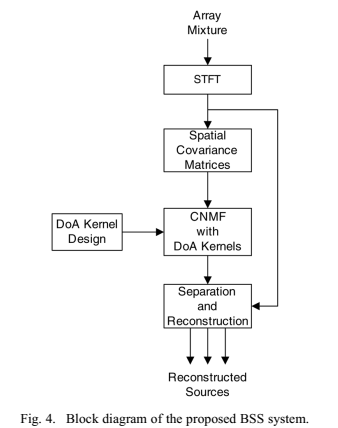
流程主要包括:逐时频点计算阵列采集信号的STFT;为后续的CNMF得到SCM模型;提前计算固定观测方向的DOA kernels 集合。
采用基于DOA的SCM模型的CNMF算法是用来估计源信号的参数,比如幅度谱和DOA kernel 方向权系数。在分离阶段,通过对CNMF得到的分量进行聚类,从混合信号中重构源,构建一个幅值掩模,用于获取源空间图像的维纳滤波估计。
用于SCM观测值的CNMF模型
实际中,若干个NMF分量表示一个实际的源信号。本文中,为了推导算法,定义一个NMF分量表示一个声源信号。随后在源信号重建时,根据NMF分量的估计方向权系数 进行聚类。
进行聚类。
SCM观测值的模型可以表示为:
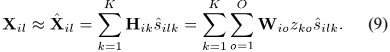
从NMF可以得到源信号的幅值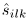 。第k个源信号的幅度谱的一阶NMF模型定义为:
。第k个源信号的幅度谱的一阶NMF模型定义为:
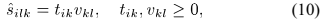
其中列向量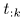 包含源信号的频谱,对应行
包含源信号的频谱,对应行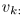 表示其在每个STFT帧的增益。固定源信号频谱的NMF幅度模型极度简化并且只对真实声源进行建模,为空间参数估计提供了一个中间表述。
表示其在每个STFT帧的增益。固定源信号频谱的NMF幅度模型极度简化并且只对真实声源进行建模,为空间参数估计提供了一个中间表述。
将表述NMF模型的公式(10)带入SCM模型(9),得到整个CNMF模型如下:
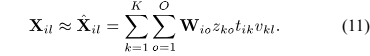
此外,CNMF模型可以通过采用源SCMs 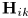 得到:
得到:
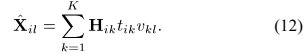
比较公式(11)和(12),可以看出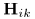 的对角线实值条目可以用来对每个通道的源绝对幅值进行建模,非对角线元素可以对跨通道幅值和相位差进行建模。进一步地,表示结合非负权重
的对角线实值条目可以用来对每个通道的源绝对幅值进行建模,非对角线元素可以对跨通道幅值和相位差进行建模。进一步地,表示结合非负权重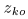 的幅值
的幅值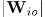 决定通道间的幅度差。
决定通道间的幅度差。
采用公式(7)的DOA kernels生成有单位幅值,要对幅值差进行建模,需要对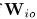 进行估计和更新。这是因为每个麦克风采集信号的不同。
进行估计和更新。这是因为每个麦克风采集信号的不同。
CNMF算法
一般NMF算法采用乘法更新准则,以最小化给定的代价函数,比如欧式距离或者KL散度。本文采用辅助函数和EM算法得到算法更新法则。
1)代价函数:在时频点上最小化观测值和模型的平方F反数值
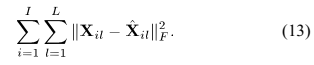
CNMF模型误差的统计解释相当于负的对数似然(up to terms independent of the model parameters):
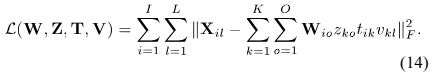
用上述结果推导算法更新法则,通过优化模型参数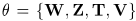 ,隐变量:
,隐变量:
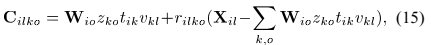
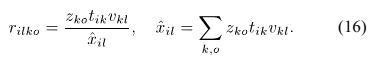
参数满足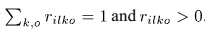
隐变量满足:
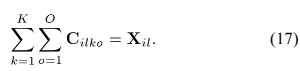
基于参考文献[19]中的技术,公式(14)中的负对数似然可以通过一个结合隐变量的辅助函数最小化。辅助函数定义为:
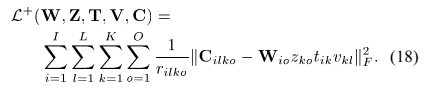
根据[19],(18)中似然函数可以被当作(14)的间接优化,这是因为辅助函数拥有以下性质:
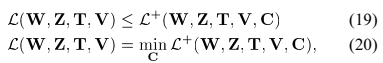
2)非负参数的更新算法
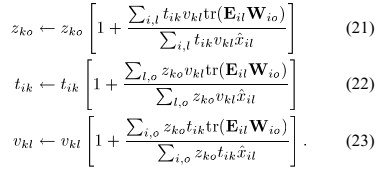
其中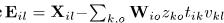 是模型误差。
是模型误差。
3)SCM模型参数的更新算法
DOA kernels 的优化需要不同的更新框架,所以需要保留预先定义的kernels的相位差,同时更新相对幅度差。为了估计DOA kernels,首先得到复值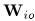 的更新,但是限制其幅值的更新。
的更新,但是限制其幅值的更新。
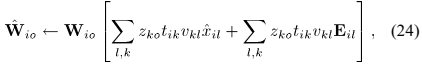
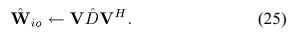
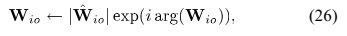
4)参数尺度
限制DOA kernels的尺度如下:

通过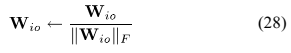 得到。
得到。

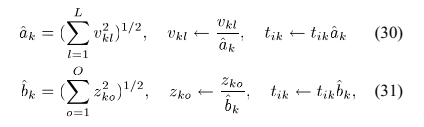
5)算法实现
- 用0到1之间的均匀分布随机变量初始化
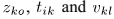 。
。 - 用公式(7)初始化
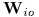 ,并用公式(28)进行scaling。
,并用公式(28)进行scaling。 - 用公式(16)重新计算幅值模型
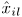 。
。 - 用公式(22)更新
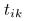 。
。 - 用公式(16)重新计算幅值模型。
- 用公式(23)更新
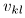 。
。 - 将
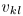 缩放到统一L2范数,如同公式(30)中对
缩放到统一L2范数,如同公式(30)中对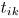 进行补偿和重新缩放。
进行补偿和重新缩放。 -
用公式(16)重新计算幅值模型
。 -
用公式(21)更新
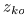 。
。 -
将
缩放到L2范数,如同公式(31)中对进行补偿和重新缩放。 -
用公式(16)重新计算幅值模型
。 -
用公式(24)计算
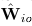 并且用公式(25)限制其半正定。
并且用公式(25)限制其半正定。 -
用公式(26)更新
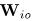 并根据公式(28)对其进行缩放。
并根据公式(28)对其进行缩放。
The algorithm is implemented by repeating steps 3-13 for a fixed amount of iterations or until the parameter updates converge.
tips
1、A well known BSS approach is the independent component analysis (ICA) applied separately at each frequency of a short-time Fourier transformed (STFT) array input.
2、NMF is applied in the magnitude spectrogram domain and it finds an approximation of the mixture spectrogram using a linear combination of components that have a fixed spectrum and time-dependent gain.
3、在NMF分离框架中,每个源信号的空间特征可以用其在每个STFT频率仓的空间协方差矩阵SCM进行建模。这种extension可被称为complex-value NMF。这个SCM表明采集通道间,不同幅值和相位差的混合信号不依赖于源信号的绝对相位。此外,采用了基于magnitude panning of sources 的空间信息的非负张量分解也被提出。
参考文献
[1] Nikunen J, Virtanen T. Direction of Arrival Based Spatial Covariance Model for Blind Sound Source Separation[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2014, 22(3):727-739.
[2] Orti J J C, Nikunen J, Virtanen T, et al. Multichannel Blind Sound Source Separation Using Spatial Covariance Model With Level and Time Differences and Nonnegative Matrix Factorization[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2018, PP(99):1-1.
