【album】Python使用笔记
描述
- python是一种解释性文件,代码要通过解释器解释运行。python解释器就是python.exe这个程序。
- pip也是一个pip.exe的程序,是用来管理python的第三方库。
- 有两种执行方式:脚本执行 & 交互式执行。前者是 cmd 中用 python 文件名 来运行(Linux常用);交互式运行就是在解释器里面运行的方式。
- Python解释器同一时间只能运行一个程序的一条语句。 标准的交互Python解释器可以在命令行中通过键入 python 命令打开。
GPU
编程
方法
参考【那少年和狗】的博客【Python中@staticmethod和@classmethod的作用和区别】:
Python有3种方法,静态方法(staticmethod),类方法(classmethod)和实例方法。
对于一般的函数foo(x),它跟类和类的实例没有任何关系,直接调用foo(x)即可。
在类A里面的实例方法foo(self, x),第一个参数是self,我们需要有一个A的实例,才可以调用这个函数。
当我们需要和类直接进行交互,而不需要和实例进行交互时,类方法是最好的选择。类方法与实例方法类似,但是传递的不是类的实例,而是类本身,第一个参数是cls。我们可以用类的实例调用类方法,也可以直接用类名来调用。
静态方法类似普通方法,参数里面不用self。这些方法和类相关,但是又不需要类和实例中的任何信息、属性等等。如果把这些方法写到类外面,这样就把和类相关的代码分散到类外,使得之后对于代码的理解和维护都是巨大的障碍。而静态方法就是用来解决这一类问题的。
比如我们检查是否开启了日志功能,这个和类相关,但是跟类的属性和实例都没有关系。
多线程
进程(process)和线程(thread)是操作系统的基本概念,但是它们比较抽象,不容易掌握。关于多进程和多线程,教科书上最经典的一句话是“进程是资源分配的最小单位,线程是CPU调度的最小单位”。 线程是程序中一个单一的顺序控制流程。进程内一个相对独立的、可调度的执行单元,是系统独立调度和分派CPU的基本单位指运行中的程序的调度单位。在单个程序中同时运行多个线程完成不同的工作,称为多线程。
文件
从本质上讲,文件是用于存储数据的连续字节集。这些数据以特定格式组织,可以是任何像文本文件一样简单的数据,也可以像程序可执行文件一样复杂。最后,这些字节文件被翻译成二进制文件1,0以便计算机更容易处理。
大多数现代文件系统上的文件由三个主要部分组成:
- 标题(Header):有关文件内容的元数据(文件名,大小,类型等)
- 数据(Data): 由创建者或编辑者编写的文件内容
- 文件结束(EOF):表示文件结尾的特殊字符
读取
excel
可以使用pandas读取。参考:【pandas】使用笔记 - 博客园 (cnblogs.com)。
【报错:not supported】【参考:https://blog.csdn.net/weixin_44073728/article/details/111054157】
pickle
pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。它能够实现任意对象与文本之间的相互转化,也可以实现任意对象与二进制之间的相互转化。
pickle模块只能在python中使用,python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化,
参考:
【Python pickle模块:实现Python对象的持久化存储】
【CSDN博客】【详解python中pickle模块的一些函数】
json
.pth
pytorch中的模型文件 .pth 文件,是一个包含 四组 “key-value”的字典,类型分别如下:
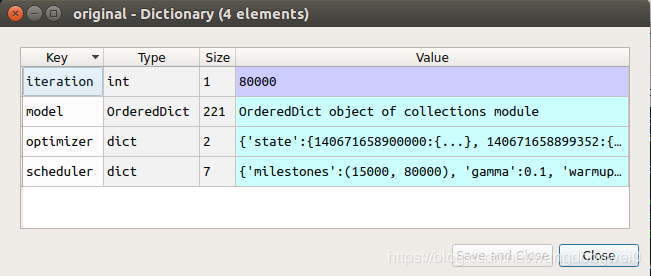
torch.save / torch.load
IPython / Jupyter
自省[?]
在变量前后使用问号?,可以显示对象的信息。
?还有一个用途, 就是像Unix或Windows命令行一样搜索IPython的命名空间,与通配符结合可以匹配所有的名字。
魔术命令
IPython中特殊的命令(Python中没有)被称作“魔术”命令。这些命令可以使普通任务更便捷, 更容易控制IPython系统。魔术命令是在指令前添加百分号%前缀。例如,可以用 %timeit 测量任何Python语句的执行时间。
魔术命令可以被看做IPython中运行的命令行。许多魔术命令有“命令行”选项,可以通过?符号查看。
可以用 %run 命令运行所有的Python程序。 【ipynb脚本中】
文件解压
基本数据类型
python 与 C 语言和 Java 语言的一点不同,表现在它的变量不需要声明变量类型,这是因为像 C 语言和 Java 语言来说,它们是静态的,而 python 是动态的,变量的类型由赋予它的值来决定。
Python3 废除了 long 类型,将 0 和 1 独立出来组成判断对错的 Bool 型,即 0 和 1 可以用来判断 flase 和 true。但是根本上并没有修改原则。这里的 Bool 型依然是 int 型的一部分,所以依然能当做数字参与运算,所以 Python3 里的 Bool 型是 int 型的一个特例而不是一个独立的类型。
参考教程[2],Python3 的六个标准数据类型:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
number
Python3 支持 int、float、bool、complex(复数)。
在Python 3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。像大多数语言一样,数值类型的赋值和计算都是很直观的。
内置的 type() 函数可以用来查询变量所指的对象类型。
| >>> a, b, c, d = 20, 5.5, True, 4+3j >>> print(type(a), type(b), type(c), type(d)) <class 'int'> <class 'float'> <class 'bool'> <class 'complex'> |
在 Python2 中是没有布尔型的,它用数字 0 表示 False,用 1 表示 True。到 Python3 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0,它们可以和数字相加。
- 数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数。在混合计算时,Python会把整型转换成为浮点数。
String
Python中的字符串用单引号 ' 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符。索引值以 0 为开始值,-1 为从末尾的开始位置。(Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。)
加号 + 是字符串的连接符, 星号 * 表示复制当前字符串,紧跟的数字为复制的次数。
与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如word[0] = 'm'会导致错误。
List
List(列表) 是 Python 中使用最频繁的数据类型。列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。Python 列表截取可以接收第三个参数,参数作用是截取的步长。
加号 + 是列表连接运算符,星号 * 是重复操作。索引值以 0 为开始值,-1 为从末尾的开始位置。
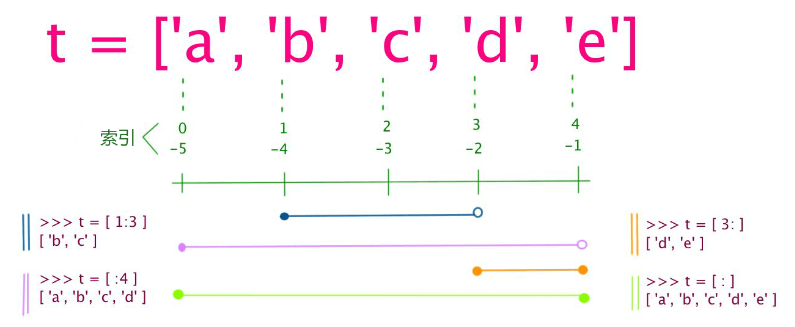
与Python字符串不一样的是,列表中的元素是可以改变的。List 内置了有很多方法,例如 append()、pop() 等等。
Tuple
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。 元组中的元素类型也可以不相同。
元组与字符串类似,可以被索引且下标索引从0开始,-1 为从末尾开始的位置。也可以进行截取。其实,可以把字符串看作一种特殊的元组。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。string、list 和 tuple 都属于 sequence(序列)。
一般来说,函数的返回值一般为一个。而函数返回多个值的时候,是以元组的方式返回的。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
- tup1 = () # 空元组
- tup2 = (20,) # 一个元素,需要在元素后添加逗号
Set
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
基本功能是进行成员关系测试和删除重复元素。列表和元组不会把相同的值合并,但是集合会把相同的合并。
- 无序:集合是无序的,所以不支持索引;字典同样也是无序的,但由于其元素是由键(key)和值(value)两个属性组成的键值对,可以通过键(key)来进行索引
- 元素唯一性:集合是无重复元素的序列,会自动去除重复元素;字典因为其key唯一性,所以也不会出现相同元素
Dictionary
字典(dictionary)是Python中另一个非常有用的内置数据类型。
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。键(key)必须使用不可变类型。在同一个字典中,键(key)必须是唯一的。
python中的字典是使用了一个称为散列表(hash table)的算法,其特点就是:不管字典中有多少项,in操作符花费的时间都差不多。如果把一个字典对象作为for的迭代对象,那么这个操作将会遍历字典的键。
微积分
参考:https://www.cnblogs.com/NaughtyBaby/p/5419043.html
运算符优先级
| 运算符说明 | Python运算符 | 优先级 |
|---|---|---|
| 小括号 | () | 20 |
| 索引运算符 | x[index] 或 x[index:index2[:index3]] | 18、19 |
| 属性访问 | x.attrbute | 17 |
| 乘方 | ** | 16 |
| 按位取反 | ~ | 15 |
| 符号运算符 | +(正号)或 -(负号) | 14 |
| 乘、除 | *、/、//、% | 13 |
| 加、减 | +、- | 12 |
| 位移 | >>、<< | 11 |
| 按位与 | & | 10 |
| 按位异或 | ^ | 9 |
| 按位或 | | | 8 |
| 比较运算符 | ==、!=、>、>=、<、<= | 7 |
| is 运算符 | is、is not | 6 |
| in 运算符 | in、not in | 5 |
| 逻辑非 | not | 4 |
| 逻辑与 | and | 3 |
| 逻辑或 | or | 2 |
虽然 Python 运算符存在优先级的关系,但并不推荐过度依赖运算符的优先级,因为这会导致程序的可读性降低。尽量用()控制运算速度。
[1]中展示了更详细的优先级由低到高排列的运算符表格。
参考
[1] https://blog.csdn.net/qq_41573234/article/details/81351693
[2] https://www.runoob.com/python3/python3-data-type.html
[3] 部分参考《利用 Python 进行数据分析 · 第 2 版 》
