【album】语音分离技术
留坑
概述
- 微信公众号-NatureNLP于2020-08-15如何分离不同说话人的语音信号?深度学习单通道语音分离方法最新综述
- 微信公众号-机器学习算法工程师:入门语音分离,从鸡尾酒问题开始!
语音分离(Speech Separation),属于盲源分离问题,来自于“鸡尾酒会问题”。目的是从采集的观测信号(包括目标语音和干扰语音/噪声)中分离出目标语音。涉及到信号重构问题。
人类的听觉系统是除了视觉系统以外最重要的感觉系统,具有多种听觉功能,比如分辨声音的方位和距离,感觉声音的远近变化,选择性聆听感兴趣的声音等。其中,选择性聆听就是人类听觉能够在嘈杂环境中正常交流的根本原因。1953年,Colin Cherry提出了著名的”鸡尾酒会”问题:在嘈杂的室内环境中,比如在鸡尾酒会中,同时存在着许多不同的声源:多个人同时说话的声音、餐具的碰撞声、音乐声以及这些声音经墙壁和室内的物体反射所产生的反射声等。在声波的传递过程中,不同声源所发出的声波之间(不同人说话的声音以及其他物体振动发出的声音)以及直达声和反射声之间会在传播介质(通常是空气)中相叠加而 形成复杂的混合声波。因此,在到达听者外耳道的混合声波中已经不存在独立的与各个声源相对应的声波了。然而,在这种声学环境下,听者却能够在相当的程度上听懂所注意的目标语句。
基于深度学习的方法及相关基础概述,可参考以下内容:
- 雷锋网分享/搜狗研究员讲解基于深度学习的语音分离
- 腾讯云/大象声科分享如何利用深度学习实现单通道语音分离?
TasNet
TasNet(Time-domain Audio Separation Network)是时域的方法(直接输入混合语音,不经过STFT等变化得到声音特征),由编码器、分离网络、解码组成,与频域方法相比,编码过程不是固定的而是网络学到的(论文中认为对于语音而言STFT并不一定是最佳编码方式,有两点证实了此观点,论文中对编码器输出增加非负的约束会使模型变差,对编解码器增加互逆的关联约束使模型变差,即同一信号经过编码器再经过解码器得到同一信号),通过分离网络得到两个mask,学到的mask与编码器输出相乘再经过解码器得分离的声音,训练过程使用前文提到的PIT方法,编解码器都是一维卷积(相当于全连接层线性变换),实验结果展示幅度和相位信息都被编码器学习到了特征之中。
编码器Encoder实质上是一个线性变换,将16维输入信号变为512维,这个变换过程相当于做匹配滤波,Encoder的512维的权重就是匹配滤波的权重。而解码器是与编码器相反的过程,将编码器的512维的输出和分离网络输出的mask的点乘结果作为输入,做线性变换后得到分离的语音信号。在训练过程中,编码器和解码器不一定是可逆的,不需要对编码器和解码器做额外要求。
TasNet的分离网络与WaveNet相似,采用多层的CNN网络,每一层都是卷积操作,涉及到的卷积主要包括因果卷积和空洞卷积(可以增大感受野,由于语音往往较长,空洞卷积和残差连接是标配)。最后一层最后一个输出经过sigmoid函数得到mask(0-1)矩阵,论文中认为对于输出的mask不需要softmax来归一化使得输出和为1,模型可以自己学到,另外sigmoid也不是必须的,生成的mask可以为负值,不用加特殊限制。
TasNet核心工作:提出使用时域音频分离网络,即编码器-解码器框架直接在时域对信号建模,并在非负编码器输出上执行声源分离。
| STFT缺点 | TasNet特点 |
|---|---|
| 1. 提出傅里叶分解并不一定是最优的语音分离信号变换 | 1. N个非负加权基础信号表示混合语音波形 |
| 2. STFT将信号转换为复数域,但不能很好的处理相位谱 | 2. 基础信号的权重来自于编码器输出,基础信号即解码器的滤波器 |
| 3. 频谱有效分率需要高频率高分辨率,否则会产生时延 | 3. 估计权重(非负)可以表示为每个声源对混合权重贡献的掩模,类似于STFT中的T-F掩模 |
| 4. 解码器学习后重建声源波形 |
可以看出,借鉴了非负矩阵分解NMF的思想。
Conv-TasNet
- IEEE/ACM Transactions on Audio, Speech and Language Processing [SCI]录用:Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation
- CSDN博客:【论文笔记之Conv-TasNet】: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation
- 知乎文章:TasNet & Conv-TasNet
Conv-TasNet是哥大的一名中国博士生Yi Luo提出的全卷积时域音频分离网络,一种端到端时域语音分离的深度学习框架。该框架解决了STFT域语音分离的缺点,包括相位和幅度的解耦,用于分离的混合音频的次优表示以及计算STFT的高延迟。
Conv-TasNet使用线性编码器来生成语音波形的表示形式,该波形针对分离单个音轨进行了优化。音轨的分离则是通过将一组加权函数(mask)用于编码器输出来实现,即将一组加权函数(掩码)应用于编码器的输出来实现说话人分离。最后使用线性解码器得到分离出的语音波形。
由卷积的一维扩张卷积块组成的时域卷积网络(TCN)计算mask,使网络可以对语音信号的长期依赖性进行建模,同时保持较小的模型尺寸。
文章所提出的Conv-TasNet系统在分离两个和三个说话人方面明显优于以前的时频掩蔽方法。此外,Conv-TasNet在两个说话人的语音分离中超过了几个理想的时频幅度掩码,这个结论是通过客观失真测量和听众的主观质量评估得出的。最后,Conv-TasNet具有较小的模型尺寸以及较短的最小延迟,这使其成为离线和实时语音分离的合适解决方案。
尽管TasNet在因果实现和非因果实现中都优于以前的时频语音分离方法,但原始TasNet将深度长短时记忆(LSTM)网络作为分离模块会大大限制其适用性。第一,在编码器中选择较小的核大小(即波形段的长度)会增加编码器输出的长度,这使得LSTM的训练变得难以管理。第二,深度LSTM网络中的大量参数显著增加了其计算成本,并限制了其在低资源、低功耗平台(例如可穿戴式听力设备)中的适用性。文章将说明的第三个问题是LSTM网络在时间上的长期依赖性,这经常导致分离准确性不一致,例如,当更改了混合信号的起点时。为了减轻TasNet的局限性,作者提出了全卷积TasNet(Conv-TasNet),该网络在处理的所有阶段均仅使用卷积层。受时间卷积网络(TCN)模型成功的启发,Conv-TasNet使用堆叠的膨胀一维卷积块代替深层LSTM网络进行分离。卷积的使用允许对连续帧或片段进行并行处理,从而大大加快了分离过程,并且还大大减小了模型大小。为了进一步减少参数量和计算成本,作者用深度可分离卷积替换了原始卷积运算。通过这些修改,Conv-TasNet的因果和非因果实现相比LSTM-TasNet在分离准确性上有很大提升。此外,Conv-TasNet的分离准确性在信噪比(SDR)和主观(平均意见得分,MOS)度量方面都超过了理想时频幅度掩码的性能,包括理想二值掩码(IBM)、理想比例掩码(IRM)和类似于维纳滤波器的掩码(WFM)。
该框架解决了STFT域语音分离的缺点,包括相位和幅度的解耦,用于分离的混合音频的次优表示以及计算STFT的高延迟。通过使用卷积编码器-解码器体系结构替代STFT来实现改进。 Conv-TasNet中的分离是使用时间卷积网络(TCN)架构以及深度可分离的卷积运算来完成的,以应对深层LSTM网络的挑战。评估表明,即使使用目标说话人的理想时频掩码,Conv-TasNet的性能也远胜于STFT语音分离系统。此外,Conv-TasNet具有更小的模型尺寸和更短的最小延迟,这使其适用于低资源,低延迟的应用程序。
全卷积时域音频分离网络(Conv-TasNet)由三个处理阶段组成,如下图所示:

上述流程图分为:编码器,分离和解码器。首先,编码器模块将混合信号的短片段转换为中间特征空间中的相应表示。然后,使用该表示来估计每个源的乘法函数(掩码)。 最后,解码器模块通过转换掩蔽之后的编码器特征来重建源波形。
Conv-TasNet的一些局限性必须加以解决,然后才能实现,包括对说话人的长期跟踪以及对嘈杂和混响环境的泛化。由于Conv-TasNet使用固定的时间上下文长度,因此对单个说话者的长期跟踪可能会失败,尤其是在混合音频中有较长的停顿时。
TCN
时序/时间卷积网络(Temporal convolutional network,TCN)
FCN与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入,采用卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到与输入相同的尺寸,再进行预测。
TCN 的卷积层结合了扩张卷积与因果卷积两种结构。使用因果卷积的目的是为了保证前面时间步的预测不会使用未来的信息,因为时间步 t 的输出只会根据 t-1 及之前时间步上的卷积运算得出。
可以看出,TCN的卷积和普通的一维卷积非常类似,只不过最大的不同是用了扩张卷积,随着层数越多,卷积窗口越大,卷积窗口中的空孔会越多。
值得一提的是在 TCN 的残差模块内有两层扩张卷积和 ReLU 非线性函数,且卷积核的权重都经过了权重归一化。此外TCN 在残差模块内的每个空洞卷积后都添加了 Dropout 以实现正则化。
论文中跳层连接时直接将下层的特征图跳层连接到上层,这样的话对应的通道数channel不一致,所以不能直接做加和操作。为了两个层加和时特征图数量,即通道数数量相同,作者通过用1×1卷积进行元素合并来保证两个张量的形状相同。
总结,时间卷积网络是:同时用到一维因果卷积和扩张卷积作为标准卷积层,并将每两个这样的卷积层与恒等映射可以封装为一个残差模块(包含了relu函数)。再由残差模块堆叠起深度网络,并在最后几层使用全卷积层代替全连接层。
| 优点 | 缺点 |
|---|---|
| (1)并行性。当给定一个句子时,TCN可以将句子并行的处理,而不需要像RNN那样顺序的处理。 | (1)TCN 在迁移学习方面可能没有那么强的适应能力。在不同的领域,模型预测所需要的历史信息量可能是不同的。因此,在将一个模型从一个对记忆信息需求量少的问题迁移到一个需要更长记忆的问题上时,TCN 可能会表现得很差,因为其感受野不够大。 |
| (2)灵活的感受野。TCN的感受野的大小受层数、卷积核大小、扩张系数等决定。可以根据不同的任务不同的特性灵活定制。 | (2)论文中描述的TCN是一种单向的结构,在ASR/TTS等任务上,纯单向的结构相当有用的。但文本中大多使用双向的结构,当然将TCN也很容易扩展成双向的结构,不使用因果卷积,使用传统的卷积结构即可。 |
| (3)稳定的梯度。RNN经常存在梯度消失和梯度爆炸的问题,这主要是由不同时间段上共用参数导致的,和传统卷积神经网络一样,TCN不太存在梯度消失和爆炸问题。 | (3)TCN是CNN的变种,虽然使用扩展卷积可以扩大感受野,但是仍然受到限制,相比于Transformer那种可以任意长度的相关信息都可以抓取到的特性还是差了点。 |
| (4)内存更低。RNN在使用时需要将每步的信息都保存下来,这会占据大量的内存,TCN在一层里面卷积核是共享的,内存使用更低。 |
Demucs
Spleeter等基于频域的分离技术框架,由于要计算频谱,存在着延迟较长的缺点。虽然之前也有一些对声音波形进行处理的方法,但实际效果与频域处理方法相差甚远。
Facebook AI研究院提供了两种波形域方法的PyTorch实现,分别是Demucs和Conv-Tasnet,而且测试结果均优于其他常见的频域方法。其中Demucs是Facebook人工智能研究院在2019年9月提出的弱监督训练模型,基于受Wave-U-Net和SING启发的U-Net卷积架构。
与之前的Wave-U-Net相比,Demucs的创新之处在于编码器和解码器中的GLU激活函数,以及其中的双向LSTM和倍增的通道数量。
The original Demucs architecture (Défossez et al., 2019) is a U-Net (Ronneberger et al., 2015) encoder/decoder structure.
Hybrid-Demucs
于2021年提出。ISMIR 2021 MDX Workshop. authors introduced a number of architectural changes to the Demucs architecture that greatly improved the quality of source separation for music.
Hybrid Spectrogram and Waveform Source Separation
Hybrid Demucs extends the original architecture with multi-domain analysis and prediction capabilities. The model is composed of a temporal branch, a spectral branch, and shared layers. The temporal branch takes the input waveform and process it like the standard Demucs. It contains 5 layers, which are going to reduce the number of time steps by a factor of 45 = 1024. Compared with the original architecture, all ReLU activations are replaced by Gaussian Error Linear Units (GELU) (Hendrycks and Gimpel, 2016).
Spleeter
- CSDN博客:Spleeter工具简单分析
- 微信公众号-雷岳甡@青榴实验室:伴奏提取福音,人声分离框架Spleeter (qq.com)
伴奏提取神器。仅支持64位计算机系统。基于python开发。
法国音乐流媒体公司Deezer开源的音轨分离软件spleeter,该项目于2019年年中左右发布于github(源地址deezer/spleeter),属于代码交互的机器学习软件,能将音乐的人声和各种乐器声分离,最多支持分离成人声、鼓、贝斯、钢琴、其他共5部分(但实践中通常建议只分为2轨,即伴奏+人声)。
从功能上,目前预训练模型为2stems(分离出人声/伴奏),4stems(分离出人声/伴奏/鼓/贝斯/其他),5stems(人声/鼓/贝斯/钢琴/其他)。性能上,按照spleeter的官网解释,4stems在使用GPU加速的情况下可以达到100s长度的音乐1s分离完成。从效果上来看,spleeter的各项指标均优于目前的其他开源模型。
spleeter基于频域进行音轨分离。其网络结构中,每条音轨对应着一个unet网络结构。2stems对应着两个unet,4stems对应4个unet网络。unet的网络输入为音频幅度谱,输出为某条音轨的幅度谱。训练时损失函数为计算出音轨的幅度谱与标准幅度谱的L1距离。预测时稍有不同,通过多条音轨的幅度谱计算出每条音轨占据输入音频的能量比例,即每条音轨的mask,通过输入音频频谱乘以mask得到各个音轨的输出频谱,计算得到wav。
spleeter训练时的一组数据为(音乐,伴奏,人声),要求三者在时间轴上尽量完全一致,提取三者频谱并计算出幅度谱。将音乐幅度谱分别输入到人声U-Net和伴奏U-Net中,得到预测的人声U-Net和伴奏U-Net,分别计算预测结果和标准结果的距离并取均值。其中伴奏U-Net和人声U-Net内部参数会随着数据输入不断更新。
预测过程没有标准的人声和伴奏,只有混合后的音乐。当预测出伴奏和人声的幅度谱之后,Spleeter将两者分别进行平方,得到人声能量Engv和伴奏能量Enga,然后使用Maskv = Engv/( Engv +Enga)计算出每个时刻人声在各个频段音乐的占比,同时使用Maska= Enga /( Engv +Enga)计算出每个时刻伴奏在各个频段音乐的占比。利用输入的音乐频谱分别乘以Maskv和Maska得到人声和伴奏频谱,最后使用ISTFT得到人声和伴奏的WAV音频文件。
团子
- 官网:人工智能提取伴奏人声
团子主要由基于MIT协议的开源项目Spleeter制作的,同时在其之上增加了一些功能魔改使效率与音质得到提升。团子是一款在线的音频分离软件,团子开放平台也因此诞生,其目标是使第三方开发者和项目可以快速的对接、使用团子的服务。
团子是基于深度神经网络(DNN)实现的音轨分离所诞生的人工智能,它使用Python/Tensorflow开发。
Speakerfilter-Pro
2020年投递至ICASSP 2021。
This paper proposes a target speaker extractor, where WaveUNet, CRN, and BGRU-GCNN are used for time-domain feature enhancer, speech separator, and speaker feature extractor, respectively. By leveraging the time-domain modeling ability of WaveUNet and the frequency-domain modeling ability of the CRN, the target speaker can be tracked well.
SpEx
SpEx+: A Complete Time Domain Speaker Extraction Network (researchgate.net)
SpEx+:一个完整的时域说话人提取网络 - 知乎 (zhihu.com)
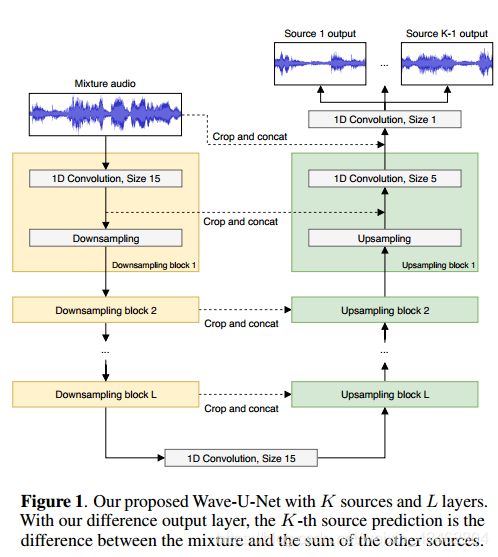
Wave-U-Net
[1806.03185] Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation (arxiv.org)
一种用于端到端音频分离的多尺度神经网络-CSDN博客
2018年提出的一种用于端到端音频源分离的多尺度神经网络,时域。
Wave-U-Net,这是对U-Net体系结构的一维调整,它可以在时域中直接分离源,并且可以考虑大的时间上下文。