数据驱动
数据流程: 数据采集-数据处理-数据传输-数据存储
数据管理
建立数据的meta信息
1.假如传感器的配置--配置的元数据
2.标定的元数据-版本管理-gitlab或者github
3.数据存储的格式以及版本
4.数据可视化以及数据检索-数据可视化主要是为了方便调试和解决问题
数据处理流程
cyber的数据流程可以分为6个过程。
Node节点中的Writer往通道里面写数据。
通道中的Transmitter发布消息,通道中的Receiver订阅消息。
Receiver接收到消息之后,触发回调,触发DataDispather进行消息分发。
DataDispather接收到消息后,把消息放入CacheBuffer,并且触发Notifier,通知对应的DataVisitor处理消息。
DataVisitor把数据从CacheBuffer中读出,并且进行融合,然后通过notifier_唤醒对应的协程。
协程执行对应的注册回调函数,进行数据处理,处理完成之后接着进入睡眠状态
数据解析
1.消息的持久化
01.序列化和反序列化
02.消息索引
2. 序列化和反序列化
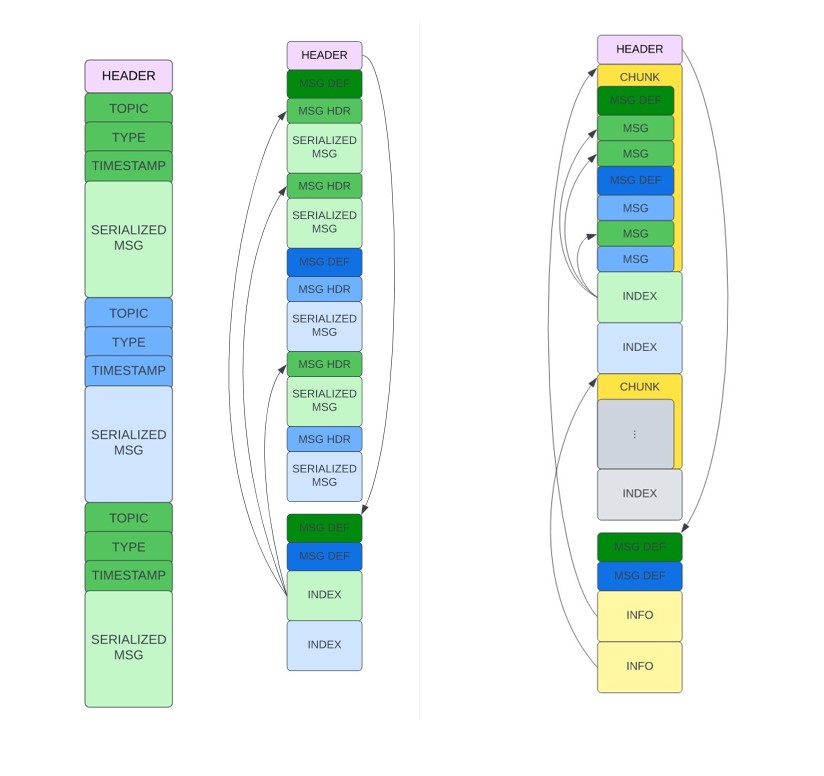
Rosbag的序列化和反序列化是自己实现的,ros是单个消息序列化,apollo是整个chunk序列化
apollo record则采用了protobuf来进行序列化和反序列化
3.消息索引
4.功能
Bag header 头信息放在文件首部,
Chunk info 块的索引和消息元信息的索引都是放在文件的末尾-2个统计record都会保存在文件末尾。
Index data
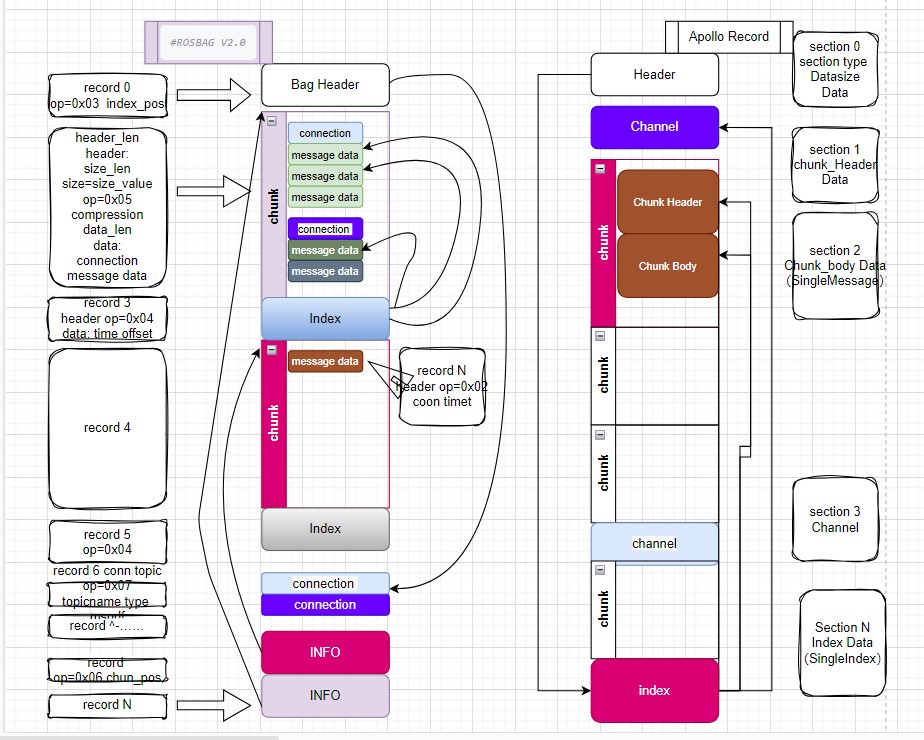
Rosbag
rosbag storage format
Rosbag 文件由许多的record组成
每个record由header和data组成, header和data,还需要保存header_len和data_len
信息头(Headers)。每个记录头包含一系列 name=value 字段 Op 码所有的信息头必须包含Op码字段
record0 Bag header 主要存放bag包整体的信息,必须是第一个 record
record1:
Message data 块的结构之一,消息序列化之后以二进制存储,
通过Connection获取消息格式后进行反序列化
Connection 块的结构之一,存放信息的格式信息,有了消息的格式,才能解析消息
Chunk 主要的数据结构,可以被压缩,可以理解为把N个消息打包为一个块(Chunk) 一个块中可能有多种不同的消息
Chunk info 块的结构之一,主要描述块的信息,例如消息的起始和结束时间等
Index data 索引数据,因为一个块比较大,索引消息在块中的位置
index_pos index data 一个消息对应一个index
reflection:bag包中的Connection包含了数据类型和格式,而每个Message data中可以找到Connection,从而找到消息类型,进行解析
a time-based index of all the messages at the end of the file.
the message definitions
introduced an internal partitioning called a "Chunk."
Chunks are blocks of messages, usually grouped by time or message-type and optionally compressed
includes a sub-index describing the messages it contains
the end of the bag now had a collection of Chunk Info records with each chunk's location
图例
Record
Record文件由许多的 Section 组成
Header
Section Type: ChunkHeader ChunkBoady RecordInfo Index Channel
Section 0:第一个Section 0为HEADER类型。Header中指明了索引区Index的位置
Section 1:
Index Data 包含一个SingleIndex类型数组,作为Section的索引,保存了Channel、ChunkHeader、ChunkBody三种Section的位置和简要数据。
record.proto中并不存在Chunk这个结构,而是用ChunkHeader和ChunkBody两部分来表示。
序列化:
每个Section的数据部分通过protobuf提供的函数进行序列化。
apollo/cyber/record/file/record_file_writer.h 文件中
反序列化:读取record文件时,需要将每个Section的数据部分通过protobuf提供的函数进行反序列化。
apollo/cyber/record/file/record_file_reader.h 文件中
protobuf的原理实际上是根据用户定义好的proto文件,来对消息进行解析,实际使用的时候,
protobuf采用了descriptor来描述proto文件,
而descriptor_pb则是proto文件的proto,descriptor_pb只能描述它自己,但并没有包含它引用的消息的格式
我们就可以知道消息的结构,有哪些字段,也就能够解析消息了
思路:
自身的消息描述descriptor和它依赖的所有消息的descriptor,都放入descriptor_pool,之后就可以根据消息类型来创建消息了
apollo/cyber/proto/record.proto
apollo/cyber/record/file/section.h
录制文件可以按时间分段也可以按大小分段,
文件cyber/record/record_writer.cc中的RecordWriter::SplitOutfile负责文件切片段。
思路:
通过 时序数据库InfluxDB 来对传感器数据进行管理
Willow Garage由传奇程序员Scott Hassan(他是Google最初代码的编写者)创立,是一家机器人研发与孵化公司。
2006年,Hassan创立了Willow Garage
它开发了机器人开源操作系统软件ROS、标准机器人PR2和TurtleBot,为机器人行业做出了巨大的贡献,
直到2014年它关闭了所有业务。
SDK 需要能够轻松地将所有数据转换为 Rerun 基于 Arrow 的格式
参考
https://wiki.ros.org/Bags/Format/2.0
apollo介绍之Cyber框架(十一) https://zhuanlan.zhihu.com/p/115046708
Rosbag格式分析 https://zhuanlan.zhihu.com/p/494474804
Apollo record文件格式 https://blog.csdn.net/weixin_43739110/article/details/121852346
ROS Bags/Format/2.0 中文图解 https://zhuanlan.zhihu.com/p/87213444
From the Evolution of Rosbag to the Future of AI Tooling https://www.rerun.io/blog/rosbag
https://theorg.com/org/rerun/org-chart
cyber_recorder报文录制简介 https://cloud.tencent.com/developer/article/1796672
一张图对比Rosbag和cyber record https://zhuanlan.zhihu.com/p/496684194

