


语义分割
图像分割:根据像素的特征,对像素进行分类。
自编码器:(auto endcoder)
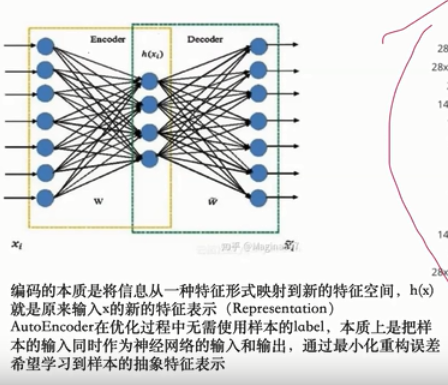
encoder和decoder之间可以是一些典型的网络
对于编解码的理解:编码过程通过池化层逐渐减少位置信息、抽取抽象特征;译码过程逐渐恢复位置信息。一般译码与编码间有直接的连接。
总体了解:
语义分割的发展:
https://blog.csdn.net/u013580397/article/details/78508392
语义开源的项目以及各模型的论文:
https://github.com/mrgloom/awesome-semantic-segmentation
FCN
介绍了FCN,空洞卷积和 crf在图像分割上的优化,这篇博客很详细:
https://www.cnblogs.com/jerrybaby/p/9293419.html
Unet的理解:
(1)收缩路径(编码部分)其实就是一个常规的卷积网络,它包含重复的2个3x3卷积,紧接着是一个RELU,一个max pooling(步长为2),用来降采样,每次降采样我们都将feature channel扩大一倍,从64、128、256、512、1024。两个3x3的卷积核之后跟一个2x2的最大化池化层,缩小图片的分辨率。
(2)扩展路径(解码部分)包含一个上采样(2x2上卷积),将图像大小扩大一倍,然后再使用普通的3x3卷积核,再将通道数feature channel缩小一倍,从1024、512、256、128、64
(3)编解码的feature map不对称:因为所有的卷积过程都是没有加pad的,这样就会导致每做一次卷积,特征的长宽就会减少两个像素,最后网络的输出和输入大小不一样。因为u-net作者只有30张影像,为了数据增强没有加pad.Unet适用少样本
(4)特征融合:https://zhuanlan.zhihu.com/p/31428783
参考:https://blog.csdn.net/qq_27825451/article/details/89470972
提升:Unet相比FCN只是借鉴方式不同,FCN通过add的方法借鉴了之前特征提取的信息,来给上采样提供更多的辅助信息,8s较32s效果提升很多,但是依然比较模糊,对图像的细节不敏感。Unet通过concat,特征融合方式是“拼接“”,U-net采用将特征在channel维度拼接在一起,形成更厚的channel。
