
e2e代码分析
conll-2012-train.v4.tar.gz
conll-2012-development.v4.tar.gz
conll-2012-test-key.tar.gz
conll-2012-test-official.v9.tar.gz
conll-2012-scripts.v3.tar.gz(把ske文件转换成conll文件的脚本)
reference-coreference-scorers.v8.01.tar.gz。
reference-coreference-scorers 移到了conll-2012/scorer
数据:dev.english.v4_gold_conll
train.english.v4_gold_conll
test.english.v4_gold_conll
minimize_partition:主要就是处理数据集:输入是conll文件,输出是.jsonline文件
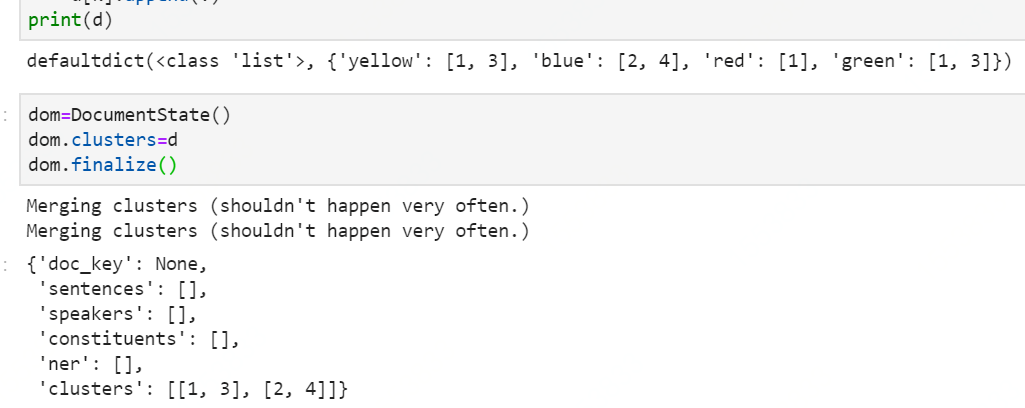
dom.finalize():主要是把clusters里面的val统一。
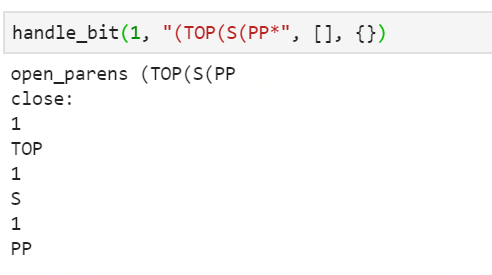
hanld_bit:##stack ,在遇见(的时候弹入,(1,top),(1,s),(1,pp),在)的时候弹出。
labels里的english_const_labels里面放的就是这些parse拆分之后的,ner放的就是ner
stats里面放的是共指链的个数,mentions 的个数。
get_char_vocab:获得各个数据集的词典:char_vocab.english.txt
filter_embedding.py : 输入是glove.840.txt,train.jsonline test.jsonline 输出是glove.840.filter,主要是对词向量表针对数据集进行一定的过滤,抽出需要的词向量。
elmo_modul的使用:http://quabr.com/53570918/paragraph-embedding-with-elmo

cach_elmo:就是对应地获得每一句的词向量的表示(但是elmo是基于charater的所以论文叫做charater embeding),其实是基于字向量的embedding。
["elmo"]这个只是一个名字吗?为什么这里做了三次。

以上都是setup_training的里面的,是生成一些后续需要的文件的。
接下来的是train.py里面的:
tensorize_example:train_examples是一个list,这个list的每一行就是一个string
给每一个共指链一个编号,

之后的一系列都是在求一些值,还是类似于在处理数据,注意char_index
(tokens, context_word_emb, head_word_emb, lm_emb, char_index, text_len, speaker_ids, genre, is_training, gold_starts, gold_ends, cluster_ids)
tokens
lm_emb就是个onehot估计。
关于这个mask,在这里面不是标签的意思, 是说把这个二维的list,取对应的数出来进行一个拼接成一维的list。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号