
爬虫笔记
了解爬虫
爬虫分类
1.通用爬虫:百度搜索引擎
2.聚焦爬虫:针对自已需要的内容进行爬取
聚集爬虫的流程过程
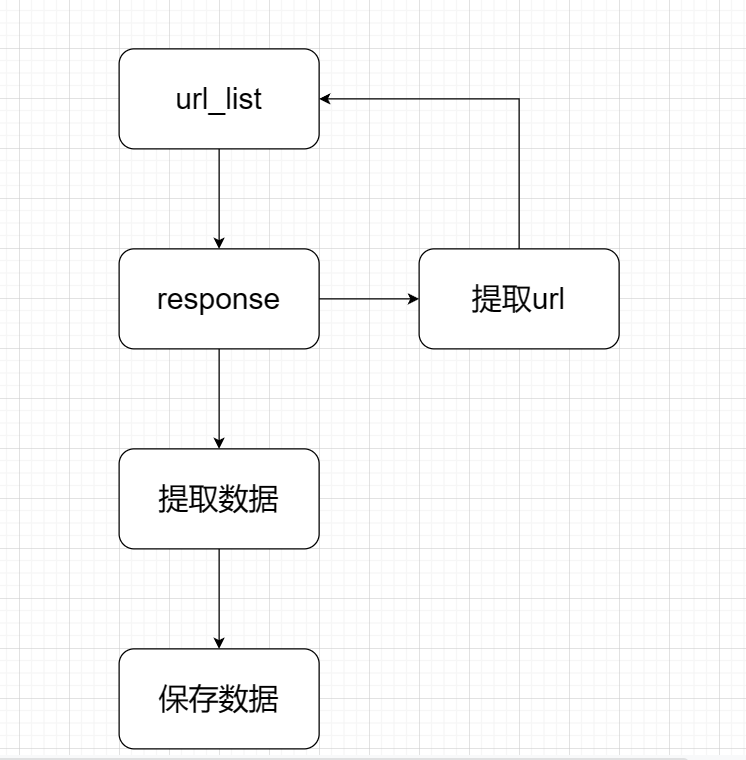
说明:
1.向起始地址发起请求,获取响应。如果有需要其它链接提取url返回到起始列表重新发送获取响应
2.将获取到的响应进行数据提取。
3.保存数据
协议
HTTP协议:端口为80,超文本传输协议
HTTP协议:端口为443,带有安全套(SSL)的超文本传输协议
常见的请求头参数
1.Host(主机和端口号)
2.Connection(链接类型)
3.Upgrade-Insecure-Requests(升级为HTTPS请求)
4.User-Agent(浏览器名称)
5.Accept(传输文件类型)
6.Referer(页面跳转)
7.Accept-Encoding(文件编码格式)
8.Cookie(Cookie信息)
9.x-requested-with :XMLHttpRequest(表示请求为Ajax异步请求)
响应头参数
Set-Cookie(对方服务器设置cookie到用户浏览器的缓存)
常见状态码
- 200:成功
- 302:临时转移到新的URL(一般用于GET,原本POST跳到GET)
- 307:临时转移到新的URL(原本POST跳到POST)
- 403:无清求权限
- 404:找不到页面
- 500:服务器内部错误
- 503:服务不可用,一般是被反爬
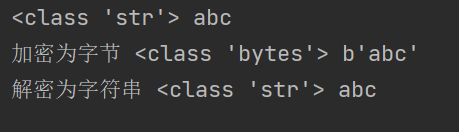
编码
str_code='abc'
print(type(str_code),str_code)
byte_code=str_code.encode()
print('加密为字节',type(byte_code),byte_code)
str_decode_code=byte_code.decode()
print('解密为字符串',type(str_decode_code),str_decode_code)
requests介绍
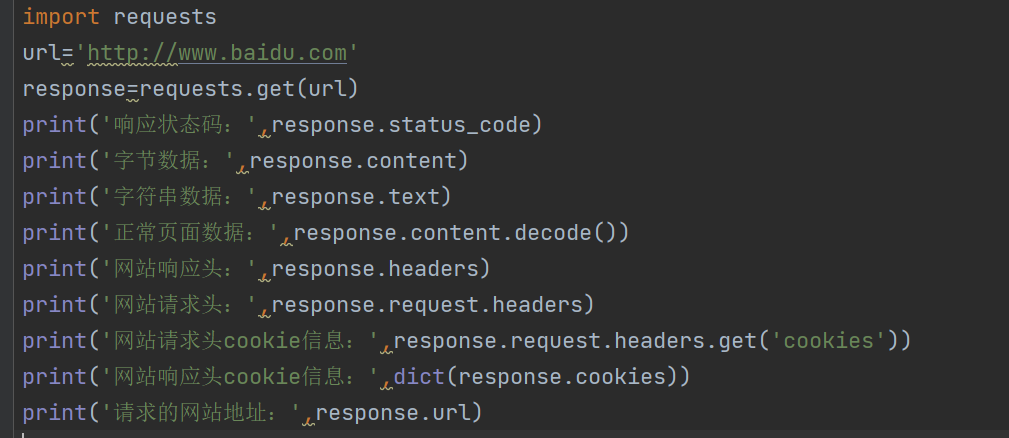
text与content的区别
text:
根据网站的响应头推测可能的编码类型,自已指定编码集(apparent_encoding可以获取网页编码集)
content:
当前方法返回的数据类型是字节,没有编码集,可以直接解码成字符串。在decode解码时需要指明页面原有的编码集
下载进度
import requests
def download_video(url,save_path):
response=requests.get(url,stream=True)
total_size=int(response.headers.get('Content-Length',0))
download_size=0
with open(save_path,'wb')as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
download_size+=len(chunk)
percent=(download_size/total_size)*100
print(f"下载进度:{percent:.2f}%")
print('下载完成。。。')
video_url='http://v3-web.douyinvod.com/e9235cc6a6e1eb52ca099190a74b2311/66169ada/video/tos/cn/tos-cn-ve-15/oQBqJLQWIhbt6AUANpyAhzbB8EA9D3zNgAPfXe/?a=6383&ch=5&cr=3&dr=0&lr=all&cd=0%7C0%7C0%7C3&cv=1&br=2263&bt=2263&cs=0&ds=3&ft=LjhJEL998xx1u.Zmo0P58lZW_3iXXvUWxVJEc4l0jCPD-Ipz&mime_type=video_mp4&qs=0&rc=ZjQ6Mzw7Nmc3NmVpaWg1NkBpM3VxeWU6Zm90cTMzNGkzM0AxYWEtMDExXjMxMTE0Ly9gYSNfYmE0cjQwNmRgLS1kLTBzcw%3D%3D&btag=e00028000&cquery=101s_100B_100H_100K_100a&dy_q=1712753794&feature_id=aec1901414fcc21744f0443229378a3c&l=20240410205633BD9B3571C2A5DD105DB6'
path='video.mp4'
download_video(video_url,path)
携带与查询参数
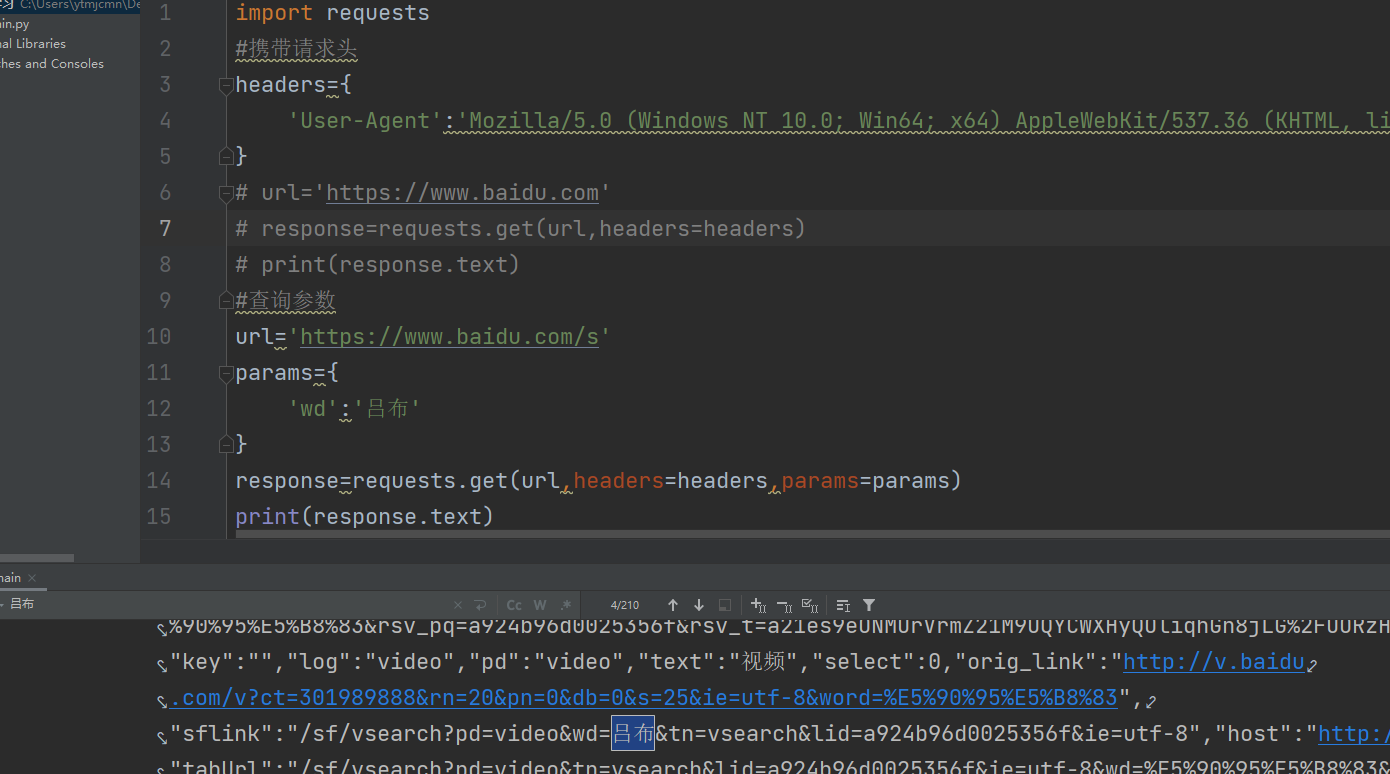
发送post请求
案例
import requests
url = 'https://fanyi.baidu.com/basetrans'
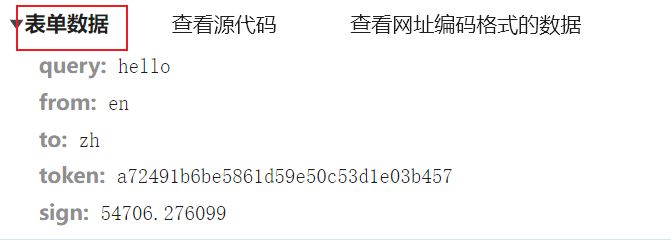
form_data = {
"query": "hello",
"from": "en",
"to": "zh",
"token": "a72491b6be5861d59e50c53d1e03b457",
"sign": "54706.276099"
}
headers = {
'Referer': 'https://fanyi.baidu.com/',
'Cookie': 'REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; PSTM=1704239175; BAIDUID=FF20EB01000063FFBC6614B38775E8D2:FG=1; BIDUPSID=1209C1CA255A4C481420113F8E3E005D; BDUSS=mdJNERVeWQ1WkhKd0VCM2tpWGx-YWxLdjhGZDlQZmRTc1owc0xmM1llNjdyY2xsSVFBQUFBJCQAAAAAAAAAAAEAAACMHMGaAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALsgomW7IKJlT; BDUSS_BFESS=mdJNERVeWQ1WkhKd0VCM2tpWGx-YWxLdjhGZDlQZmRTc1owc0xmM1llNjdyY2xsSVFBQUFBJCQAAAAAAAAAAAEAAACMHMGaAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALsgomW7IKJlT; H_WISE_SIDS=40211_40080_40365_40352_40367_40376_40446_40300_40467_40458_40479_40475_40317_40510_40512; H_PS_PSSID=40367_40376_40446_40300_40467_40458_40479_40510_40512_40398_60041_60024_60036_60047; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_WISE_SIDS_BFESS=40211_40080_40365_40352_40367_40376_40446_40300_40467_40458_40479_40475_40317_40510_40512; BA_HECTOR=8h0l2g2421012ka121a4ahal3ahd831j1d4l71s; ZFY=MKbVsXOTSNYGbEausX8j07e1eAGDKzVhK2dAyqiJ7XU:C; BAIDUID_BFESS=FF20EB01000063FFBC6614B38775E8D2:FG=1; RT="z=1&dm=baidu.com&si=mtzvj3947s&ss=luv0hdkz&sl=1&tt=2zw&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ul=hhk&hd=i60"; Hm_lvt_afd111fa62852d1f37001d1f980b6800=1712826235; Hm_lpvt_afd111fa62852d1f37001d1f980b6800=1712826235; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1712826235; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1712826235; ab_sr=1.0.1_OTkwMmJmZTQzMGU5M2E3MzdhNTYwYmM0NjAzOGM2MTI2YzY3M2IwMzljMWE4MzFiMzcyMzAwMjFhMzQ3ODg2NjdiM2M0ZDY4YmI3NDA4NGUwNDNjNWFlMDhiYmMxMmNjMjlhNGEzMzJkZTE1ZTFlZTgwOGM2ZjFjYTFhMWY0MWVhMGFjZTAzMDExMmMwOWU3NzMwYTRiMTZlNjA2ZGUyNWYzNTYyMzczY2M5NGYyMzc4MzM4ZTQwNzM1YTIyZDM5',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Mobile Safari/537.36'
}
response = requests.post(url, headers=headers, data=form_data)
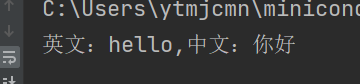
dst=response.json()['trans'][0]['dst']
src=response.json()['trans'][0]['src']
print('英文:%s,中文:%s'%(src,dst))
重定向与历史请求

取消重定向


历史
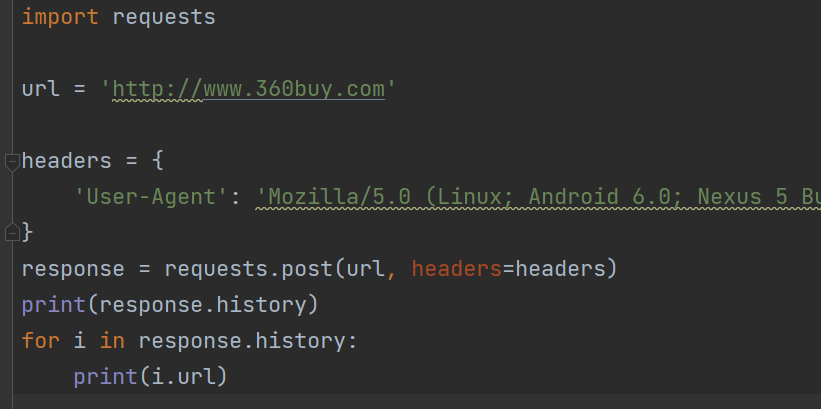
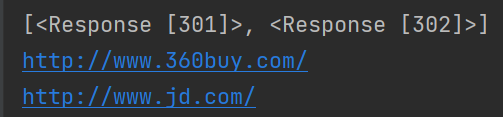
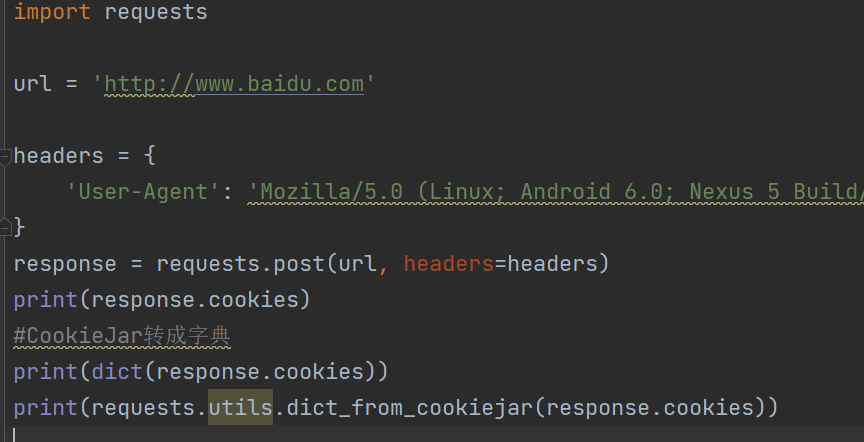
处理cookie
SSL证书
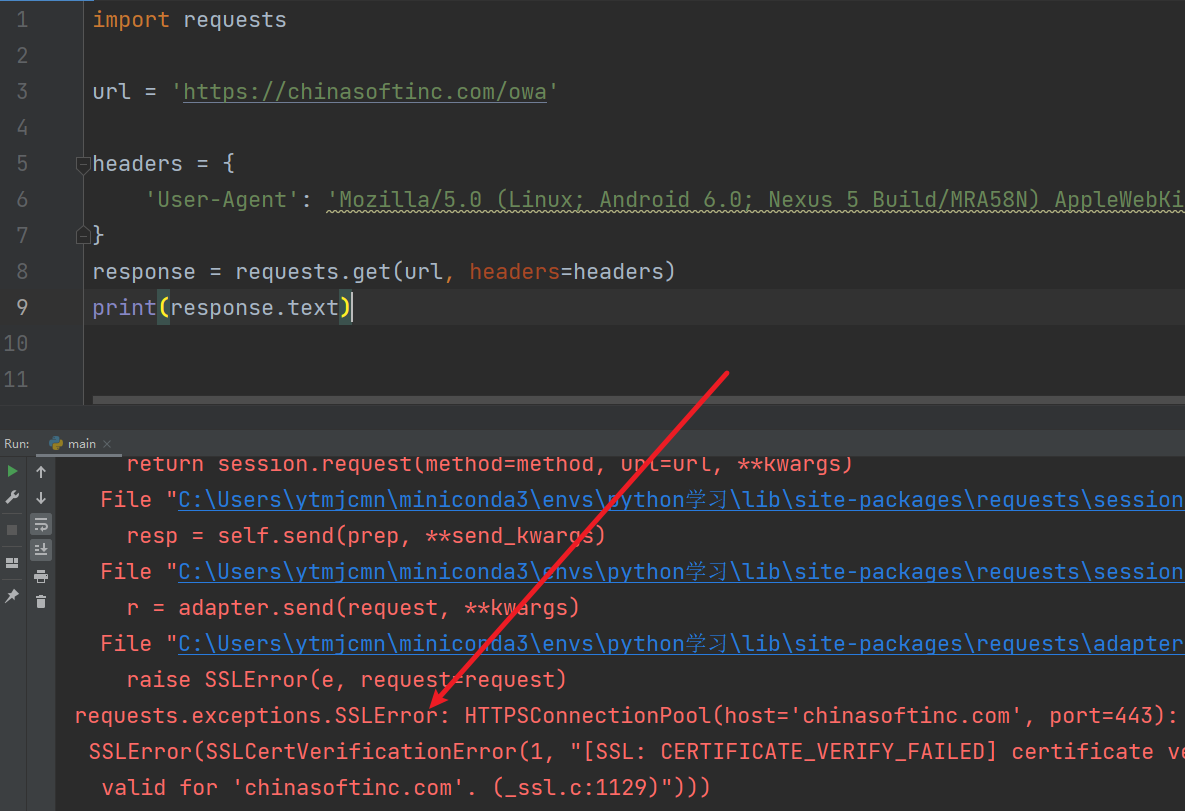
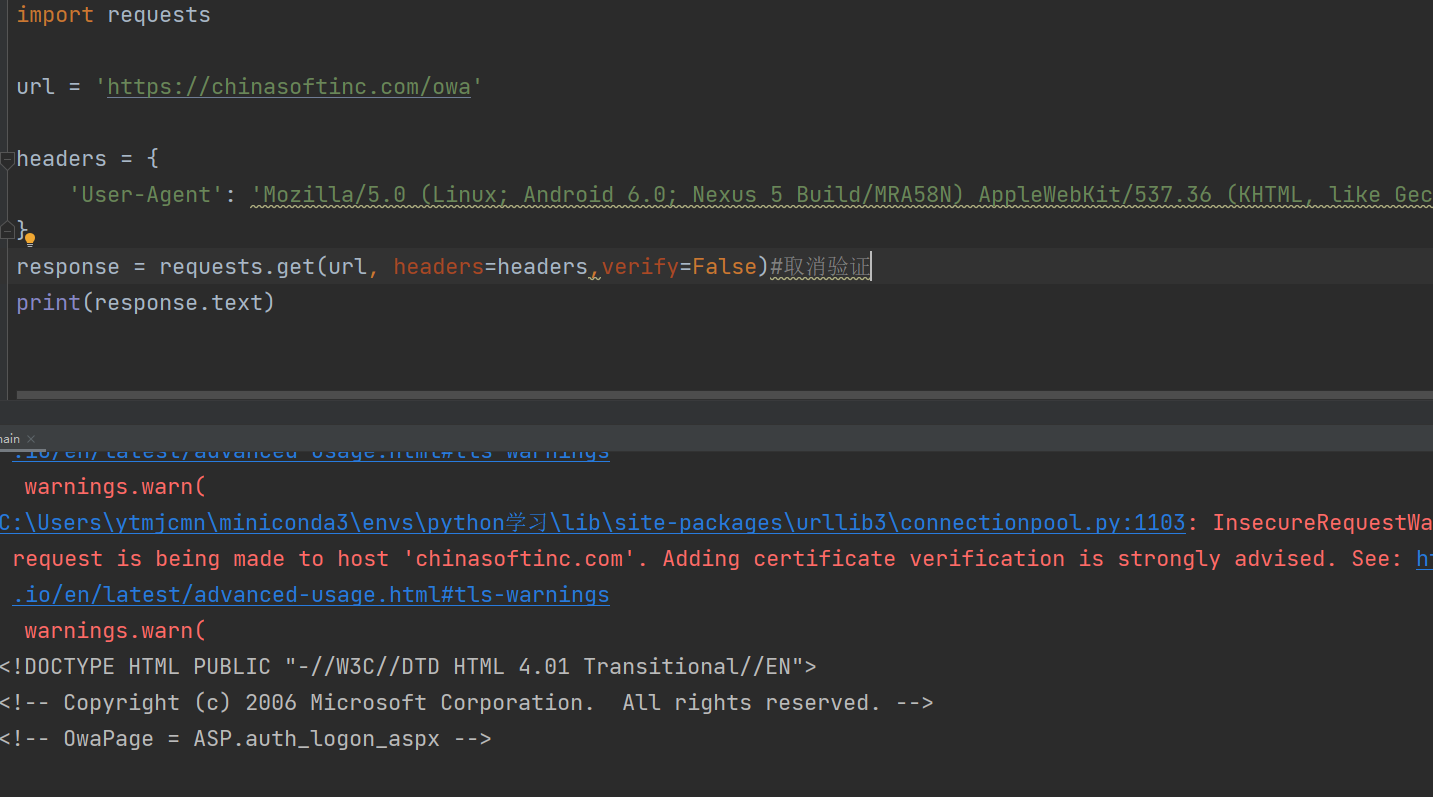
请求超时
import requests
import time
url = 'https://www.google.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Mobile Safari/537.36'
}
t1=time.time()
try:
response = requests.get(url, headers=headers,timeout=3)
except Exception as e:
print('报错信息:',e)
finally:
t2 = time.time()
print('消耗的时间:',t2 - t1)

报错重试(retrying)
import requests
from retrying import retry
import time
num=1
@retry(stop_max_attempt_number=3)
def test():
global num
print(num)
num+=1
time.sleep(1)
for temp in 100:
print(temp)
try:
test()
except Exception as e:
print(e)
发送JSON数据
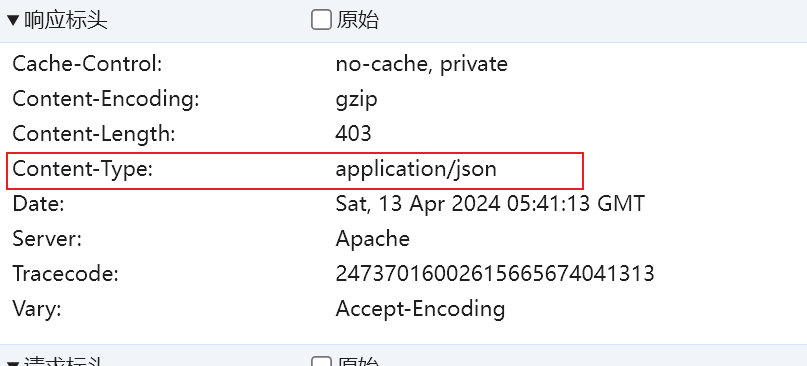
import requests
url='https://fanyi.baidu.com/sug'
headers= {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Mobile Safari/537.36"
}
form_data= {
"kw": "hello"
}
response=requests.post(url,headers=headers,json=form_data)
print(response.json())

Session会话
与网站保持长链接
- 保存cookie,下次请求携带上一交的cookie
- 实现与服务端的长连接,加速请求速度
import requests
url_1='https://www.baidu.com'
headers= {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Mobile Safari/537.36"
}
session=requests.Session()
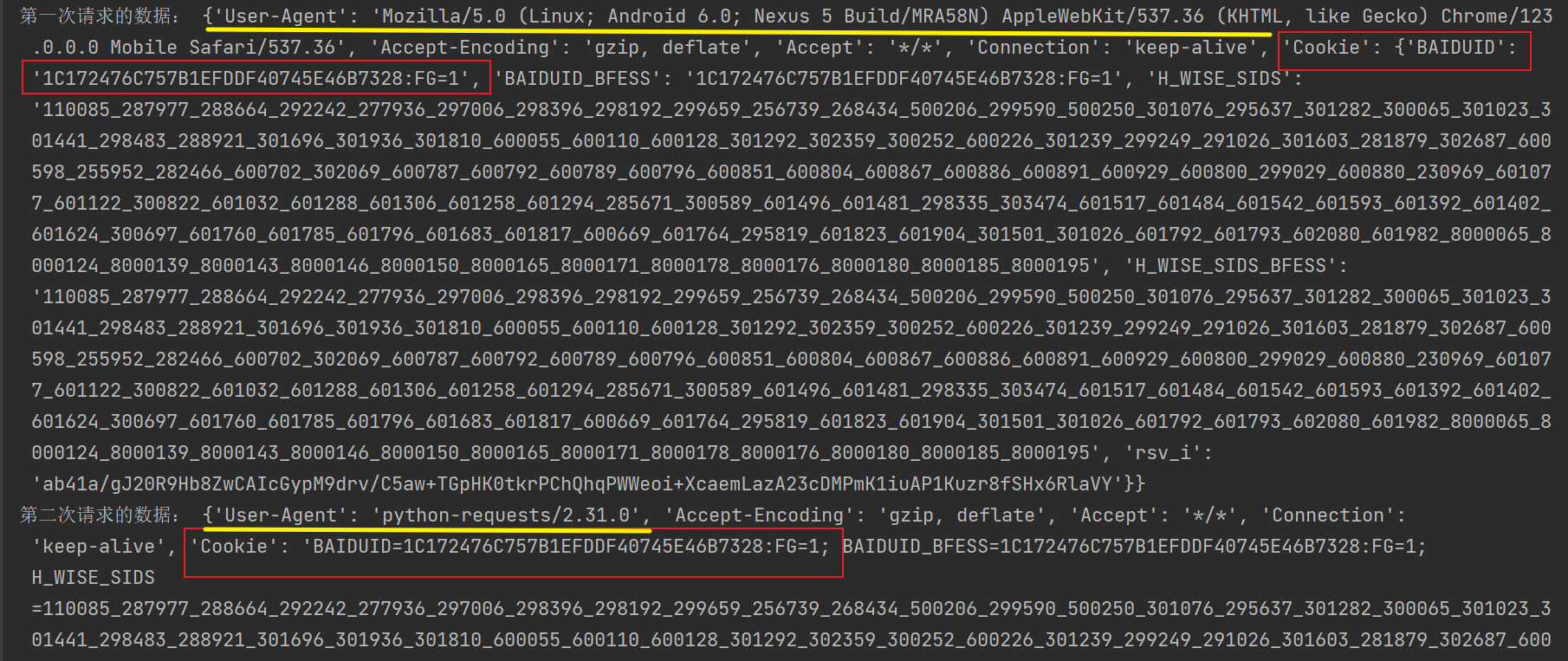
response=session.get(url_1,headers=headers)
# print('第一次响应的数据:',response.headers)
response.request.headers['Cookie']=requests.utils.dict_from_cookiejar(response.cookies)
print('第一次请求的数据:',response.request.headers)
url_2='https://www.baidu.com'
response=session.get(url_2)
print('第二次请求的数据:',response.request.headers)
代理
import requests
ip='127.0.0.1'
port=1014
proxies={
'http':'http://%s:%d'%(ip,port),
'https':'https://%s:%d'%(ip,port)
}
print(proxies)
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36"
}
url = "http://httpbin.org/ip"
response=requests.get(url,headers=headers,proxies=proxies,timeout=10)
print(response.text)
数据提取
json数据
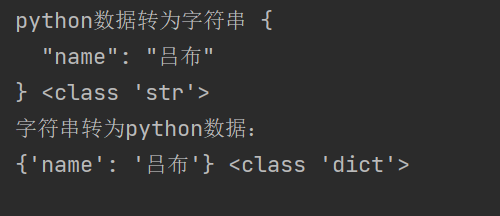
import json
str_data={'name':'吕布'}
json_str=json.dumps(str_data,indent=2,ensure_ascii=False)#indent实现缩进格式,ensure_ascii实现中文保存
print('python数据转为字符串',json_str,type(json_str))
print('字符串转为python数据:')
json_dict=json.loads(json_str)
print(json_dict,type(json_dict))
XPTH语法
安装
pip install lxml
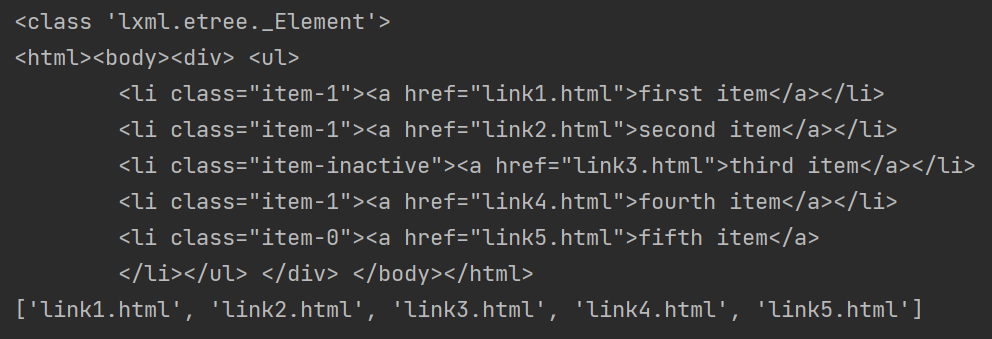
from lxml import etree
text = ''' <div> <ul>
<li class="item-1"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul> </div> '''
html=etree.HTML(text)#字符串转为Element对象,<class 'lxml.etree._Element'>
print(type(html))
html_str=etree.tostring(html).decode()#tostring变为二进制数据,decode解为字符串
print(html_str)
html_href=html.xpath('//a/@href')
print(html_href)
jsonpath工具
安装
pip install jsonpath --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
初体验
from jsonpath import jsonpath
info = {
"error_code": 0,
"stu_info": [
{
"id": 2059,
"name": "小白",
"sex": "男",
"age": 28,
"addr": "河南省济源市北海大道xx号",
"grade": "天蝎座",
"phone": "1837830xxxx",
"gold": 10896,
"info": {
"card": 12345678,
"bank_name": '中国银行'
}
},
{
"id": 2067,
"name": "小黑",
"sex": "男",
"age": 28,
"addr": "河南省济源市北海大道xx号",
"grade": "天蝎座",
"phone": "87654321",
"gold": 100
}
]
}
#提取name数据
res_1=jsonpath(info,'$.stu_info[0].name')
print(res_1)#返回的是一个列表,['小白']
#简略写法
res_2=jsonpath(info,'$..name')
print(res_2)#['小白', '小黑']
from jsonpath import jsonpath
info = {
"store": {
"book": [
{"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
#提取第一本书的书名
# res=jsonpath(info,'$..book[0].title')
# print(res)
#提取2,3,4这三本书的书名
# res=jsonpath(info,'$..book[1,2,3].title')
# print(res)
# res=jsonpath(info,'$..book[1:].title')#根据列表的特征
# print(res)
#提取1,3这两本书的书名
# res=jsonpath(info,'$..book[0,2].title')
# print(res)
# res=jsonpath(info,'$..book[::2].title')
# print(res)
#提取最后一本书的书名
# res=jsonpath(info,'$..book[(@.length-1)].title')
# print(res)
# res=jsonpath(info,'$..book[-1:].title')
# print(res)
#提取价格小于10的书籍名称
# res=jsonpath(info,'$..book[?(@.price<10)].title')#?()过滤
# print(res)
#提取价格小于或者等于20的所有商品的价格
# res=jsonpath(info,'$..book[?(@.price<=20).price')
# print(res)
#提取所有书籍的作者
# res=jsonpath(info,'$..author')
# print(res)
# res=jsonpath(info,'$..book[:].author')
# print(res)
# res=jsonpath(info,'$..book[*].author')
# print(res)
# res=jsonpath(info,'$.store.book.author')#如何键不存在,报错False
# print(res)
# res=jsonpath(info,'$.store.book..author')
# print(res)
#获取商店中的所有商品
# res=jsonpath(info,'$.store')
# print(res)
#获取所有商品的价格
# res=jsonpath(info,'$..price')
# print(res)
# res=jsonpath(info,'$.store..price')
# print(res)
#获取不带有isbn的书
# res=jsonpath(info,'$..book[?(!@.isbn).title')
# print(res)
#获取价格在5-10之间的书籍
# res=jsonpath(info,'$..book[?(@.price>=5 && @.price<=10)].title')
# print(res)
#获取价格不在5-10之间的书籍
# res=jsonpath(info,'$..book[?(@.price<5 || @.price>10)].title')
# print(res)
#获取所有的值
res=jsonpath(info,'$..*')
print(res)
bs4工具
安装
pip install bs4 --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
find_all()
import re
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#创建bs4对象,第二个参数需要手动指定一个解析器
soup=BeautifulSoup(html,'lxml')
#格式化输出页面代码
# print(soup.prettify())
#根据标签名称获取对应标签
# res_1=soup.find_all('b')
# print(res_1)
# res_2=soup.find_all(['a','b'])
# print(res_2)#获取a,b所有标签
# res_3=soup.find_all(re.compile('^b'))
# print(res_3)#获取以b开头的标签
#根据属性过滤
# res_4=soup.find_all(class_='sister')
# print(res_4)#class属性与python中的类冲突所以要加 _ ,其它不用
# res_4=soup.find_all(attrs={'class':'sister'})
# print(res_4)
# res_5=soup.find(id='link2')
# print(res_5)
'''
find获取查询到的第一个值 ,find_all查询所有符合要求的值
'''
#根据文本获取对应的标签
# res_6=soup.find_all(string='Elsie')
# print(res_6)#获取文本值
# res_7=soup.find_all(string=['Elsie','Lacie','abc'])#匹配不上的文本忽略
# print(res_7)
# res_8=soup.find_all(string=re.compile('Dormouse'))
# print(res_8)
总结
1.创建bs对象并手动指定解析器: lxml
2.find_all方法的特征: 根据标签名称查询、属性查询、文本查询、re正则匹配查询, 返回的数据类型是列表
标签名称可以传递多个: 将多个标签放到列表中直接传递给find_all方法
css
import re
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html, 'lxml')
#标签选择器
print(soup.select('title'))#使用css选择器语法完成标签定位
print(soup.select('a'))#查询符合条件的所有标签,使用列表返回
print(soup.select_one('a'))#返回一个
print('类选择器',soup.select('.sister'))
print('id选择器',soup.select('#link1'))
print('层级选择器',soup.select('p #link1'))
print('属性选择器',soup.select('a[class="sister"]'))
print('*'*30)
for temp in soup.select('title'):
print(type(temp))
print(temp.get_text())#获取文本
for temp_attr in soup.select('a'):
print(temp_attr.get('href'))
正则
import re
# content = """
# 苹果是绿色的
# 橙子是橙色的
# 香蕉是黄色的
# 乌鸦是黑色的
# """
#通配符.匹配任意一个字符,除\n
# for temp in re.findall(r'.色',content):
# print(temp)
#匹配任意次数:*可以匹配0次或者多次
# for temp in re.findall(r'是.*',content):
# print(temp)
#匹配任意次数:+可以匹配1次或者多次
# for temp in re.findall(r'是.+',content):
# print(temp)
#匹配0-1次
# for temp in re.findall(r'是.?',content):
# print(temp)
#匹配指定次数
# content = """
# 红彤彤,绿油油,黑乎乎,绿油油油油
# """
# print(re.findall(r'.油{2}',content))
#非贪婪模式
# content = '<html><head><title>Title</title>'
# for temp in re.findall(r'<.*?>',content):
# print(temp)
# 元字符转义
# content = """
# 苹果.是绿色的
# 橙子.是橙色的
# 香蕉.是黄色的
# """
# for temp in re.findall(r'.*\.',content):
# print(temp)
#使用中括号定义匹配范围
# content='a3247kj2lk3jl43'
# for temp in re.findall(r'[0-9]',content):
# print(temp)
#起始与结束
# content = '''001-苹果价格-60
# 002-橙子价格-70
# 003-香蕉价格-80
# '''
# for temp in re.findall(r'^\d+',content,re.M):
# print(temp)#以数字开始
# for temp in re.findall(r'\d+$',content,re.M):
# print(temp)#以数字结尾
#分组
# content = '''张三,手机号码15945678901
# 李四,手机号码13945677701
# 王二,手机号码13845666901'''
# for temp in re.findall(r'(.*?),手机号码(\d*)',content):
# print(temp)
#允许点号匹配所有字符
# content = '''
# <div class="el">
# <p class="t1">
# <span>
# <a>Python开发工程师</a>
# </span>
# </p>
# <span class="t2">南京</span>
# <span class="t3">1.5-2万/月</span>
# </div>
# <div class="el">
# <p class="t1">
# <span>
# <a>java开发工程师</a>
# </span>
# </p>
# <span class="t2">苏州</span>
# <span class="t3">1.5-2/月</span>
# </div>
# '''
# for temp in re.findall(r'<a>(.*?)</a>',content,re.DOTALL):
# print(temp)
#字符串分割
# names = '关羽; 张飞, 赵云,马超, 黄忠 李逵'
# print(re.split(r'[;,\s]\s*',names))
#替换
html_obj = '''
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
'''
print(re.sub(r"'_.*'",r'11',html_obj))
数据存储
csv文件存储
import csv
###########################################写入###########################################
#列表数据
# headers = ['班级', '姓名', '性别', '手机号', 'QQ']
#
# rows = [
# ["18级Python", '小王', '男', '13146060xx1', '123456xx1'],
# ["18级Python", '小李', '男', '13146060xx2', '123456xx2'],
# ["19级Python", '小赵', '女', '13146060xx3', '123456xx3'],
# ["19级Python", '小红', '女', '13146060xx4', '123456xx4'],
# ]
# with open('test_1.csv','w',newline='')as f:
# #创建一个csv的writer对象,这样才能够将写入csv格式数据到这个文件
# f_csv=csv.writer(f)
# #写入一行(将第一行做为表头)
# f_csv.writerow(headers)
# #写入多行(将数据写入)
# f_csv.writerows(rows)
#字典数据
# rows = [
# {
# "class_name": "18级Python",
# "name": '小王',
# "gender": '男',
# "phone": '13146060xx1',
# "qq": '123456xx1'
# },
# {
# "class_name": "18级Python",
# "name": '小李',
# "gender": '男',
# "phone": '13146060xx2',
# "qq": '123456xx2'
# },
# {
# "class_name": "19级Python",
# "name": '小赵',
# "gender": '女',
# "phone": '13146060xx3',
# "qq": '123456xx3'
# },
# {
# "class_name": "19级Python",
# "name": '小红',
# "gender": '女',
# "phone": '13146060xx4',
# "qq": '123456xx4'
# },
# ]
# with open('test_2.csv','w',newline='')as f:
# #创建一个csv的writer对象
# f_csv=csv.DictWriter(f,['class_name','name','gender','phone','qq'])
# #写入一行
# f_csv.writeheader()
# #写入多行
# f_csv.writerows(rows)
###########################################读取###########################################
#列表数据
# with open('test_1.csv','r')as f:
# #创建一个reader对象,迭代时能够提取到每一行(包括表头)
# f_csv=csv.reader(f)
# for row in f_csv:
# print(type(row),row)
#字典数据
with open('test_2.csv','r')as f:
#创建一个DictReader对象
f_csv=csv.DictReader(f)
for row in f_csv:
# print(row)
print(row.get('class_name'))
案例练习
import csv,requests
from lxml import etree
class SaveVideoInfo:
def __init__(self):
self.header= {
"Cookie":"_uuid=846FC69A-B2F7-85EA-32A4-5E6C8819DE5A17493infoc; buvid3=F529CA3B-3759-5438-E89E-656A8726C5E818743infoc; b_nut=1703570420; buvid4=3D6ADEA8-A979-68CF-4DA4-A68F82260D4F18743-023122606-PnTDfAqDXykieYmd7n7tsQ%3D%3D; PVID=1; CURRENT_FNVAL=4048; rpdid=|(J~R)um)))Y0J'u~|JYJ)Jk); fingerprint=fb64ac8cc2acad832dc2bea6ac2e48d0; buvid_fp_plain=undefined; DedeUserID=456072351; DedeUserID__ckMd5=e9662eb0a29a67c3; CURRENT_QUALITY=80; buvid_fp=fb64ac8cc2acad832dc2bea6ac2e48d0; enable_web_push=ENABLE; iflogin_when_web_push=1; FEED_LIVE_VERSION=V_WATCHLATER_PIP_WINDOW2; header_theme_version=CLOSE; home_feed_column=5; browser_resolution=1920-919; bp_video_offset_456072351=916084402193170529; b_lsid=910E67228_18F04A89AD4; SESSDATA=199f7046%2C1729322115%2Caa101%2A42CjAdsBhzY2yg3zCDv1cKHujbuOOJKoPfTcj7gur3kEJw91FvOO7OEtFK_GPGlQUhK8MSVnFNblBiYmRta0pkbXVpcEJUT1JETlBYZEQxQnVRUUZ5OEhaSU5ZOE56c2pTdWJEV2RYSUFVU2VNN2pVUDlhOFdRRWlBNTkzNTJ0b2ZlQXBlX0pWSGxnIIEC; bili_jct=5f0bf1b4cce9d98a5e62df0cfaa6cbc7; sid=7hqvrx6f; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3MTQwMjk0NzIsImlhdCI6MTcxMzc3MDIxMiwicGx0IjotMX0.UecxlcTXnluc1LssNc3xMqq8RV4X2FO6ZwoGAwighfo; bili_ticket_expires=1714029412",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
}
self.url='https://search.bilibili.com/video?vt=71752637&keyword=%E6%B1%BD%E8%BD%A6&from_source=webtop_search&spm_id_from=333.1007&search_source=5'
def parse_data(self):
"""
解析数据
:return:rows,数据
"""
response=requests.get(self.url,headers=self.header).content.decode()
html=etree.HTML(response)
href_list=html.xpath('//div[@class="bili-video-card__info--right"]/a/@href')
title_list=html.xpath('//div[@class="bili-video-card__info--right"]/a/h3/@title')
rows=list()
for i,j in zip(href_list,title_list):
href='https:'+i if not i.startswith('https:') else i
rows.append([j,href])
return rows
def save_csv(self,rows):
"""
保存数据
:return:
"""
header=['标题','链接']
with open('video_info.csv','w',encoding='utf-8',newline='')as f:
#创建writer对象
f_csv=csv.writer(f)
f_csv.writerow(header)
f_csv.writerows(rows)
def main(self):
rows=self.parse_data()
self.save_csv(rows)
if __name__ == '__main__':
s=SaveVideoInfo()
s.main()

json文件存储

案例
import csv,requests
import json
from bs4 import BeautifulSoup
class GameInfo:
def __init__(self):
self.header= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
}
self.url='https://www.4399.com/flash/'
def parse_data(self):
"""
解析数据
:return:data_list,数据
"""
response=requests.get(self.url,headers=self.header)
response.encoding=response.apparent_encoding
html=BeautifulSoup(response.text,'lxml')
data_list=list()
for i in html.select('li'):
item=dict()
item["href"]="https:"+i.select('a')[0].get('href') if i.select('a')[0].get('href').startswith('//www') \
else 'https://www.4399.com'+i.select('a')[0].get('href')
item["title"]=i.text
# print(href,title)
data_list.append(item)
return data_list
def save_json(self,data_list):
"""
保存数据
:return:
"""
with open('data.json','w',encoding='utf-8')as f:
f.write(json.dumps(data_list,indent=2,ensure_ascii=False))#禁止ascli编码
def main(self):
data_list=self.parse_data()
self.save_json(data_list)
if __name__ == '__main__':
s=GameInfo()
s.main()
mysql数据库存储
安装
pip install pymysql --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
案例
import requests,pymysql
from jsonpath import jsonpath
class TXWork:
def __init__(self):
self.header= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
self.url="https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1713776444398&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=1&keyword=python&pageIndex={}&pageSize=10&language=zh-cn&area=cn"
self.db=pymysql.connect(host='127.0.0.1',port=3306,user='root',password='root',db='py_spider')
self.cursor=self.db.cursor()
def get_work_info(self):
for page in range(1,39):
print(page)
response=requests.get(self.url.format(page),headers=self.header).json()
work_list=jsonpath(response,'$..Posts')[0][0]
yield work_list
def insert_work_info(self,*args):
"""
插入数据
:param args:id,work_name,country_name,city_name,responsibility
:return:
"""
sql="""
insert into tx_work values (%s,%s,%s,%s,%s)
"""
try:
self.cursor.execute(sql,args)
self.db.commit()
print('插入数据成功:',args)
except Exception as e:
print(e)
print('插入数据失败:',e)
self.db.rollback()
def create_table(self):
"""
mysql表的创建
id 索引ID
work_name 招聘名称
country_name 国家名称
city_name 城市名称
responsibility 职责
:return:
"""
sql="""
create table if not exists tx_work(
id int primary key auto_increment,
work_name varchar(100) not null,
country_name varchar (100),
city_name varchar (50),
responsibility text
)
"""
try:
self.cursor.execute(sql)
print('创建表成功。。。。')
except Exception as e:
print(e)
print('创建表失败。。。。')
def __del__(self):
self.cursor.close()
self.db.close()
def main(self):
work_id = 0
self.create_table()
work_list=self.get_work_info()
for i in work_list:
work_name=i["RecruitPostName"]
country_name=i["CountryName"]
city_name=i["LocationName"]
responsibility=i["Responsibility"]
self.insert_work_info(work_id,work_name,country_name,city_name,responsibility)
if __name__ == '__main__':
t=TXWork()
t.main()
import requests, pymysql
from jsonpath import jsonpath
class ALWork:
def __init__(self):
self.url = "https://talent.taotian.com/position/search?_csrf=2b85ca7c-bf23-48b2-af96-406a7447d4e3"
self.header = {
"Cookie":"cna=zJIBHjdP0AgCAXWIHj1ioIpM; XSRF-TOKEN=2b85ca7c-bf23-48b2-af96-406a7447d4e3; prefered-lang=zh; SESSION=OERBMUQyM0QzOUIyRjJBNURDMUQ2QzQzOUE5RDZDMTY=; xlly_s=1; tfstk=f7cZnuM8YCdZqik0YkN4YAWDxLPTG7K5sjZboq005lqgcdLVgDuuns9T1rAqcDwm15gsYmorVRc6BVgciqqLclZsCrAqxDwgGAZ_oNhE4s16Xd3cgSNDV3OWNVQTMSxW1xYHPNUblojcc-qhxmdGIqOWNV3G5PYS-QTAYyC3poV0I-0hxkUVnom0mBYUorsGn1mm-ezYxiX0I1XhtzldhV0cTzwMX2y8Mh-pPEPrSk5rJXzG4uR8vsfqTPuU8VbRiscU7RljdJZgYRMmy8hs7I5L14k3tkiDyTaKKzubzAtVHlms9mUadQxn8jraEf2Fo_0Utrm03vKPNPPsL8lZBEInS0ZZE53fzhgUUvy8-JbVI5MSPjeosCS8A8Uqlzk60tEgngRGDy0ZEjHNmtygJyrW8eXWl_gJwY5P5tBYK7UUVFa1HtegJyrW8eWAHJqL8uT_5; isg=BB4epLMi9G7g3COjyIorUxz4b7Rg3-JZccJIdcimi2E267zFMGuKaanJ4_dnU9px",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
self.db = pymysql.connect(host='127.0.0.1', port=3306, password='root', user='root', db='py_spider')
self.cursor = self.db.cursor()
def get_work_info(self):
for page in range(1,113):
data = {
"channel": "group_official_site",
"language": "zh",
"batchId": "",
"categories": "",
"deptCodes": [],
"key": "",
"pageIndex": page,
"pageSize": 10,
"regions": "",
"subCategories": "",
"shareType": "",
"shareId": "",
"myReferralShareCode": ""
}
response=requests.post(self.url,headers=self.header,json=data).json()
response_data_list=jsonpath(response,'$..datas')[0]
yield response_data_list
def create_table(self):
"""
创建存储数据的表
name 招聘名称
work_locations 省信息
requirement 职责要求
:return:
"""
sql="""
create table if not exists al_work(
id int primary key auto_increment,
name varchar(50) not null,
work_locations varchar(100),
requirement text
)
"""
try:
self.cursor.execute(sql)
print('创建表成功。。。')
except Exception as e:
print(e)
print('创建表失败。。。')
def insert_work_info(self,*args):
"""
保存数据
:param args: work_id,name,work_locations,requirement
:return:
"""
sql="""
insert into al_work values (%s,%s,%s,%s)
"""
try:
self.cursor.execute(sql,args)
print('保存数据成功:',args)
self.db.commit()
except Exception as e:
print(e)
print('保存数据失败。。。。')
self.db.rollback()
def main(self):
self.create_table()
work_id=0
response_data_list=self.get_work_info()
for page_data in response_data_list:
for j in page_data:
name=j['name']
work_locations=j['workLocations']
requirement=j['requirement']
self.insert_work_info(work_id,name,work_locations,requirement)
def __del__(self):
self.cursor.close()
self.db.close()
if __name__ == '__main__':
a=ALWork()
a.main()

MySQL数据库连接池存储
安装
pip install DBUtils --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
import pymysql
from dbutils.pooled_db import PooledDB
pool = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示无限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=3, # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和mysqldb的模块都不支持共享链接
blocking=True, # 连接池中如果没有可用链接后,是否阻塞等待。False,不等待直接报错;True,等待直到有可用链接,再返回。
host='127.0.0.1',
port=3306,
user='root',
password='root',
database='py_spider',
charset='utf8'
)
# 从数据库连接池中获取一个链接
conn = pool.connection()
# 获取游标
cursor = conn.cursor()
# 根据游标查询数据
sql = 'select * from tx_work;'
cursor.execute(sql)
print(cursor.fetchall())
MongoDB数据库存储
安装
pip install pymongo --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
import pymongo
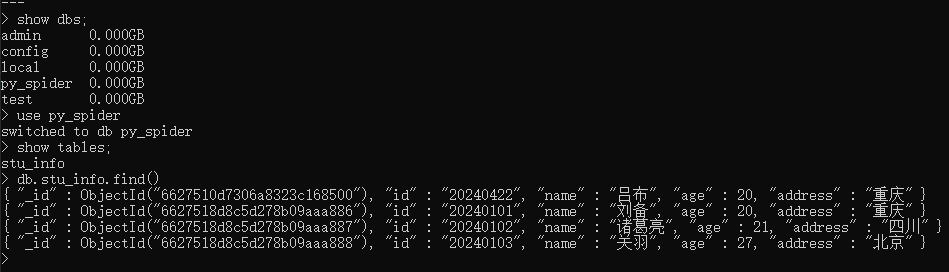
client_mongo=pymongo.MongoClient(host='localhost',port=27017)
db=client_mongo['py_spider']['stu_info']
#插入单条数据
# student = {'id': '20240422', 'name': '吕布', 'age': 20, 'address': '重庆'}
# res=db.insert_one(student)
# print(res)
#插入多条数据
student_list = [
{'id': '20240101', 'name': '刘备', 'age': 20, 'address': '重庆'},
{'id': '20240102', 'name': '诸葛亮', 'age': 21, 'address': '四川'},
{'id': '20240103', 'name': '关羽', 'age': 27, 'address': '北京'},
]
res=db.insert_many(student_list)
print(res)
案例
import requests,pymongo
from jsonpath import jsonpath
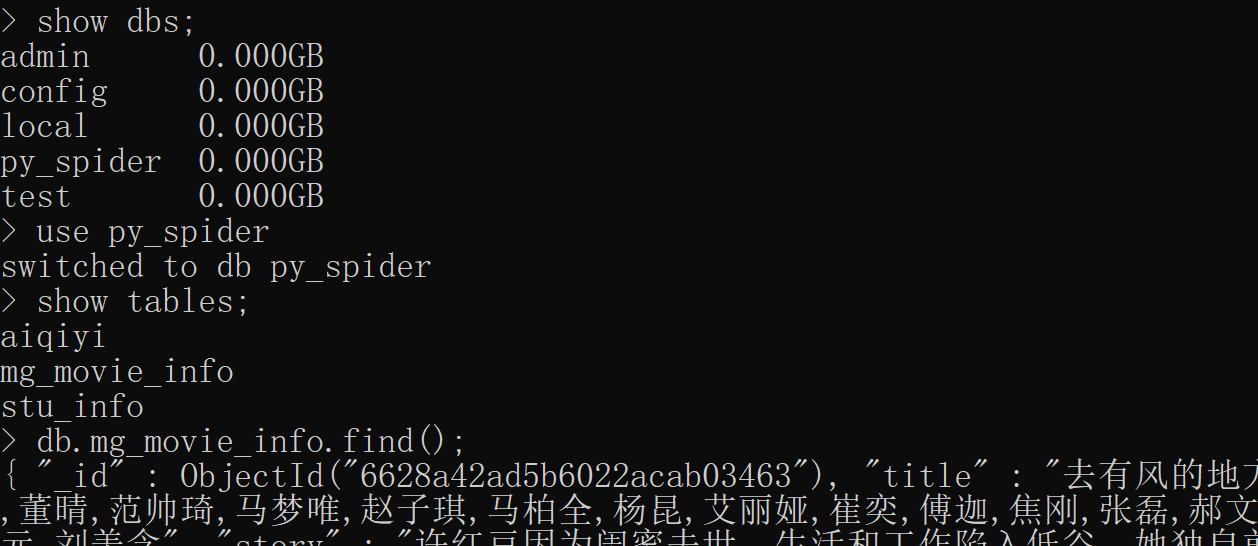
class AiQiYi:
def __init__(self):
self.url="https://pcw-api.iqiyi.com/search/recommend/list?channel_id=2&data_type=1&mode=11&page_id={}&ret_num=48&session=071d98453eb79ef6a10a719c9e3781ba&three_category_id=15;must"
self.header= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
self.client_pymongo=pymongo.MongoClient(host="127.0.0.1",port=27017)
self.db=self.client_pymongo['py_spider']['aiqiyi']
def get_work_info(self,page):
"""
获取数据信息
:return:
"""
response=requests.get(self.url.format(page),headers=self.header).json()
list_data=jsonpath(response,'$..list')[0]
return list_data
def parse_work_info(self,list_data):
for data in list_data:
item = dict()
item['name'] = data['name']
item['imageUrl']=data['imageUrl']
item['description']=data['description']
self.insert_work_info(item)
def insert_work_info(self,item):
self.db.insert_one(item)
print('保存数据成功:',item)
def main(self):
for page in range(1, 10):
print(f'*******************************************正在下载第{page}页信息*******************************************')
data=self.get_work_info(page)
self.parse_work_info(data)
if __name__ == '__main__':
a=AiQiYi()
a.main()
数据去重
安装
pip install redis --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
案例
import redis,requests
import pymongo,hashlib
class MovieInfo:
url = "https://pianku.api.mgtv.com/rider/list/pcweb/v3"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
def __init__(self):
self.client_mongo=pymongo.MongoClient(host="localhost",port=27017)
self.collection=self.client_mongo['py_spider']['mg_movie_info']
self.client_redis=redis.Redis()
@classmethod
def get_work_info(cls,params):
"""数据请求"""
response=requests.get(cls.url,headers=cls.header,params=params)
if response.status_code==200:
return response.json()
else:
print('请求失败,状态码为:',response.status_code)
def parse_work_info(self,response):
"""数据提取"""
if response['data']["hitDocs"]:
for movie in response['data']["hitDocs"]:
item=dict()
item['title']=movie['title']
item['subtitle']=movie['subtitle']
item['story']=movie['story']
# print(item)
self.save_work_info(item)
else:
print('没有你想要的数据!!!')
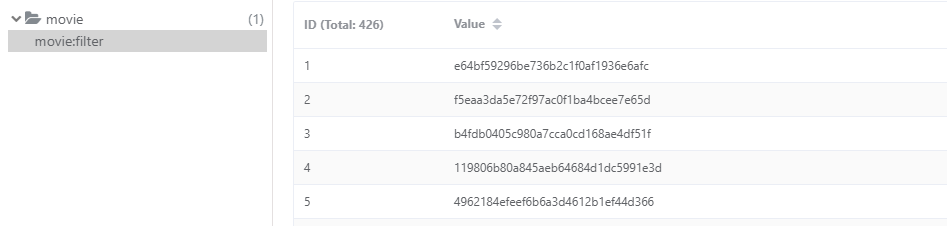
@staticmethod
def get_md5(value):
"""数据去重"""
md5_hash=hashlib.md5(str(value).encode('utf-8')).hexdigest()
return md5_hash
def save_work_info(self,item):
"""保存数据"""
md5_hash=self.get_md5(item)
result=self.client_redis.sadd('movie:filter',md5_hash)
if result:
self.collection.insert_one(item)
print('保存数据成功:',item)
else:
print('数据重复,保存失败:',item)
def main(self):
for page in range(1,10):
print(f'**********************************************************正在下载第{page}页数据**********************************************************')
params = {
"allowedRC": "1",
"platform": "pcweb",
"channelId": "2",
"pn": page,
"pc": "80",
"hudong": "1",
"_support": "10000000",
"kind": "19",
"area": "10",
"year": "all",
"chargeInfo": "a1",
"sort": "c2",
"feature": "all"
}
response=self.get_work_info(params)
self.parse_work_info(response)
if __name__ == '__main__':
m=MovieInfo()
m.main()

并发爬虫
asyncio与requests的使用
import asyncio, requests
from functools import partial # 偏函数
from bs4 import BeautifulSoup
class DouBanSpider:
url = 'https://movie.douban.com/top250?start={}&filter='
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36 "
}
@classmethod
async def get_movie_info(cls, loop, page):
# run_in_executor不支持传递参数,使用偏函数
response = await loop.run_in_executor(None,
partial(requests.get, cls.url.format(page * 25), headers=cls.headers))
soup = BeautifulSoup(response.text, 'lxml')
div_list = soup.find_all('div', class_='hd')
for title in div_list:
print(title.get_text())
def main(self):
loop = asyncio.get_event_loop()
tasks = [loop.create_task(self.get_movie_info(loop, page)) for page in range(10)]
loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
d = DouBanSpider()
d.main()
aiohttp的使用
安装
pip install aiohttp --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
基本使用
import asyncio,aiohttp
class BaiduSpider:
url="https://www.baidu.com"
headers= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36 "
}
@classmethod
async def get_baidu(cls):
#使用异步上下文管理器的方式创建请求对象
async with aiohttp.ClientSession() as session:
async with session.get(cls.url,headers=cls.headers)as response:
response=await response.text()
print(response)
def main(self):
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())# windows系统自行设置事件循环对象
asyncio.run(self.get_baidu())
if __name__ == '__main__':
b=BaiduSpider()
b.main()
并发操作
import aiohttp,asyncio
class CompletedCallback:
def __init__(self):
self.headers= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36 "
}
def download_completedcallback(self,task_obj):
"""任务完成后打印返回值的结果"""
print("下载的内容为:",task_obj.result())
# pass
async def baidu_spider(self):
"""百度页面信息爬取"""
url="https://www.baidu.com"
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=self.headers)as response:
return await response.text()
async def sogou_spider(self):
"""搜狗页面信息爬取"""
url="https://www.sogou.com"
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=self.headers)as response:
return await response.text()
async def jd_spider(self):
"""京东页面信息爬取"""
url="https://www.jd.com"
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=self.headers)as response:
return await response.text()
async def main(self):
task_baidu=asyncio.create_task(self.baidu_spider())
task_baidu.add_done_callback(self.download_completedcallback)#传递函数引用
task_sogou=asyncio.create_task(self.sogou_spider())
task_sogou.add_done_callback(self.download_completedcallback)
task_jd=asyncio.create_task(self.jd_spider())
task_jd.add_done_callback(self.download_completedcallback)
await asyncio.wait([task_baidu,task_sogou,task_jd])
# done,pending=await asyncio.wait([task_baidu,task_sogou,task_jd])
# for res in done:
# print(res.result())#获取返回结果
if __name__ == '__main__':
c=CompletedCallback()
loop=asyncio.get_event_loop()
loop.run_until_complete(c.main())
aiomysql的使用
安装
pip install aiomysql --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
基本使用
import asyncio
import aiomysql
async def main():
db= await aiomysql.connect(host='localhost',port=3306,user='root',password='root',db='py_spider')
cursor= await db.cursor()
await cursor.execute('select * from tx_work;')
result=await cursor.fetchall()
print(result)
print(cursor.description)#查询表中的字段信息
#关闭游标
await cursor.close()
db.close()
if __name__ == '__main__':
loop=asyncio.get_event_loop()
loop.run_until_complete(main())
上下文管理的使用
import asyncio,aiomysql
async def main():
async with aiomysql.connect(host='localhost',port=3306,user='root',password='root',db='py_spider') as db:
async with db.cursor() as cursor:
await cursor.execute('select * from tx_work;')
result=await cursor.fetchall()
print(result)
if __name__ == '__main__':
loop=asyncio.get_event_loop()
loop.run_until_complete(main())
案例
import redis
import aiohttp
import aiomysql
import asyncio
import chardet #判断页面编码
import hashlib
from lxml import etree
from fake_useragent import UserAgent
from motor.motor_asyncio import AsyncIOMotorClient
class CarSpider:
redis_client=redis.Redis()
mongo_client=AsyncIOMotorClient('localhost',27017)['py_spider']['car_info']
def __init__(self):
self.url="https://www.che168.com/china/a0_0msdgscncgpi1ltocsp{}exf4x0/?pvareaid=102179#currengpostion"
self.api_url = 'https://cacheapigo.che168.com/CarProduct/GetParam.ashx?specid={}'
# self.headers= {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
# }
self.user_agent=UserAgent()
def __del__(self):
print('数据库即将关闭。。。')
self.redis_client.close()
async def get_car_id(self,page,session,pool):
"""获取每个汽车页面的id"""
headers={"User-Agent":self.user_agent.random}
async with session.get(self.url.format(page),headers=headers)as response:
content=await response.read()
encoding=chardet.detect(content)['encoding']
if encoding == 'GB2312' or encoding == 'ISO-8859-1':
result=content.decode('gbk')
else:
result=content.decode(encoding)
print(encoding,'编码解析错误,被反爬了。。。。')
tree=etree.HTML(result)
id_list=tree.xpath('//ul/li/@specid')
if id_list:
tasks=[loop.create_task(self.get_car_info(sepc_id,session,pool)) for sepc_id in id_list]
await asyncio.wait(tasks)
async def get_car_info(self,sepc_id,session,pool):
"""获取汽车的参数信息"""
headers={"User-Agent":self.user_agent.random}
async with session.get(self.api_url.format(sepc_id),headers=headers) as response:
result=await response.json()
# 存在一些车型没有详细的硬件配置
if result['result'].get('paramtypeitems'):
item = dict()
item['name'] = result['result']['paramtypeitems'][0]['paramitems'][0]['value']
item['price'] = result['result']['paramtypeitems'][0]['paramitems'][1]['value']
item['brand'] = result['result']['paramtypeitems'][0]['paramitems'][2]['value']
item['altitude'] = result['result']['paramtypeitems'][1]['paramitems'][2]['value']
item['breadth'] = result['result']['paramtypeitems'][1]['paramitems'][1]['value']
item['length'] = result['result']['paramtypeitems'][1]['paramitems'][0]['value']
md5_hash = self.get_md5(item)
redis_result = self.redis_client.sadd('car:filter', md5_hash)
if redis_result:
await self.save_car_info_mysql(item, pool)
await self.save_car_info_mongo(item)
else:
print('数据重复')
else:
print('数据不存在...')
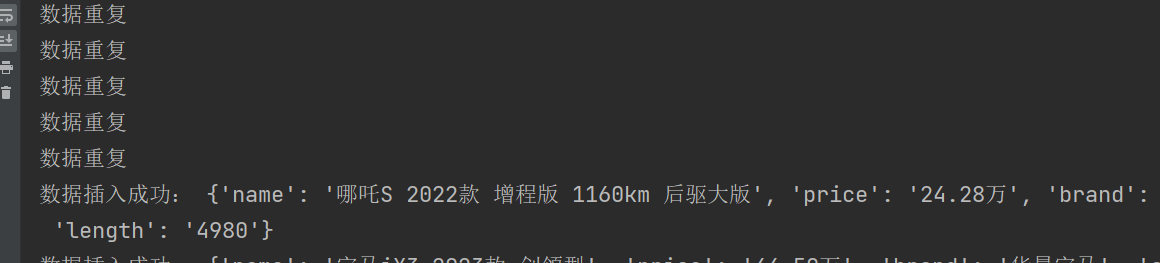
async def save_car_info_mysql(self,item,pool):
"""将数据进行保存到mysql"""
async with pool.acquire() as conn:
async with conn.cursor() as cursor:
sql="""
insert into car_info(
id,name,price,brand,altitude,breadth,length) values (
%s,%s,%s,%s,%s,%s,%s);
"""
try:
await cursor.execute(sql, (0,
item['name'],
item['price'],
item['brand'],
item['altitude'],
item['breadth'],
item['length']
))
await conn.commit()
print('数据插入成功:',item)
except Exception as e:
print('数据插入失败:',e)
await conn.rollback()
async def save_car_info_mongo(self,item):
"""将数据保存到mongo"""
await self.mongo_client.insert_one(item)
print('数据插入mongo成功:',item)
@staticmethod
def get_md5(item):
"""将数据进行md5加密"""
md5=hashlib.md5()
md5.update(str(item).encode('utf-8'))
return md5.hexdigest()
async def main(self):
async with aiomysql.create_pool(user='root',password='root',db='py_spider')as pool:
async with pool.acquire() as coon:
async with coon.cursor() as cursor:
create_table_sql="""
create table car_info(
id int primary key auto_increment,
name varchar(100),
price varchar(100),
brand varchar(100),
altitude varchar(100),
breadth varchar(100),
length varchar(100)
);
"""
check_table_query="show tables like 'car_info';"
result=await cursor.execute(check_table_query)
if not result:
await cursor.execute(create_table_sql)
async with aiohttp.ClientSession() as session:
tasks=[loop.create_task(self.get_car_id(page,session,pool))for page in range(1,4)]
await asyncio.wait(tasks)
if __name__ == '__main__':
c=CarSpider()
loop=asyncio.get_event_loop()
loop.run_until_complete(c.main())
线程方式
import requests
import threading
from lxml import etree
from fake_useragent import UserAgent
url = 'https://movie.douban.com/top250?start={}&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
def get_movie_info(page):
response=requests.get(url.format(page*25),headers=headers).text
tree=etree.HTML(response)
result=tree.xpath('//div[@class="hd"]/a/span[1]/text()')
print(result)
if __name__ == '__main__':
thread_list=[threading.Thread(target=get_movie_info,args=(page,))for page in range(1,3)]
for thread_obj in thread_list:
thread_obj.start()
线程池方式
import requests
import threading
from lxml import etree
from concurrent.futures import ThreadPoolExecutor,as_completed
url = 'https://movie.douban.com/top250?start={}&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
def get_movie_info(page):
response=requests.get(url.format(page*25),headers=headers).text
tree=etree.HTML(response)
result=tree.xpath('//div[@class="hd"]/a/span[1]/text()')
# print(result)
return result
if __name__ == '__main__':
with ThreadPoolExecutor(max_workers=3)as pool:
futures=[pool.submit(get_movie_info,page) for page in range(10)]
#并发返回:as_completed
for future in as_completed(futures):
print(future.result())
进程方式
import time
import requests
import jsonpath
from multiprocessing import Process,JoinableQueue as Queue
url = "https://careers.tencent.com/tencentcareer/api/post/Query"
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
def get_work_info(page_num, queue):
params = {
"timestamp": "1714307524077",
"countryId": "",
"cityId": "",
"bgIds": "",
"productId": "",
"categoryId": "",
"parentCategoryId": "",
"attrId": "",
"keyword": "python",
"pageIndex": page_num,
"pageSize": "10",
"language": "zh-cn",
"area": "cn"
}
response = requests.get(url, params=params, headers=headers).json()
for info in response['Data']['Posts']:
work_info_dict = dict()
work_info_dict['recruit_post_name'] = jsonpath.jsonpath(info, '$..RecruitPostName')[0]
work_info_dict['country_name'] = jsonpath.jsonpath(info, '$..CountryName')[0]
work_info_dict['location_name'] = jsonpath.jsonpath(info, '$..LocationName')[0]
work_info_dict['category_name'] = jsonpath.jsonpath(info, '$..CategoryName')[0]
work_info_dict['responsibility'] = jsonpath.jsonpath(info, '$..Responsibility')[0]
work_info_dict['last_update_time'] = jsonpath.jsonpath(info, '$..LastUpdateTime')[0]
queue.put(work_info_dict)
def save_work_info(queue):
while True:
dict_info = queue.get()
print('数据为:', dict_info)
# 直到队列计数器为0则释放主进程
queue.task_done()
if __name__ == '__main__':#进程需要创建启动入口
dict_info_queue=Queue()
process_list=list()
for page in range(1,3):
p_get_info=Process(target=get_work_info,args=(page,dict_info_queue))
process_list.append(p_get_info)
p_save_work = Process(target=save_work_info, args=(dict_info_queue,))
process_list.append(p_save_work)
for process_obj in process_list:
#将子进程设置为守护进程
process_obj.daemon=True
process_obj.start()
#让主进程等待所有的子进程启动
time.sleep(3)
print('任务完成....')
进程池方式
import time
import requests
import jsonpath
from multiprocessing import Process,JoinableQueue as Queue,Pool
url = "https://careers.tencent.com/tencentcareer/api/post/Query"
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
def get_work_info(page_num):
params = {
"timestamp": "1714307524077",
"countryId": "",
"cityId": "",
"bgIds": "",
"productId": "",
"categoryId": "",
"parentCategoryId": "",
"attrId": "",
"keyword": "python",
"pageIndex": page_num,
"pageSize": "10",
"language": "zh-cn",
"area": "cn"
}
response = requests.get(url, params=params, headers=headers).json()
for info in response['Data']['Posts']:
work_info_dict = dict()
work_info_dict['recruit_post_name'] = jsonpath.jsonpath(info, '$..RecruitPostName')[0]
work_info_dict['country_name'] = jsonpath.jsonpath(info, '$..CountryName')[0]
work_info_dict['location_name'] = jsonpath.jsonpath(info, '$..LocationName')[0]
work_info_dict['category_name'] = jsonpath.jsonpath(info, '$..CategoryName')[0]
work_info_dict['responsibility'] = jsonpath.jsonpath(info, '$..Responsibility')[0]
work_info_dict['last_update_time'] = jsonpath.jsonpath(info, '$..LastUpdateTime')[0]
print(work_info_dict)
if __name__ == '__main__':#进程需要创建启动入口
print('程序开始')
pool=Pool(3)
for page in range(1,3):
pool.apply_async(get_work_info,(page,))
time.sleep(3)
pool.close()
pool.join()
print('任务完成....')
案例
多线程
import time
import requests
import threading
import pymysql
import pymongo
import csv
import json
import hashlib
import redis
from jsonpath import jsonpath
from fake_useragent import UserAgent
from queue import Queue
class AiQiYiSpider:
# 标记是否已经写入标题
header_written = False
redis_client = redis.Redis()
mongo_client = pymongo.MongoClient(host='localhost', port=27017)
mongo_db=mongo_client['py_spider']['aiqiyi_info']
def __init__(self):
self.useragent = UserAgent()
self.api_url = "https://pcw-api.iqiyi.com/search/recommend/list?channel_id=2&data_type=1&mode=11&page_id={}&ret_num=48&session=7c0d98b276a6dfde780b2994ab78f0c8&three_category_id=15;must"
self.db = pymysql.connect(host='localhost', port=3306, user='root', password='root', db='py_spider')
self.cursor = self.db.cursor()
self.url_queue = Queue()
self.parse_queue = Queue()
self.save_queue = Queue()
def get_page_url(self):
"""添加分页url"""
for page in range(1, 4):
url = self.api_url.format(page)
self.url_queue.put(url)
def get_work_info(self):
"""获取响应并解析"""
while True:
url = self.url_queue.get()
headers = {
'User-Agent': self.useragent.random,
'Referer': 'https://list.iqiyi.com/www/2/15-------------11-1-1-iqiyi--.html?s_source=PCW_SC'
}
response=requests.get(url,headers=headers).json()
self.parse_queue.put(response)
self.url_queue.task_done()
def parse_work_info(self):
"""解析响应数据"""
while True:
response=self.parse_queue.get()
titles = jsonpath(response, '$..title')
urls = jsonpath(response, '$..playUrl')
for name, url in zip(titles, urls):
item = dict()
item['名称'] = name
item['链接'] = url
hash_md5=self.get_md5(item)
resdis_result=self.redis_client.sadd('aiqiyi:filter',hash_md5)
if resdis_result:
self.save_csv(item)
self.save_json(item)
self.save_mongo(item)
self.save_queue.put(item)
else:
print('数据重复')
self.parse_queue.task_done()
def save_work_mysql(self):
"""数据保存在mysql"""
sql="""
insert into aiqiyi_info values (
%s,%s,%s
)
"""
while True:
item=self.save_queue.get()
print(item)
try:
self.cursor.execute(sql,(0,item["名称"],item['链接']))
self.db.commit()
print('mysql数据保存成功',item)
except Exception as e:
print('保存数据失败',e)
self.save_queue.task_done()
def save_csv(self,item):
"""保存数据到csv"""
with open('aiqiyi.csv','a',encoding='utf-8',newline='')as f:
f_csv=csv.DictWriter(f,['名称','链接'])
if not self.header_written:
f_csv.writeheader()
self.header_written=True
f_csv.writerow(item)
def save_json(self,item):
"""保存数据到json"""
with open('aiqiyi.json','a',encoding="utf-8")as f:
f.write(json.dumps(item,indent=2,ensure_ascii=False)+',')
def save_mongo(self,item):
"""保存数据到mongodb"""
self.mongo_db.insert_one(item)
print('mongo保存数据成功:',item)
def __del__(self):
print('数据库即将关闭')
self.redis_client.close()
self.mongo_client.close()
@staticmethod
def get_md5(item):
"""加密成md5"""
md5=hashlib.md5(str(item).encode('utf-8')).hexdigest()
return md5
def create_table(self):
"""创建mysql的表"""
sql="""
create table if not exists aiqiyi_info(
id int primary key auto_increment,
title varchar(100) not null,
url varchar(100) not null
)
"""
try:
self.cursor.execute(sql)
print('创建表成功')
except Exception as e:
print(e)
print('创建表失败。。。')
def main(self):
self.create_table()
thread_list=list()
t_url=threading.Thread(target=self.get_page_url)
thread_list.append(t_url)
for _ in range(3):
t_work_info=threading.Thread(target=self.get_work_info)
thread_list.append(t_work_info)
for _ in range(2):
t_parse_info=threading.Thread(target=self.parse_work_info)
thread_list.append(t_parse_info)
t_save_mysql=threading.Thread(target=self.save_work_mysql)
thread_list.append(t_save_mysql)
for thread_obj in thread_list:
thread_obj.daemon=True
thread_obj.start()
#判断所有队列中的任务是否完成
for queue in [self.url_queue,self.parse_queue,self.save_queue]:
queue.join()
print('主线程结束。。。')
if __name__ == '__main__':
a=AiQiYiSpider()
a.main()
线程池
import pymysql
import requests
from dbutils.pooled_db import PooledDB
from fake_useragent import UserAgent
from concurrent.futures import ThreadPoolExecutor,as_completed
class BaiDuWork:
def __init__(self):
self.pool=PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=3, # 设置线程之间的共享连接
blocking=True, # 连接耗尽则等待直至有可用的连接为止
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
host='localhost',
port=3306,
user='root',
password='root',
database='py_spider',
charset='utf8'
)
self.api_url="https://talent.baidu.com/httservice/getPostListNew"
self.useragent=UserAgent()
def get_work_info(self,page):
"""获取页面信息"""
post_form= {
"recruitType": "SOCIAL",
"pageSize": "10",
"keyWord": "python",
"curPage": "1",
"projectType":""
}
headers={
"User-Agent":self.useragent.random,
"Referer":"https://talent.baidu.com/jobs/social-list?search=python"
}
response=requests.post(self.api_url,headers=headers,data=post_form).json()
return response
def parse_work_info(self, response):
works = response['data']['list']
for work_info in works:
education = work_info['education'] if work_info['education'] else '空'
name = work_info['name']
service_condition = work_info['serviceCondition']
self.save_work_info(0, name, education, service_condition)
def save_work_info(self,*args):
"""
保存信息
:param args: id,name, education, service_condition
:return:
"""
with self.pool.connection()as db:
with db.cursor() as cursor:
sql="""
insert into baidu_work_thread values (%s,%s,%s,%s);
"""
try:
cursor.execute(sql,args)
db.commit()
print('数据保存成功:',args)
except Exception as e:
print('数据保存失败:',e)
db.rollback()
def create_table(self):
with self.pool.connection()as db:
with db.cursor() as cursor:
sql="""
create table if not exists baidu_work_thread(
id int primary key auto_increment,
name varchar(100),
education varchar(100),
service_condition text
)
"""
try:
cursor.execute(sql)
print('创建表成功。。。')
except Exception as e:
print('创建表失败:',e)
def main(self):
self.create_table()
with ThreadPoolExecutor(max_workers=5)as pool:
futures=[pool.submit(self.get_work_info,page) for page in range(1,30)]
for future in as_completed(futures):
pool.submit(self.parse_work_info,future.result())
if __name__ == '__main__':
b=BaiDuWork()
b.main()
多进程
import time
import redis
import requests
import hashlib
import pymongo
from fake_useragent import UserAgent
from multiprocessing import JoinableQueue as Queue, Process
class MOGuoSpider:
redis_client = redis.Redis()
mongo_client = pymongo.MongoClient("localhost", 27017)
collection = mongo_client['py_spider']['moguo_info']
useragent = UserAgent()
def __init__(self):
self.url = "https://pianku.api.mgtv.com/rider/list/pcweb/v3"
self.params_queue = Queue()
self.json_queue = Queue()
self.content_queue = Queue()
def put_page_info(self):
"""添加url"""
for page in range(1, 5):
params_dict = {
"allowedRC": "1",
"platform": "pcweb",
"channelId": "2",
"pn": page,
"pc": "80",
"hudong": "1",
"_support": "10000000",
"kind": "19",
"area": "10",
"year": "all",
"chargeInfo": "a1",
"sort": "c2",
"feature": "all"
}
self.params_queue.put(params_dict)
def get_work_info(self):
"""获取页面信息"""
while True:
headers = {
"User-Agent": self.useragent.random
}
params = self.params_queue.get()
response = requests.get(self.url, headers=headers,params=params).json()
self.json_queue.put(response)
self.params_queue.task_done()
def parse_work_info(self):
"""数据提取"""
while True:
response = self.json_queue.get()
movie_list = response['data']['hitDocs']
for movie in movie_list:
item = dict()
item['title'] = movie['title']
item['subtitle'] = movie['subtitle']
item['story'] = movie['story']
self.content_queue.put(item)
self.json_queue.task_done()
@staticmethod
def get_md5(item):
"""去重"""
md5 = hashlib.md5(str(item).encode('utf-8')).hexdigest()
return md5
def save_work_info(self):
"""保存信息"""
while True:
item = self.content_queue.get()
hash_md5 = self.get_md5(item)
result = self.redis_client.sadd('moguo:filter', hash_md5)
if result:
self.collection.insert_one(item)
print('数据保存成功:', item)
else:
print('数据重复')
self.content_queue.task_done()
def close_spider(self):
"""关闭数据库"""
print('数据库即将关闭')
self.redis_client.close()
self.mongo_client.close()
def main(self):
process_list = list()
url_process = Process(target=self.put_page_info)
process_list.append(url_process)
get_work_process = Process(target=self.get_work_info)
process_list.append(get_work_process)
parse_work_process = Process(target=self.parse_work_info)
process_list.append(parse_work_process)
save_work_process = Process(target=self.save_work_info)
process_list.append(save_work_process)
for process_obj in process_list:
process_obj.daemon = True
process_obj.start()
time.sleep(2)
for q in [self.params_queue, self.json_queue, self.content_queue]:
q.join()
self.close_spider()
if __name__ == '__main__':
m = MOGuoSpider()
m.main()
进程池
import time
import redis
import requests
import hashlib
import pymongo
from fake_useragent import UserAgent
from multiprocessing import JoinableQueue as Queue, Process, Pool
class MOGuoSpider:
redis_client = redis.Redis()
mongo_client = pymongo.MongoClient("localhost", 27017)
collection = mongo_client['py_spider']['moguo_info']
useragent = UserAgent()
def __init__(self):
self.url = "https://pianku.api.mgtv.com/rider/list/pcweb/v3"
def get_work_info(self, params):
"""获取页面信息"""
headers = {
"User-Agent": self.useragent.random
}
response = requests.get(self.url, headers=headers, params=params).json()
return response
def parse_work_info(self, response):
"""数据提取"""
movie_list = response['data']['hitDocs']
item_list = list()
for movie in movie_list:
item = dict()
item['title'] = movie['title']
item['subtitle'] = movie['subtitle']
item['story'] = movie['story']
item_list.append(item)
return item_list
@staticmethod
def get_md5(item):
"""去重"""
md5 = hashlib.md5(str(item).encode('utf-8')).hexdigest()
return md5
def save_work_info(self, item):
"""保存信息"""
hash_md5 = self.get_md5(item)
result = self.redis_client.sadd('moguo:filter', hash_md5)
if result:
self.collection.insert_one(item)
print('数据保存成功:', item)
else:
print('数据重复')
def close_spider(self):
"""关闭数据库"""
print('数据库即将关闭')
self.redis_client.close()
self.mongo_client.close()
def main(self):
p = Pool(3)
result_list = list()
for page in range(1, 4):
params_dict = {
"allowedRC": "1",
"platform": "pcweb",
"channelId": "2",
"pn": page,
"pc": "80",
"hudong": "1",
"_support": "10000000",
"kind": "19",
"area": "10",
"year": "all",
"chargeInfo": "a1",
"sort": "c2",
"feature": "all"
}
result = p.apply_async(self.get_work_info, args=(params_dict,))
result_list.append(result)
for result in result_list:
save_result = p.apply_async(self.parse_work_info, args=(result.get(),))
for item in save_result.get():
p.apply_async(self.save_work_info, args=(item,))
p.close()
p.join()
self.close_spider()
if __name__ == '__main__':
m = MOGuoSpider()
m.main()
协程
import os
import aiofile
import aiohttp
import asyncio
class HeroSkin:
def __init__(self):
self.json_url = 'https://pvp.qq.com/web201605/js/herolist.json'
self.skin_url = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg'
self.headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
async def get_image_content(self, session, e_name, c_name):
"""获取内容并保存"""
for skin_id in range(1, 50): # 每个英雄的最大值
async with session.get(self.skin_url.format(e_name, e_name, skin_id), headers=self.headers) as response:
if response.status == 200:
content = await response.read()
async with aiofile.async_open('./images/' + c_name + '-' + str(skin_id) + '.jpg', 'wb') as f:
await f.write(content)
print('保存图片成功:', c_name)
else:
break
async def main(self):
tasks = list()
async with aiohttp.ClientSession() as session:
async with session.get(self.json_url, headers=self.headers) as response:
result = await response.json(content_type=None)
for item in result:
e_name = item['ename']
c_name = item['cname']
coro_obj = self.get_image_content(session, e_name, c_name)
tasks.append(asyncio.create_task(coro_obj))
await asyncio.wait(tasks)
if __name__ == '__main__':
path = os.getcwd() + "/images/"
if not os.path.exists(path):
os.mkdir(path)
h = HeroSkin()
loop = asyncio.get_event_loop()
loop.run_until_complete(h.main())
自动化测试框架
安装
pip install selenium==4.9.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
谷歌驱动下载地址:https://googlechromelabs.github.io/chrome-for-testing/#stable
火狐驱动下载地址:https://github.com/mozilla/geckodriver/releases
Edge驱动下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?form=MA13LH
测试
import time
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
time.sleep(2)
基本使用
import time
from selenium import webdriver
from selenium.webdriver.common.by import By#元素定位的类
from selenium.webdriver.chrome import service # 指定驱动路径的
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC # 内置异常库
from selenium.webdriver import ActionChains #动作链
from selenium.common.exceptions import NoSuchElementException #异常库
#浏览器检测问题
# # 创建浏览器配置对象
# options = webdriver.ChromeOptions()
# # 将浏览器配置载入到配置对象中
# options.add_argument('--disable-blink-features=AutomationControlled')
#
# #创建浏览器对象
# driver=webdriver.Chrome(options=options)
#参数配置
# # 创建浏览器配置对象
# options = webdriver.ChromeOptions()
#
# # 禁止图片加载
# prefs = {"profile.managed_default_content_settings.images": 2}
# options.add_experimental_option('prefs', prefs)
#
# # 设置UA
# user_agent = 'abc'
# options.add_argument(f'user-agent={user_agent}')
#
#
# # 去除开发者警告
# options.add_experimental_option('useAutomationExtension', False)
# options.add_experimental_option('excludeSwitches', ['enable-automation'])
#
#
# # 设置代理
# options.add_argument("--proxy-server=http://127.0.0.1:7890")
#
#
#
# browser = webdriver.Chrome(options=options)
# browser.get('https://www.taobao.com/')
#
# time.sleep(10)
# browser.quit()
# #获取网页地址
# driver.get("https://www.baidu.com")
# #页面截图
# driver.save_screenshot("百度首页.png")
# #页面元素定位
# driver.get("https://www.baidu.com")
# #定位元素并操作
# driver.find_element(By.ID,'kw').send_keys("python")
# time.sleep(1)
# #点击
# driver.find_element(By.ID,'su').click()
# time.sleep(2)
# #获取文本信息
# result=driver.find_element(By.XPATH,'//div[@class="s_tab_inner s_tab_inner_81iSw"]')
# print(result.text)
# #获取属性信息
# result1=driver.find_element(By.LINK_TEXT,'图片')
# print(result1.get_attribute('href'))
"""
find_element: 用于查询指定的标签
By: 用于指定查询方法: xpath方法、id查询、标签名称查询、css选择器查询等等
send_keys: 一般用于输入框, 在输入框中输入指定的关键字
click: 一般用于按钮, 可以点击
"""
#查看响应信息
# #查看访问成功的页面源码:渲染之后的源码
# print(driver.page_source)
# print('*'*50)
# #查看cookie信息
# print(driver.get_cookies())
# cookie_list=driver.get_cookies()
# for temp in cookie_list:
# print(temp)
#cookie结构处理
# cookie_dict={x["name"]:x["value"] for x in cookie_list}
# print(cookie_dict)
#删除cookie
##删除所有cookie
# driver.delete_all_cookies()
# print(driver.get_cookies())
##删除指定cookie
# driver.delete_cookie("BAIDUID")
# cookie_list=driver.get_cookies()
# cookie_dict={x["name"]:x["value"] for x in cookie_list}
# print(cookie_dict)
##添加指定cookie
# driver.add_cookie({'name':'吕布','value':'安娜'})
# cookie_list=driver.get_cookies()
# cookie_dict={x["name"]:x["value"] for x in cookie_list}
# print(cookie_dict)
# #查看目标地址的url
# print(driver.current_url)
#浏览器操作部分
# #在原有的标签中访问新网址
# driver.get('https://www.bing.com')
# time.sleep(2)
# driver.get('https://www.jd.com')
# time.sleep(3)
# # 如果代码执行完毕, 可以使用close方法关闭标签页, 如果标签页只有一个则关闭浏览器
# # driver.close()
# #使用js代码开启新标签页
# js_code="window.open('https://www.sogou.com')"
# driver.execute_script(js_code)
# time.sleep(3)
#
# # 标签页的切换问题: 只有两个标签页的场景
# print('标签页列表:',driver.window_handles)
# driver.switch_to.window(driver.window_handles[0]) # 切换第一个标签页
# time.sleep(3)
# driver.switch_to.window(driver.window_handles[1]) # 切换第二个标签页
# time.sleep(2)
# frame切换
# iframe = driver.find_element(By.XPATH, '//div[@id="loginDiv"]/iframe')
# driver.switch_to.frame(iframe)
# # 自定义驱动文件地址
# service = service.Service(executable_path='./chromedriver')
#
#
# driver = webdriver.Chrome(service=service)
# driver.get('https://www.baidu.com')
# driver.maximize_window()
#等待
##创建驱动等待对象
# wait_obj=WebDriverWait(driver,10)
# driver.get('https://www.jd.com')
# ##等待指定的标签数据:搜索框
# # presence_of_element_located: 参数必须是一个元组
# search_input = wait_obj.until(EC.presence_of_element_located((By.ID, 'key')))
# print(search_input)
"""
等待对象:WebDriverWait
需要传递浏览器对象和超时时间
使用presence_of_element_located判断标签是否加载完成
"""
#页面的前进与后退
# driver.get('https://www.baidu.com')
# time.sleep(1)
# # driver.get('https://www.jd.com')
# # time.sleep(1)
# # js_code="window.open('https://www.jd.com')"
# # driver.execute_script(js_code)
# time.sleep(1)
# driver.back()#回退
# time.sleep(1)
# driver.forward()#前进
# time.sleep(1)
#页面滚动
# driver.get('https://36kr.com/')
#
# # 利用js操作网站滚动
# # js_code = 'window.scrollTo(0, 2000)' # 绝对位置
# # browser.execute_script(js_code)
# # time.sleep(2)
#
# for num in range(1, 10):
# driver.execute_script(f'window.scrollBy(0, {num * 1000})') # 相对位置
# time.sleep(1)
# driver.quit()
#动作链
# browser = webdriver.Chrome()
# browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
#
# iframe = browser.find_element(By.XPATH, '//iframe[@id="iframeResult"]')
# browser.switch_to.frame(iframe)
#
# source = browser.find_element(By.ID, 'draggable')
# target = browser.find_element(By.ID, 'droppable')
#
# # 创建动作链对象
# actions = ActionChains(browser)
# actions.drag_and_drop(source, target)
# actions.perform() # 动作激活
#
# time.sleep(3)
# browser.quit()
#内置异常
# browser = webdriver.Chrome()
#
# try:
# browser.find_element(By.ID, 'hello')
# except NoSuchElementException:
# print('No Element')
# finally:
# browser.close()
案例
import time
from random import randint
from pymongo import MongoClient
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class WPHShop:
mongo_client=MongoClient()
collection=mongo_client["py_spider"]['wp_spider']
def __init__(self):
#创建浏览器配置
options=webdriver.ChromeOptions()
#屏幕图片
prefs = {"profile.managed_default_content_settings.images": 2}
options.add_experimental_option('prefs', prefs)
#驱动设置
self.driver=webdriver.Chrome(options=options)
def base(self):
"""获取唯品会首页并搜索指定商品"""
self.driver.get('https://www.vip.com')
wait=WebDriverWait(self.driver,10)
el_input=wait.until(EC.presence_of_element_located(
(By.XPATH, "//input[@class='c-search-input J-search-input']")
))
el_input.send_keys('电脑')
el_button = wait.until(EC.presence_of_element_located(
(By.XPATH, "//a[@class='c-search-button J-search-button J_fake_a']")
))
time.sleep(2)
el_button.click()
# 当前页面成功获取之后建议延迟 1-3秒 让浏览器滚动
time.sleep(randint(1, 3))
def drop_down(self):
"""页面滚动"""
for i in range(1, 12):
js_code = f'document.documentElement.scrollTop = {i * 1000}'
self.driver.execute_script(js_code)
time.sleep(randint(1, 2))
def parse_data(self):
"""数据提取"""
self.drop_down()
div_list = self.driver.find_elements(
By.XPATH,
'//section[@id="J_searchCatList"]/div[@class="c-goods-item J-goods-item c-goods-item--auto-width"]'
)
for div in div_list:
price = div.find_element(
By.XPATH,
'.//div[@class="c-goods-item__sale-price J-goods-item__sale-price"]'
).text
title = div.find_element(
By.XPATH,
'.//div[2]/div[2]'
).text
item = {
'title': title,
'price': price
}
print(item)
self.save_mongo(item)
self.next_page() # 当前页面获取完成之后需要点击下一页
@classmethod
def save_mongo(cls, item):
"""数据保存"""
cls.collection.insert_one(item)
def next_page(self):
"""翻页"""
try:
next_button = self.driver.find_element(By.XPATH, '//*[@id="J_nextPage_link"]')
if next_button:
next_button.click()
self.parse_data() # 进入到下一页需要重新解析页面数据
else:
self.driver.close()
except Exception as e:
print('最后一页: ', e)
self.driver.quit()
def main(self):
"""启动函数"""
self.base()
self.parse_data()
if __name__ == '__main__':
w=WPHShop()
w.main()
pyppeteer框架
安装
pip install pyppeteer==1.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
基本使用
import asyncio
from pyppeteer import launch
async def main():
#创建浏览器对象
#默认不启动浏览器界面
browser=await launch({'headless':False})#开启浏览器界面
page=await browser.newPage()
await page.goto('https://www.baidu.com')
await page.screenshot({'path':'./百度.png'})
await browser.close()
loop =asyncio.get_event_loop()
loop.run_until_complete(main())

import asyncio
from pyppeteer import launch
#手动设置浏览器窗口大小
width,height=1366,768
async def main():
#创建浏览器对象
#默认不启动浏览器界面
browser=await launch(headless=False,args=['--disable-infobars',f'--window-size={width},{height}'])
page=await browser.newPage()
await page.setViewport({'width':width,'height':height})
await page.goto('https://bot.sannysoft.com/')
# await page.screenshot({'path':'./百度.png'})
await asyncio.sleep(10)
await browser.close()
loop =asyncio.get_event_loop()
loop.run_until_complete(main())
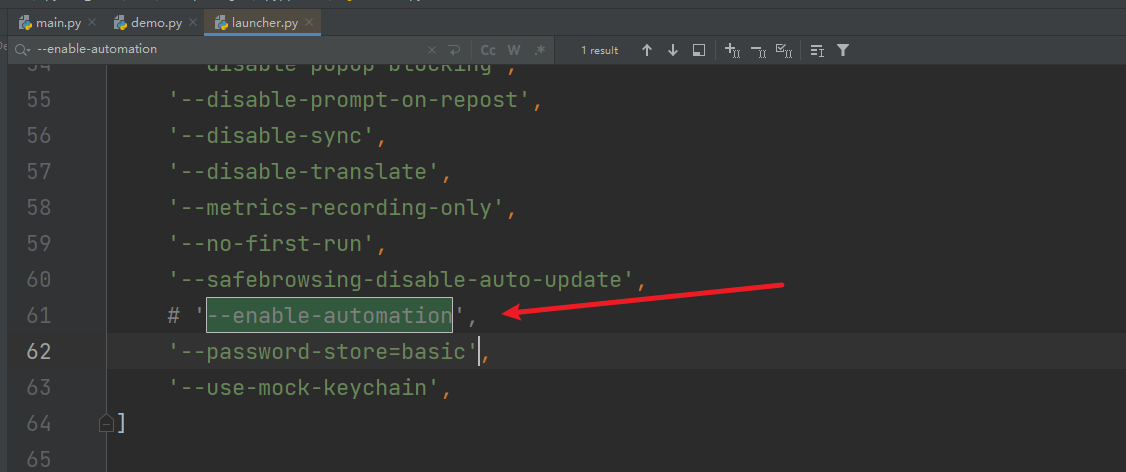
#绕过检测
"""
在launch源码中注释以下参数即可:
--enable-automation
"""
案例
import asyncio
from pyppeteer import launch
async def get_movies(page,url):
"""获取内容"""
await page.goto(url)
titile_elements=await page.xpath('//div[@class="item"]//div[@class="hd"]/a/span[1]')
#提取电影标题文本
titles=list()
for element in titile_elements:
title=await page.evaluate('(element)=>element.textContent',element)
# print(title)
titles.append(title)
#回调
# 获取下一页的数据
next_page = await page.xpath('//span[@class="next"]/a')
if next_page:
next_page_url = await page.evaluate('(element) => element.href', next_page[0])
titles.extend(await get_movies(page, next_page_url))
return titles
async def main():
"""启动函数"""
browser=await launch(headless=False)
page=await browser.newPage()
try:
url="https://movie.douban.com/top250"
titiles=await get_movies(page,url)
print(titiles)
except Exception as e:
print(e)
finally:
await browser.close()
loop=asyncio.get_event_loop()
loop.run_until_complete(main())
IP学习
免费
import re
import json
import requests
class FreeIp:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
def get_ip(self, page):
url = f'https://www.kuaidaili.com/free/dps/{page}'
response = requests.get(url, headers=self.headers).text
try:
ip_list = re.findall(r'const fpsList = (.*?);', response)[0]
ip_pattern = r'"ip": "(\d{1,3}(?:\.\d{1,3}){3})"'
port_pattern = r'"port": "(\d{1,5})"'
ips = re.findall(ip_pattern, ip_list)
ports = re.findall(port_pattern, ip_list)
for temp in zip(ips, ports):
ip_dict = dict()
ip_dict['ip'] = temp[0]
ip_dict['port'] = temp[1]
yield ip_dict
except:
print('页面信息不存在...')
def test_ip(self, max_page_num):
for page_num in range(1, max_page_num + 1):
for result in self.get_ip(page_num):
proxies = {
'http': 'http://' + result['ip'] + ':' + result['port'],
'https': 'http://' + result['ip'] + ':' + result['port'],
}
try:
response = requests.get('http://httpbin.org/ip', headers=self.headers, proxies=proxies, timeout=3)
if response.status_code == 200:
print(response.text)
with open('success_ip.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(proxies, ensure_ascii=False, indent=4) + '\n')
except Exception as e:
print('请求超时:', e)
free_ip = FreeIp()
free_ip.test_ip(10)
if __name__ == '__main__':
free_ip = FreeIp()
free_ip.get_ip(1)
付费
import requests
# 提取代理API接口,获取1个代理IP
api_url = "https://dps.kdlapi.com/api/getdps/?secret_id=ovurlzs23j8y3egjs207&signature=n4bqxx2yty2mnkgx4x5r7650pkiu836v&num=1&pt=1&format=text&sep=1"
# 获取API接口返回的代理IP
proxy_ip = requests.get(api_url).text
# 用户名密码认证(私密代理/独享代理)
username = "xxxx"
password = "xxxx"
proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip}
}
# 白名单方式(需提前设置白名单)
# proxies = {
# "http": "http://%(proxy)s/" % {"proxy": proxy_ip},
# "https": "http://%(proxy)s/" % {"proxy": proxy_ip}
# }
# 要访问的目标网页
target_url = "http://httpbin.org/ip"
# 使用代理IP发送请求
response = requests.get(target_url, proxies=proxies)
# 获取页面内容
if response.status_code == 200:
print(response.text)
else:
print('访问异常')
案例
import pymongo
import requests
import threading
from lxml import etree
from queue import Queue
from retrying import retry
from fake_useragent import UserAgent
class DingDingShop:
mongo_client=pymongo.MongoClient()
collection=mongo_client['py_spider']["dingding_shop"]
def __init__(self):
self.url = 'https://search.dangdang.com/?key=java&act=input'
self.headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
# 代理池api
self.ip_url = 'https://dps.kdlapi.com/api/getdps/?secret_id=ovurlzs23j8y3egjs207&signature=n4bqxx2yty2mnkgx4x5r7650pkiu836v&num=1&pt=1&format=text&sep=1'
# 队列对象
self.ip_queue = Queue()
self.url_queue = Queue()
self.response_queue = Queue()
self.detail_queue = Queue()
def get_ip(self):
"""获取ip并上传到ip队列"""
proxy_ip = requests.get(self.ip_url).text
self.ip_queue.put(proxy_ip)
def get_goods_index(self):
"""访问页面首页并返回响应对象"""
response = requests.get(self.url, headers=self.headers)
if response.status_code==200:
return response
else:
print('请求失败',response.status_code)
def get_page_num(self, response):
"""获取商品列表翻页数据"""
tree = etree.HTML(response.text)
max_page = tree.xpath("//ul[@name='Fy']/li[last()-2]/a/text()")[0]
if max_page:
for page in range(1, int(max_page) + 1):
url = f'https://search.dangdang.com/?key=java&act=input&page_index={page}'
self.url_queue.put(url)
else:
self.url_queue.put(self.url)
@retry(stop_max_attempt_number=5)
def get_goods_list(self):
"""访问翻页地址"""
while True:
if self.ip_queue.empty():#判断ip队列是否为空
self.get_ip()
proxy_ip = self.ip_queue.get()
url = self.url_queue.get()
# 在出现异常之前调用task_done
self.url_queue.task_done()
username = 'xxx'
password = 'xxx'
proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password,
"proxy": proxy_ip},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password,
"proxy": proxy_ip}
}
self.headers['User-Agent'] = UserAgent().random
response = requests.get(url, headers=self.headers, proxies=proxies, timeout=5)
# print('UA池信息:', self.headers)
self.response_queue.put(response)
# 代理重用
if response.status_code == 200:
print('当前代理ip已请求成功:', proxy_ip)
self.ip_queue.put(proxy_ip)
else:
print('代理不可用...')
def parse_info(self):
"""数据解析"""
while True:
response = self.response_queue.get()
tree = etree.HTML(response.text)
li_list = tree.xpath("//ul[@class='bigimg']/li")
for li in li_list:
item = dict()
goods_name = li.xpath("./a/@title")
goods_price = li.xpath("p[@class='price']/span[1]/text()")
item['goods_name'] = goods_name[0]
item['goods_price'] = goods_price[0] if goods_price else '空'
self.detail_queue.put(item)
self.response_queue.task_done()
def save_info(self):
"""数据保存"""
while True:
detail = self.detail_queue.get()
self.collection.insert_one(detail)
print('数据保存成功:', detail)
self.detail_queue.task_done()
def close_spider(self):
self.mongo_client.close()
print('爬虫即将退出, 数据库链接已关闭...')
def main(self):
"""启动函数"""
response = self.get_goods_index()
self.get_page_num(response)
# 线程列表
thread_list = list()
for _ in range(5):
thread_obj = threading.Thread(target=self.get_goods_list)
thread_list.append(thread_obj)
for _ in range(5):
thread_obj = threading.Thread(target=self.parse_info)
thread_list.append(thread_obj)
save_thread = threading.Thread(target=self.save_info)
thread_list.append(save_thread)
for temp in thread_list:
temp.daemon = True
temp.start()
for queue in [self.url_queue, self.response_queue, self.detail_queue]:
queue.join()
# 关闭爬虫
self.close_spider()
if __name__ == '__main__':
d=DingDingShop()
d.main()
Scrapy框架学习
安装
# 注意: 需要将scrapy框架限制在2.6.3版本
pip install scrapy==2.6.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
创建项目
#scrapy startproject 项目名称
scrapy startproject mySpider
创建爬虫
# scrapy genspider 爬虫名 允许爬取的域名
scrapy genspider baidu baidu.com


运行爬虫文件
# 启动命令中的爬虫名称需要和创建时设置的爬虫名称保持一致
scrapy crawl baidu
或
from scrapy import cmdline
cmdline.execute('scrapy crawl baidu'.split())

pip install Twisted==22.10.0

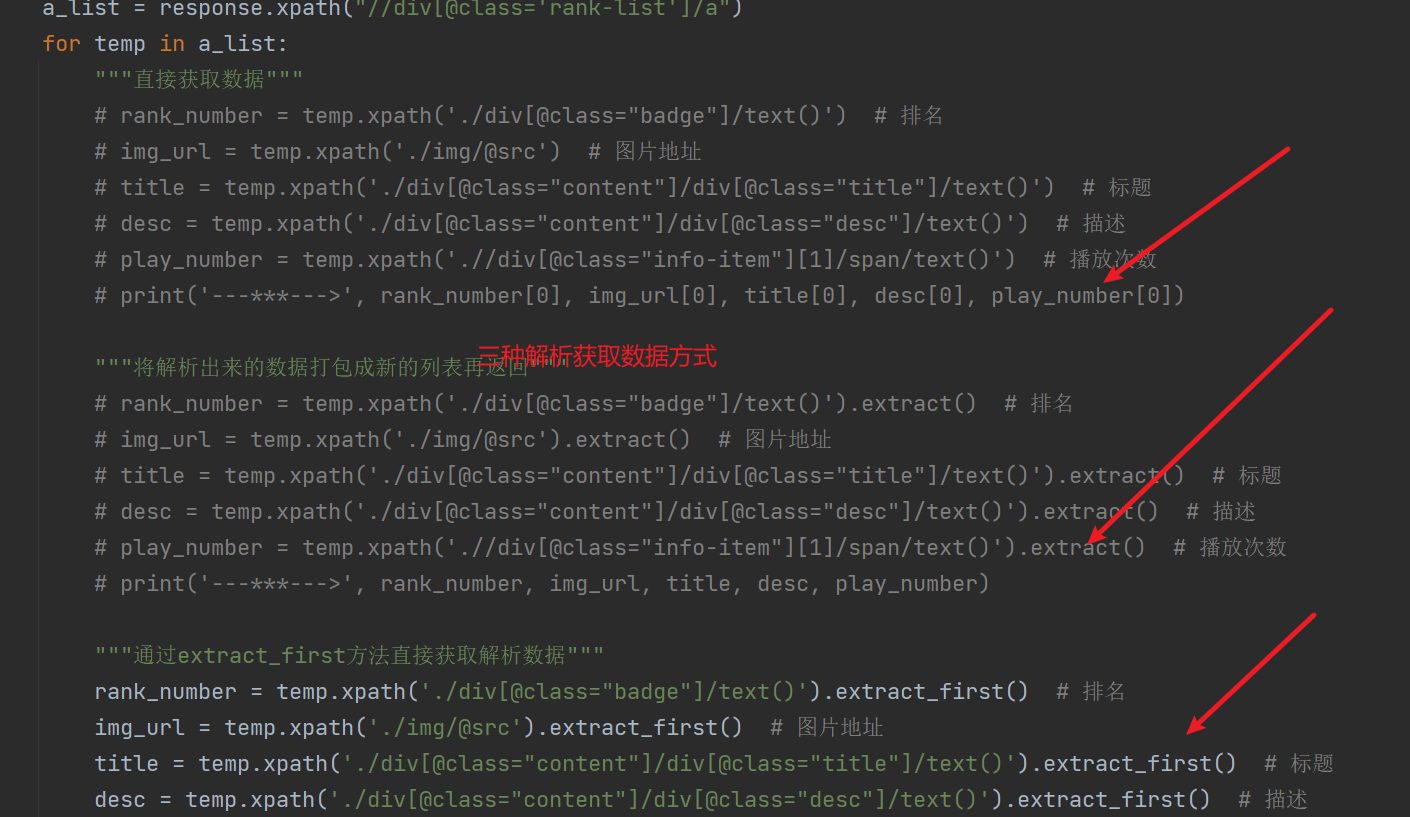
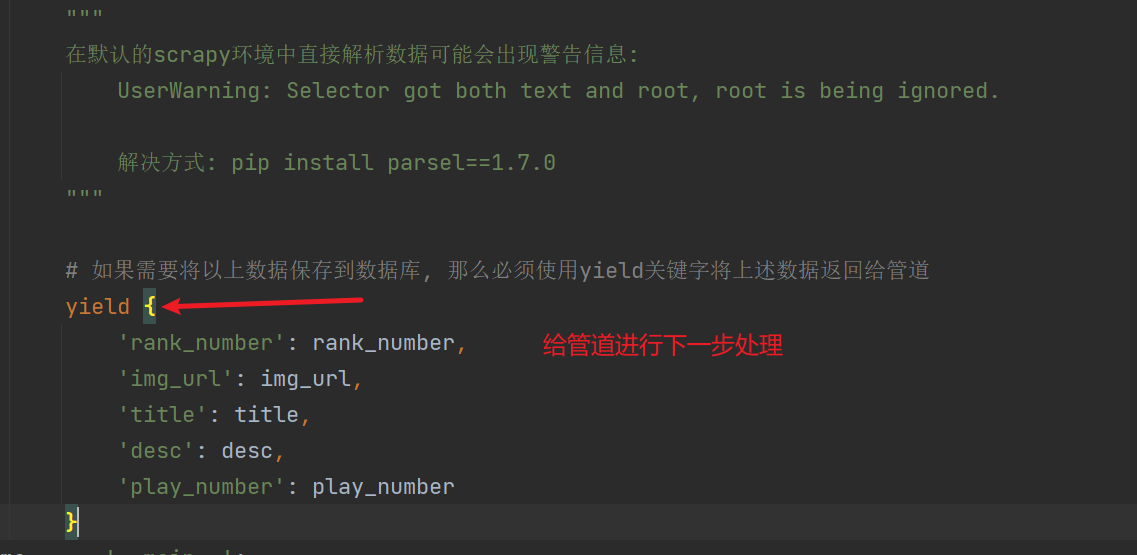
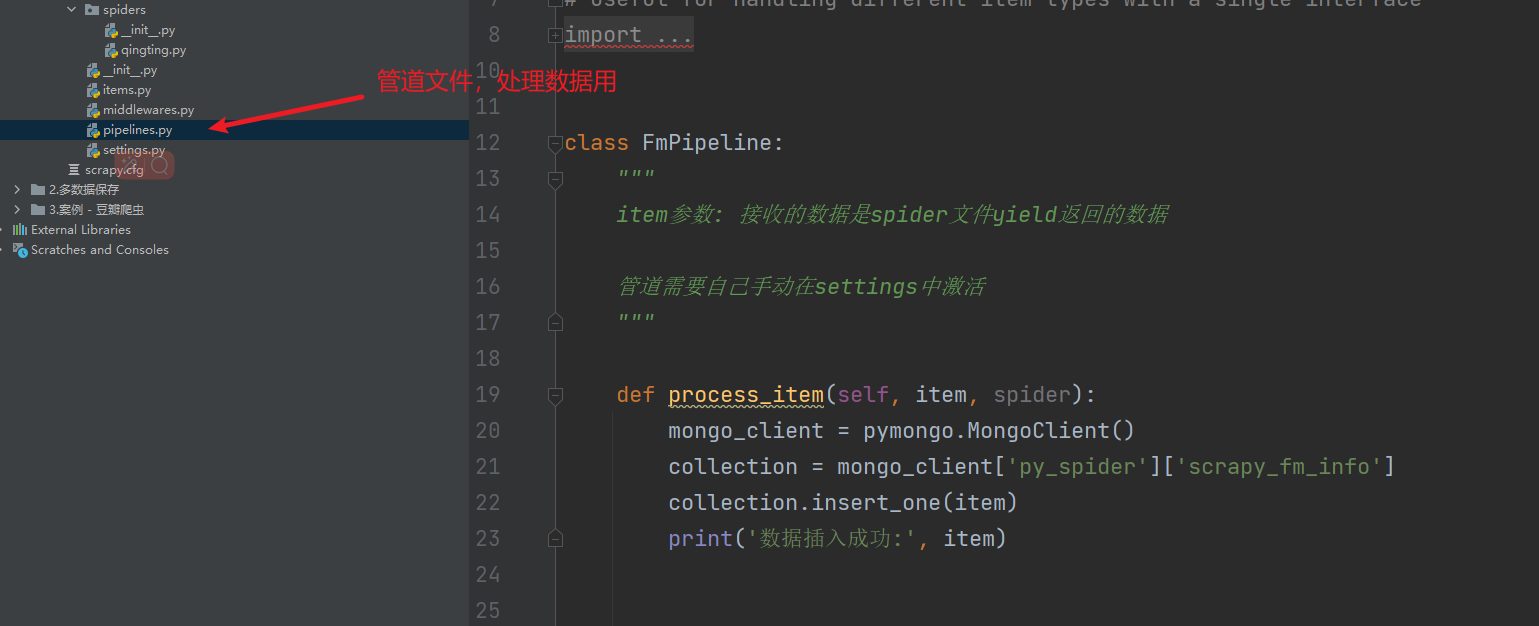

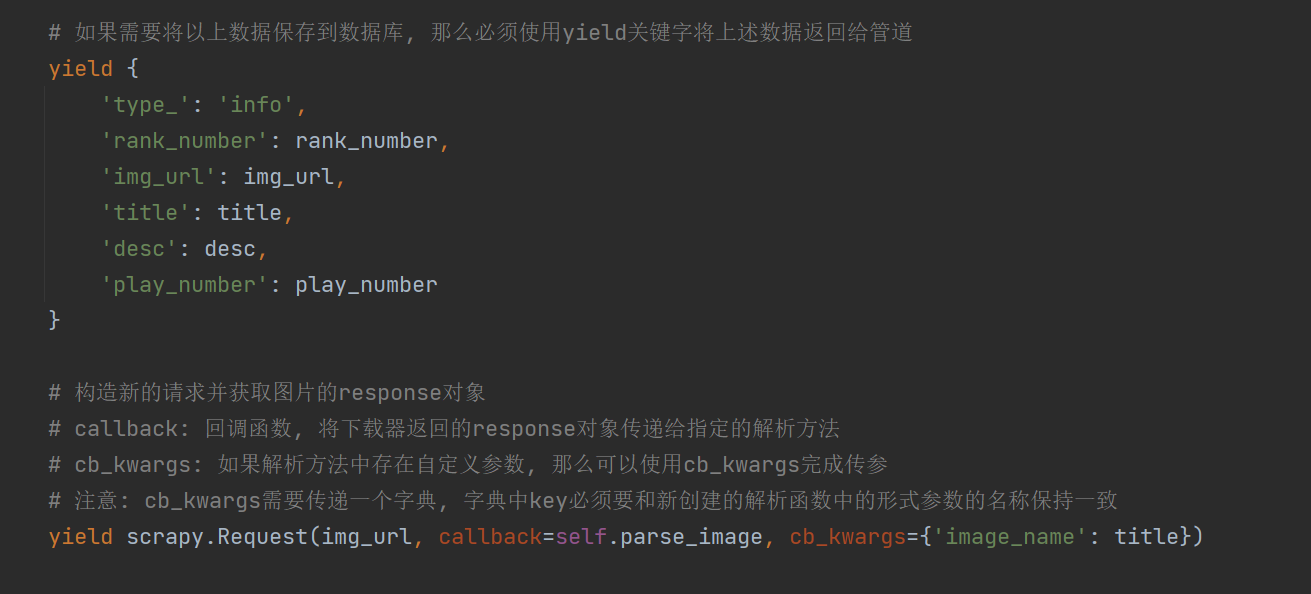
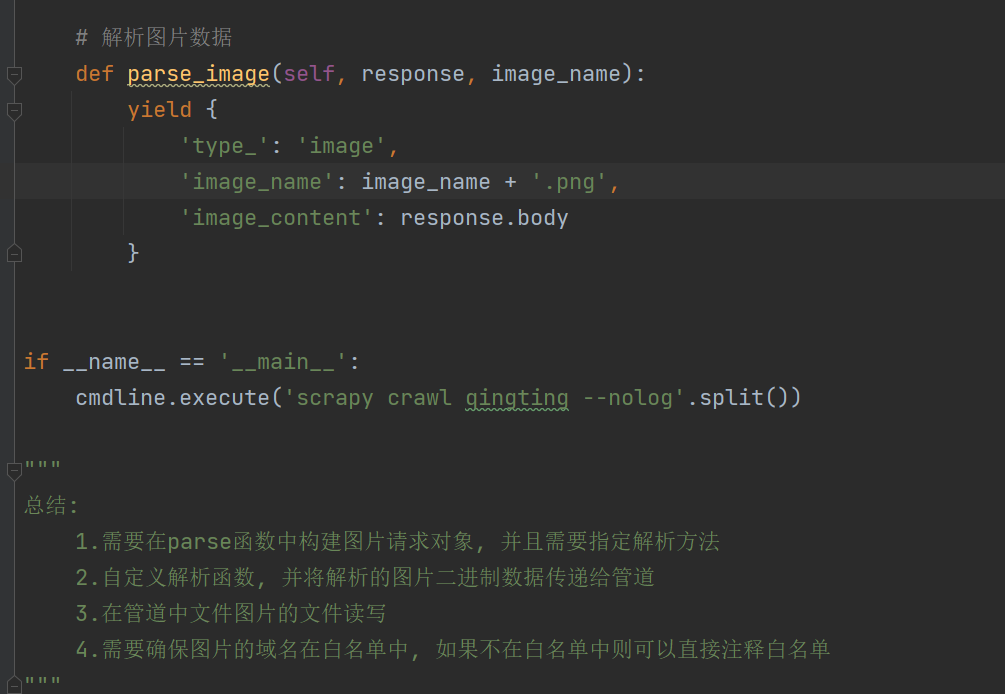
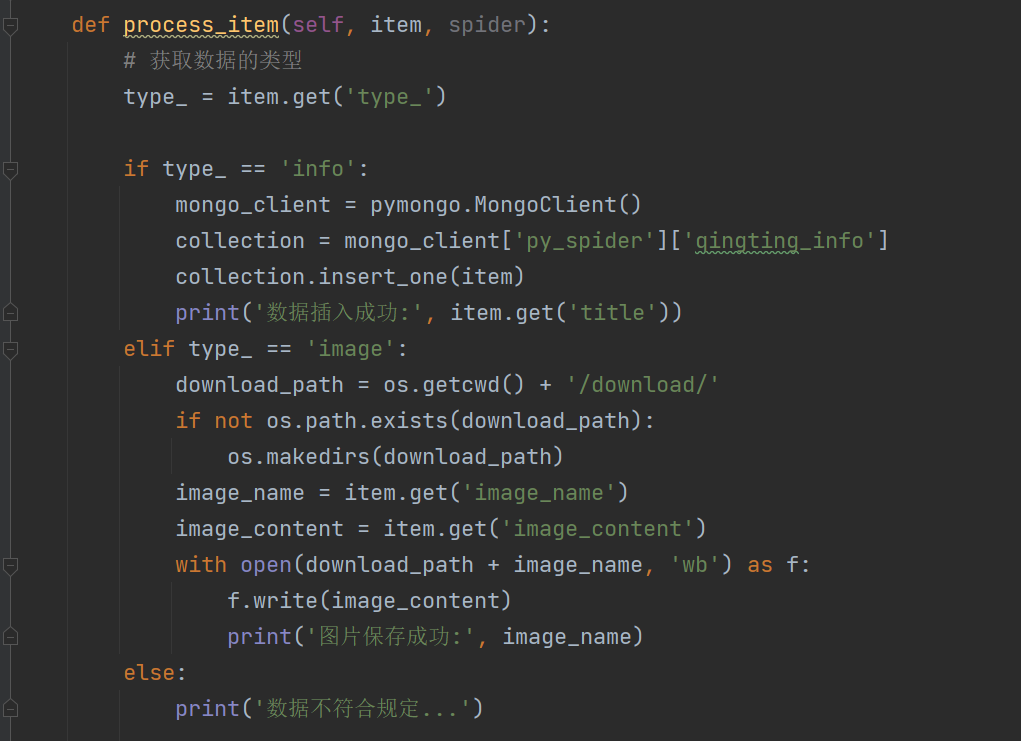



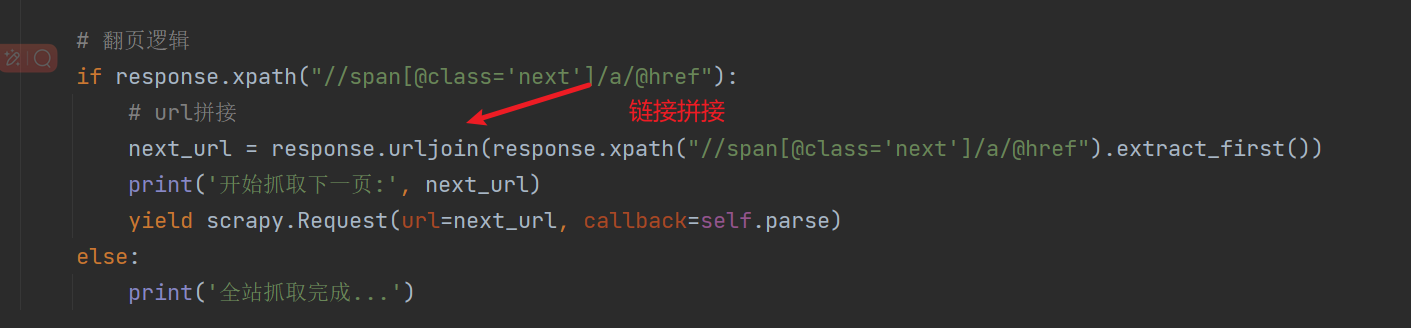
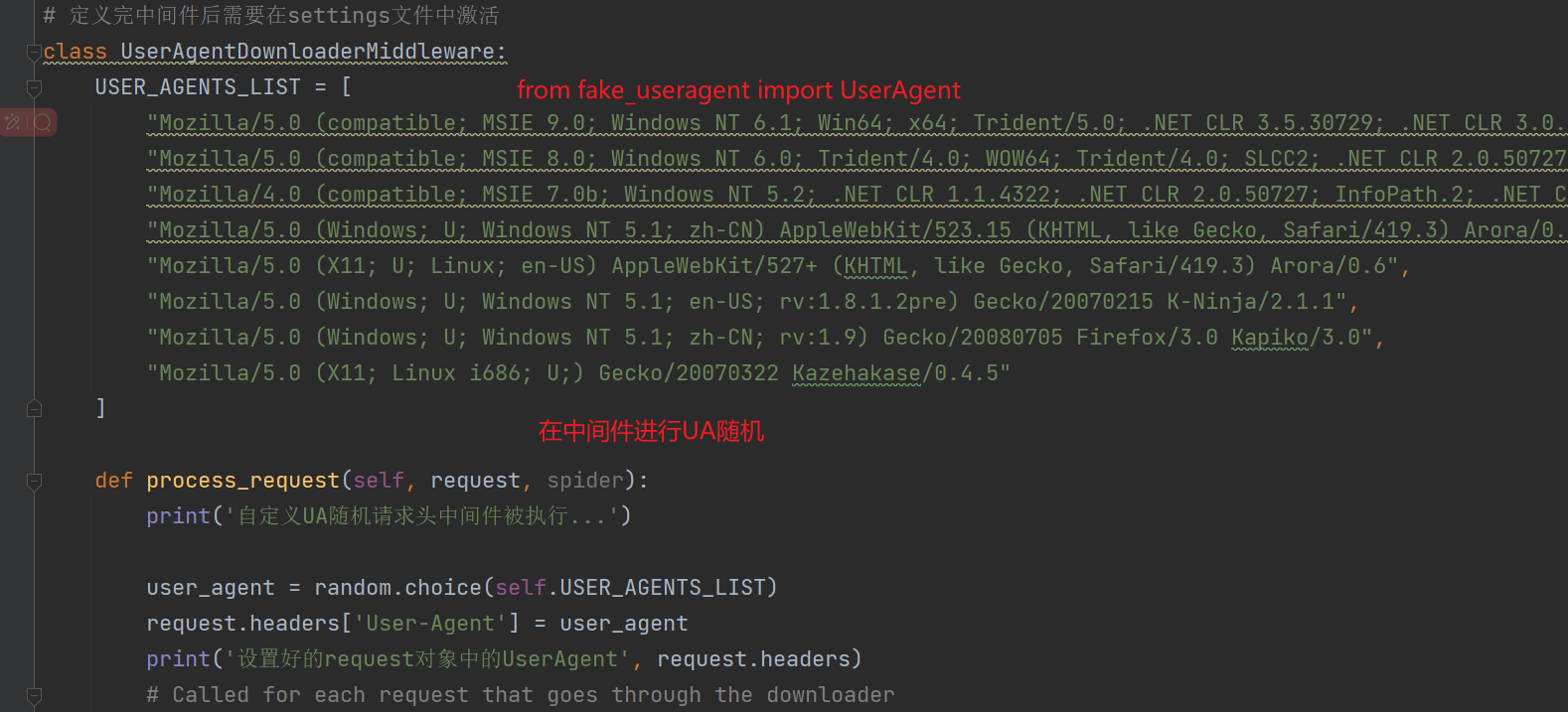

from .proxy_extend import pro
#免费
# class ProxyDownloaderMiddleware:
# def process_request(self, request, spider):
# print('下载中间件 - request')
# request.meta['proxy'] = 'http://127.0.0.1:7890'
# return None
#
# def process_response(self, request, response, spider):
# print('下载中间件 - response')
# if response.status != 200:
# request.dont_filter = True # 关闭过滤
# return request # 如果状态码不为200则重新提交给调度器
# return response
#付费
class ProxyDownloaderMiddleware:
def process_request(self, request, spider):
proxy = random.choice(pro.proxy_list)
# 用户名密码认证(私密代理/独享代理)
username = "账号"
password = "密码"
request.meta['proxy'] = "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password,
"proxy": proxy}
print('付费代理信息为:', request.meta['proxy'])
# 白名单认证(私密代理/独享代理)
# request.meta['proxy'] = "http://%(proxy)s/" % {"proxy": proxy}
return None
#创建proxy_extend.py文件
import time
import threading
import requests
from scrapy import signals # 爬虫信号
api_url = 'https://dps.kdlapi.com/api/getdps/?secret_id=ovurlzs23j8y3egjs207&signature=n4bqxx2yty2mnkgx4x5r7650pkiu836v&num=1&pt=1&format=json&sep=1'
foo = True
class Proxy:
def __init__(self):
self._proxy_list = requests.get(api_url).json().get('data').get('proxy_list')
@property
def proxy_list(self):
return self._proxy_list
@proxy_list.setter
def proxy_list(self, list):
self._proxy_list = list
pro = Proxy()
print(pro.proxy_list)
class ProxyExtend:
def __init__(self, crawler):
self.crawler = crawler
crawler.signals.connect(self.start, signals.engine_started)
crawler.signals.connect(self.close, signals.spider_closed)
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
# 爬虫启动创建线程并启动
def start(self):
t = threading.Thread(target=self.extract_proxy)
t.start()
def extract_proxy(self):
while foo:
pro.proxy_list = requests.get(api_url).json().get('data').get('proxy_list')
# 设置每15秒提取一次ip
time.sleep(15)
def close(self):
global foo
foo = False
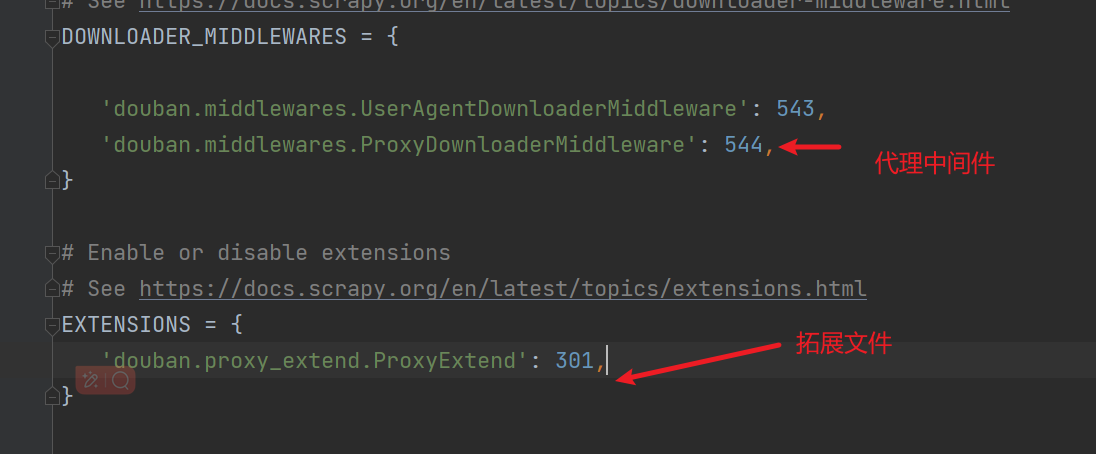
#selenium配置
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class SeleniumDownloaderMiddleware:
def __init__(self):
self.browser = webdriver.Chrome()
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
# scrapy信号检测爬虫任务是否完成, 如果已完成即将退出则在退出之前回调spider_closed
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)
return s
def process_request(self, request, spider):
self.browser.get(request.url)
wait = WebDriverWait(self.browser, 10)
wait.until(EC.presence_of_all_elements_located((
By.CLASS_NAME, 'recruit-list'
)))
# 获取页面信息
body = self.browser.page_source
return scrapy.http.HtmlResponse(url=request.url, body=body, request=request, encoding='utf-8')
def spider_closed(self, spider):
self.browser.quit()
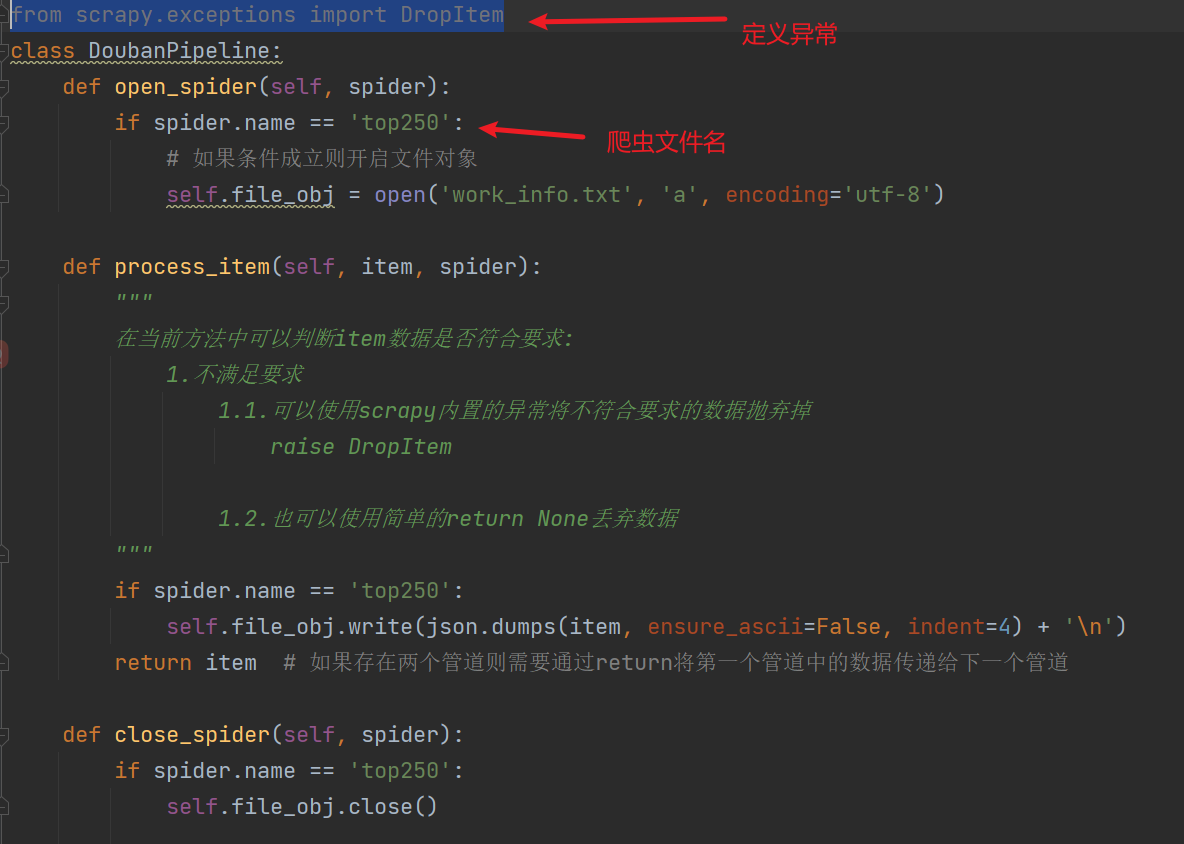
# 针对数据进行去重
class DoubanCheckPipeline:
def open_spider(self, spider):
if spider.name == 'top250':
self.redis_client = redis.Redis()
def process_item(self, item, spider):
if spider.name == 'top250':
item_str = json.dumps(item)
md5_hash = hashlib.md5(item_str.encode()).hexdigest()
if self.redis_client.get(f'top250_info_filter: {md5_hash}'):
raise DropItem('数据重复...')
else:
self.redis_client.set(f'top250_info_filter: {md5_hash}', item_str)
return item
def close_spider(self, spider):
if spider.name == 'top250':
self.redis_client.close()
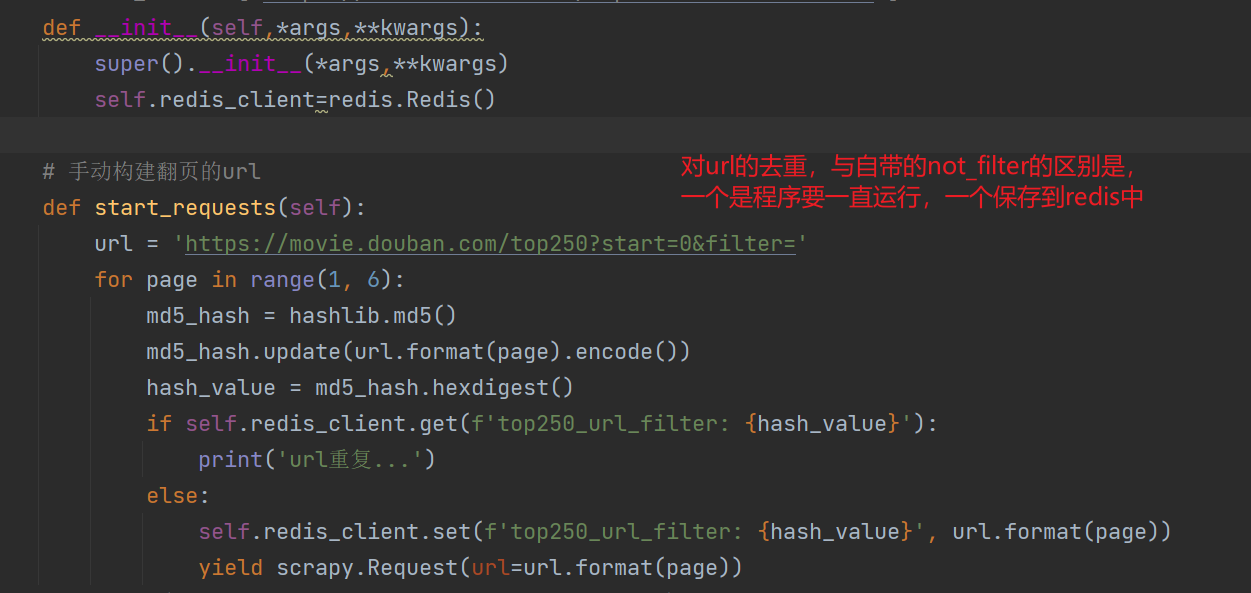
增量爬虫的命令
# scrapy crawl 爬虫名称 -s JOBDIR=缓存scrapy信息的路径
scrapy crawl MySpider -s JOBDIR=crawls/my_spider-1

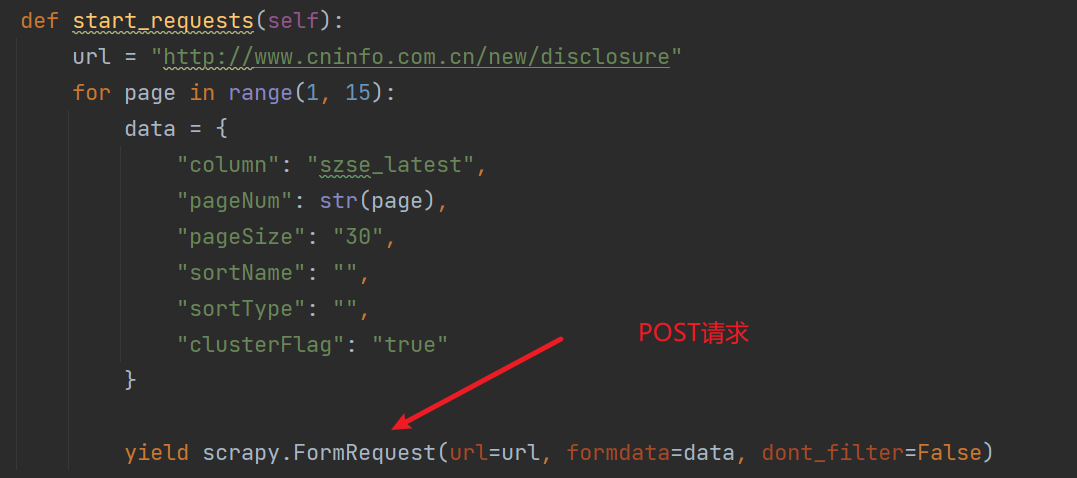
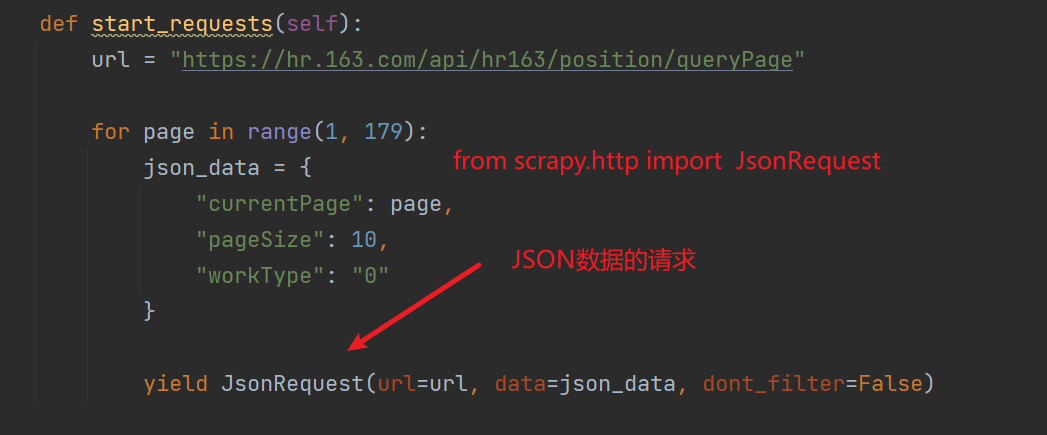
scrapy-redis实现增量爬虫
安装
# 使用scrapy-redis之前最好将scrapy版本保持在2.6.3, 2.11.0版本有兼容性问题
pip install scrapy==2.6.3 scrapy-redis
setting文件配置
""" scrapy-redis配置 """
# 调度器类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 指纹去重类
"""
指纹是指使用哈希值标识一个请求对象
确保每个对象都是唯一的
"""
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 可以替换成布隆过滤器
# 下载 - pip install scrapy-redis-bloomfilter
# from scrapy_redis_bloomfilter.dupefilter import RFPDupeFilter
# DUPEFILTER_CLASS = 'scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter'
# 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_PERSIST = True
# Redis服务器地址
REDIS_URL = "redis://127.0.0.1:6379/0" # Redis默认有16库,/1的意思是使用序号为2的库,默认是0号库(这个可以任意)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 使用有序集合来存储
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' # 先进先出
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # 先进后出、后进先出
# 配置redis管道
# from scrapy_redis.pipelines import RedisPipeline
ITEM_PIPELINES = {
"douban.pipelines.DoubanPipeline": 300,
# 可以将获取到的数据存储在redis中, 如果不期望将数据存储在redis则注释以下中间件
# 'scrapy_redis.pipelines.RedisPipeline': 301
}
# 重爬: 一般不配置,在分布式中使用重爬机制会导致数据混乱,默认是False
# SCHEDULER_FLUSH_ON_START = True
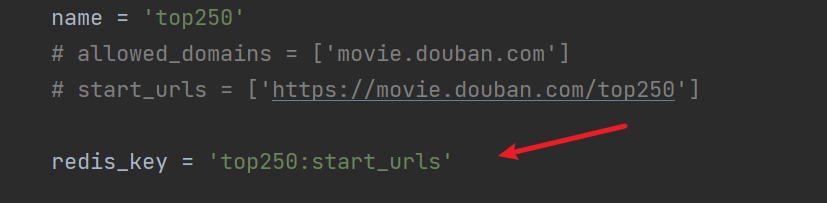
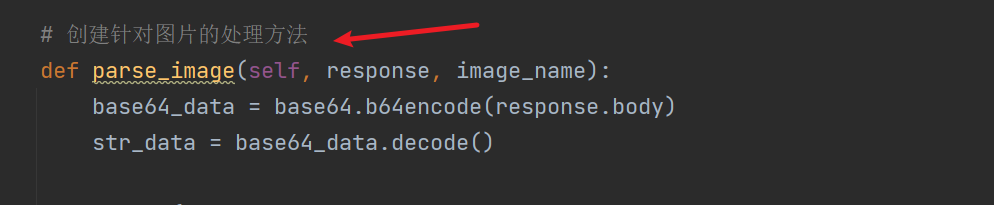
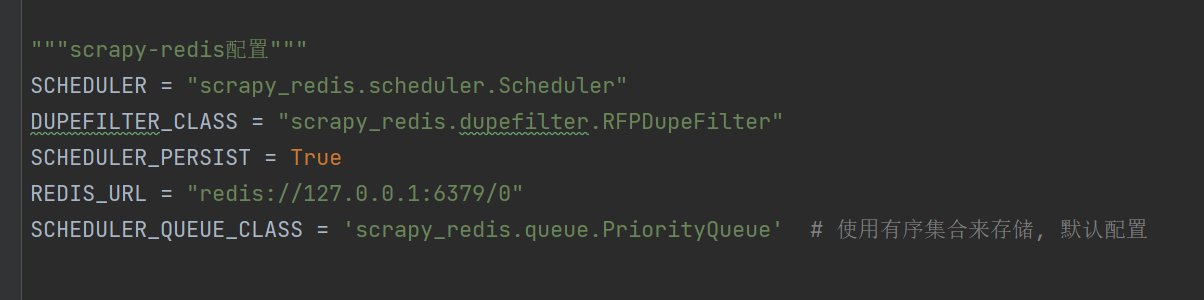
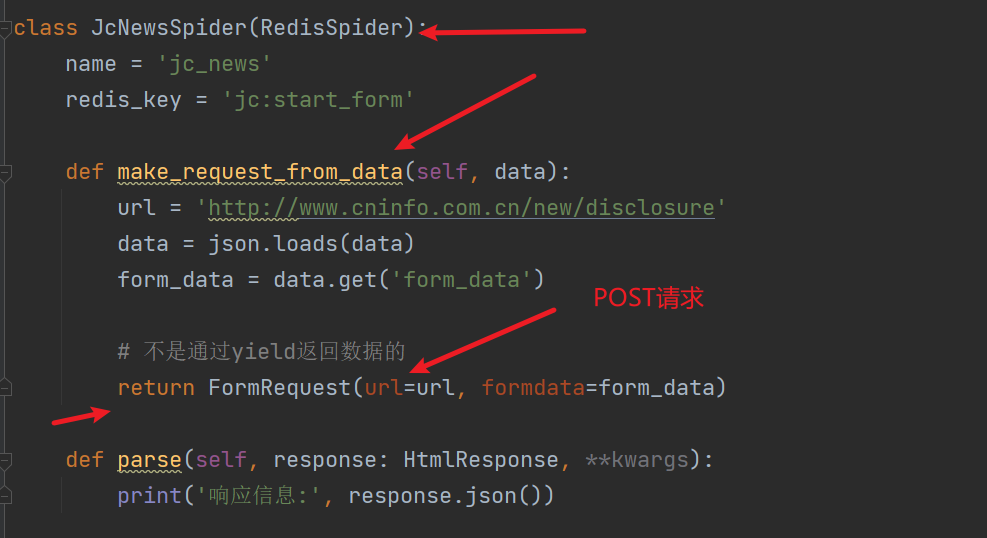
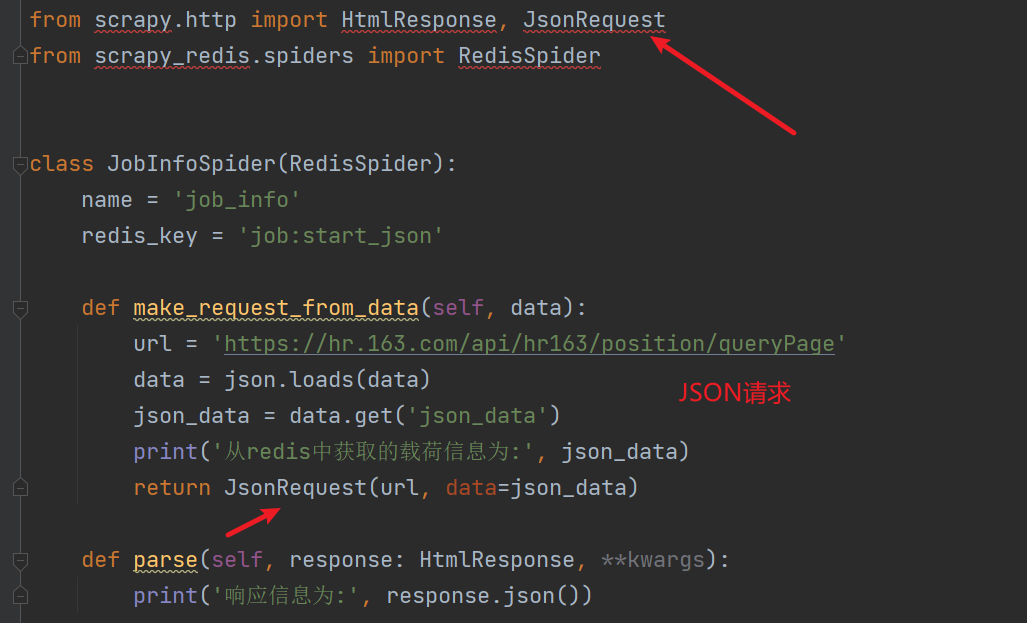
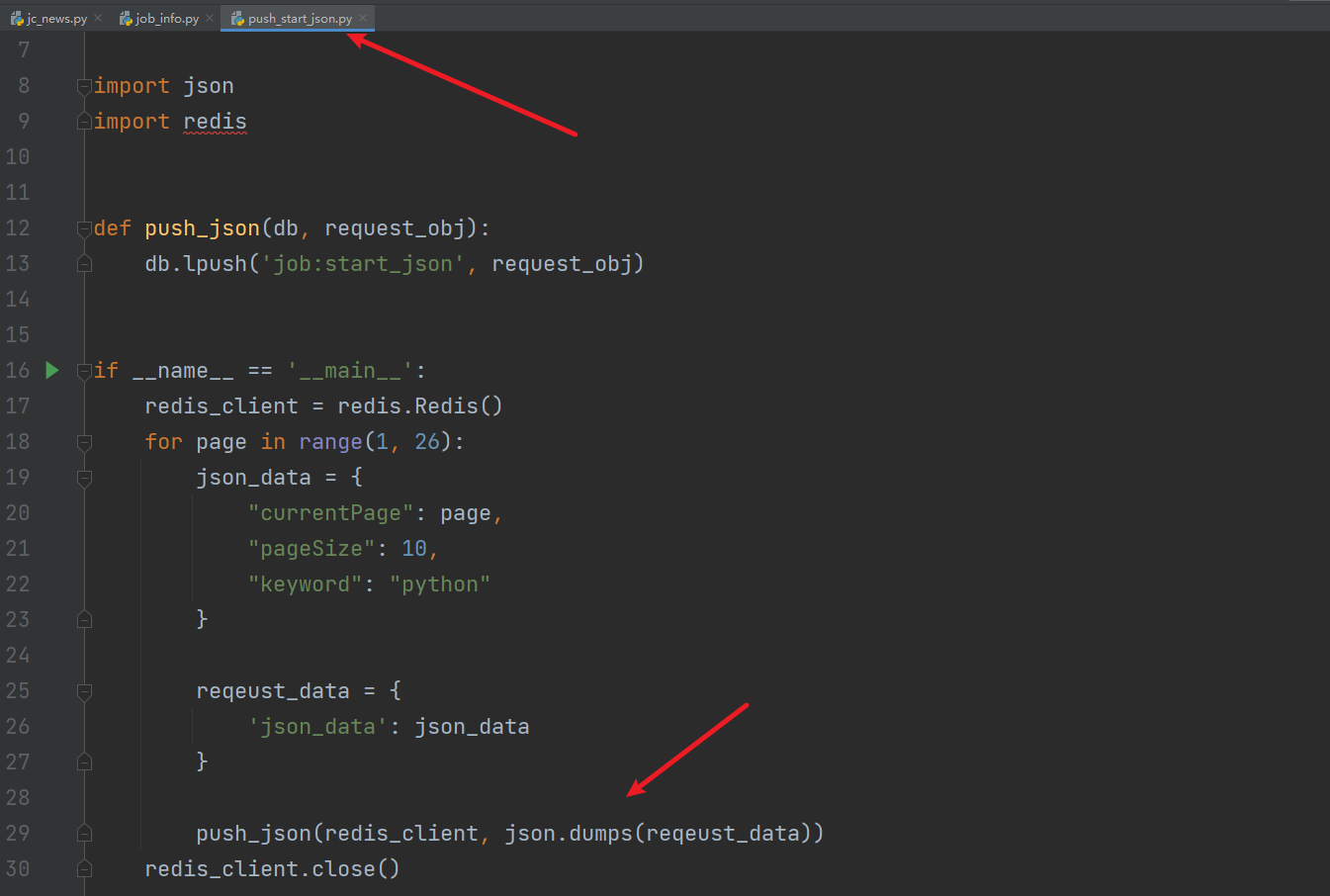
项目部署
scrapyd部署
服务端
安装
pip install scrapyd -i https://pypi.tuna.tsinghua.edu.cn/simple
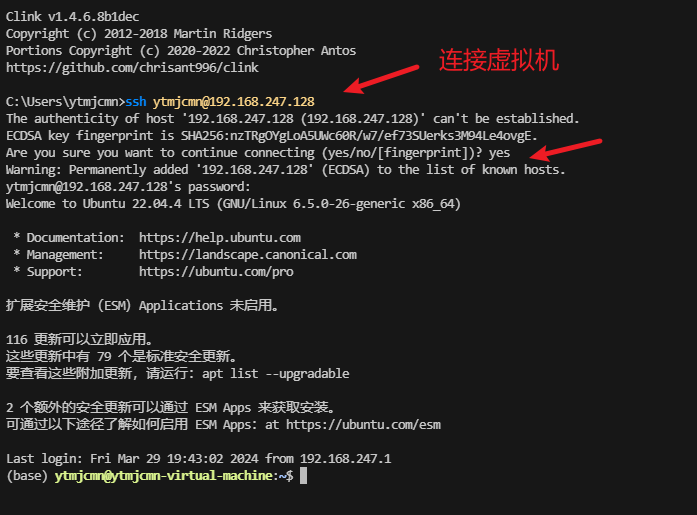

python 导出环境输出到requirements.txt,导出离线包,并安装
1、导出
pip freeze > requirements.txt
2、在其他环境安装
pip install -r requirements.txt
3、离线包
pip download -r requestments.txt -d ./pip_packages
#从当前环境的网络中下载requestments.txt中写的包,下载到当前目录下的pip_packages目录中,这时候你会发现,里面有很多依赖,还有一些whl文件
4、安装
pip install --no-index --find-links=d:\packages -r requirements.txt
# --find-links指定的是包文件的存放地址,-r指定的是txt文件的位置
requirements.txt
attrs==23.2.0
Automat==22.10.0
certifi==2024.2.2
cffi==1.16.0
charset-normalizer==3.3.2
constantly==23.10.4
cryptography==42.0.7
cssselect==1.2.0
defusedxml==0.7.1
filelock==3.14.0
hyperlink==21.0.0
idna==3.7
incremental==22.10.0
itemadapter==0.9.0
itemloaders==1.2.0
jmespath==1.0.1
lxml==5.2.2
packaging==24.0
parsel==1.7.0
Protego==0.3.1
pyasn1==0.6.0
pyasn1_modules==0.4.0
pycparser==2.22
PyDispatcher==2.0.7
pyOpenSSL==24.1.0
queuelib==1.7.0
requests==2.32.2
requests-file==2.1.0
Scrapy==2.11.2
scrapyd==1.4.3
service-identity==24.1.0
six==1.16.0
tldextract==5.1.2
Twisted==22.10.0
typing_extensions==4.12.0
urllib3==1.26.18
w3lib==2.1.2
zope.interface==6.4.post2


配置文件
[scrapyd]
# 监听的IP地址,默认为127.0.0.1(只有改成0.0.0.0才能在别的电脑上能够访问scrapyd运行之后的服务器)
bind_address = 0.0.0.0
# 监听的端口,默认为6800
http_port = 6800
# 是否打开debug模式,默认为off
debug = off
客户端
安装
pip install scrapyd-client -i https://pypi.tuna.tsinghua.edu.cn/simple
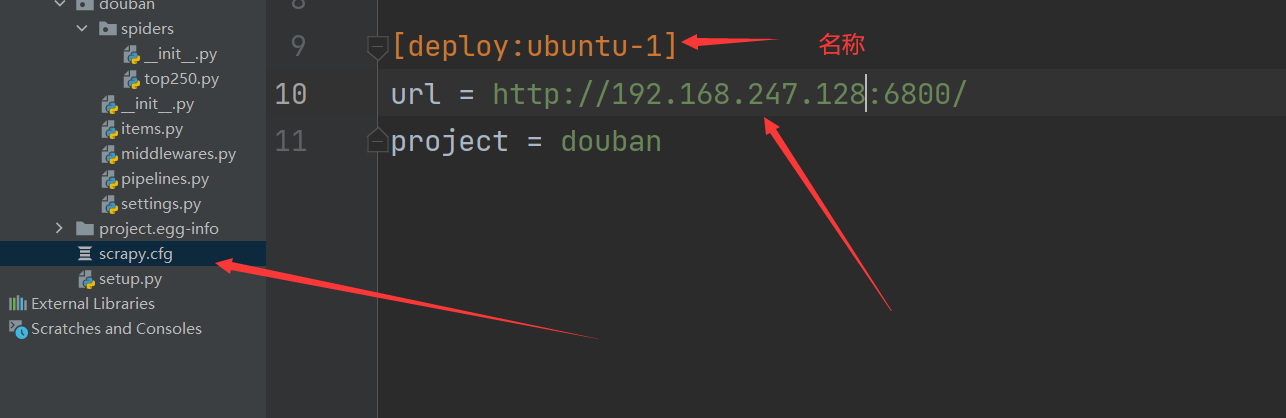
检查配置是否生效
在scrapy项目根路径之下运行如下命令:
# 注意是小写的L,不是数字1
scrapyd-deploy -l

发布scrapy项目到scrapyd所在的服务器(当前爬虫是未运行状态)
scrapyd-deploy <target> -p <project> --version <version>
● target:就是前面配置文件里deploy后面的的target名字,例如ubuntu-1
● project:可以随意定义,跟爬虫的工程名字无关,一般建议与scrapy爬虫项目名相同
● version:自定义版本号,不写的话默认为当前时间戳,一般不写



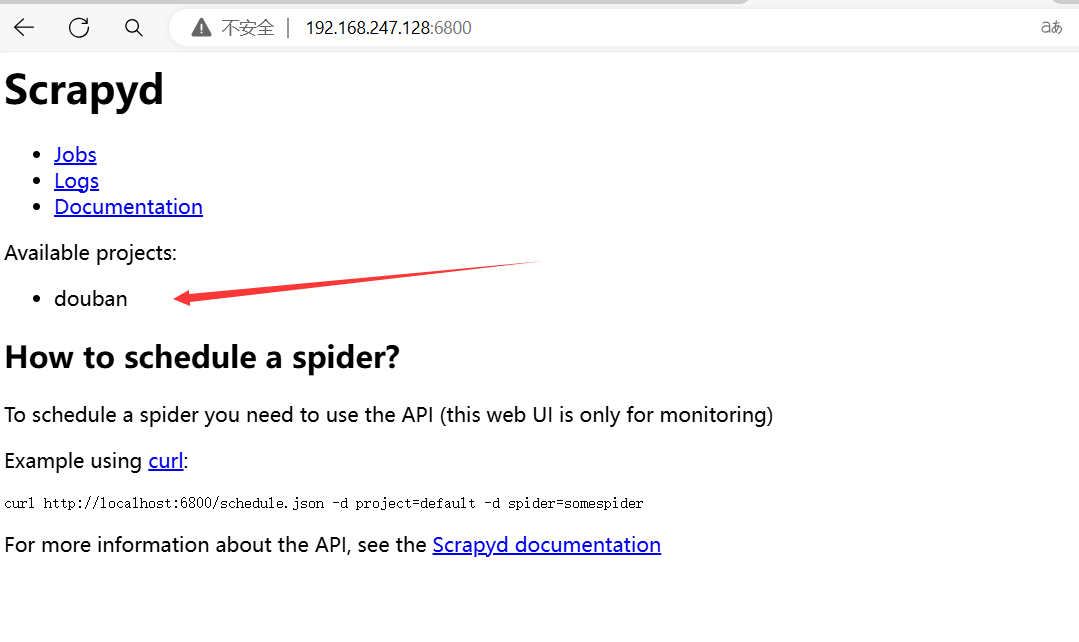

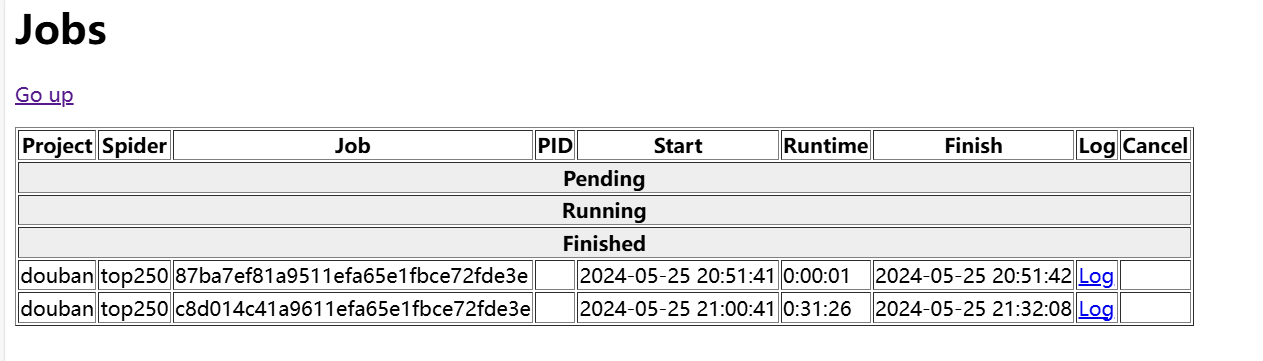

scrapyweb部署
安装
pip install scrapydweb -i https://pypi.tuna.tsinghua.edu.cn/simple

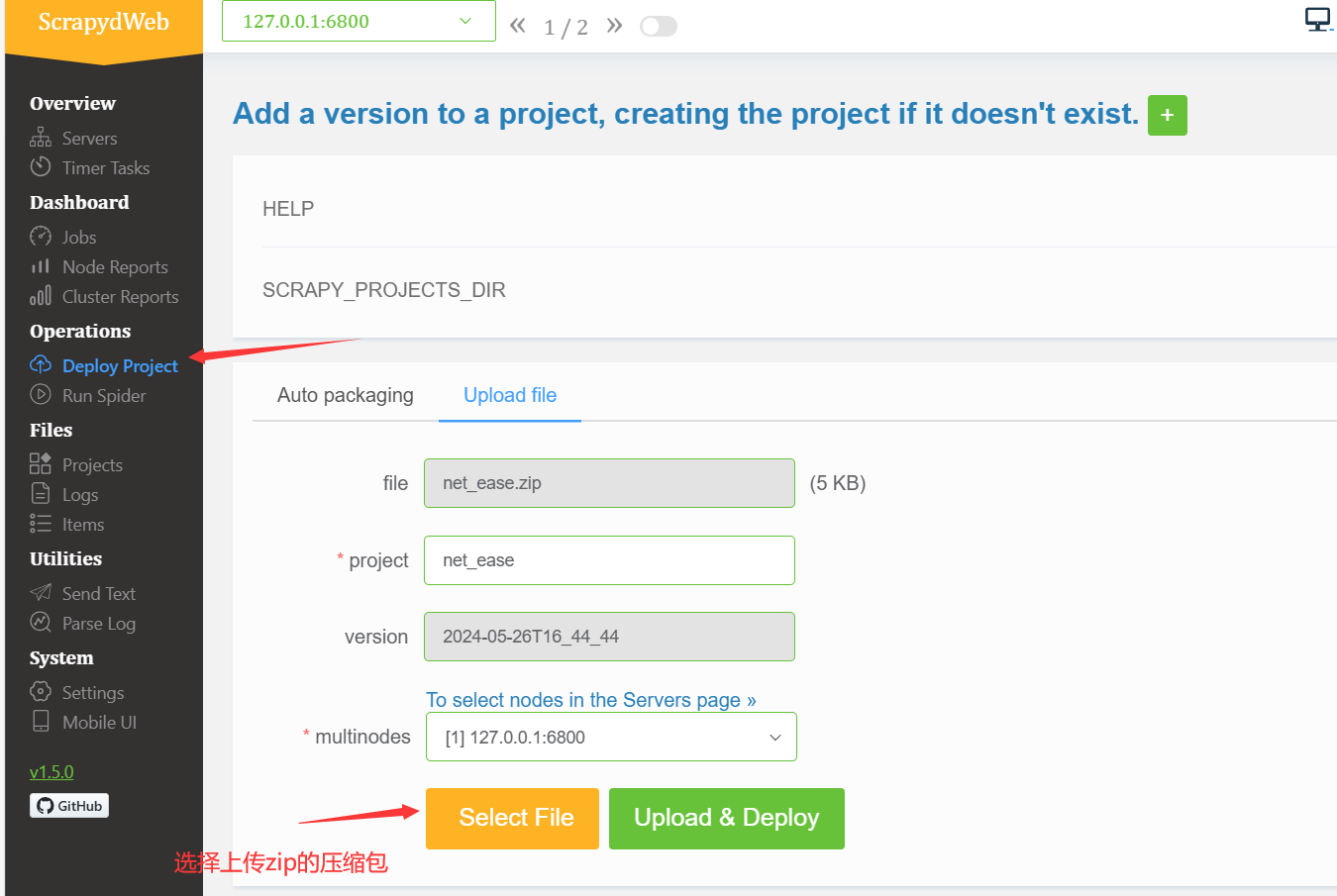
gerapy部署
安装
pip install gerapy==0.9.12 -i https://pypi.tuna.tsinghua.edu.cn/simple

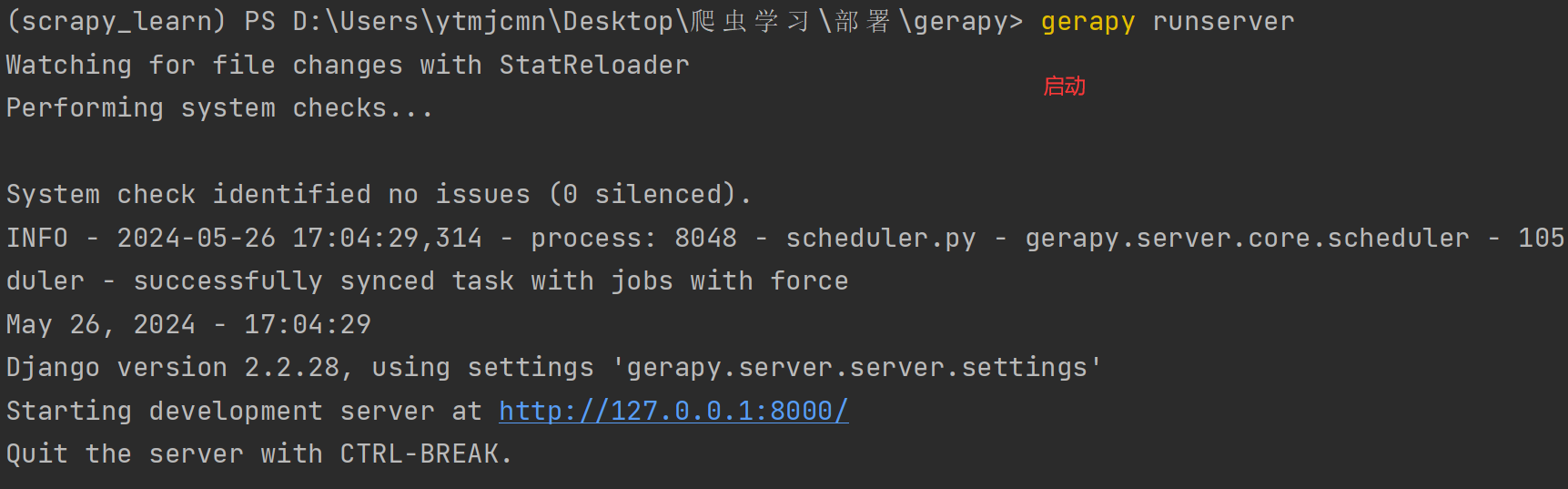

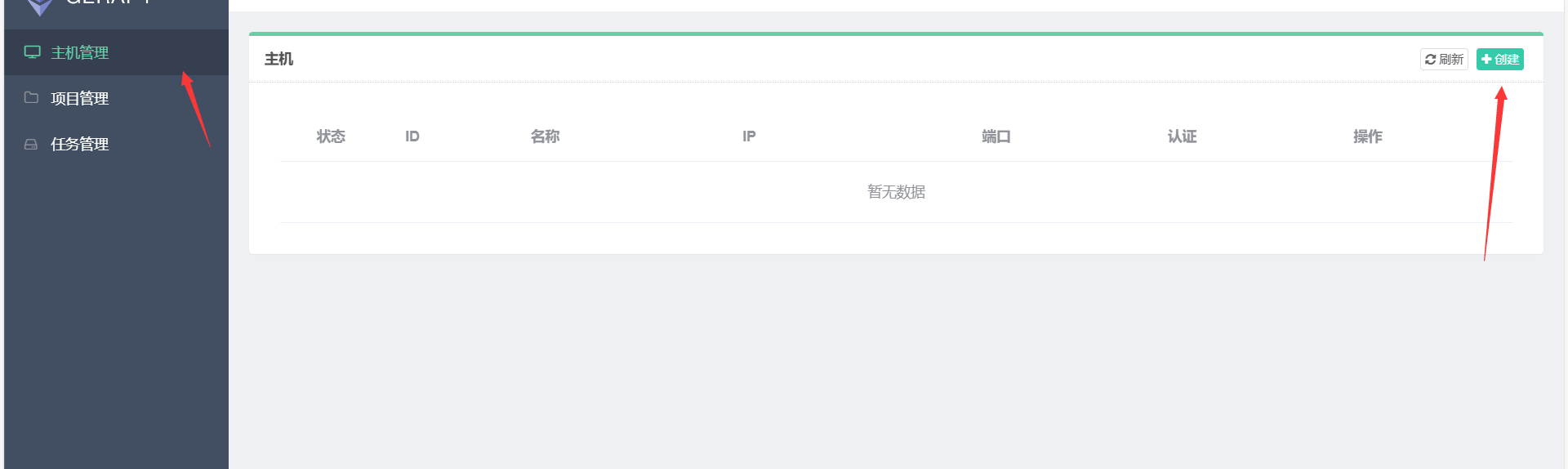
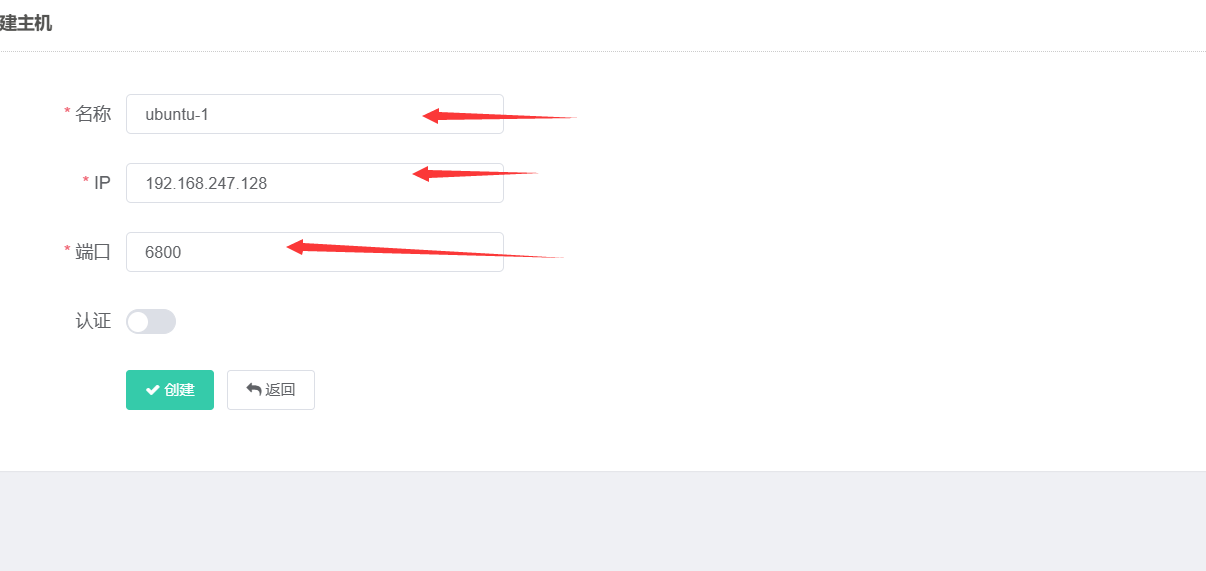
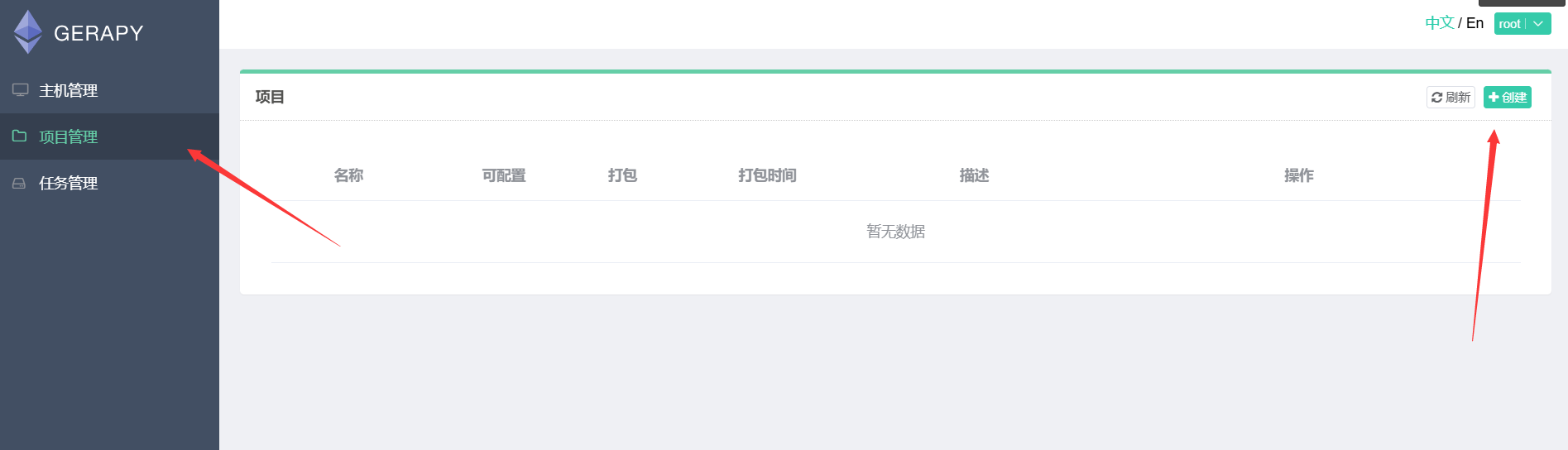
Feapder框架
官方文档
安装
pip install "feapder[all]" --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
创建爬虫
feapder create -s douban
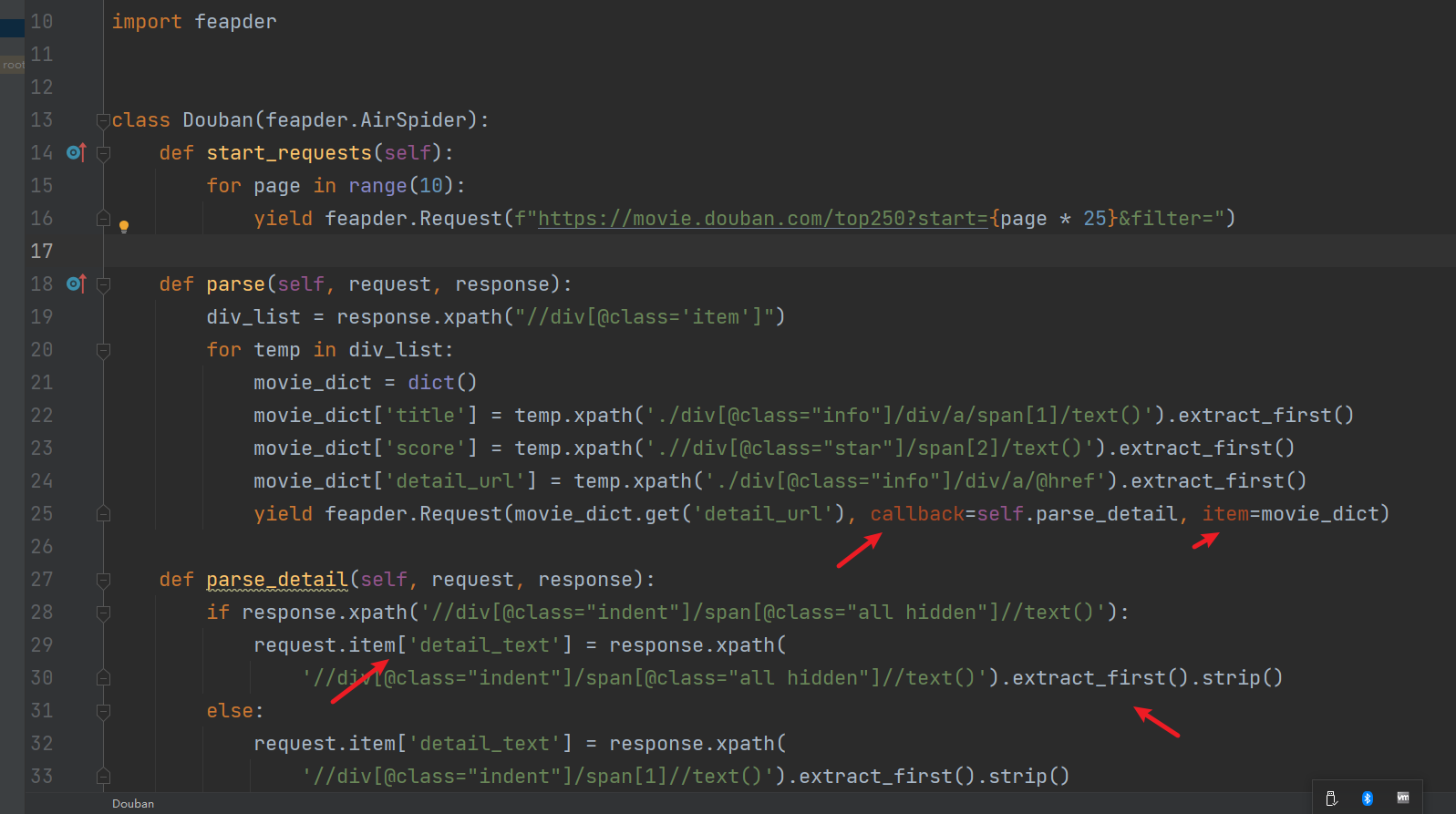
连接mysql数据库
feapder create --setting
feapder create -i <数据库表名>

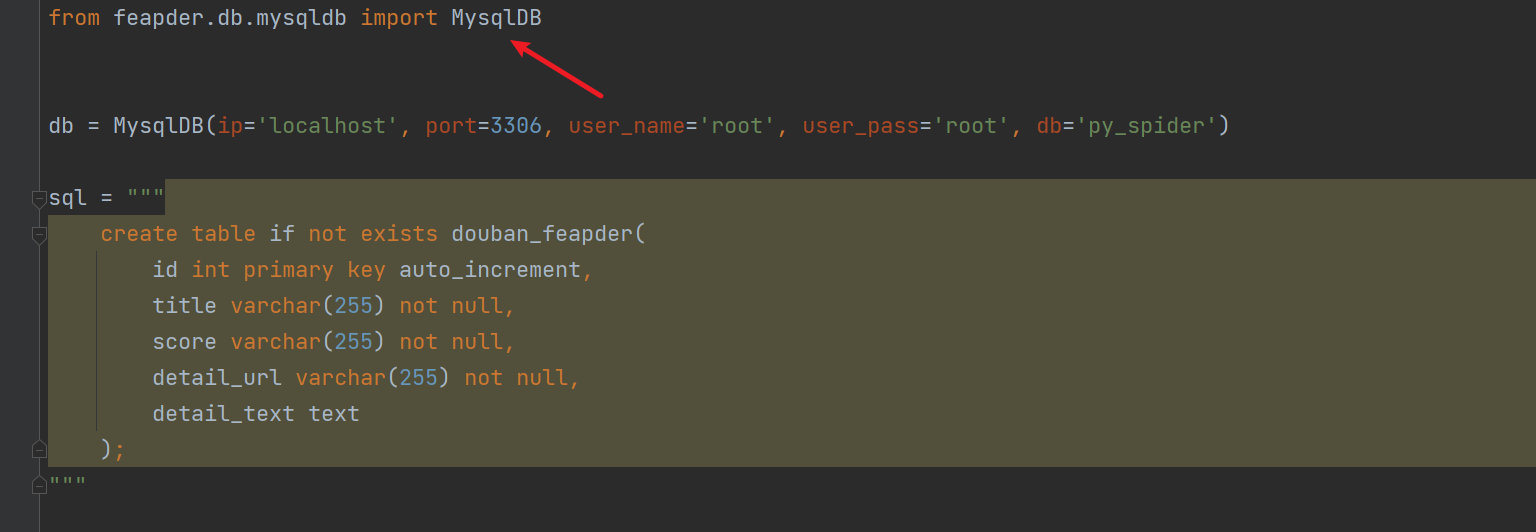
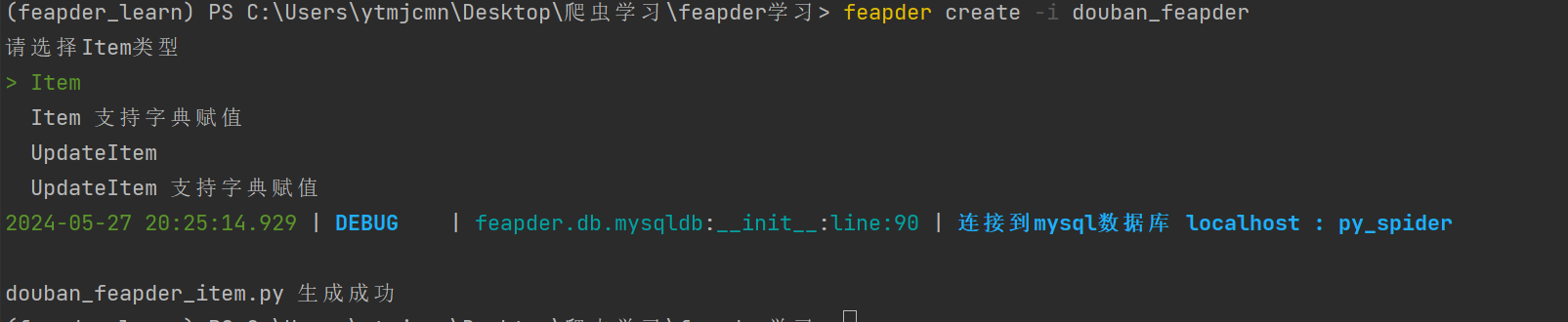
中间件
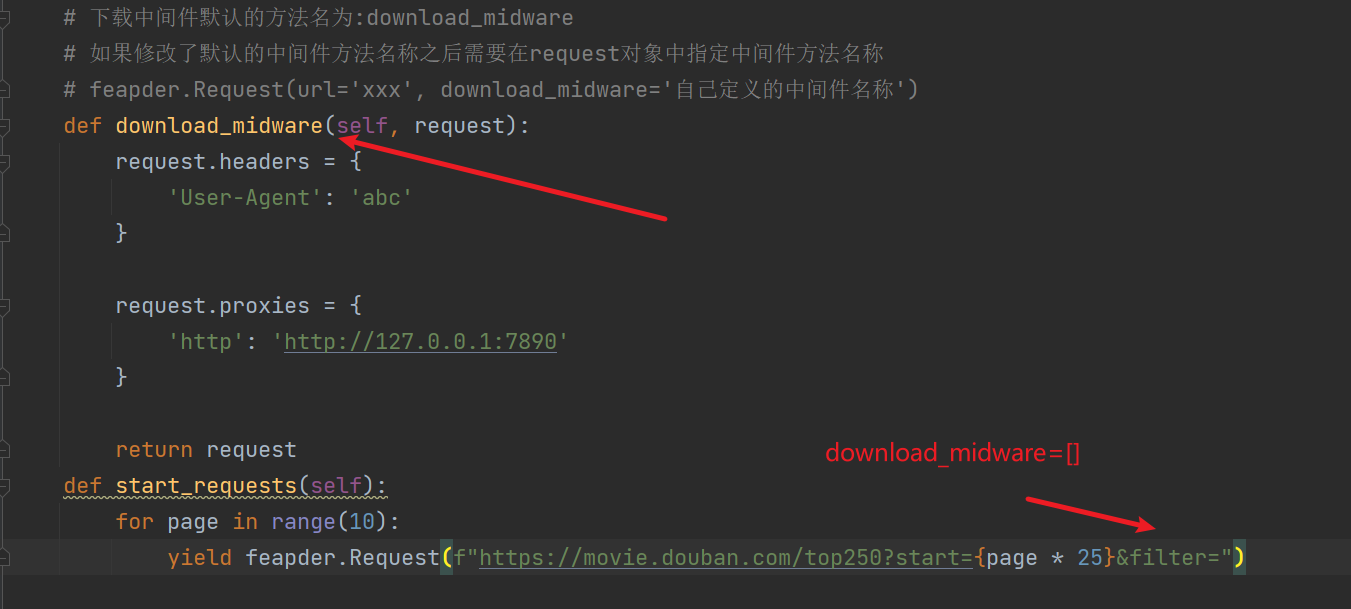
请求重试
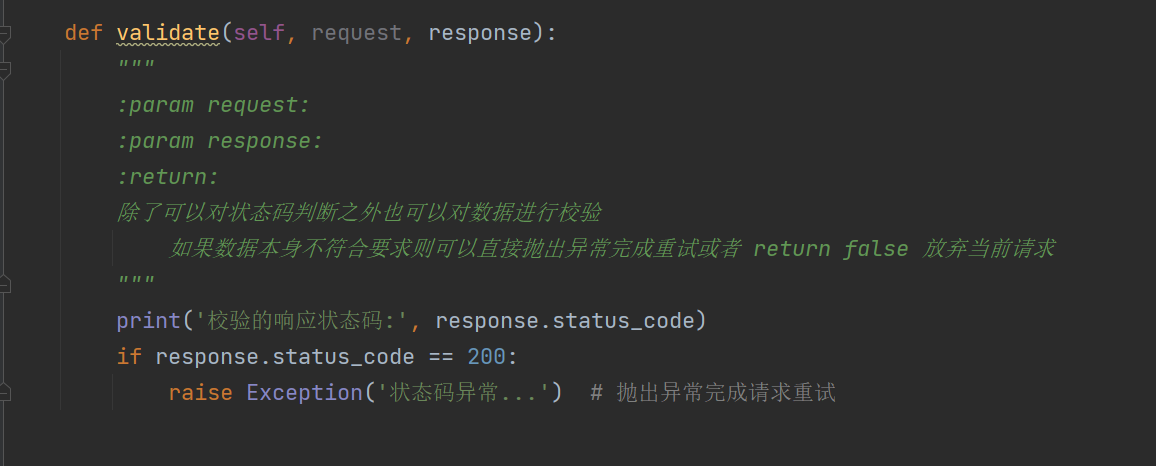

浏览器渲染
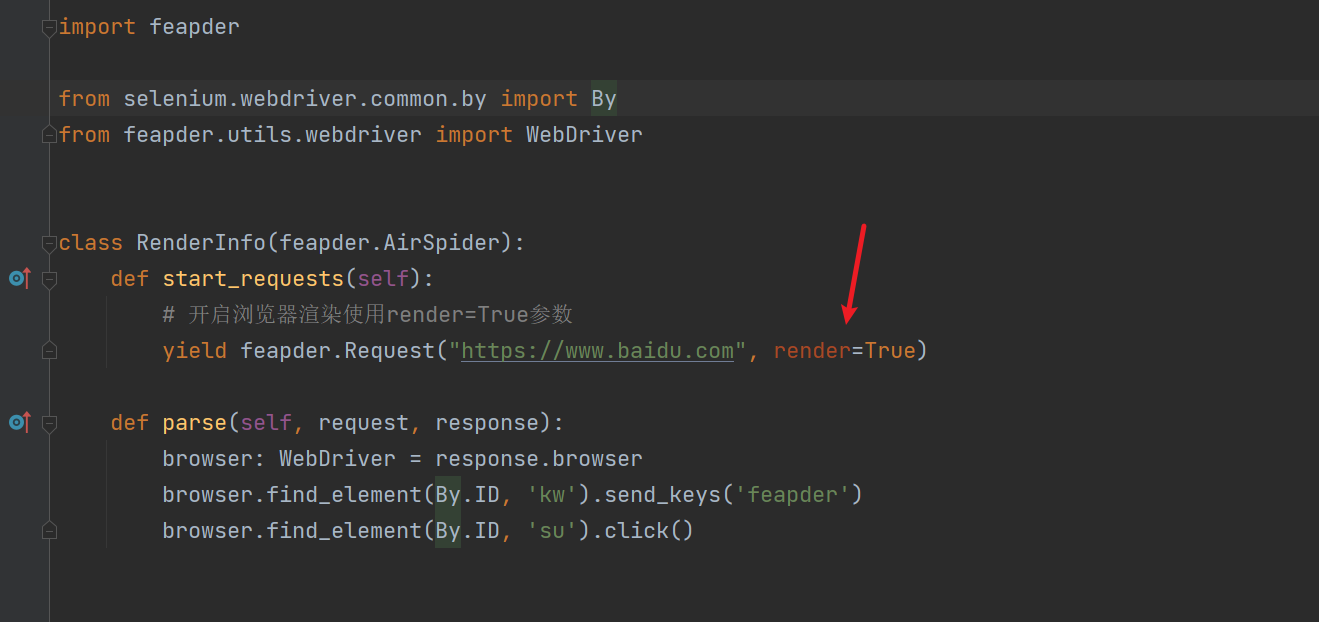
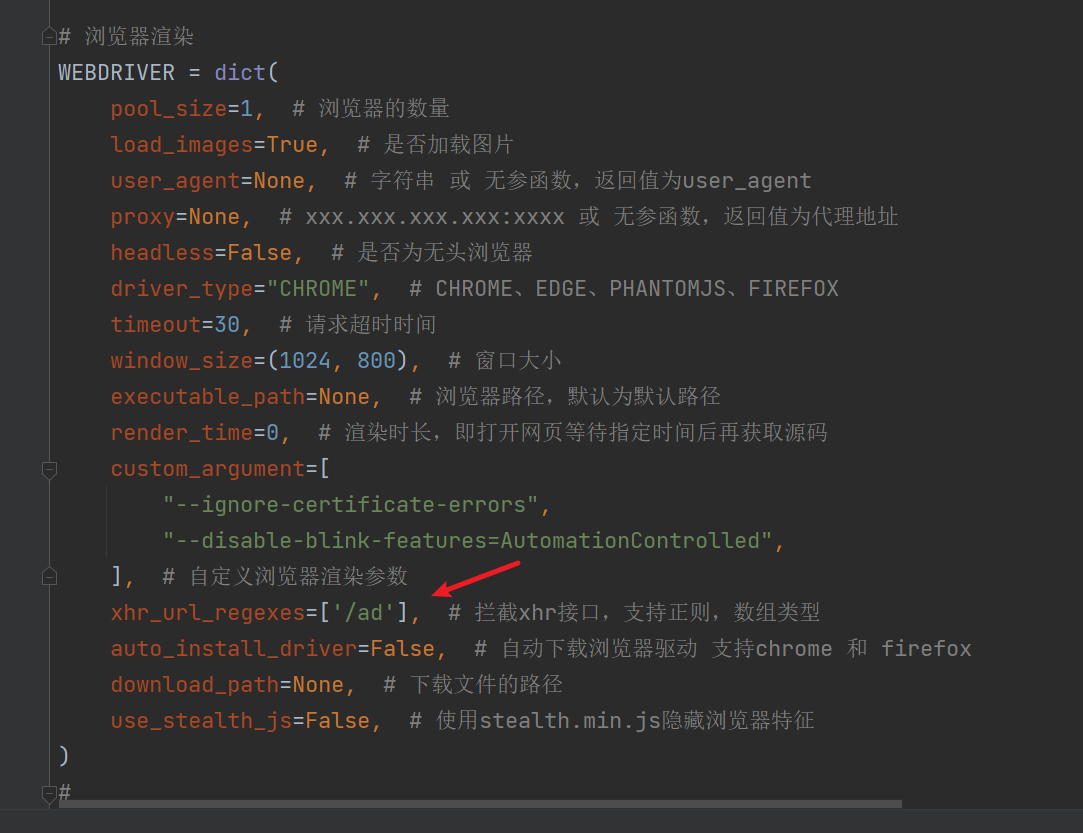
拦截xhr数据
Feapder框架创建完整项目
安装
feapder create -p <project_name>



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用