
用csv文件保存爬取到的数据
查看具体html信息
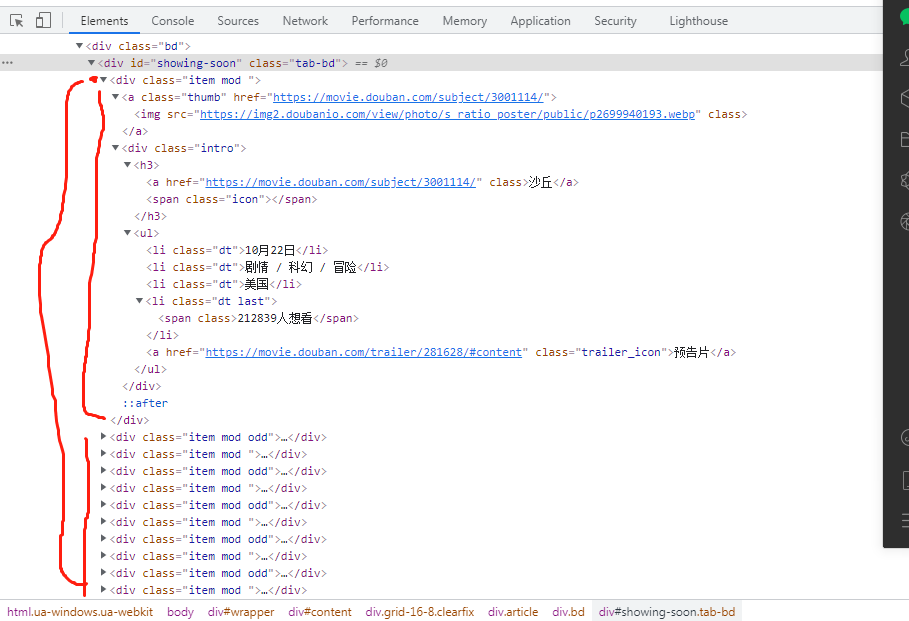
#!/usr/bin/env python # coding=utf-8 import requests from bs4 import BeautifulSoup import pymysql import re import csv url = "https://movie.douban.com/cinema/later/chengdu/" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } reponse = requests.get(url=url,headers=headers) tests = reponse.text soup = BeautifulSoup(tests,'lxml') all_movies = soup.find('div', id = "showing-soon") allshow = all_movies.find_all('div', class_ = "item") #写模式打开csv文件 csv_obj = open('data.csv', 'w', encoding="utf-8") #写入一行标题 csv.writer(csv_obj).writerow(["影片名", "链接", "上映日期", "影片类型", "地区", "关注者"]) for each_movie in allshow: all_a = each_movie.find_all('a') #[<a class="thumb" href="https://movie.douban.com/subject/3001114/"> # <img class="" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2699940193.jpg"/> # </a>, # all_a[1].text显示的事沙丘 : <a class="" href="https://movie.douban.com/subject/3001114/">沙丘</a>, # all_a[2].text <a class="trailer_icon" href="https://movie.douban.com/trailer/281628/#content">预告片</a>] all_li = each_movie.find_all('li') #[<li class="dt">10月22日</li>, <li class="dt">剧情 / 科幻 / 冒险</li>, <li class="dt">美国</li>, <li class="dt last"><span class="">212882人想看</span></li>] movie_name = all_a[1].text movie_href = all_a[1]['href'] movie_date = all_li[0].text movie_type = all_li[1].text movie_area = all_li[2].text movie_lovers = all_li[3].text #逐个写入电影信息 csv.writer(csv_obj).writerow([movie_name,movie_href,movie_date,movie_type,movie_area,movie_lovers]) #关闭 csv_obj.close() print("finshed")
知识拓展:
import requests
from bs4 import BeautifulSoup # 从bs4引入BeautifulSoup
#请求网页
# 旧版教程
# url = "https://movie.douban.com/cinema/later/chengdu/"
# response = requests.get(url)
# 2019-12-23更新,解决不能获取到响应的问题
url = "https://movie.douban.com/cinema/later/chengdu/" # URL不变
# 新增伪装成Chrome浏览器的header
fake_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'
}
response = requests.get(url, headers=fake_headers) # 请求参数里面把假的请求header加上
# 解析网页
# 初始化BeautifulSoup方法一:利用网页字符串自带的编码信息解析网页
soup = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
# 初始化BeautifulSoup方法二:手动指定解析编码解析网页
# soup = BeautifulSoup(response.content, 'lxml', from_encoding='utf-8')
# print(soup) # 输出BeautifulSoup转换后的内容
all_movies = soup.find('div', id="showing-soon") # 先找到最大的div
# print(all_movies) # 输出最大的div的内容
for each_movie in all_movies.find_all('div', class_="item"): # 从最大的div里面找到影片的div
# print(each_movie) # 输出每个影片div的内容
all_a_tag = each_movie.find_all('a')
all_li_tag = each_movie.find_all('li')
movie_name = all_a_tag[1].text
moive_href = all_a_tag[1]['href']
movie_date = all_li_tag[0].text
movie_type = all_li_tag[1].text
movie_area = all_li_tag[2].text
movie_lovers = all_li_tag[3].text
print('名字:{},链接:{},日期:{},类型:{},地区:{}, 关注者:{}'.format(
movie_name, moive_href, movie_date, movie_type, movie_area, movie_lovers))
-
Python打开文件操作详解
使用file_obj = open("file_name", 'mode', encoding="encoding")的方法进行操作。
file_name是你需要读取或者写入的文件路径及文件名(如"../data/ok.txt"是相对路径打开,如果只写一个"ok.txt",那么就会默认保存到当前.py文件或者.ipynb文件的相同文件夹里面)-
mode是你指定操作文件的方法,常用的有r,w,a,r+,rb,wb,ab,rb+这些方法,r是读取(read,如果不存在则报错),w是写入(write,文件不存在则创建,如果文件存在则覆盖),a是追加写入(文件不存在则创建,文件存在从文件最后开始写入),r+是读取和写入。后面加了个b的,是以二进制方式进行上述操作(通常用于对图片、视频等二进制文件进行操作),mode默认是r。 -
encoding在前面的章节说过了,是我们对文件进行操作所遵循的编码,默认为当前运行环境编码。Windows的默认编码是gbk,linux系统基本上是utf-8。不同的文件可以有不同的编码,设置读取的编码错误要么会报错,要么就得不到正确的内容。 -
file_obj是一个文件对象(Python里面也是万物皆对象,所以不要愁没有对象了),之后我们读取、写入数据都通过这个对象进行操作。
-
-
Python读取文件方法
file_obj.read(),一次性读取文件所有的内容作为一个字符串。
file_obj.readlines(),一次性读取文件所有内容,但每一行作为一个字符串并放在一个list(数组)里面。
file_obj.readline(limit),从上次读取的行数开始,读取limit行,limit默认为1。该方法通常用在由于文件过大不能一次性读取完毕一个文件的时候)。 -
Python写入文件的方法
file_obj.write(anystr),该方法接受一个字符串,并将字符串写入。
file_obj.writelines(list_of_str),该方法接受一个内部全是字符串的list数组,并将所有字符串一行一个写入(自动添加换行符)。 -
关闭文件
file_obj.close()关闭文件对象。打开了一个文件之后要记得关闭,否则可能会出现不可控的问题。但是如果用with方法打开了文件,则不需要手动关闭文件,在with语句块运行结束后,会自动关闭文件。
示例
# 需要手动关闭文件
file_obj = open("ok.txt", 'r', encoding="utf-8")
content = file_obj.read()
file_obj.close()
# 不需要手动关闭文件
with open("ok.txt", 'r', encoding="utf-8") as file_obj:
content = file_obj.read()
把数据保存到 html 文件
由于txt文件难度较低且所学内容被本小节囊括了,所以我们直接从保存数据到HTML文件开始。
我们的目标是:

上面这个截图的网页的代码是这样的(为了简洁美观,所以采用了bootstrap的css样式):
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>豆瓣电影即将上映影片信息</title>
<link href="https://cdn.bootcss.com/bootstrap/4.0.0/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<h2 class="text-center">豆瓣电影即将上映影片信息</h2>
<table class="table table-striped table-hover mx-auto text-center">
<thead>
<tr>
<th>影片名</th>
<th>上映日期</th>
<th>影片类型</th>
<th>地区</th>
<th>关注者数量</th>
</tr>
</thead>
<tbody>
<tr>
<td><a href="https://movie.douban.com/subject/30212331/">测试名1</a></td>
<td>测试日期1</td>
<td>测试类型1</td>
<td>测试地区1</td>
<td>测试关注者1</td>
</tr>
<tr>
<td><a href="https://movie.douban.com/subject/30212331/">测试名2</a></td>
<td>测试日期2</td>
<td>测试类型2</td>
<td>测试地区2</td>
<td>测试关注者2</td>
</tr>
</tbody>
</table>
</body>
</html>
<tr>...<tr>中间的内容,并把我们的数据填进去,数据就会一行一行地被填充到表格中了。<tbody>前后的代码我们就只需要复制过来写入就好了。所以我们就拿着之前的代码开始操作了:
注:python 里面三个
"围起来的字符会被看做是一整个字符串,避免了换行符的麻烦。.format()这个方法的用法是把字符串里面的{}字符,按次序一一替换成 format() 接受的所有参数。import requests from bs4 import BeautifulSoup # 从bs4引入BeautifulSoup #请求网页 # 旧版教程 # url = "https://movie.douban.com/cinema/later/chengdu/" # response = requests.get(url) # 2019-12-23更新,解决不能获取到响应的问题 url = "https://movie.douban.com/cinema/later/chengdu/" # URL不变 # 新增伪装成Chrome浏览器的header fake_headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36' } response = requests.get(url, headers=fake_headers) # 请求参数里面把假的请求header加上 # 初始化BeautifulSoup方法一:利用网页字符串自带的编码信息解析网页 soup = BeautifulSoup(response.content.decode('utf-8'), 'lxml') # 初始化BeautifulSoup方法二:手动指定解析编码解析网页 # soup = BeautifulSoup(response.content, 'lxml', from_encoding='utf-8') # print(soup) # 输出BeautifulSoup转换后的内容 all_movies = soup.find('div', id="showing-soon") # 先找到最大的div # print(all_movies) # 输出最大的div的内容 html_file = open('data.html', 'w', encoding="utf-8") html_file.write(""" <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>豆瓣电影即将上映影片信息</title> <link href="https://cdn.bootcss.com/bootstrap/4.0.0/css/bootstrap.min.css" rel="stylesheet"> </head> <body> <h2 class="text-center">豆瓣电影即将上映影片信息</h2> <table class="table table-striped table-hover mx-auto text-center"> <thead> <tr> <th>影片名</th> <th>上映日期</th> <th>影片类型</th> <th>地区</th> <th>关注者数量</th> </tr> </thead> <tbody> """) for each_movie in all_movies.find_all('div', class_="item"): # 从最大的div里面找到影片的div # print(each_movie) # 输出每个影片div的内容 all_a_tag = each_movie.find_all('a') all_li_tag = each_movie.find_all('li') movie_name = all_a_tag[1].text moive_href = all_a_tag[1]['href'] movie_date = all_li_tag[0].text movie_type = all_li_tag[1].text movie_area = all_li_tag[2].text # 替换字符串里面的 想看 两个字为空,使得更加美观 movie_lovers = all_li_tag[3].text.replace("想看", '') print('名字:{},链接:{},日期:{},类型:{},地区:{}, 关注者:{}'.format( movie_name, moive_href, movie_date, movie_type, movie_area, movie_lovers)) html_file.write(""" <tr> <td><a href="{}">{}</a></td> <td>{}</td> <td>{}</td> <td>{}</td> <td>{}</td> </tr> """.format(moive_href, movie_name, movie_date, movie_type, movie_area, movie_lovers)) html_file.write(""" </tbody> </table> </body> </html> """) html_file.close() print("write_finished!")
数据保存到csv文件
首先介绍一下csv文件,这是个类 txt 的表格文件,读取和写入都相对excel的表格文件更加简单方便,所以在数据领域使用较多。
要使用csv模块,我们首先需要import csv,然后把一个文件对象作为参数传给csv.writer()或者csv.reader(),然后我们就对这个writer/reader进行读写操作了。
写入是调用writer的writerow()方法。writerow方法接受一个由字符串组成的 list 数组,然后就会把这个list的内容按照规定写入到csv文件。
读取则是对reader进行遍历,每一轮遍历的结果返回一行的数据组成的 list数组。
写入示例:
import csv
# Windows默认编码是gbk,如果用utf-8,excel打开可能会乱码
# newline='' 是为了让writer自动添加的换行符和文件的不重复,防止出现跳行的情况
file_obj = open('csvtest.csv', 'w', encoding="gbk", newline='')
writer = csv.writer(file_obj)
a_row = ['你好', 'hello', 'thank', 'you']
row_2 = ['how', 'are', 'you', 'indian', 'mifans']
writer.writerow(a_row)
writer.writerow(row_2)
file_obj.close()
print('finished!')
C:/USER(用户)/username 文件夹里面,username是你的电脑的用户名。)找到这个csvtest.csv文件(默认就是excel或者wps格式)并打开
读取示例:
import csv
# 读取的编码要和写入的保持一致
file_obj = open('csvtest.csv', 'r', encoding="gbk")
reader = csv.reader(file_obj)
for row in reader:
print(row)
file_obj.close()
print('finished!')
运行结果输出:
['你好', 'hello', 'thank', 'you']
['how', 'are', 'you', 'indian', 'mifans']
finished!import csv import requests from bs4 import BeautifulSoup # 从bs4引入BeautifulSoup # 请求网页 url = "https://movie.douban.com/cinema/later/chengdu/" response = requests.get(url) # 初始化BeautifulSoup方法一:利用网页字符串自带的编码信息解析网页 soup = BeautifulSoup(response.content.decode('utf-8'), 'lxml') # 初始化BeautifulSoup方法二:手动指定解析编码解析网页 # soup = BeautifulSoup(response.content, 'lxml', from_encoding='utf-8') # print(soup) # 输出BeautifulSoup转换后的内容 all_movies = soup.find('div', id="showing-soon") # 先找到最大的div # print(all_movies) # 输出最大的div的内容 csv_file = open('data.csv', 'w', encoding="gbk", newline='') writer = csv.writer(csv_file) writer.writerow(["影片名", "链接", "上映日期", "影片类型", "地区", "关注者"]) # 写入标题 for each_movie in all_movies.find_all('div', class_="item"): # 从最大的div里面找到影片的div # print(each_movie) # 输出每个影片div的内容 all_a_tag = each_movie.find_all('a') all_li_tag = each_movie.find_all('li') movie_name = all_a_tag[1].text moive_href = all_a_tag[1]['href'] movie_date = all_li_tag[0].text movie_type = all_li_tag[1].text movie_area = all_li_tag[2].text movie_lovers = all_li_tag[3].text.replace("想看", '') print('名字:{},链接:{},日期:{},类型:{},地区:{}, 关注者:{}'.format( movie_name, moive_href, movie_date, movie_type, movie_area, movie_lovers)) writer.writerow([movie_name, moive_href, movie_date, movie_type, movie_area, movie_lovers]) csv_file.close() print("write_finished!")

