Python零基础爬虫教学(实战案例手把手Python爬虫教学)
前言
女朋友看了都能学会的爬虫教学
自己断断续续学习练习了两三年python爬虫,从网上看了无数教程,跟大神们学习了各种神奇的操作,现在虽然没成为大神,但是想通过这篇教程来分享自己学习的爬虫实战案例。
通过本教程,你将学会如何用Python爬虫从网络上爬取你想要的电影下载资源。本案例以00电影网为例进行爬取,当然你可以修改代码爬取你想要的任何内容。
如果你是零基础,请从头阅读,如果你有些基础,可以选择部分阅读。
第一章 你需要的环境和软件
python3.5
既然我们是python爬虫,那必然需要python了。我用的是3.5.3版本
官方下载链接点这个链接并下拉翻到图中位置
点击红框里的链接进行下载,如果你是64位系统就点第一个,如果你是32位系统就点第二个
下载完成后是一个.exe文件,双击运行,开始安装,一路下一步就可以了,这里我没法一步步演示,如果遇到问题可以留言保证第一时间回答(我也从小白一路走过来,能体会遇到问题时的心情)
pycharm community 2017
这个呢是一个代码编辑器,可以大大提高编程效率
同样是去官网下载,并且community版本是免费的,完全够用
官网下载地址 点进去之后如图所示
确保你选择了红框的位置,然后点击download就可以下载了
下载完成后双击打开安装程序,依然是一直点下一步就好了,当然也有一些自定义选项你可以自己选择
环境配置
到这里我们的软件就安装好了
接下来就是环境配置,这一步的目的是让pycharm和python配合
首先,为了实现爬虫程序,我们需要给python安装一些工具包,操作非常简单
在开始菜单搜索cmd并回车,打开终端命令行窗口
手动输入 pip3 install -------------- 并回车
本文案例中需要两个库安装如下
pip3 install requests
pip3 install Beautifulsoup4 这两句要分别运行,等一句安装成功了再运行另一句
然后等待安装,成功后会提示下图字样
第二章 开始写python爬虫
问题分析
在做任何爬虫之前,我们都要先了解你爬取的网站的源码,根据源码来找到你想爬取的内容在什么位置
那么首先我们来看看目标网站的页面源码目标网站,点击这个网址打开网页,然后按F12键打开开发者模式,如图所示
图中,中间靠右侧的红色框里就是我们主要查看的内容,你要从这里面的代码中找到你想要的内容才可以进行爬取。
这里,我们的目标是搜索电影资源并保存下来。可以看到,网页中间有一个搜索框,输入电影名字点击搜索之后,会跳出搜索结果的页面,然后点击搜索结果就进入了该电影的详情页,并且有下载链接,如图所示
这里我们搜索的是霸王别姬。
由上述过程,可以明确我们要写一个Python爬虫程序,让爬虫来代替我们去搜索和获取电影的下载链接,这就是我们接下来编程的指导思想,告诉你的程序让他去做什么。
总结一下,我们的爬虫要做下面这几件事情:
1、打开目标网页
2、找到搜索框
3、提交搜索电影名并打开搜索结果页面
4、进入搜索电影详情页
5、找到下载链接位置并把所有链接保存到本地电脑上
编程实现爬虫
1、打开目标网页
打开pycharm左上角菜单栏以此点击file-->new project
在弹出的对话框中,设置项目路径,这里命名为spider,然后点击create
稍等几秒项目就建立完成了,这时候在左边资源管理器栏会出现spider项目文件夹,在spider上面右键-->new-->Python file来创建一个python程序脚本文件,命名为spider
然后就可以开始教我们的爬虫做事了
复制下面代码到spider.py中
# 导入之前安装的库 import requests from bs4 import BeautifulSoup # 首先定义以个变量url并赋值为目标网站'http://www.0011kytt.com'以及要搜索的电影名movie_name # 注意引号,字符串必须用引号包围起来 movie_name = '霸王别姬' url = 'http://www.0011kytt.com' # 然后用request.get()来获取网页 r = requests.get(url) # 这里要根据网页的编码来设置解码,这个目标网站编码为'utf-8' r.encoding = 'utf-8' # 然后获取网页源码并赋值给变量html html = r.text # 最后打印出网页源码 print(html)
然后右键spider.py脚本文件,点击 run 'spyder.py' 即可运行

运行结果在下面控制台栏显示,如图所示
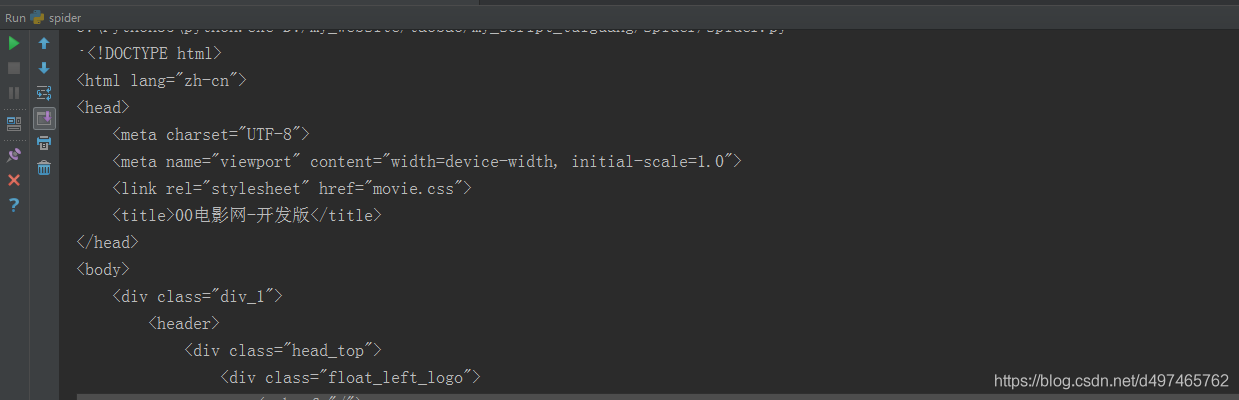
可以看到我们的爬虫乖乖爬到了网页的源码,跟浏览器中按F12得到的是一样的,这一步大功告成。
2、找到搜索框
这一步就要指挥我们的小爬虫根据刚才得到的源码去找搜索框了
小爬虫它怎么会知道搜索框在哪里呢,当然是我们告诉它啊,那我们怎么知道呢,OK,回到浏览器按F12,在红框源码部分把鼠标指针放上去挨着找,鼠标指针位置对应的网页部分会变灰色,点击源码上的小三角可以展开所有内容,方便我们查找,如图所示
咦,找到了耶,好神奇有没有
现在我们知道了原来搜索框在这个网页源码的<div class="search_box">这个部分,OK,去告诉那个智障小爬虫
# 这里利用BeautifulSoup库来解析网页的源码并赋值给soup,方便后面的寻找 soup = BeautifulSoup(html, "lxml") # 因为我们已经知道搜索框在一个叫<div class="search_box">的地方 # 所以根据class="search_box"来找就好了 # 注意,因为class是python关键字,所以这里要用class_,这是BeautifulSoup的规定 search_box = soup.find(class_='search_box') # OK 打印出来看看找得对不对 print(search_box)
复制这段代码到spider.py中,粘贴到上一段代码后面,然后跟上面一样点击运行,得到结果如图

不得了了,这个智障爬虫已经学会找到搜索框了,OK,这一步又大功告成
3、提交搜索电影名并打开搜索结果页面
我们的小爬虫长进不小,继续教他怎么把电影名字填进搜索框然后点击搜索
再回到浏览器F12界面,我们再来找填电影名的位置以及搜索按钮的位置,如图

苏菲玛索也太好看了吧 忍不住截出来给大家看看 乌蝇哥乱入 这网页做的什么鬼
说正事
我们已经找到输入位置和搜索按钮位置分别在<input>和<button>中
另外,我们研究一下这个网站的搜索功能,先随便搜索一个霸王别姬吧,说姬不说吧文明你我他,如图

从图中看到,网站链接变了,搜索页面变为了php文件,记录下这个url
还不赶紧告诉你的智障爬虫,作为父亲就得手把手教他
# 网站搜索页面的url为http://www.0011kytt.com/search/search.php search_url = 'http://www.0011kytt.com/search/search.php' # 从网页源码里看到输入位置的input中有个name='keywords' # 这个keywords就是用来记录我们输入电影名的变量 # 于是,我们构造以下变量,用来让爬虫往搜索框填电影名 formdata = {'type': 'text', 'keywords': movie_name} # requests.post就可以把formdata填进搜索框,并得到搜索结果页面赋值给r_r r_r = requests.post(search_url, formdata) # 同样需要解码 r_r.encoding = 'utf-8' # 获取网页源码并赋值给变量html r_html = r_r.text # 打印看看对不对 print(r_html)
复制代码到spider.py中,贴在上一段代码后面,然后运行,得到结果如下图

哎哟,不得了了,我们的爬虫会自己搜索了呢!
从图中可以看到,霸王别姬的详情页链接就在<div class='item_pic'>的<a href=**********>中,那就好办了呀,直接让爬虫获取链接并打开
# 首先还是用BeautifulSoup库来解析网页的源码 r_soup = BeautifulSoup(r_html, "lxml") # 再根据class_='item_pic'找到所有搜索结果,有可能搜索到多个匹配的结果 movie_div_list = r_soup.find_all(class_='item_pic') # 创建一个空的列表movie_url_list来存储搜索结果的详情页链接 movie_url_list = [] # 因为有可能搜索到多个匹配的结果 # 所以这里用一个循环来获取所有搜索结果的电影详情页链接 for movie_div in movie_div_list: # 对每一个搜索结果,找到其中的href里存着的详情页链接 movie_url = movie_div.a.attrs['href'] # 把详情页链接存到movie_url_list中 movie_url_list.append(movie_url) # OK 打印看看所有搜索结果的详情页链接 print(movie_url_list)
同上点击运行,结果如下

可以看到列表中只有一个链接,因为霸王别姬搜索结果只有一个。。。
4、进入搜索电影详情页
这一步很简单,只要request详情页链接得到详情页源码,跟我们去浏览器手动F12得到的源码比较一下,如果一样那就说明成功了
# 这一步得构造详情页的链接,因为上一步得到的链接只是网站的相对路径我们是无法直接访问的 # 因为上一步的搜索结果可能有好几个,所以还是构造循环程序 for movie_url in movie_url_list: # 构造详情页链接 movie_url = url + movie_url # 直接 requests.get获取网页 r_m = requests.get(movie_url) # 同样需要解码 r_m.encoding = 'utf-8' # 获取网页源码并赋值给变量html m_html = r_m.text # 打印看看对不对 print(r_html)
同上复制到spider.py并运行得到结果如下(篇幅限制截图一部分)
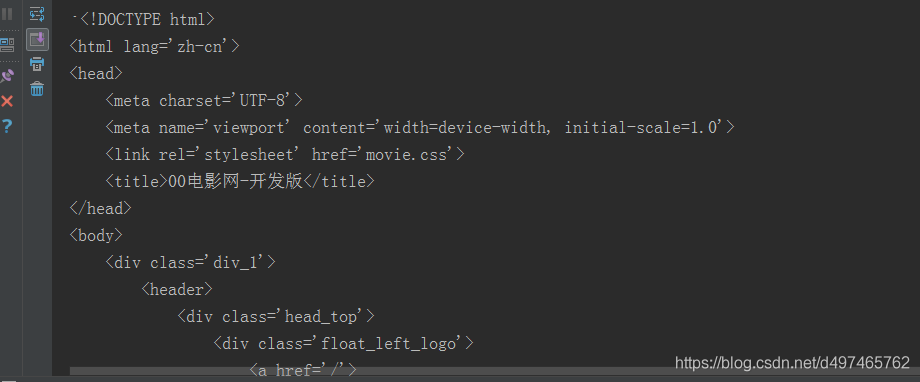
然后到霸王别姬的详情页霸王别姬按F12查看源码,比较之后完全一样,这一步又大功告成,你的智障爬虫离幼儿园毕业只差一步了!
5、找到下载链接位置并把所有链接保存到本地电脑上
这一步,我们要指挥爬虫去爬取详情页的所有下载链接并保存到自己电脑上
首先,我们还是得自己先看一下详情页源码,找到下载链接的位置,再告诉即将幼儿园毕业的爬虫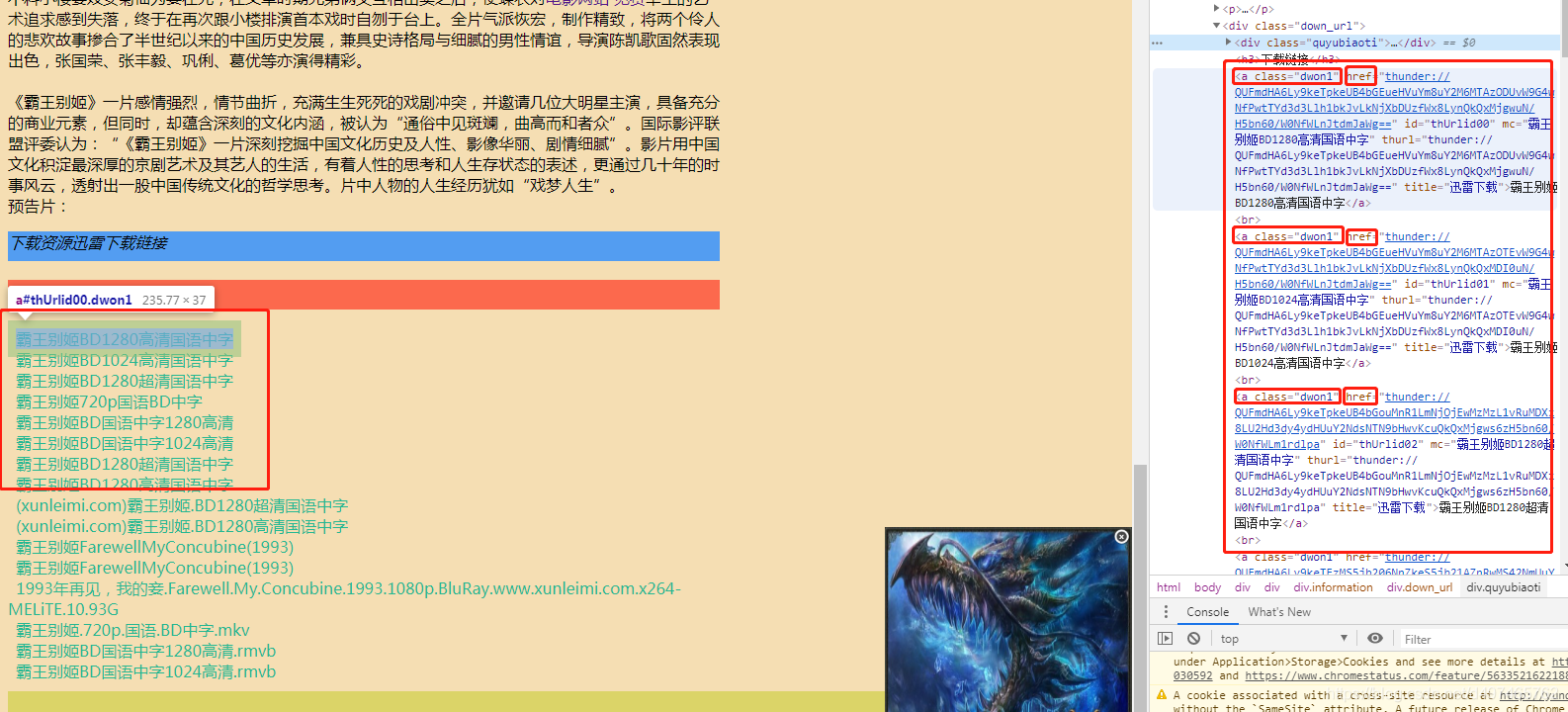
可以看到,所有的下载链接都在<a class="dwon1">中的href里面,哇,这就好办了,赶紧告诉你的爬虫去
# # 首先还是用BeautifulSoup库来解析网页的源码 m_soup = BeautifulSoup(m_html, "lxml") # 根据<title>取得电影名,方便保存下载链接时文件命名 name = m_soup.find('title').text.split('-')[1] # 再根据class_='dwon1'找到所有下载链接 movie_down_list = m_soup.find_all(class_='dwon1') # 创建一个空的列表down_url_list来存储搜索结果的详情页链接 down_url_list = [] # 继续循环爬取下载链接并保存到down_url_list for movie_down in movie_down_list: # 提取href中的下载链接 down_url = movie_down.attrs['href'] # 把下载链接保存到down_url_list中,并在每个链接后面加一个换行符'\n' down_url_list.append(down_url + '\n') # 接下来就是把下载链接都保存到'电影名.txt'中 with open(name+'.txt', 'w') as f: f.writelines(down_url_list)
这里注意!注意!注意!这部分代码跟上部分代码都在同一个循环中!!!!
为了方便小白使用,请将第4步中的代码从spider.py中删除!并且!!复制下面这段完整的代码到刚才删除的位置!!!然后运行即可
# 这一步得构造详情页的链接,因为上一步得到的链接只是网站的相对路径我们是无法直接访问的 # 因为上一步的搜索结果可能有好几个,所以还是构造循环程序 for movie_url in movie_url_list: # 构造详情页链接 movie_url = url + movie_url # 直接 requests.get获取网页 r_m = requests.get(movie_url) # 同样需要解码 r_m.encoding = 'utf-8' # 获取网页源码并赋值给变量html m_html = r_m.text # 打印看看对不对 # print(m_html) # # 首先还是用BeautifulSoup库来解析网页的源码 m_soup = BeautifulSoup(m_html, "lxml") # 根据<title>取得电影名,方便保存下载链接时文件命名 name = m_soup.find('title').text.split('-')[1] # 再根据class_='dwon1'找到所有下载链接 movie_down_list = m_soup.find_all(class_='dwon1') # 创建一个空的列表down_url_list来存储搜索结果的详情页链接 down_url_list = [] # 继续循环爬取下载链接并保存到down_url_list for movie_down in movie_down_list: # 提取href中的下载链接 down_url = movie_down.attrs['href'] # 把下载链接保存到down_url_list中,并在每个链接后面加一个换行符'\n' down_url_list.append(down_url + '\n') # 接下来就是把下载链接都保存到'电影名.txt'中 with open(name+'.txt', 'w') as f: f.writelines(down_url_list)
运行之后我们看到,spider.py路径中多了一个txt文件,里面保存了下载链接,如图

至此大功告成了!你的智障爬虫终于幼儿园毕业了!后面就要靠他自己悟了!
结束语
本文代码按顺序组合在一起就可以运行了,
实在不会的话评论区提问题
学透这段代码你就可以自由改写去爬任何网站了
然后你要问,我爬这么多电影资源干嘛啊我也看不完啊!
嘿嘿,你可以放进数据库,做自己的网站呀
做网站可以干嘛? 可以靠流量,挂广告,赚零花钱呀!
有时间再写一个零基础建网站的教程吧
————————————————
版权声明:本文为CSDN博主「d497465762」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/d497465762/article/details/105580408

 浙公网安备 33010602011771号
浙公网安备 33010602011771号