高并发系统设计(二十):分布式架构如何跟踪排查慢请求问题?
在分布式微服务的架构中,不同业务的项目之间通过RPC服务相互调用,方便了可扩展性,如下图

假如在某个时间节点某个接口请求出现了请求比较慢的问题,而整个接口的流程可能涉及到多个RPC服务之间的调用,那么该如何排查问题呢?
先说一下一体化架构的一贯方法
最简单的思路是:打印下单操作的每一个步骤的耗时情况,然后通过比较这些耗时的数据,找到延迟最高的一步,然后再来看看这个步骤要如何的优化。如果有必要的话,你还需要针对步骤中的子步骤,再增加日志来继续排查,打印出日志后,我们可以登录到机器上,搜索关键词来查看每个步骤的耗时情况。
虽然这个方式比较简单,但可能很快就会遇到问题:由于同时会有多个下单请求并行处理,所以,这些下单请求的每个步骤的耗时日志,是相互穿插打印的。你无法知道这些日志,哪些是来自于同一个请求,也就不能很直观地看到,某一次请求耗时最多的步骤是哪一步了。那么,你要如何把单次请求,每个步骤的耗时情况串起来呢?
一个简单的思路是:给同一个请求的每一行日志,增加一个相同的标记。这样,只要拿到这个标记就可以查询到这个请求链路上,所有步骤的耗时了,我们把这个标记叫做requestId,我们可以在程序的入口处生成一个requestId,然后把它放在线程的上下文中,这样就可以在需要时,随时从线程上下文中获取到requestId了。简单的代码实现就像下面这样:

String requestId = UUID.randomUUID().toString();
ThreadLocal<String> tl = new ThreadLocal<String>(){
@Override
protected String initialValue() {
return requestId;
}
}; //requestId存储在线程上下文中
long start = System.currentTimeMillis();
processA();
Logs.info("rid : " + tl.get() + ", process A cost " + (System.currentTimeMillis() - start)); // 日志中增加requestId
start = System.currentTimeMillis();
processB();
Logs.info("rid : " + tl.get() + ", process B cost " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
processC();
Logs.info("rid : " + tl.get() + ", process C cost " + (System.currentTimeMillis() - start));
有了requestId,你就可以清晰地了解一个调用链路上的耗时分布情况了。于是,你给你的代码增加了大量的日志,来排查下单操作缓慢的问题。
但是假如每次有新的问题,你需要每次给代码增加日志然后重启服务,这样的方式不是最好的办法,然后考虑一下有没有别的办法。
思路
一个接口响应时间慢,一般是出在跨网络的调用上,比如说请求数据库、缓存或者依赖的第三方服务。所以,只需要针对这些调用的客户端类,通过插入一些代码打印每个耗时就好了。
这样,你就在你的系统的每个接口中,打印出了所有访问数据库、缓存、外部接口的耗时情况,一次请求可能要打印十几条日志,如果你的电商系统的QPS是10000的话,就是每秒钟会产生十几万条日志,对于磁盘I/O的负载是巨大的,那么这时,你就要考虑如何减少日志的数量。
你可以考虑对请求做采样,采样的方式也简单,比如你想采样10%的日志,那么你可以只打印“requestId%10==0”的请求。
有了这些日志之后,当给你一个requestId的时候,你发现自己并不能确定这个请求到了哪一台服务器上,所以你不得不登陆所有的服务器,去搜索这个requestId才能定位请求。这样无疑会增加问题排查的时间。
你可以考虑的解决思路是:把日志不打印到本地文件中,而是发送到消息队列里,再由消息处理程序写入到集中存储中,比如Elasticsearch。这样,你在排查问题的时候,只需要拿着requestId到Elasticsearch中查找相关的记录就好了。在加入消息队列和Elasticsearch之后,这个排查程序的架构图也会有所改变:
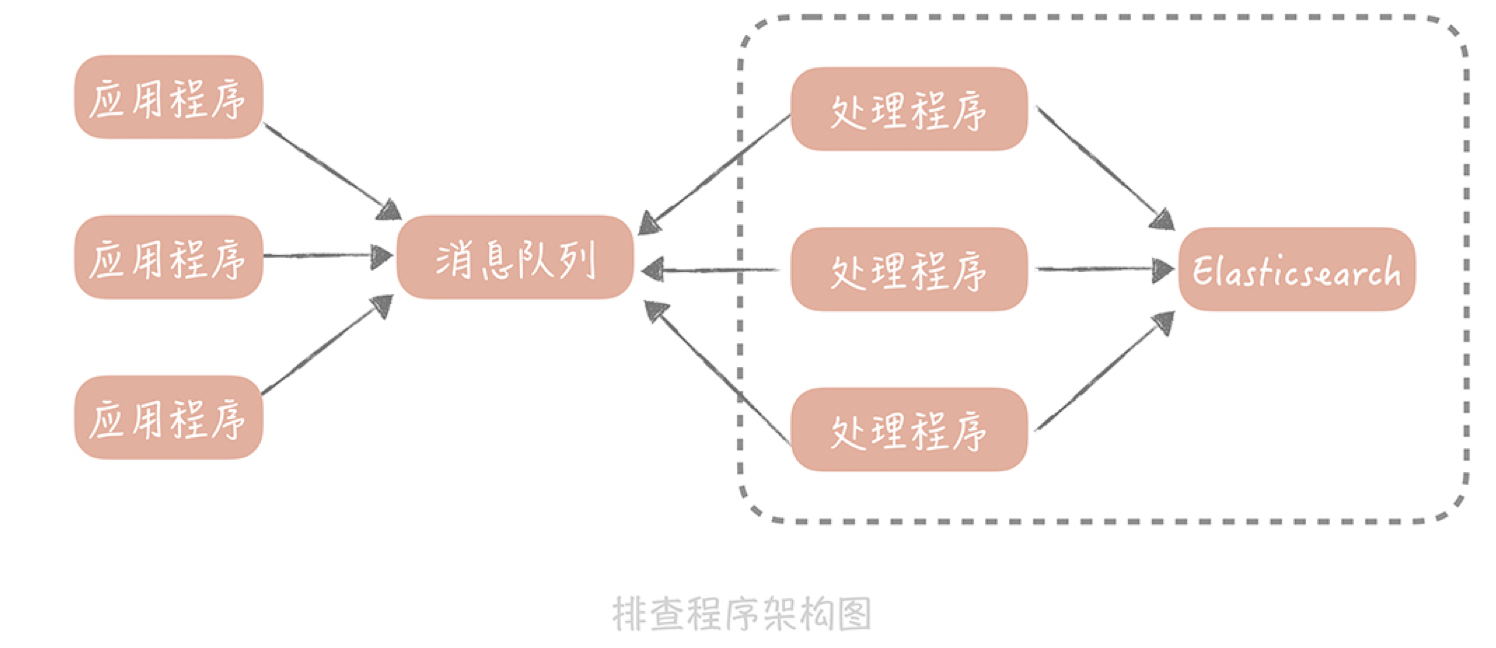
总结一下,为了排查单次请求响应时间长的原因,主要做了哪些事情:
- 1.在记录打点日志时,我们使用requestId将日志串起来,这样方便比较一次请求中的多个步骤的耗时情况;
- 2.增加了日志采样率,避免全量日志的打印;
- 3.最后为了避免在排查问题时,需要到多台服务器上搜索日志,我们使用消息队列,将日志集中起来放在了Elasticsearch中。
再来说一下分布式trace
在一体化架构中,单次请求的所有的耗时日志,都被记录在一台服务器上,而在微服务的场景下,单次请求可能跨越多个RPC服务,这就造成了,单次的请求的日志会分布在多个服务器上。
当然,你也可以通过requestId将多个服务器上的日志串起来,但是仅仅依靠requestId很难表达清楚服务之间的调用关系,所以从日志中,就无法了解服务之间是谁在调用谁。因此,我们采用traceId + spanId这两个数据维度来记录服务之间的调用关系(这里traceId就是requestId),也就是使用traceId串起单次请求,用spanId记录每一次RPC调用。
比如:你的请求从用户端过来,先到达A服务,A服务会分别调用B和C服务,B服务又会调用D和E服务。

- 用户到A服务之后会初始化一个traceId为100,spanId为1;
- A服务调用B服务时,traceId不变,而spanId用1.1标识,代表上一级的spanId是1,这一级的调用次序是1;
- A调用C服务时,traceId依然不变,spanId则变为了1.2,代表上一级的spanId还是1,而调用次序则变成了2,以此类推。
通过这种方式,我们可以在日志中,清晰地看出服务的调用关系是如何的,方便在后续计算中调整日志顺序,打印出完整的调用链路。
那么spanId是何时生成的,又是如何传递的呢?这部分内容可以算作一个延伸点,能够帮你了解分布式trace中间件的实现原理。
首先,A服务在发起RPC请求服务B前,先从线程上下文中获取当前的traceId和spanId,然后,依据上面的逻辑生成本次RPC调用的spanId,再将spanId和traceId序列化后,装配到请求体中,发送给服务方B。
服务方B获取请求后,从请求体中反序列化出spanId和traceId,同时设置到线程上下文中,以便给下次RPC调用使用。在服务B调用完成返回响应前,计算出服务B的执行时间发送给消息队列。
当然,在服务B中,你依然可以使用切面编程的方式,得到所有调用的数据库、缓存、HTTP服务的响应时间,只是在发送给消息队列的时候,要加上当前线程上下文中的spanId和traceId。
这样,无论是数据库等资源的响应时间,还是RPC服务的响应时间就都汇总到了消息队列中,在经过一些处理之后,最终被写入到Elasticsearch中以便给开发和运维同学查询使用。
而在这里,你大概率会遇到的问题还是性能的问题,也就是因为引入了分布式追踪中间件,导致对于磁盘I/O和网络I/O的影响,“避坑”指南就是:如果你是自研的分布式trace中间件,那么一定要提供一个开关,方便在线上随时将日志打印关闭;如果使用开源的组件,可以开始设置一个较低的日志采样率,观察系统性能情况再调整到一个合适的数值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号