神经网络MPLClassifier分类
代码:
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Fri Aug 24 14:38:56 2018 4 5 @author: zhen 6 """ 7 import gzip 8 import pickle 9 import numpy as np 10 from sklearn.neural_network import MLPClassifier 11 12 # 加载数据 13 # 设置编码,解决异常:UnicodeDecodeError: 'ascii' codec can't decode byte 0x90 in position 614: ordinal not in range(128) 14 with gzip.open("E:/mnist.pkl.gz") as fp: 15 training_data, valid_data, test_data = pickle.load(fp, encoding='bytes') 16 x_training_data, y_training_data = training_data 17 x_valid_data, y_valid_data = valid_data 18 x_test_data, y_test_data = test_data 19 classes = np.unique(y_test_data) 20 21 # 将验证集和训练集合并 22 x_training_data_final = np.vstack((x_training_data, x_valid_data)) 23 y_training_data_final = np.append(y_training_data, y_valid_data) 24 25 # 设置神经网络模型参数 26 # 使用solver='lbfgs',拟牛顿法,需要较多的跌点次数 27 lbfgs = MLPClassifier(solver='lbfgs', activation='relu', alpha=1e-4, hidden_layer_sizes=(50, 50), random_state=1, max_iter=10, verbose=10, learning_rate_init=0.1) 28 # 使用solver='adam',基于随机梯度下降的优化算法,准确率较低 29 adam = MLPClassifier(solver='adam', activation='relu', alpha=1e-4, hidden_layer_sizes=(50, 50), random_state=1, max_iter=10, verbose=10, learning_rate_init=0.1) 30 # 使用solver='sgd',基于梯度下降的自适应优化算法,分批训练数据,效率高,准确性高,建议使用 31 sgd = MLPClassifier(solver='sgd', activation='relu', alpha=1e-4, hidden_layer_sizes=(50, 50), random_state=1, max_iter=10, verbose=10, learning_rate_init=0.1) 32 33 34 # 使用不同算法训练模型 35 lbfgs.fit(x_training_data_final, y_training_data_final) 36 adam.fit(x_training_data_final, y_training_data_final) 37 sgd.fit(x_training_data_final, y_training_data_final) 38 39 # 预测 40 lbfgs_predict = lbfgs.predict(x_test_data) 41 adam_predict = adam.predict(x_test_data) 42 sgd_predict = sgd.predict(x_test_data) 43 44 print(lbfgs_predict) 45 print("*******************************************") 46 print(adam_predict) 47 print("@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@") 48 print(sgd_predict) 49 print("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!") 50 # 评估模型 51 print(lbfgs.score(x_test_data, y_test_data)) 52 print("===========================================") 53 print(adam.score(x_test_data, y_test_data)) 54 print("-------------------------------------------") 55 print(sgd.score(x_test_data, y_test_data)) 56 57 # 输出正确结果 58 print(y_test_data)
结果:
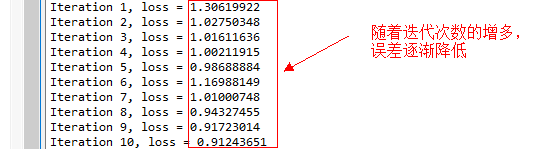
max_iter=10
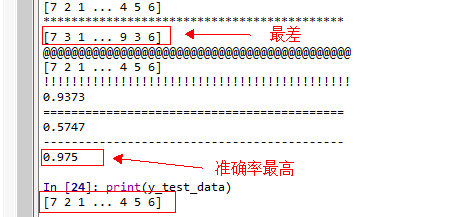
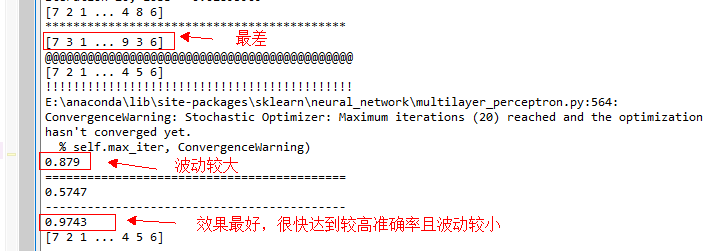
max_iter=20
注意:
1. 当使用pickle加载mnist数据时,python3.x与python2.x差距较大,python3.x会抛出异常,异常信息为:UnicodeDecodeError: 'ascii' codec can't decode byte 0x90 in position 614: ordinal not in range(128)
此时需要指定编码pickle.load(fp, encoding='bytes')来解决异常!
2. 比较lbfgs(拟牛顿法)、adam(基于随机梯度下降的优化算法)和sgd(基于梯度下降的自适应优化算法)可知,lbfgs波动较大,在相同训练数据的情况下,当迭代次数不同时,模型预测准确率波动较大。adam算法模型训练较快,但模型预测准确率较差,适合应用在预测准确率要求不高,响应时间短的地方。sgd算法在模型训练速度和预测准确率方面都能达到较好的效果,建议使用!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号