Solr7.7高级应用【MLT相似文档搜索、自动补全、自动纠错】
一.配置solr
1.上传并解压Solr包
解压命令:tar -zxvf solr-7.7.2
2.拷贝基础core
进入 /solr-7.7.2/server/solr/configsets/目录,执行命令:cp -r sample_techproducts_configs/ ../electronic,拷贝sample_techproducts_configs文件夹到上级目录,重命名为electronic。
3.启动solr
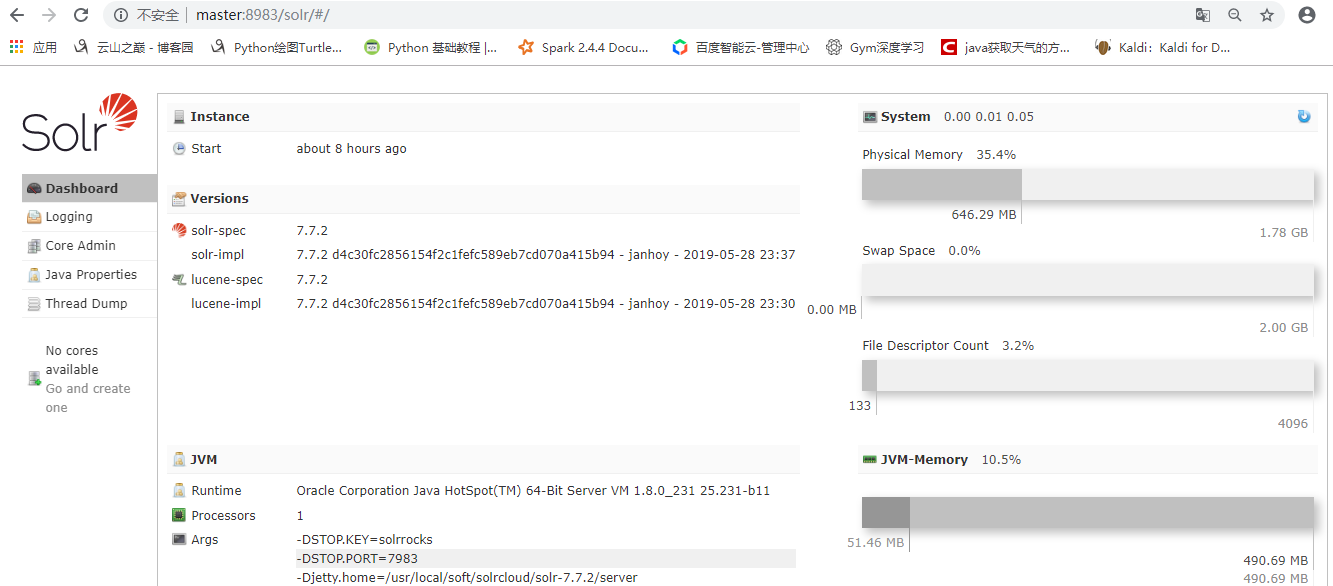
进入bin目录下执行命令:./solr start启动单机模式的solr,执行完成后打开浏览器,进入http://master:8983/solr/#/ solr界面,效果如下:
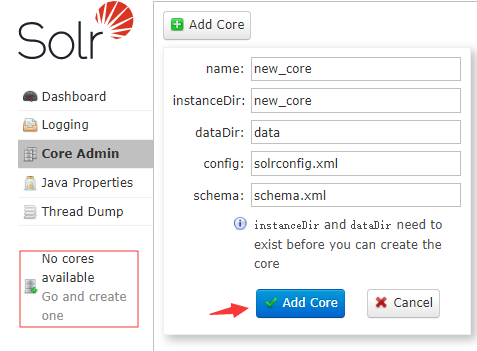
4.创建新core
点击No cores按钮,在弹出的界面上输入你要创建的core的信息,包括名称和相关配置目录:
创建成功,如下:
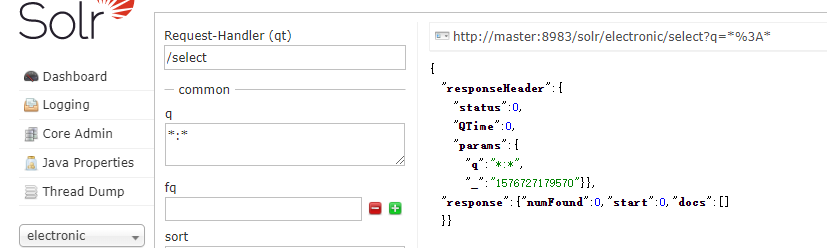
备注:instanceDir必须为之前准备好的配置,例如上面我拷贝的electronic,否则创建失败!
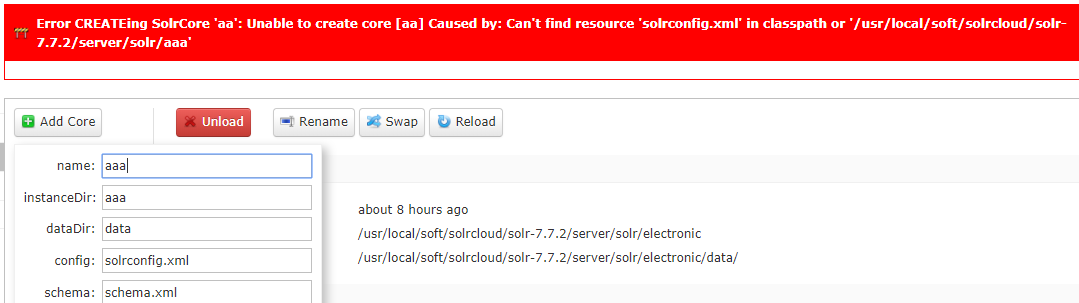
另外,因solr创建好之后不允许对配置做大幅度改动,特别是索引已经创建【可能导致失败】,因此创建core之前最好先配置好你需要的字段或者高级应用!
二.配置HanLP分词器
1. 配置配置文件
从下载的HanLP中获取hanlp.properties配置文件,放置到下面的路径中。
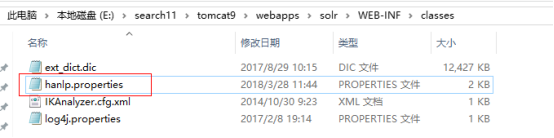
2. 导入HanLP词典
从下载的HanLP中拷贝data到下图目录下,该data包含Hanlp中提供的词库和模型。
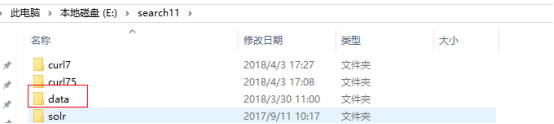
3. 导入jar包
把HanLP中的hanlp-1.5.0.jar和hanlp-1.5.0.sources.jar放到tomcat的该目录下

4. 修改hanlp.properties中的,改成data的上级目录
5.配置分词器
在使用该分词器的core中的managed-schema文件中添加
<fieldType name="text_cn" class="solr.TextField">
<analyzer type="index">
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory"
enableIndexMode="true" enablePlaceRecognize="true" enableOrganizationRecognize="true" customDictionaryPath="E:\search11\data\dictionary\custom\自定义词典.txt"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<!-- 切记不要在query中开启index模式 -->
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory"
enableIndexMode="false" enablePlaceRecognize="true" enableOrganizationRecognize="true" customDictionaryPath="E:\search11\data\dictionary\custom\自定义词典.txt"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt"
ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
6.修改使用该分词器的字段

7.结果

三.配置Tika文档提取器
1. 首先在core中添加tika文档搜索
<requestHandler name="/update/extract" class="org.apache.solr.handler.extraction.ExtractingRequestHandler" startup="lazy">
<lst name="defaults">
<!-- All the main content goes into "text"... if you need to return
the extracted text or do highlighting, use a stored field. -->
<str name="fmap.content">text</str>
<str name="lowernames">false</str>
<str name="uprefix">ignored_</str>
<!-- capture link hrefs but ignore div attributes -->
</lst>
</requestHandler>
2. 配置tika解析文档的分类字段
<!-- Tika字段 -->
<field name="PK" type="string" indexed="true" stored="true" required="true" multiValued="false"/>
<field name="BT" type="string" indexed="true" stored="true" termVectors="true" multiValued="false"/>
<field name="ZZ" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="NR" type="text_cn" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true"/>
<field name="CJSJ" type="date" indexed="true" stored="true" />
3. 修改tomcat的server.xml配置
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"
maxHttpHeaderSize ="104857600" maxPostSize="0" />
注意:
maxHttpHeaderSize :设置最大上传头大小
maxPostSize:解除post提交大小限制
4. 结果

四.配置HTML及相关样式过滤器
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- 清除\n样式 -->
<charFilter class="solr.MappingCharFilterFactory"
mapping="mapping-FoldToASCII.txt"/>
<charFilter class="solr.HTMLStripCharFilterFactory"/><!-- 清除HTML样式 -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<charFilter class="solr.HTMLStripCharFilterFactory"/><!-- 清除HTML样式 -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt"
ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
五.配置MLT文档相识度搜索
1.添加配置
<!-- Solr More like this 文件相似度搜索用到此配置 -->
<requestHandler name="/mlt" class="solr.MoreLikeThisHandler">
<lst name="defaults">
<!-- wt即writer type,即返回的数据的MIME类型,如json,xml等等 -->
<str name="wt">json</str>
<str name="fl">
ZSYBS,ZSYWT,ZSYDA,ZSBS,XH,ZSDZT,CZRBS,ZZBM,DQBM,FJFZBS,
SCJBS,ZSYWB,YXQ,YDHS,GDMB,ZSLX,CZSJ,CJSJ</str><!-- 需要返回的字段 -->
<str name="mlt.qf"> <!-- 设置 mlt.fl中的各个字段的权重 -->
ZSYWT^2.0 ZSYWB^1.0
</str>
<str name="mlt.fl">ZSYWT,ZSYWB</str><!-- 指定用于判断是否相似的字段 -->
<str name="mlt.match.include">true</str>
<!-- 指定最小的分词频率,小于此频率的分词将不会被计算在内 -->
<str name="mlt.mintf">1</str>
<!-- 指定最小的文档频率,分词所在文档的个数小于此值的话将会被忽略 -->
<str name="mlt.mindf">1</str>
<!-- 指定分词的最小长度,小于此长度的单词将被忽略。 -->
<str name="mlt.minwl">2</str>
<!-- 默认值5. 设置返回的相似的文档数 -->
<int name="mlt.count">10</int>
<str name="df">ZSYBS</str>
<str name="q.op">AND</str>
</lst>
</requestHandler>
2.测试结果

六.配置SolrJ高亮展示
1. 高亮的默认配置
<!-- Highlighting defaults -->
<str name="hl">on</str>
<str name="hl.fl">content features title name</str>
<str name="hl.preserveMulti">true</str>
<str name="hl.encoder">html</str>
<str name="hl.simple.pre"><b></str>
<str name="hl.simple.post"></b></str>
<str name="f.title.hl.fragsize">0</str>
<str name="f.title.hl.alternateField">title</str>
<str name="f.name.hl.fragsize">0</str>
<str name="f.name.hl.alternateField">name</str>
<str name="f.content.hl.snippets">3</str>
<str name="f.content.hl.fragsize">200</str>
<str name="f.content.hl.alternateField">content</str>
<str name="f.content.hl.maxAlternateFieldLength">750</str>
2. 启用高亮
SolrQuery solrQuery = new SolrQuery();
solrQuery.setQuery("ZSYWT:交易电价"); //设置查询关键字
solrQuery.setHighlight(true); //开启高亮
solrQuery.addHighlightField("ZSYWT"); //高亮字段
solrQuery.addHighlightField("ZSYWB"); //高亮字段
solrQuery.setHighlightSimplePre("<font color='red'>"); //高亮单词的前缀
solrQuery.setHighlightSimplePost("</font>"); //高亮单词的后缀
solrQuery.setParam("hl.fl", "ZSYWT");
七.配置搜索关键词自动补全(汉字,拼音)
-
添加配置
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str>
<str name="lookupImpl">FuzzyLookupFactory</str>
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<str name="field">ZSYWT_PINYIN</str><!--匹配字段,可以使用copyField实现多列-->
<!--权重,用于排序-->
<!--<str name="weightField">ZSYWB</str>-->
<str name="suggestAnalyzerFieldType">text_cn</str>
</lst>
</searchComponent>
<requestHandler name="/suggest" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="suggest">true</str>
<str name="suggest.build">true</str>
<str name="suggest.dictionary">mySuggester</str><!--与上面保持一致-->
<str name="suggest.count">10</str>
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>
2.设置搜索字段
<!-- 设置自动补全 -->
<field name="ZSYWT_PINYIN" type="text_cn" indexed="true"
stored="true" multiValued="true"/>
<copyField source="PINYIN" dest="ZSYWT_PINYIN"/>
<copyField source="ZSYWT" dest="ZSYWT_PINYIN"/>
3.测试结果

八.搜索关键词自动纠错
代码实现:
public Collection<List<String>> getAutomaticErrorCorrection(String content)
throws SolrServerException, IOException {
HttpSolrServer server = new HttpSolrServer(url);
SolrQuery params = new SolrQuery();
params.set("qt", "/suggest");
//全部转换为拼音
StringBuilder sb = new StringBuilder();
char[] array = content.toCharArray();
for(int j=0;j<array.length;j++){
if(isChineseByBlockStyle(array[j])){
List<Pinyin> pinyinMidList = HanLP.convertToPinyinList(""+array[j]);
for (Pinyin pinyin : pinyinMidList)
{
sb.append(pinyin.getPinyinWithoutTone());
}
}else{
sb.append(array[j]);
}
}
params.setQuery(sb.toString());
QueryResponse response = null;
response = server.query(params);
SuggesterResponse suggest = response.getSuggesterResponse();
Collection<List<String>> collection = suggest.getSuggestedTerms().values();
server.close();
return collection;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号