Spark ML之高级数据源
一.图像数据源
图像数据源用于从目录加载图像文件,它可以通过ImageIO Java库将压缩图像(jpeg,png等)加载为原始图像表示形式。加载的DataFrame具有一StructType列:“ image”,其中包含存储为图像架构的图像数据。该image列的架构为:
- origin :(
StringType代表图像的文件路径) - height:(
IntegerType图像的高度) - width:(
IntegerType图像的宽度) - nChannels :(
IntegerType图像通道数) - mode:(
IntegerType兼容OpenCV的类型) - data:(
BinaryType以OpenCV兼容顺序的图像字节:大多数情况下按行BGR)
代码实现:
val image_df = spark.read.format("image").option("dropInvalid", true)
.load("D:\\software\\spark-2.4.4\\data\\mllib\\images\\origin\\kittens")
image_df.schema.printTreeString()
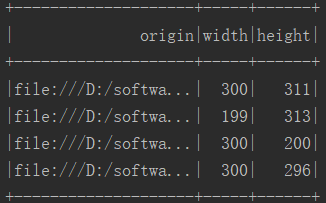
image_df.select("image.origin", "image.width", "image.height")
.show(true)
执行结果:

二.LIBSVM数据源
LIBSVM数据源用于从目录加载“ libsvm”类型的文件。加载的DataFrame有两列:包含以double形式存储的标签编号和包含以Vectors存储的特征向量的特征。列的模式为:
- label:(
DoubleType代表实例标签) - features :(
VectorUDT代表特征向量)
代码实现:
val libsvm_df = spark.read.format("libsvm").option("numFeatures", "780")
.load("D:\\software\\spark-2.4.4\\data\\mllib\\sample_libsvm_data.txt")
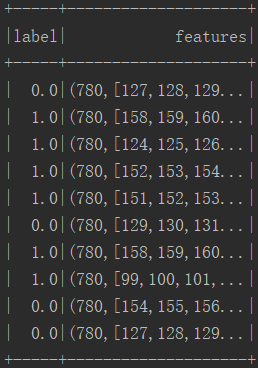
libsvm_df.show(10)
执行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号