深入理解Spark Streaming
一.DStream的两类操作
DStream内部其实是RDD序列,所有的DStream操作最终都转换为RDD操作。通过分析源码,可以进一步窥探这种转换是如何进行的。
DStream有一些与RDD类似的基础属性:
- 依赖的其它DStream列表。
- 生成RDD的时间间隔。
- 一个名为compute的计算函数,用于生成RDD,类似于RDD的compute。
DStream的操作分为两类,一类是Transformation操作,对应RDD的Transformation操作。以flatMap为例,DStream中的flatMap不过是返回一个新的DStream派生类FlatMappedDStream,这一点跟RDD的flatMap非常类似。DStream的flatMap定义如下:
/** * Return a new DStream by applying a function to all elements of this DStream, * and then flattening the results */ def flatMap[U: ClassTag](flatMapFunc: T => TraversableOnce[U]): DStream[U] = ssc.withScope { new FlatMappedDStream(this, context.sparkContext.clean(flatMapFunc)) }
而FlatMappedDStream的实现也很简单,主要作用是像RDD一样维护计算关系链,完整定义如下:
private[streaming] class FlatMappedDStream[T: ClassTag, U: ClassTag]( parent: DStream[T], flatMapFunc: T => TraversableOnce[U] ) extends DStream[U](parent.ssc) { override def dependencies: List[DStream[_]] = List(parent) override def slideDuration: Duration = parent.slideDuration override def compute(validTime: Time): Option[RDD[U]] = { parent.getOrCompute(validTime).map(_.flatMap(flatMapFunc)) } }
其中compute调用DStream的getOrCompute方法用于读取RDD的内存,要么放到缓存中,要么调用接口函数compute计算生成。
DStream另外一类操作是OutPut操作,Output操作才会触发DStream的实际执行,作用非常类似于RDD的Action操作,类如print操作,定义如下:
/** * Print the first ten elements of each RDD generated in this DStream. This is an output * operator, so this DStream will be registered as an output stream and there materialized. */ def print(): Unit = ssc.withScope { print(10) } /** * Print the first num elements of each RDD generated in this DStream. This is an output * operator, so this DStream will be registered as an output stream and there materialized. */ def print(num: Int): Unit = ssc.withScope { def foreachFunc: (RDD[T], Time) => Unit = { (rdd: RDD[T], time: Time) => { val firstNum = rdd.take(num + 1) // scalastyle:off println println("-------------------------------------------") println(s"Time: $time") println("-------------------------------------------") firstNum.take(num).foreach(println) if (firstNum.length > num) println("...") println() // scalastyle:on println } } foreachRDD(context.sparkContext.clean(foreachFunc), displayInnerRDDOps = false) }
DStream.print调用了RDD.take方法,而后者是一个Action操作,是不是所有的DStream输出操作最后都调用一个RDD的Action操作呢,看看saveAsTextFiles和saveAsObjectFiles,它们没有直接调用RDD Action操作【而是先调用一下rdd.saveAsTextFile】,然后通过foreachRDD来实现的,传入的函数中调用了RDD的Action。saveAsTextFiles的定义如下:
/** * Save each RDD in this DStream as at text file, using string representation * of elements. The file name at each batch interval is generated based on * `prefix` and `suffix`: "prefix-TIME_IN_MS.suffix". */ def saveAsTextFiles(prefix: String, suffix: String = ""): Unit = ssc.withScope { val saveFunc = (rdd: RDD[T], time: Time) => { val file = rddToFileName(prefix, suffix, time) rdd.saveAsTextFile(file) } this.foreachRDD(saveFunc, displayInnerRDDOps = false) }
相比之下,另外一个最灵活的Output操作foreachRDD完全依赖传入的函数来实现功能,所以对于foreachRDD的使用至少要包含一个RDD Action调用。因为Spark Streaming的调度是由Output方法触发的,每个周期调用一次所有定义的Output方法。Output内部再调用RDD Action最终完成计算,否则程序只会接收数据,然后丢弃,不执行计算。
二.容错处理
1.背景知识
DStream依赖RDD的容错机制。RDD是只读的、可重复计算的分布式数据集,它用线性链条的形式记录了RDD从创建开始,到中间每一步的计算过程,错误恢复的过程就是重新计算的过程,如果RDD某个分区因为任何原因数据丢失了,都可以使用记录起来的计算过程重新计算从而恢复数据,只要计算过程确定,即使集群出错也能保证确定的计算结果。
Spark操作的数据一般存储在有容错功能的文件系统【HDFS、S3等】上,从这些系统上的数据生成的RDD也具有容错能力,但是这个不适用于Spark Streaming。因为大部分场景下,Spark Streaming的数据来自网络,为了达到相同的容错能力,通过网络接收的数据还被复制到其它节点,这就导致错误发生时有两类数据需要恢复。
- 收到已经缓存,但未复制到其它节点的数据。因为没有其他副本,恢复的唯一方法是从数据源重新获取一份。
- 收到且已复制到其它节点的数据。这部分数据可以从其它节点恢复。
此外,还有两类可能发生的错误:
- worker节点失效。一旦计算节点失效,所有内存中的数据都会丢失且无法恢复。
- Driver节点失效。如果运行Driver进程的节点失效,那么SparkContext也会随之失效,整个Streaming程序会退出,所有附属的执行节点都会退出,内存中的数据全部丢失。
关于容错保证的效果定义,一般都是用数据被计算的次数来定义:
- 至多一次。每条记录最多被计算一次,或者根本没计算就丢失。
- 至少一次。保证每条记录都会被计算,最少计算一次,但可能会重复计算。
- 精准一次。保证每条记录都会被计算,且只计算一次,显然这是最佳的容错保证。
了解一下通用的流式计算过程有助于了解在每个环节的容错保证效果,一般流式计算分为3步:

要想实现精准一次的容错效果,我们需要确保每一步都能实现精准一次的计算。
- 数据接收,容错保障很大程度上依赖于数据源。
- Transformation计算,因为有RDD容错性在,所以可能实现精确一次的容错保障。
- 结果输出,默认只提供至少一次的容错保障,不能达到精准一次的级别,因为还依赖输出操作的类型和下一级接收系统是否支持事务特性。
2.数据接收容错
不同数据源提供不同程度的容错保障。
- 对于HDFS、S3等自带容错功能的文件系统,可以保证精准一次的容错能力。
- Spark1.3开始引入新的Kafka Direct API,也可以保证精准一次的容错能力。
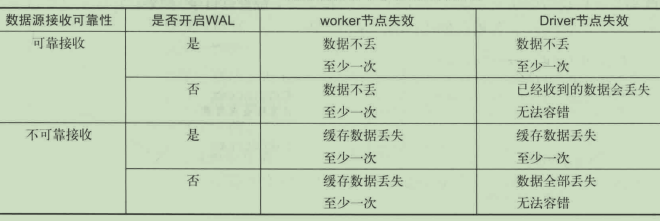
- 对于其他实用接收器来接收数据的场景,视接收机制是否可靠【有确认机制】以及是否开启WAL功能而不同。如果接收可靠且开启WAL功能,可以确保数据不丢失,并且提供实现至少一次级别的容错保障。在开启WAL的情况下,即使数据源接收不可靠,也只会丢失还在缓存的数据并且对其它数据实现至少一次级别的容错保障。其它情况下容错能力都不高,特别是Driver节点失效的情况下基本丧失容错能力。详情如下:
3.结果输出容错
结果输出操作本身提供至少一次级别的容错性能,就是说可能输出多次至外部系统,但可能通过一些辅助手段来实现精确一次的容错效果。
当输出为文件时是可以接受的,因为重复的数据会覆盖前面的数据,结果一致,效果相当于精确一次,其它场景下的输出要想实现精确一次的容错,需要一些额外的操作,如下:
- 幂等更新。确保多操作的效果与一次操作的效果相同,比如saveAsXXXFiles即使调用多次,结果还是同一个文件。
- 事务更新。更新时带有事务信息,确保更新只进行一次,比如使用批次时间和RDD的分区编号构造一个事务ID,在更新时使用ID来判断是否已经更新,如果已经更新过则跳过,避免重复,实现精准一次的容错效果。
4.检查点
由于流式计算7*24小时运行的特点,除了考虑具备容错能力,还要考虑容错的代价问题。为了避免错误恢复的代价与运行时间成正比增长,Spark提供了检查点功能,用户定期记录中间状态,避免从头开始计算的漫长恢复。
有一种情况下必须要启用检查点功能,那就是调用了有状态的Transformation操作,比如updateStateByKey或reduceByKeyAndWindow。因为有状态的操作是从程序开始时一直进行的,如果不做检查点,那么计算链会随着时间一直增长,重新计算的代价也将是天文数字。
另外,如果期望程序在因Driver节点失效后的重启之后可以继续运行,也建议开启检查点功能,可以记录配置、操作以及未完成的批次,这样重启后可以继续运行。
当然,不启用检查点也是可以的,实际上大部分程序都不需要,可根据需求进行设置。
开启检查点的方式很简单,调用streamingContext.checkpoint(checkpointDirectory)即可,参数是一个支持容错的文件系统目录,可以是HDFS或S3。
为了让Driver程序自动重启时也能使用检查点功能,还需要添加一些代码。主要改动是在启动后创建StreamingContext时检查一下检查点目录,如果存在则从这个目录恢复StreamingContext,否则就创建新的。如下:
/** * 创建ssc,根据检查点情况创建新的ssc * @return */ def functionToCreateContext() : StreamingContext = { val ssc = new StreamingContext(sc, Seconds(5)) ssc.checkpoint(checkpointDirectory) val lines = ssc.socketTextStream("master",9999) // 与nc端口对应 val words = lines.flatMap(_.split(" ")) var pairs = words.map(word=>(word,1)).reduceByKey(_+_) // 累加 pairs = pairs.updateStateByKey[Int](updateFunction _) // 必须设置检查点 pairs.foreachRDD(row => row.foreach(println)) ssc } // 根据检测点创建新的ssc val ssc = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
注意,代码执行的前提是在程序发布时配置了自动重启。检查点是有代价的,需要存储数据至存储系统,增加批次的计算时间,并且降低吞吐量,可以通过运行时的监控来查看实际的额外负载。可以通过增加周期的时间间隔来降低影响,一般建议时间间隔至少为10秒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号