Solr高级搜索【拼写检查】
一.拼写检查常用场景
1.查询包括一个或多个拼写错误的词,导致结果中得到不相关的内容。如果查询建议可用,搜索引擎应自动执行查询建议,向用户显示一条消息,如“显示的是xxx的搜索结果”或“仍然搜索xxx”。
2.查询包括罕见词,没有返回什么搜索结果。与此同时,存在可用的查询建议,并且能够得到多一些搜索结果。在这种情况下,搜索引擎提示用户“你是不是要找。。。?”。
3.查询包括拼写正确的词项。虽然存在可用的查询建议,但两者的搜索结果情况差不多。在这种情况下,搜索引擎无需向用户提供建议。
4.查询包括索引中不存在的词项,没有可用的查询建议。
从这4种情况可以得出拼写检查使用的两个关键要求。首先,需要一种方法识别出查询中每个词项的建议词。也就是说,在某种词典中查找与用户输入查询词项相似的词项。其次,需要知道每个建议词匹配了多少文档,这会对是否给出查询建议以及如何提示用户起到一定参考作用。
二.拼写检查案例
1.拼写检查


2.搜索不存在的词项
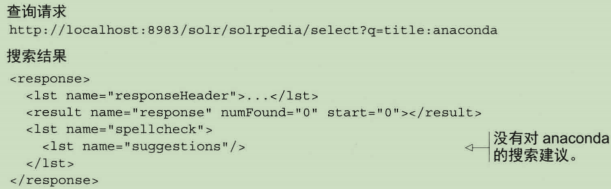
3.忽略查询建议

三.拼写检查搜索组件
拼写检查主要通过使用/spell请求处理器进行提交。默认配置如下:
<searchComponent name="spellcheck" class="solr.SpellCheckComponent"> <str name="queryAnalyzerFieldType">text_general</str> <!-- Multiple "Spell Checkers" can be declared and used by this component --> <!-- a spellchecker built from a field of the main index --> <lst name="spellchecker"> <str name="name">default</str> <str name="field">text</str> <str name="classname">solr.DirectSolrSpellChecker</str> <!-- the spellcheck distance measure used, the default is the internal levenshtein --> <str name="distanceMeasure">internal</str> <!-- minimum accuracy needed to be considered a valid spellcheck suggestion --> <float name="accuracy">0.5</float> <!-- the maximum #edits we consider when enumerating terms: can be 1 or 2 --> <int name="maxEdits">2</int> <!-- the minimum shared prefix when enumerating terms --> <int name="minPrefix">1</int> <!-- maximum number of inspections per result. --> <int name="maxInspections">5</int> <!-- minimum length of a query term to be considered for correction --> <int name="minQueryLength">4</int> <!-- maximum threshold of documents a query term can appear to be considered for correction --> <float name="maxQueryFrequency">0.01</float> <!-- uncomment this to require suggestions to occur in 1% of the documents <float name="thresholdTokenFrequency">.01</float> --> </lst> <!-- a spellchecker that can break or combine words. See "/spell" handler below for usage --> <lst name="spellchecker"> <str name="name">wordbreak</str> <str name="classname">solr.WordBreakSolrSpellChecker</str> <str name="field">name</str> <str name="combineWords">true</str> <str name="breakWords">true</str> <int name="maxChanges">10</int> </lst> </searchComponent>
当需要在查询中默认支持拼写检查,可以把spell里面的配置拷贝到/select中,这样默认查询就会支持拼写检查。
拼写检查参数详解:
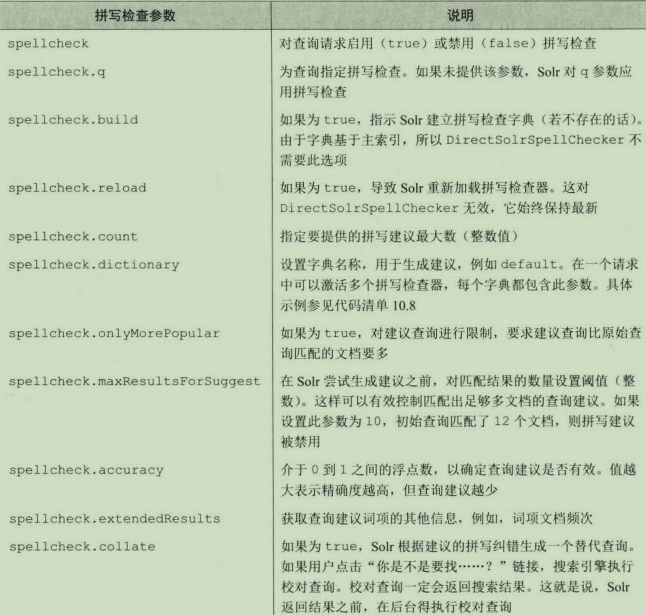

Solr4的默认拼写检查组件是DirectSolrSpellChecker组件。该组件根据主索引直接提供建议。而在Solr的早期版本中,需要基于主索引构建一个单独的拼写检查索引。在主索引改变后需要重新构建所有二级索引的情况,基于主索引提供建议的做法可以避免这种情况,因此该方法优于维护二级索引。
DirectSolrSpellChecker组件可以调整多个参数,其中最重要的三个参数分别是field、distanceMeasure和accuracy。field参数指定索引中用于提供建议的字段。distanceMeasure参数告诉Solr如何确定查询词的建议。accuracy参数是一个介于0~1之间的浮点数,它确定了查询建议需要的准确程度。数字越大,准确性越高,但会导致匹配结果减少,极端情况下可能没有可用的查询建议。如果accuracy设定值太低,Solr会产生很多查询建议,但无法保证这些查询建议对用户而言是有意义的。
用于拼写检查的文本分析
考虑一下在拼写检查字典的词项上应执行的文本分析类型。在大多数情况下,我们都希望文本分析粒度尽可能小,尤其要避免过滤器对词项进行大幅度修改,例如,词干提取或语音分析。
其它拼写检查实现方式
Solr拼写检查的强大特征之一是可以将多个拼写检查实现方法结合起来创建复合拼写检查方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号