
Spark之RDD内核剖析
一.Spark核心数据结构RDD
RDD是Spark最重要的抽象,掌握了RDD,可以说就掌握了Spark计算的精髓。它不但对理解现有Spark程序大有帮助, 也可能提升Spark程序编写能力。 RDD的全称是“弹性分布式数据集”。首先,它是一个数据集,就像Scala语言中的Array,List,Tuple,Set,Map也是数据集合一样,但从操作上看RDD最像Aarray和List, 里面的数据都是平铺的,可以顺序遍历。而且Array,List对象拥有的许多操作RDD对象也有,比如flatMap,map,filter, reduce,groupBy等。
其次,RDD是分布存储的,里面的成员被水平切割成小的数据块,分散在集群的多个节点上,便于对RDD里面的数据进行并行计算。最后,RDD的分布是弹性的,不是固定不变的。RDD的一些操作可以被拆分成对各数据块的直接计算,不涉及其它节点,比如map。这样的操作一般在数据块所在的节点上直接进行,不影响RDD的分布,除非某个节点故障需要转换到其它节点上。但是在有些操作中,只访问部分数据块是无法完成的,必须访问RDD的所有数据块。比如groupBy,在做groupBy之前完全不知道每个key的分布,必须遍历RDD的所有数据块,将具有相同key的元素汇总在一起,这样RDD的分布就完全重组,而且数量也可能发生变化。此外,RDD的弹性还表现在高可靠性上。
此外,RDD还具有如下特点:
1.RDD是只读的,一旦生成,内容就不能修改。这样的好处是让整个系统的设计相对简单,比如并行计算时不用考虑数据互斥的问题。
2.RDD可指定缓存级别,默认缓存到内存中。一般计算都是流水式生成、使用RDD,新的RDD生成之后,旧的不再使用,并被Java虚拟机回收。但如果后续有多个计算依赖某个RDD,我们可以让这个RDD缓存在内存中,避免重复计算。这个特性在机器学习等需要反复迭代的计算场景下对性能的提升尤为明显。
3.RDD可以通过重新计算得到。RDD的高可靠性不是通过复制来实现的,而是通过记录足够的计算过程,在需要时【比如因为节点故障导致内容失效】重新计算或从某个缓存镜像重新加载来恢复的。
二.RDD的定义
一个RDD对象,包含如下5个核心属性:
1.一个分区列表,每个分区里是RDD的部分数据【称为数据块】。
2.一个依赖列表,存储依赖的其它RDD。
3.一个名为compute的计算函数,用于计算RDD各分区的值。
4.分区器【可选】,用于键值对类型的RDD,比如某个RDD是按照散列来分区的。
5.计算各分区时优先的位置列表【可选】,比如从HDFS上的文件生成RDD时,RDD分区的位置优先选择数据所在的节点,这样可以避免数据移动带来的开销。
分区与依赖
依赖关系定义在一个Seq数据集中,类型是Dependency。有检查点时,这些信息被重写,指向检查点。如下:
private var dependencies_ : Seq[Dependency[_]] = null
分区定义在Array数据中,类型是Partition,没用Seq,这主要考虑到随时需要通过下标来访问或更新。如下:
@transient private var partitions_ : Array[Partition] = null
计算函数
compute方法由子类来实现,对输入的RDD分区进行计算
def compute(split : Partition, context : TaskContext) : Iterator[T]
分区器
可选,子类可以重写以指定新的分区方式。Spark支持两种分区方式:Hash和Range。
@transient val partitioner : Option[Partitioner] = None
优先计算位置
可选,子类可以指定分区优先的位置,比如HadoopRDD会重写此方法,让分区尽可能与数据在相同的节点上。
protected def getPreferredLocations(split : Partition) : Seq[String] = Ni;
RDD提供统一的调用方法,统一处理检查点问题
final def preferredLocations(split : Partition) : Seq[String] = {
checkpointRDD.map(_.getPreferredLocations(split)).getOrElse{
getPreferredLocations(split)
}
}
Spark调度和计算都基于这5个属性,各种RDD都有自己实现的计算,用户也可以方便地实现自己的RDD,比如从一个新的存储系统中读取数据。RDD及其常见子类的继承关系:
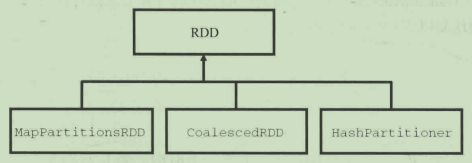
每个Transformation操作都会生成一个新的RDD,不同操作也可能返回相同类型的RDD,只是计算方法等参数不同。比如map,flatMap,filter这3个操作都会生成MapPartitionsRDD类型的RDD。
def map[U : ClassTag](f : T => U) : RDD[U] = withScope{
val cleanF = sc.clean(f)
new MapPartitionRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
def flatMap[U : ClassTag](f : T => TraversableOnce[U]) : RDD[U] = withScope{
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}
def filter(f : T => Boolean) : RDD[T] = withScope{
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T]{
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}
}
三.Transformation转换算子
RDD的Transformation是指由一个RDD生成新RDD的过程,比如前面使用的flatMap,map,filter操作都返回一个新的RDD对象,类型是MapPartitionsRDD,它是RDD的子类。所有的RDD Transformation操作都只是生成了RDD之间的计算关系以及计算方法,并没有进行真正的计算。
下面还是以wordCount为例进行分析:

每一个操作都会生成一个新的RDD对象【其类型为RDD子类】,它们按照依赖关系串在一起,像一个链表【DAG有向无环图】。WordCount计算过程中的RDD转换操作生成的RDD对象的依赖关系如下:
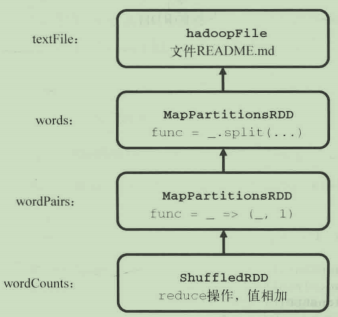
结合每一个RDD的数据和它们之间的依赖关系,每个RDD都可以按照依赖链追溯每个RDD的祖先,这些依赖链就是RDD重建和容错的基础。

private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag]( var prev: RDD[T], f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator) preservesPartitioning: Boolean = false, isFromBarrier: Boolean = false, isOrderSensitive: Boolean = false) extends RDD[U](prev) { override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None override def getPartitions: Array[Partition] = firstParent[T].partitions override def compute(split: Partition, context: TaskContext): Iterator[U] = f(context, split.index, firstParent[T].iterator(split, context)) override def clearDependencies() { super.clearDependencies() prev = null } @transient protected lazy override val isBarrier_ : Boolean = isFromBarrier || dependencies.exists(_.rdd.isBarrier()) override protected def getOutputDeterministicLevel = { if (isOrderSensitive && prev.outputDeterministicLevel == DeterministicLevel.UNORDERED) { DeterministicLevel.INDETERMINATE } else { super.getOutputDeterministicLevel } } }
备注:
1.preservesPartitioning:输入函数是否保留分区程序,除非“ prev”是一对RDD并且输入函数不会修改键,否则应为“ false”。
2.isFromBarrier:指示该RDD是否从RDDBarrier转换而来,一个包含至少一个RDDBarrier的状态应被转换为barrier状态。
3.isOrderSensitive:该函数是否对顺序敏感。 如果它是顺序敏感的,则更改输入顺序时,它可能会返回完全不同的结果。 有状态功能通常是顺序敏感的。
可以看到,MapPartitionsRDD最主要的工作是用变量f保存传入的计算函数,以便compute调用它来进行计算。其它4个重要属性基本保持不变。分区和优先计算位置没有重新定义,保持不变,依赖关系默认依赖调用的RDD,分区器优先使用上一级RDD的分区器,否则为None。
在Spark中,RDD是有依赖关系的,这种依赖关系有两种类型:
1.窄依赖:依赖上级RDD的部分分区【1对1,1对多】。
2.Shuffle依赖:依赖上级RDD的所有分区【多对多,多对1】。
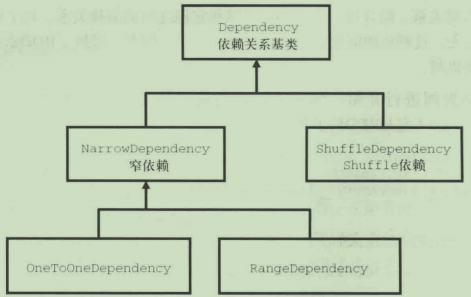
之所以这么区分依赖关系,是因为它们之间有本质的区别。使用窄依赖时,可以精确知道依赖的上级RDD的分区。一般情况下,会选择与自己在同一节点的上级RDD分区,这样计算过程都在同一节点进行,没有网络IO开销,非常高效,常见的map,flatMap,filter操作都是这一类。而Shuffle依赖则不同,无法精确定位依赖的上级RDD的分区,相当于依赖所有分区。计算时涉及所有节点之间的数据传输,开销巨大。所以以Shuffle依赖为分隔,Task被分成Stage,方便计算时的管理。
RDD仔细维护着这种依赖关系和计算方法,使得通过重新计算来恢复RDD成为可能。当然,这也不是万能的。如果依赖链太长,那么通过计算来恢复的代价就太大了。所以,Spark又提供了一种叫检查点的机制。对于依赖链条太长的计算,对中间结果存一份快照,这样就不需要从头开始计算了。特别是sparkstreaming流式计算,程序需要7*24小时不停运行,依赖链会无穷扩充,如果没有检查点机制,容错将完全没有意义。
四.Action算子
RDD的Action是相对Transformation的另一种操作。Transformation代表计算的中间过程,从一个RDD生产另一个RDD。而Action代表计算的结束,一次Action调用之后,不再生成新的RDD,结果返回到Driver程序。
鉴于Action具有这样的特点,所以Action操作是不可以在RDD Transformation内部调用的。如下就是错误的:
rdd.map(row => rdds.values.count() * row)
Transformation只是建立计算关系,而Action才是实际的执行。每个Action都会调用SparkContext的runJob方法向集群提交请求,所以每个Action对应一个Job。比如在count的实现中,先提交Job去集群上运行,返回结果到Driver程序,然后调用sum方法获取数据:
def count() : Long = sc.runJob(this, Utils.getIteratorSize _).sum
五.Shuffle操作
Shuffle的概念来自Hadoop的MapReduce计算过程。当对一个RDD的某个分区进行操作而无法精确知道依赖前一个RDD的哪个分区时,依赖关系变成了依赖前一个RDD的所有分区。比如,几乎所有<key, value>类型的RDD操作,都涉及按key对RDD成员进行重组,将具有相同key但分布在不同节点上的成员聚合到一个节点上,以便对它们的value进行操作。这种重组的过程就是Shuffle操作。因为Shuffle操作会涉及数据的传输,所以成本会比较高,而且过程复杂。
下面以reduceByKey为例来介绍。在进行reduce操作之前,单词Spark可能分布在不同的机器节点上,此时需要先把它们汇聚到一个节点上,这样汇聚的过程就是Shuffle,如图:
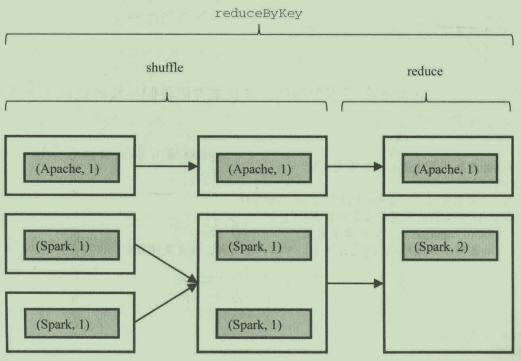
Shuffle是一个非常消耗资源的操作,除了会涉及大量网络IO操作并使用大量内存外,还会在磁盘上生成大量临时文件,以避免恢复时重新计算。因为Shuffle操作的结果其实是一次调度的Stage的结果,而一次Stage包含许多Task,缓存下来还是很划算的。Shuffle使用的本地磁盘目录由spark.local.dir属性项指定。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2019-04-11 Spark MLlib FPGrowth关联规则算法
2019-04-11 Spark MLlib KMeans 聚类算法
2019-04-11 英语【第一天】