Keras深度学习框架之损失函数
一.损失函数的使用
损失函数【也称目标函数或优化评分函数】是编译模型时所需的两个参数之一。
model.compile(loss='mean_squared_error', optimizer='sgd')
或
from keras import losses
model.compile(loss=losses.mean_squared_error, optimizer='sgd')
可以传递一个现有的损失函数名或者一个TensorFlow/Theano符号函数。该符号函数为每个数据点返回一个标量,有一下两个参数:
1.y_true
真实标签,TensorFlow/Theano张量。
2.y_pred
预测值,TensorFlow/Theano张量,其shape与y_true相同。
实际的优化目标是所有数据点的输出数组的平均值。
二.可用的损失函数
1.mean_squared_error(y_true, y_pred)【MSE,均方误差】
计算公式:
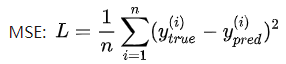
源码:

2.mean_absolute_error(y_true, y_pred)【MAE,平均绝对误差】
提到MAE就不能不说显著性目标检测,所谓显著性目标,举个例子来说,当我们观察一张图片时,我们会首先关注那些颜色鲜明,夺人眼球的内容。就像我们看变形金刚时会首先看擎天柱一样,这是绝对的C位。所以我们把变形金刚中的擎天柱定义为显著性目标。
在显著性目标检测中的评价指标计算中,常用的检测算法就有平均绝对误差,其计算公式如下:
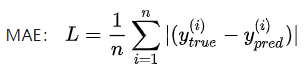
源码:
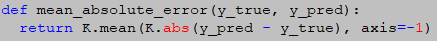
3.mean_absolute_percentage_error【MAPE,平均绝对百分比误差】
与平均绝对误差类似,平均绝对百分比误差预测结果与真实值之间的偏差比例。计算公式如下:

源码:

备注:
1.clip
逐元素,将超出指定范围的数强制变为边界数。
2.epsilon
固定参数,默认值为1*e-7。
4.mean_squared_logarithmic_error【MSLE,均方对数误差】
在计算均方误差之前先对数据取对数,再计算。
计算公式:
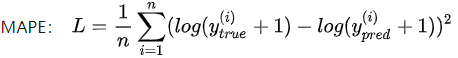
源码:

5.squared_hinage【不常用】
计算公式:
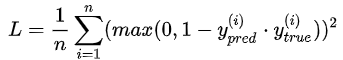
源码:

6.hinage【不常用】
计算公式:
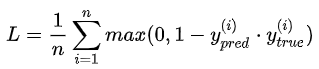
源码:

7.categorical_hinge【不常用】
源码:

8.logcosh【不常用】
预测误差的双曲余弦的对数。计算结果与均方误差大致相同,但不会受到偶尔疯狂的错误预测的强烈影响。
源码:

9.categorical_crossentropy【不常用】
当使用categorical_crossentropy损失时,目标值应该是分类格式【即假如是10类,那么每个样本的目标值应该是一个10维的向量,这个向量除了表示类别的那个索引为1,其它均为0】。为了将整数目标值转换为分类目标值,可以使用keras实用函数to_categorical。
from keras.utils.np_utils import to_categorical
categorical_labels = to_categorical(int_labels, num_classes=None)
源码:
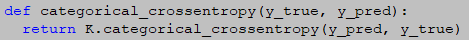
10.sparse_categorical_crossentropy【不常用】
源码:

11.binary_crossentropy【不常用】
源码:

12.kullback_leibler_divergence【不常用】
源码:

13.poisson【不常用】
计算公式:
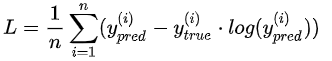
源码:
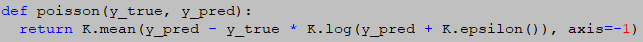
14.cosine_proximity【不常用】
计算公式:
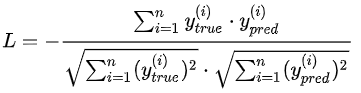
源码:

三.其它类型的损失函数
1.ctc_batch_cost【高性能】
源码:
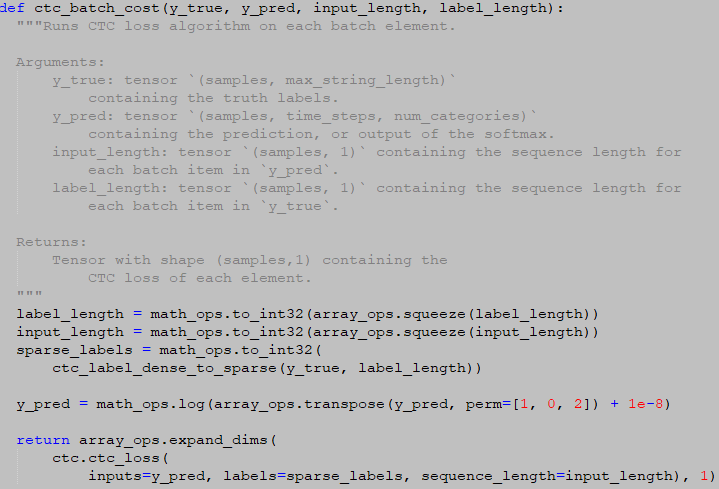
在每个批处理元素上运行CTC损失算法。
参数:
1.y_true
包含真实值标签的张量。类型(samples, max_string_length).
2.y_pred
包含预测值或softmax输出的张量。类型(samples, time_steps, num_categories)。
3.input_length
张量(samples, 1),包含y_pred中每个批处理项的序列长度。
4.label_length
张量(samples, 1), 包含y_true中每个批处理项的序列长度。
返回shape为(samples, 1)的张量,包含每一个元素的CTC损失。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号