Kaldi语音识别CVTE模型实战
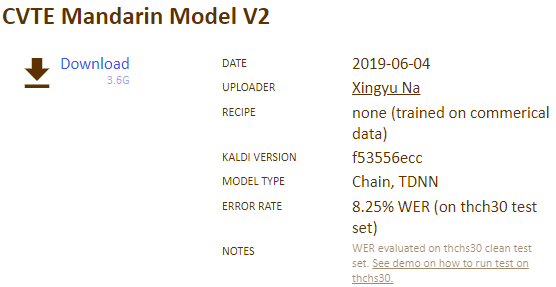
一.下载训练好的模型
下载路径:http://kaldi-asr.org/models/m2
二.上传&配置
1.上传到kaldi/egs/目录下
2.解压,tar -zxvf 0002_cvte_chain_model_v2.tar.gz
备注:因HCLG.fst模型解压后文件较大,在解压过程中会出现停顿,等待片刻即可!

3.将egs/wsj/s5中的steps和utils拷贝到egs/cvte/s5目录下


4.将egs/hkust/s5/local/score.sh拷贝到egs/cvte/s5/local/目录下


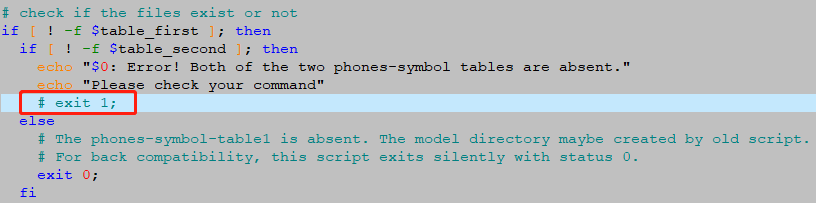
5.注释掉kaldi/egs/cvte/s5/utils/lang/check_phones_compatible.sh中if语句中的exit 1
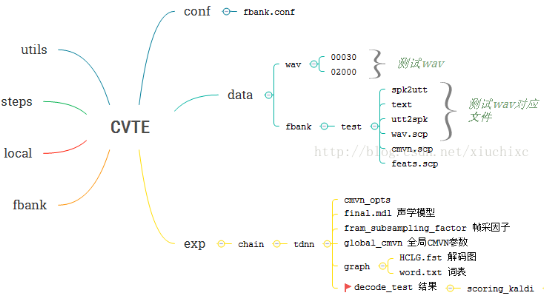
三.CVTE文件结构
四.运行示例脚本
1.运行
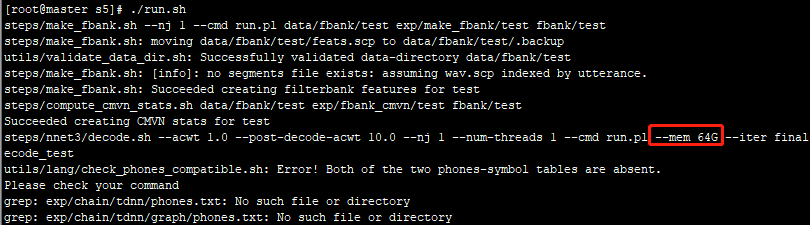
2.执行结果
bash: line 1: 5327 Killed ( nnet3-latgen-faster --frame-subsampling-factor=3 --frames-per-chunk=50 --extra-left-context=0 --extra-right-context=0 --extra-left-context-initial=-1 --extra-right-context-final=-1 --minimize=false --max-active=7000 --min-active=200 --beam=15.0 --lattice-beam=8.0 --acoustic-scale=1.0 --allow-partial=true --word-symbol-table=exp/chain/tdnn/graph/words.txt exp/chain/tdnn/final.mdl exp/chain/tdnn/graph/HCLG.fst "ark,s,cs:apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/fbank/test/split1/1/utt2spk scp:data/fbank/test/split1/1/cmvn.scp scp:data/fbank/test/split1/1/feats.scp ark:- |" "ark:|lattice-scale --acoustic-scale=10.0 ark:- ark:- | gzip -c >exp/chain/tdnn/decode_test/lat.1.gz" ) 2>> exp/chain/tdnn/decode_test/log/decode.1.log >> exp/chain/tdnn/decode_test/log/decode.1.log run.pl: job failed, log is in exp/chain/tdnn/decode_test/log/decode.1.log
备注:因运行该模型要求的最小内存为64G,因此在低于64G的情况下会被直接Kill掉!
3.参考别人的执行结果



 浙公网安备 33010602011771号
浙公网安备 33010602011771号