Spark实现分组TopN
一.概述
在许多数据中,都存在类别的数据,在一些功能中需要根据类别分别获取前几或后几的数据,用于数据可视化或异常数据预警。在这种情况下,实现分组TopN就显得非常重要了,因此,使用了Spark聚合函数和排序算法实现了分布式TopN计算功能。
二.代码实现
1 package scala 2 3 import org.apache.log4j.{Level, Logger} 4 import org.apache.spark.sql.types.{StringType, StructField, StructType} 5 import org.apache.spark.sql.{Row, SparkSession} 6 7 /** 8 * 计算分组topN 9 * Created by Administrator on 2019/11/20. 10 */ 11 object GroupTopN { 12 Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别 13 def main(args: Array[String]) { 14 //创建测试数据 15 val test_data = Array("CJ20191120,201911", "CJ20191120,201910", "CJ20191105,201910", "CJ20191105,201909", "CJ20191111,201910") 16 val spark = SparkSession.builder().appName("GroupTopN").master("local[2]").getOrCreate() 17 val sc = spark.sparkContext 18 val test_data_rdd = sc.parallelize(test_data).map(row => { 19 val Array(scene, cycle) = row.split(",") 20 Row(scene, cycle) 21 }) 22 // 设置数据模式 23 val structType = StructType(Array( 24 StructField("scene", StringType, true), 25 StructField("cycle", StringType, true) 26 )) 27 // 转换为df 28 val test_data_df = spark.createDataFrame(test_data_rdd, structType) 29 test_data_df.createOrReplaceTempView("test_data_df") 30 // 拼接周期 31 val scene_ws = spark.sql("select scene,concat_ws(',',collect_set(cycle)) as cycles from test_data_df group by scene") 32 scene_ws.count() 33 scene_ws.show() 34 scene_ws.createOrReplaceTempView("scene_ws") 35 /** 36 * 定义参数确定N的大小,暂定为1 37 */ 38 val sum = 1 39 // 创建广播变量,把N的大小广播出去 40 val broadcast = sc.broadcast(sum) 41 /** 42 * 定义Udf实现获取组内的前N个数据 43 */ 44 spark.udf.register("getTopN", (cycles : String) => { 45 val sum = broadcast.value 46 var mid = "" 47 if(cycles.contains(",")){ // 多值 48 val cycle = cycles.split(",").sorted.reverse // 降序排序 49 val min = Math.min(cycle.length, sum) 50 for(i <- 0 until min){ 51 if(mid.equals("")){ 52 mid = cycle(i) 53 }else{ 54 mid += "," + cycle(i) 55 } 56 } 57 }else{ // 单值 58 mid = cycles 59 } 60 mid 61 }) 62 63 val result = spark.sql("select scene,getTopN(cycles) cycles from scene_ws") 64 result.show() 65 spark.stop() 66 } 67 }
三.结果
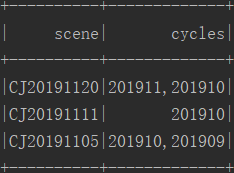

四.备注
当N大于1时,多个数据会拼接在一起,若想每个一行,可是使用使用列转行功能,参考我的博客:https://www.cnblogs.com/yszd/p/11266552.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号