SparkStreaming高级算子应用【combineByKey、transform,checkpoint】
一.combineByKey算子简介
功能:实现分组自定义求和及计数。
特点:用于处理(key,value)类型的数据。
实现步骤:
1.对要处理的数据进行初始化,以及一些转化操作
2.检测key是否是首次处理,首次处理则添加,否则则进行分区内合并【根据自定义逻辑】
3.分组合并,返回结果
二.combineByKey算子代码实战
1 package big.data.analyse.scala.arithmetic 2 3 import org.apache.spark.sql.SparkSession 4 /** 5 * Created by zhen on 2019/9/7. 6 */ 7 object CombineByKey { 8 def main (args: Array[String]) { 9 val spark = SparkSession.builder().appName("CombineByKey").master("local[2]").getOrCreate() 10 val sc = spark.sparkContext 11 sc.setLogLevel("error") 12 13 val initialScores = Array((("hadoop", "R"), 1), (("hadoop", "java"), 1), 14 (("spark", "scala"), 1), (("spark", "R"), 1), (("spark", "java"), 1)) 15 16 val d1 = sc.parallelize(initialScores) 17 18 val result = d1.map(x => (x._1._1, (x._1._2, x._2))).combineByKey( 19 (v : (String, Int)) => (v : (String, Int)), // 初始化操作,当key首次出现时初始化以及执行一些转化操作 20 (c : (String, Int), v : (String, Int)) => (c._1 + "," + v._1, c._2 + v._2), // 分区内合并,非首次出现时进行合并 21 (c1 : (String,Int),c2 : (String,Int)) => (c1._1 + "," + c2._1, c1._2 + c2._2)) // 分组合并 22 .collect() 23 24 result.foreach(println) 25 } 26 }
三.combineByKey算子执行结果

四.transform算子简介
在spark streaming中使用,用于实现把一个DStream转化为另一个DStream。
五.transform算子代码实现
1 package big.data.analyse.streaming 2 3 import org.apache.log4j.{Level, Logger} 4 import org.apache.spark.SparkConf 5 import org.apache.spark.streaming.{Seconds, StreamingContext} 6 7 /** 8 * Created by zhen on 2019/09/21. 9 */ 10 object StreamingSocket { 11 12 def functionToCreateContext():StreamingContext = { 13 val conf = new SparkConf().setMaster("local[2]").setAppName("StreaingTest") 14 val ssc = new StreamingContext(conf, Seconds(10)) 15 val lines = ssc.socketTextStream("192.168.245.137", 9999) 16 17 val words = lines.flatMap(_.split(" ")) 18 val pairs = words.map(word=>(word,1)) 19 20 /** 21 * 过滤内容 22 */ 23 val filter = ssc.sparkContext.parallelize(List("money","god","oh","very")).map(key => (key,true)) 24 25 val result = pairs.transform(rdd => { // transform:把一个DStream转化为另一个SDtream 26 val leftRDD = rdd.leftOuterJoin(filter) 27 val word = leftRDD.filter( tuple =>{ 28 val y = tuple._2 29 if(y._2.isEmpty){ 30 true 31 }else{ 32 false 33 } 34 }) 35 word.map(tuple =>(tuple._1,1)) 36 }).reduceByKey(_+_) 37 38 result.foreachRDD(rdd => { 39 if(!rdd.isEmpty()){ 40 rdd.foreach(println) 41 } 42 }) 43 ssc.checkpoint("D:\\checkpoint") 44 ssc 45 } 46 Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别 47 def main(args: Array[String]) { 48 val ssc = StreamingContext.getOrCreate("D:\\checkpoint", functionToCreateContext _) 49 50 ssc.start() 51 ssc.awaitTermination() 52 ssc.stop() 53 } 54 }
六.transform算子执行结果
输入:
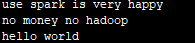
输出:

备注:若在执行流计算时报:Some blocks could not be recovered as they were not found in memory. To prevent such data loss, enable Write Ahead Log (see programming guide for more details.,可以清空checkpoint目录下对应的数据【当前执行生成的数据】,可以解决这个问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号