Solr基础理论【倒排索引,模糊查询】
一.简介
现有的许多不同类型 的技术系统,如关系型数据库、键值存储、操作磁盘文件的map-reduce【映射-规约】引擎、图数据库等,都是为了帮助用户解决颇具挑战性的数据存储与检索问题而设计的。而搜索引擎,尤其是Solr,致力于解决一类特定的问题:搜索大量非结构化的文本数据,并返回最相关的搜索结果。
二.文档
Solr是一个文档存储与检索引擎。提交给solr处理的每一份数据都是一个文档。文档可以是一篇新闻报道、一份简历、社交用户信息,甚至是一本书。
每个文档包含一个或多个字段,每个字段被赋予具体的字段类型:字符串、标记化文本、布尔值、日期/时间、经纬度等。潜在的字段类型数量是无限的,因为一个字段类型是有若干个分析步骤组成的,这些步骤会决定数据如何在字段中被处理,以及如何映射到Solr索引中。每个字段在solr的schema文件中被指定特定的字段类型,并告知solr接收到此类内容的处理办法。
如下:
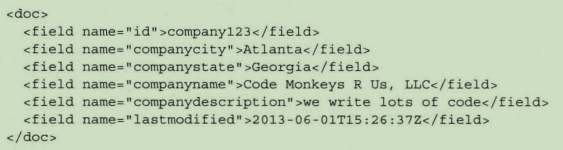
要在solr上执行一个查询,可以在文档上搜索一个或多个字段,即使字段未包含在该文档中。solr将返回哪些包含了与查询匹配的字段内容的文档。值得注意的是,虽然solr为每个文档提供了一个灵活的schema文件,但灵活并不代表无模式。在solr的schema文件中,所有的字段必须被定义,所有的字段名称【包括动态字段命名模式】必须被指定类型。这并不意味着每个文档必须包含所有字段,仅当所有可能的字段出现在一个文档中需要处理时,才会被全部映射到特定字段类型中。当首次接收到包含新字段的文档时,solr会自动猜测未知的新字段类型。通过检查字段中的数据类型,自动将字段增加到solr的schema中。如果输入的数据难以理解,solr可能会对字段类型识别失败,因此,更好的做法是预先定义好字段类型。
三.倒排索引
Solr使用Lucene倒排索引来驱动快速搜索功能,并且在查询时提供了许多其他附加功能。
原理:

在传统数据库中,多个文档的表征是一个文档id对应一个或多个内容字段,这些字段包含文档中出现的单词/词项。倒排索引将这个模型颠倒过来,将语料库中的每个单词/词项与出现它们的文档对应起来。在插入倒排索引之前,原始输入的文本会根据空格进行拆分【英文分词,汉语分词使用分词器】,每个词项转换为小写,其它部分保持不变。值得注意的是,在实际中可能还需要很多其它的文本转化,不仅仅是这些简单的处理。在内容分析处理中词项可以被修改,添加或删除。
倒排索引的两个特点:
1.倒排索引中的所有词项对应一个或多个文档。
2.倒排索引中的词项根据字典顺序升序排列。
3.布尔逻辑
Solr默认配置为查询词之间是OR运算。OR运算符为二元运算符,solr还支持+【正,表示true】,-【负,表示false,取反】等一元运算符。
例如:id:'zhangsan' AND -name:'lisi'
4.实现逻辑

四.模糊查询
既定查询在solr索引中能找到怎样的搜索结果,这并不是总能提前准确知晓,所以solr提供了几种模糊匹配查询功能。模糊匹配可以对索引中的词项进行并不那么准确的匹配。例如,有人想搜索特定的前缀开头的查询【通配符搜索】,有人下个搜索一个或两个字符的拼写变化【模糊搜索或编辑距离搜索】,有人想根据特定距离来匹配两个查询词【邻近搜索】。查询词与短语的多种变化存在于被搜索的文档中,这种情况正是模糊匹配的用武之地。
1.通配符搜索
由于能匹配到的词汇变化已经存在于solr的索引中,所以可以使用星号【*】通配符实现相同的查询功能。星号通配符匹配查询词中0个或多个字符。若只匹配单个字符,可以使用问好【?】来实现。
备注:首位通配符,虽然solr的通配符功能相当强大,但特定的通配符查询执行可能花销巨大。当通配符搜索执行时,倒排索引中的所有词项与第一个通配符之前的查询词部分匹配。接下来,检查每个候选词项是否与查询中的通配符相匹配。正因为如此,在通配符之前指定越多的字符,查询执行速度越快。执行首位通配符查询是一项花销甚大的操作。例如,假设你需要匹配以ing结尾的所有词项,那么可能会导致严重的性能问题。这是可以做一些额外的配置,在字段类型的分析链中增加ReversedWildcardFilterFactory类。这个类表示在solr索引中两次插入被索引的内容,一次是每个词项的文本,另一个是每个文本的反向文本。带有*ing首位通配符的查询提交后,solr会搜索反向版本【*ing也会转为gni*】,将首位通配符搜索转为标准通配符搜索,这会在反向内容中导致性能问题。在Solr中对所有词项开启双索引,会增加索引的大小且拖慢整体搜索效率。除非必须,否则不建议开启这个功能。
2.区间搜索
solr还提供了在已知区间值中进行搜索的功能,适用于在一个区间内搜索特定文档子集。例如,year:[18 TO 20],匹配:18,19,20,区间查询使用方括号,这是包含边界值的语法。另外,solr还支持使用大括号实现不包含边界值的搜索。;例如:year:[18,20},匹配:18,19。
3.模糊/编辑距离搜索
对于多数搜索应用而言,精确匹配用户输入的文本,灵活处理拼写错误,甚至对正确拼写做出细微修正都是非常重要的。solr基于Damerau-Levenshtein距离的编辑距离度量方法提供了字符变体的处理手段,可以有效解决80%以上的人为拼写错误。solr使用~符号表示模糊编辑距离搜索。例如:adm~。这个查询匹配到原始词项【admin】及与之相距两个编辑距离的其它词项【adman,admni等】。编辑距离被定义为字符的一次插入、删除、替换或位置互换。另外可以修改编辑距离的大小,让搜索可以匹配任意编辑距离的词项。例如:adm~1匹配1个以内的编辑距离。adm~2匹配两个以内的编辑距离【默认值】。请注意,两个以上的编辑距离会使搜索速度大幅下降,也可能匹配出意外的词项。一个或两个编辑距离的搜索使用有效的Levenshtein自动机方法执行,但超过两个编辑距离的查询就会退回更慢的编辑距离实现方法。
4.邻近搜索
与编辑距离搜索类似,邻近搜索可以搜索词与词之间间隔多少词来进行搜索。例如:chief officer ~1匹配两词之间最多间隔一个词这种情况。注意,邻近搜索并不适用于真实的编辑距离,换位可能只算是一次编辑操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号