Spark ML协同过滤推荐算法
一.简介
协同过滤算法【Collaborative Filtering Recommendation】算法是最经典、最常用的推荐算法。该算法通过分析用户兴趣,在用户群中找到指定用户的相似用户,综合这些相似用户对某一信息的评价,形成系统关于该指定用户对此信息的喜好程度预测。
二.步骤
1.收集用户偏好。
2.找到相似的用户或物品。
3.计算推荐。
三.用户评分
从用户的行为和偏好中发现规律,并基于此进行推荐,所以收集用户的偏好信息成为系统推荐效果最基础的决定因素。
数据预处理:
1.减噪
因为用户数据在使用过程中可能存在大量噪声和误操作,所以需要过滤掉这些噪声。
2.归一化
不同行为数据的差别比较大,通过归一化,数据归于大致均衡,计算时才能减少异常数据产生的影响。
组合不同用户行为方式:
1.将不同的行为分组
2.对不同行为进行加权
四.相似度计算
对用户的行为分析得到用户的偏好后,可以根据用户的偏好计算相似用户和物品,然后可以基于相似用户或相似物品进行推荐。我们可以将用户对所有物品的偏好作为一个矩阵来计算用户之间的相似度,或者将所有用户对物品的偏好作为一个矩阵来计算物品之间的相似度。
1.同现相似度
指在喜爱物品A的前提下,喜爱物品B的概率。当物品B喜爱率较高时可以使用(A交B)/sqrt(A或B)。
2.欧式距离
1/(1+d(x,y))
备注:d(x,y) 欧式距离
3.皮尔逊相关系数
皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值为【-1~1】之间。
4.Cosine相似度【余弦相似度】
Cosine相似度广泛应用于计算文档数据的相似度。
5.Tanimoto系数
Tanimoto系数也被称为Jaccard系数,是Cosine相似度的扩展,也多用于计算文档数据的相似度。
五.代码实现
1 package big.data.analyse.ml 2 3 import _root_.breeze.numerics.sqrt 4 import org.apache.log4j.{Level, Logger} 5 import org.apache.spark.{SparkContext, SparkConf} 6 import org.apache.spark.rdd.RDD 7 8 /** 9 * 用户评分 10 * @param userid 用户 11 * @param itemid 物品 12 * @param pref 评分 13 */ 14 case class ItemPref(val userid : String,val itemid : String, val pref : Double) extends Serializable 15 16 /** 17 * 相似度 18 * @param itemid_1 物品 19 * @param itemid_2 物品 20 * @param similar 相似度 21 */ 22 case class ItemSimilar(val itemid_1 : String, val itemid_2 : String, val similar : Double) extends Serializable 23 24 /** 25 * 给用户推荐物品 26 * @param userid 用户 27 * @param itemid 物品 28 * @param pref 推荐系数 29 */ 30 case class UserRecommend(val userid : String, val itemid : String, val pref : Double) extends Serializable 31 32 /** 33 * 相似度计算 34 */ 35 class ItemSimilarity extends Serializable{ 36 def Similarity(user : RDD[ItemPref], stype : String) : RDD[ItemSimilar] = { 37 val similar = stype match{ 38 case "cooccurrence" => ItemSimilarity.CooccurenceSimilarity(user) // 同现相似度 39 //case "cosine" => // 余弦相似度 40 //case "euclidean" => // 欧式距离相似度 41 case _ => ItemSimilarity.CooccurenceSimilarity(user) 42 } 43 similar 44 } 45 } 46 47 object ItemSimilarity{ 48 def CooccurenceSimilarity(user : RDD[ItemPref]) : (RDD[ItemSimilar]) = { 49 val user_1 = user.map(r => (r.userid, r.itemid, r.pref)).map(r => (r._1, r._2)) 50 /** 51 * 内连接,默认根据第一个相同字段为连接条件,物品与物品的组合 52 */ 53 val user_2 = user_1.join(user_1) 54 55 /** 56 * 统计 57 */ 58 val user_3 = user_2.map(r => (r._2, 1)).reduceByKey(_+_) 59 60 /** 61 * 对角矩阵 62 */ 63 val user_4 = user_3.filter(r => r._1._1 == r._1._2) 64 65 /** 66 * 非对角矩阵 67 */ 68 val user_5 = user_3.filter(r => r._1._1 != r._1._2) 69 70 /** 71 * 计算相似度 72 */ 73 val user_6 = user_5.map(r => (r._1._1, (r._1._1,r._1._2,r._2))) 74 .join(user_4.map(r => (r._1._1, r._2))) 75 76 val user_7 = user_6.map(r => (r._2._1._2, (r._2._1._1, r._2._1._2, r._2._1._3, r._2._2))) 77 .join(user_4.map(r => (r._1._1, r._2))) 78 79 val user_8 = user_7.map(r => (r._2._1._1, r._2._1._2, r._2._1._3, r._2._1._4, r._2._2)) 80 .map(r => (r._1, r._2, (r._3 / sqrt(r._4 * r._5)))) 81 82 user_8.map(r => ItemSimilar(r._1, r._2, r._3)) 83 } 84 } 85 86 class RecommendItem{ 87 def Recommend(items : RDD[ItemSimilar], users : RDD[ItemPref], number : Int) : RDD[UserRecommend] = { 88 val items_1 = items.map(r => (r.itemid_1, r.itemid_2, r.similar)) 89 val users_1 = users.map(r => (r.userid, r.itemid, r.pref)) 90 91 /** 92 * i行与j列join 93 */ 94 val items_2 = items_1.map(r => (r._1, (r._2, r._3))).join(users_1.map(r => (r._2, (r._1, r._3)))) 95 96 /** 97 * i行与j列相乘 98 */ 99 val items_3 = items_2.map(r => ((r._2._2._1, r._2._1._1), r._2._2._2 * r._2._1._2)) 100 101 /** 102 * 累加求和 103 */ 104 val items_4 = items_3.reduceByKey(_+_) 105 106 /** 107 * 过滤已存在的物品 108 */ 109 val items_5 = items_4.leftOuterJoin(users_1.map(r => ((r._1, r._2), 1))).filter(r => r._2._2.isEmpty) 110 .map(r => (r._1._1, (r._1._2, r._2._1))) 111 112 /** 113 * 分组 114 */ 115 val items_6 = items_5.groupByKey() 116 117 val items_7 = items_6.map(r => { 118 val i_2 = r._2.toBuffer 119 val i_2_2 = i_2.sortBy(_._2) 120 if(i_2_2.length > number){ 121 i_2_2.remove(0, (i_2_2.length - number)) 122 } 123 (r._1, i_2_2.toIterable) 124 }) 125 126 val items_8 = items_7.flatMap(r => { 127 val i_2 = r._2 128 for(v <- i_2) yield (r._1, v._1, v._2) 129 }) 130 131 items_8.map(r => UserRecommend(r._1, r._2, r._3)) 132 } 133 } 134 135 /** 136 * Created by zhen on 2019/8/9. 137 */ 138 object ItemCF { 139 def main(args: Array[String]) { 140 val conf = new SparkConf() 141 conf.setAppName("ItemCF") 142 conf.setMaster("local[2]") 143 144 val sc = new SparkContext(conf) 145 146 /** 147 * 设置日志级别 148 */ 149 Logger.getRootLogger.setLevel(Level.WARN) 150 151 val array = Array("1,1,0", "1,2,1", "1,4,1", "2,1,0", "2,3,1", "2,4,0", "3,1,0", "3,2,1", "4,1,0", "4,3,1") 152 val cf = sc.parallelize(array) 153 154 val user_data = cf.map(_.split(",")).map(r => (ItemPref(r(0), r(1), r(2).toDouble))) 155 156 /** 157 * 建立模型 158 */ 159 val mySimilarity = new ItemSimilarity() 160 val similarity = mySimilarity.Similarity(user_data, "cooccurrence") 161 162 val recommend = new RecommendItem() 163 val recommend_rdd = recommend.Recommend(similarity, user_data, 30) 164 165 /** 166 * 打印结果 167 */ 168 println("物品相似度矩阵:" + similarity.count()) 169 similarity.collect().foreach(record => { 170 println(record.itemid_1 +","+ record.itemid_2 +","+ record.similar) 171 }) 172 173 println("用户推荐列表:" + recommend_rdd.count()) 174 recommend_rdd.collect().foreach(record => { 175 println(record.userid +","+ record.itemid +","+ record.pref) 176 }) 177 } 178 }
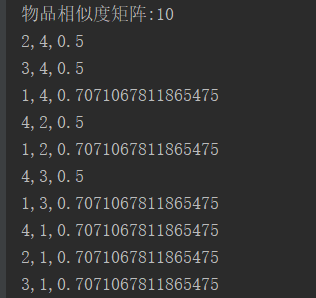
六.结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号