Spark完全分布式集群搭建【Spark2.4.4+Hadoop3.2.1】
一.安装Linux
需要:3台CentOS7虚拟机

注意:
虚拟机的网络设置为NAT模式,NAT模式可以在断网的情况下连接上虚拟机而桥架模式不行!
二.设置静态IP
跳转目录到:

修改IP设置:
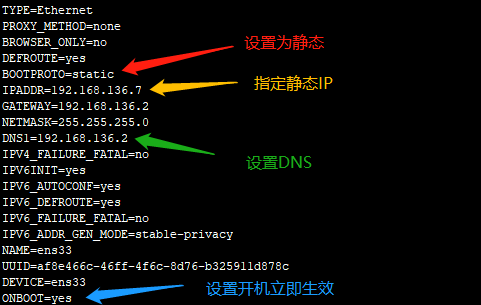
备注:执行scp命令拷贝设置文件到另外两个节点,修改IP分别为192.168.136.8和192.168.136.9
三.安装JDK
参考我的博客:https://www.cnblogs.com/yszd/p/10140327.html
四.运行Spark预编译包中的实例
1.测试Scala代码实例
执行:
运行Scala版本计算Pi的代码实例结果:
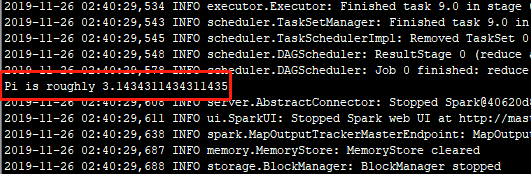
表示运行成功!
2.测试python代码实例
执行:

运行python版本计算Pi的代码实例,注意,若要是遇到下面的异常:
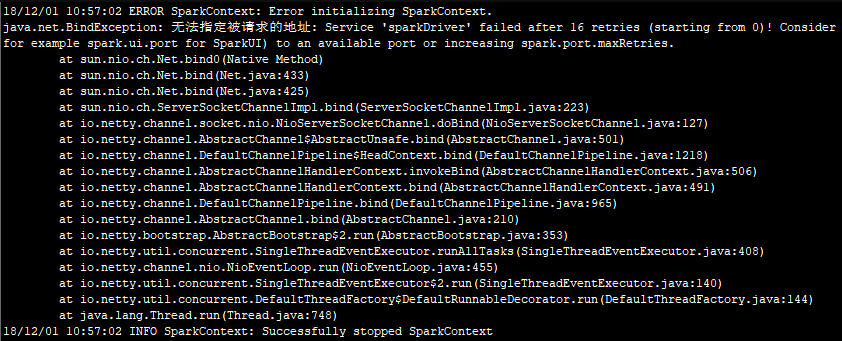
表示没有指定ip,这是需要修改配置文件spark-env.sh,前往conf目录下执行

拷贝配置模板文件,并修改为spark-env.sh,执行

打开配置文件,添加,指定默认ip。

然后继续执行计算Pi代码命令:

结果如下:
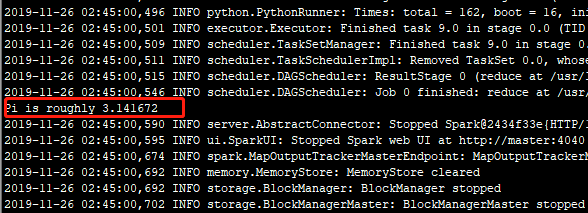
表示执行成功!
五.本地体验Spark
1.执行命令进入Spark交互模式

2.编写简单代码实例
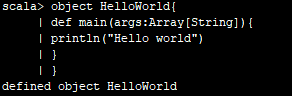
执行结果:

六.免密码登录
参考我的博客:https://www.cnblogs.com/yszd/p/10123911.html
备注:如果是使用root或高权限的账号操作的,那么authorized_keys文件本身权限就够,无需追加权限,否则可以使用chmod添加权限。另外,各个节点首次访问时需要输入密码!
七.Zookeeper集群部署
1.上传zookeeper到集群的各个节点

2.修改配置,指定datadir和集群节点配置
initLimit=10 syncLimit=5 dataDir=/hadoop/zookeeper dataLogDir=/usr/local/soft/zookeeper-3.4.12/log clientPort=2181 #maxClientCnxns=60 server.1 = master:2888:3888 server.2 = slave01:2888:3888 server.3 = slave02:2888:3888
3.配置myid

注意:内容为上面server.x中的x
4.启动zookeeper节点,查看节点运行状态
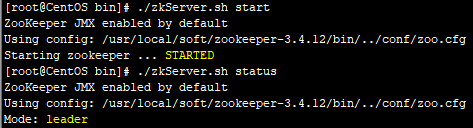

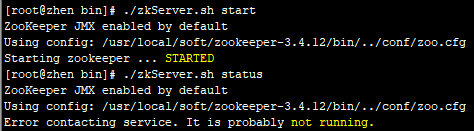
注意:节点zhen启动异常,查看zoo.cfg配置是否正确及防火墙是否已经关闭,确定无误后等待zookeeper自启!
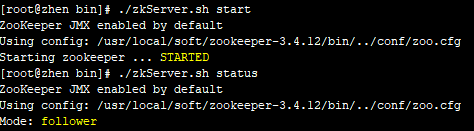
异常节点zhen启动成功,zookeeper集群搭建完成!
八.Spark Standalone集群搭建
安装scala环境
下载地址:https://www.scala-lang.org/download/2.11.12.html
下拉到最下面,选择scala-2.11.12.rpm使用rpm安装:
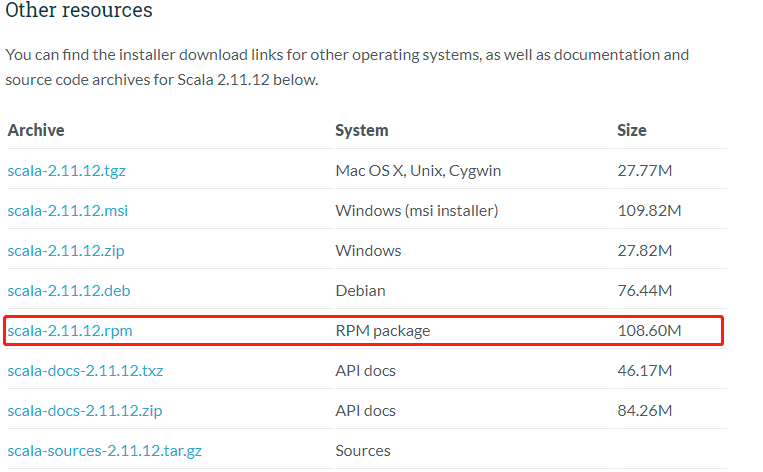
上传到集群:
执行命令:rpm -ivh scala-2.11.12.rpm安装scala环境,输入scala -version检测是否安装成功

表示安装成功!
配置环境变量,编辑etc/profile,添加:

九.Hadoop3.2.1完全分布式搭建
1.下载文件
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
2.上传并解压Hadoop文件

3.修改相应配置文件
3.1 etc/profile:

3.2 HADOOP_HOME/etc/hadoop/hadoop-env.sh

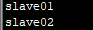
3.3 HADOOP_HOME/etc/hadoop/slaves,注意:在Hadoop3.1之后,slaves改为workers
3.4 HADOOP_HOME/etc/hadoop/core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/soft/hadoop-3.2.1/tmp</value> </property> </configuration>
3.5 HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/soft/hadoop-3.2.1/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/soft/hadoop-3.2.1/hdfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> </configuration>
3.6 HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
注意:在Hadoop3.1之后,为了避免在执行任务时报一下错误:
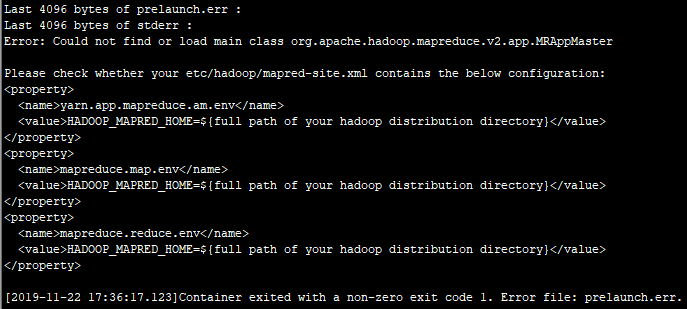
要额外添加一下配置(也就是上面报错信息提到的配置):
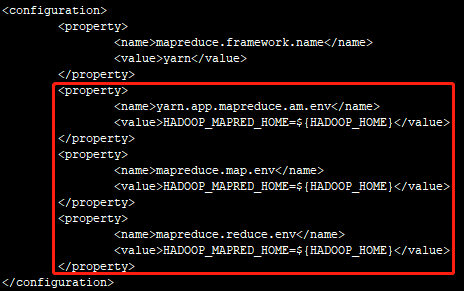
3.7 HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
3.8 格式化Hadoop
执行:hdfs namenode -format
4.拷贝Hadoop到Worker节点
执行命令:scp -r /usr/local/soft/hadoop-3.2.1 root@worker1:/usr/local/soft
执行命令:scp -r /usr/local/soft/hadoop-3.2.1 root@worker2:/usr/local/soft
5.在浏览器上输入:master:50070查看,注意:在Hadoop3.1之后,端口修改为9870
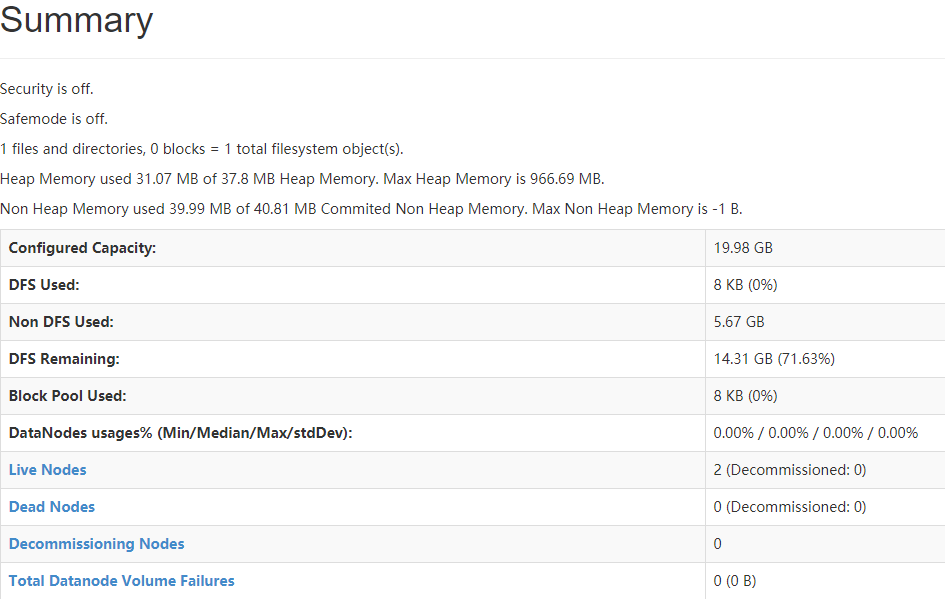
表示安装成功!
十.Spark-2.4.4完全分布式搭建
1.下载安装文件
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
2.上传并解压安装文件

3.修改相应的配置文件
3.1 etc/profile

3.2 SPARK_HOME/conf/spark-env.sh
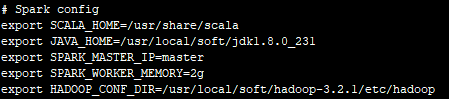
3.3 SPARK_HOME/conf/slaves
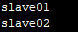
十一.编辑集群的脚本
1.启动脚本
#!/bin/bash echo -e "=========================Start spark cluster==================================" echo -e "Starting Hadoop..." /usr/local/soft/hadoop-3.2.1/sbin/start-all.sh echo -e "Starting Spark..." /usr/local/soft/spark-2.4.4-bin-hadoop2.7/sbin/start-all.sh echo -e "The Result of the Command \"jps\"" jps echo -e "=================================End=========================================="
注意:如果jps没有namenode,则说明namenode元数据损坏,这时需要前往bin目录下,执行:hadoop namenode -format重建一下
2.关闭脚本
#!/bin/bash echo -e "=========================Stop spark cluster==================================" echo -e "Stoping Hadoop..." /usr/local/soft/hadoop-3.2.1/sbin/stop-all.sh echo -e "Stoping Spark..." /usr/local/soft/spark-2.4.4-bin-hadoop2.7/sbin/stop-all.sh echo -e "The Result of the Command \"jps\"" jps echo -e "=================================End=========================================="
十二.测试
1.测试Hadoop
1.1 创建测试文件

1.2 编辑内容
spark scala hadoop spark hadoop java redis hbase hive kafka flume
1.3 创建Hadoop文件夹,用于保存测试文件
hadoop fs -mkdir -p /hadoop/data
1.4 把创建好的测试文件导入到Hadoop中
hadoop fs -put /wordcount.txt /hadoop/data/
1.5 运行程序
hadoop jar /usr/local/soft/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /hadoop/data /hadoop/output
1.6 执行结果

2.测试Spark
执行Spark提交命令:./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.4.4.jar 1000
部分执行日志:

执行结果:
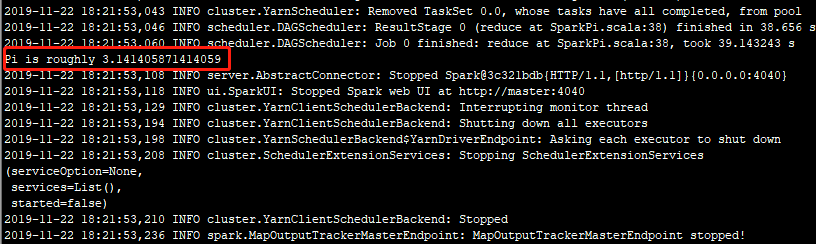
完成!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号