时空大数据至少带有三个信息:用户id,时间,空间
一、出租车OD提取
1、读取数据
csv格式:Excel最多支持104万行,如果超过这个打开Excel再保存,就会丢失数据。
import pandas as pd #读取数据 data = pd.read_csv(r'data-sample/TaxiData-Sample',header = None) #给数据命名列 data.columns = ['VehicleNum', 'Stime', 'Lng', 'Lat', 'OpenStatus', 'Speed']
① pd.read_csv()
路径名字符串前要加r。
header=None表示原始文件没有列索引,自动加上列索引0,1,2...,如果不加header,就会把第0行变成列名。
header=0表示第0行作为列索引。
可以通过name属性指定新的索引名字,如names=range(2,4)。
② data.columns
data.index返回一个index类型的行索引列表
data.columns返回一个index类型的列索引列表
#显示数据的前5行 data.head(5)
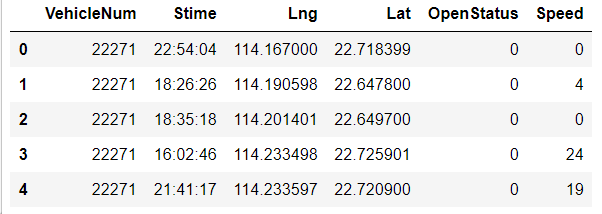
VehicleNum —— 车牌
Stime —— 时间
Lng —— 经度
Lat —— 纬度
OpenStatus —— 是否有乘客(0没乘客,1有乘客)
Speed —— 速度
type(data) type(data['Lng']) type(data[['Lng']])
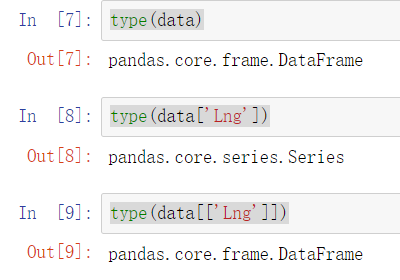
当我们读一个数据的时候,我们读进来的就是DataFrame格式的数据表,而一个DataFrame中的每一列,则为一个Series也就是说,DataFrame由多个Series组成。
如果我们想取DataFrame的某一列,想得到的是Series:data[列名]
如果我们想取DataFrame的某一列或者某几列,想得到的是DataFrame:data2[[列名,列名]]
2、筛选数据
在筛选数据的时候,我们一般用data[条件]的格式,其中的条件,是对data每一行数据的true和false布尔变量的Series
data['VehicleNum'] == 22271
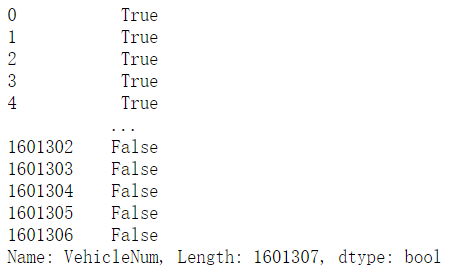
得到一个Series,可以作为筛选条件。
data[data['VehicleNum'] == 22271]

想要去掉所筛选的数据,有两种方法
data[data['VehicleNum'] != 22271]
data[-(data['VehicleNum'] == 22271)]
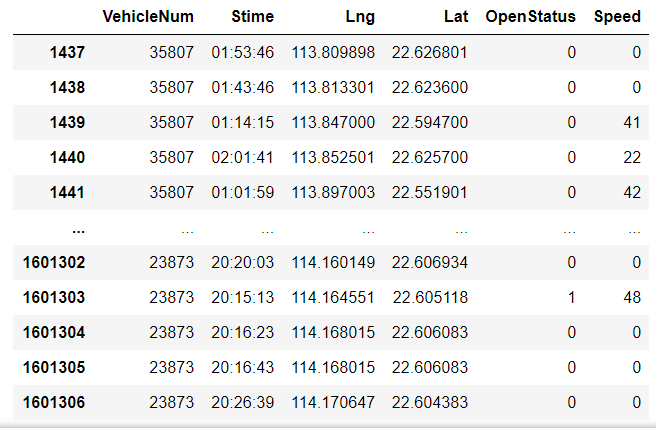
data[-(条件)]
data2 = data[(data['VehicleNum']==22271)|(data['VehicleNum']==23873)] data2
data2['Speed2'] = data2['Speed']*2 data2.loc[4] # 取某一行,以行前面的index来取(这个第一列索引号不是数据里的,是自动加的)
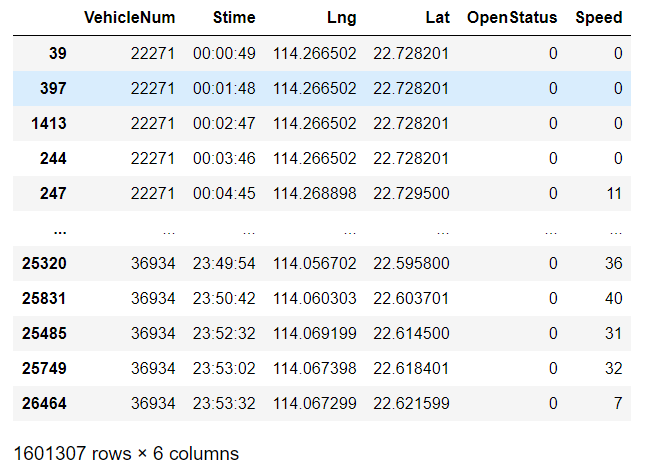
data2.iloc[1000] # 以绝对位置来取(就是从上往下数第1000行,一般用这个)
iloc是按照行数取值,而loc按着index名取值
在获取某行某列的数据时,记得一定要用iloc(按表目前排列的顺序取),不能用loc(按index取)
因为很多时候我们做完筛选、排序等操作,表就不是按index来排列,用loc取行就会取错行,或者直接报错。
#获取Stime列的第4行数据 data['Stime'].iloc[3]
3、删除某列
data2 = data2.drop(['Speed2'],axis=1) # 不指定axis默认是0/行,指定1/列就可以删除Speed2列 data2
4、排序与数据清洗
将数据按车牌、时间排序:
data = data.sort_values(by = ['VehicleNum','Stime']) data
正常的openstatus:
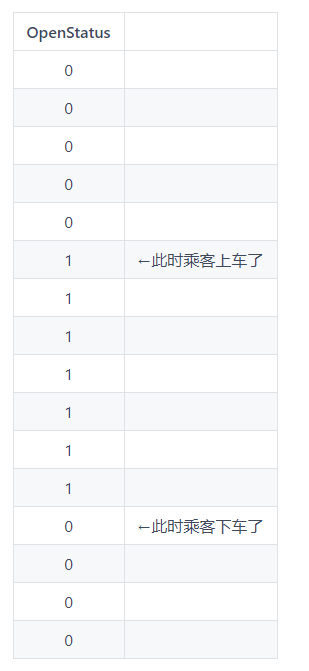
异常的openstatus:
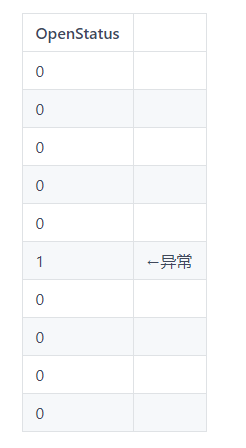
异常点的前一位和后一位相等,但前后位均与该点不相等。
把一列的值向上/向下移一位:
data2 = data.iloc[2460:2480] data2['OpenStatus'].shift(1) data2['OpenStatus'].shift(-1)
异常数据清洗思路:
前一位等于后一位&后一位不等于中间位&前中后的车牌号相等
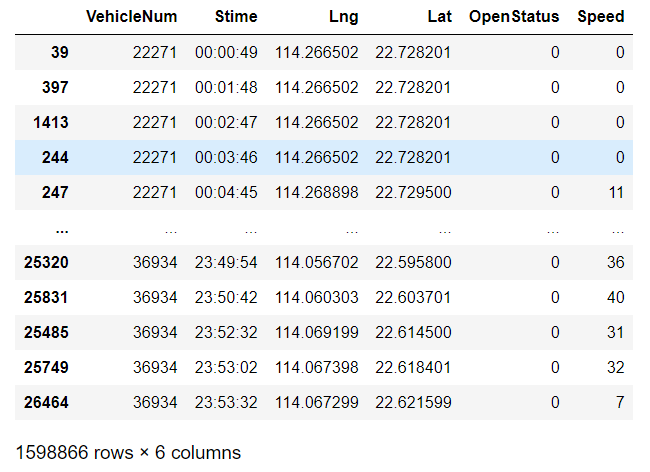
data = data[-(((data['OpenStatus'].shift(-1))==data['OpenStatus'].shift())& (data['OpenStatus'].shift(-1)!=(data['OpenStatus']))& (data['VehicleNum'].shift(-1)==data['VehicleNum'].shift())& (data['VehicleNum'].shift(-1)==data['VehicleNum']))] data
删除了所有的异常数据:
5、乘客上下车状态变化识别
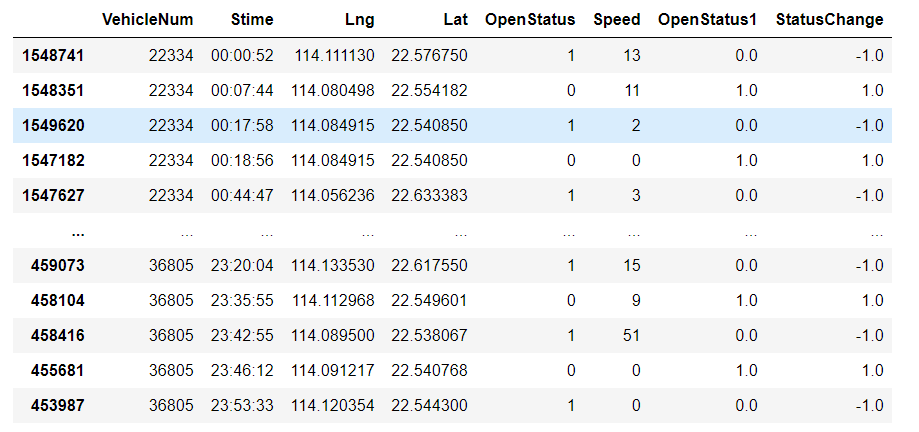
在字段名后加个1,代表后面一条数据的值
另外我们定义StatusChange为下一条数据的OpenStatus减去这一条数据的OpenStatus

乘客上车和下车都有两条数据,一般我们认为这两条数据的位置和时间非常接近,都可以认为是下车或者上车的地点
索引出StatusChange是1或-1的字段,并且要保证同一辆车的上下车成对出现。
data[((data['StatusChange']==1)|(data['StatusChange']==-1))&(data['VehicleNum']==data['VehicleNum'].shift(-1))]
oddata = oddata[['VehicleNum','Stime','Lng','Lat','StatusChange']] # 只留下需要的列 oddata.columns = ['VehicleNum','Stime','SLng','SLat','StatusChange'] # 改一下列名 oddata['ELng'] = oddata['SLng'].shift(-1) # 增加结束的经纬度和时间 oddata['ELat'] = oddata['SLat'].shift(-1) oddata['Etime'] = oddata['Stime'].shift(-1) oddata
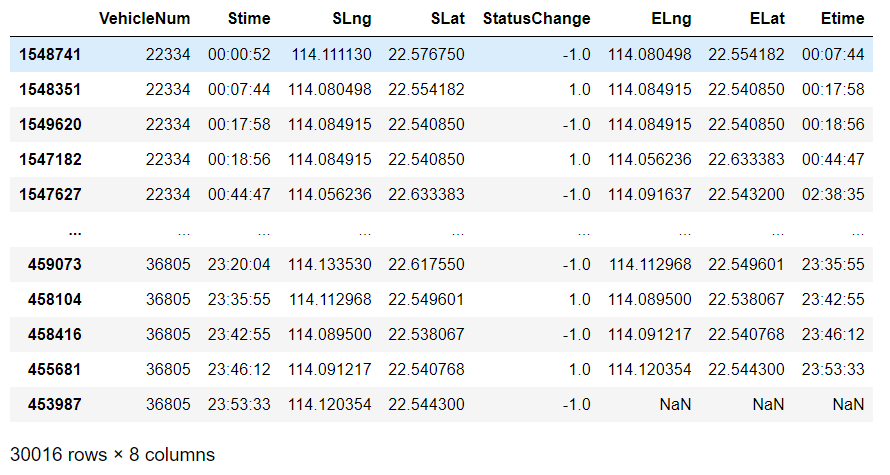
# 先筛选出状态为1的,同时要保证是同一辆车,然后再删除状态列 oddata = oddata[(oddata['StatusChange']==1)&(oddata['VehicleNum']==oddata['VehicleNum'].shift(-1))].drop('StatusChange',axis=1) oddata
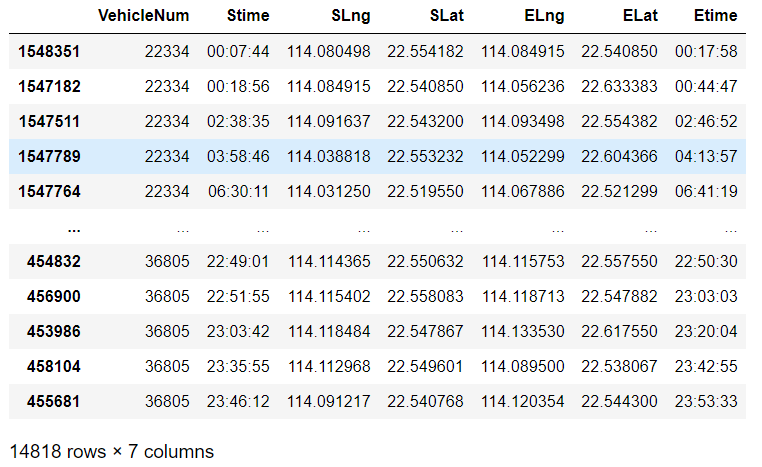
6、保存数据
# 不加索引列index=None # 编码一般用utf-8,中文gbk # utf-8要加上_sig,相当于在文件头加上识别标志,防止Excel打开是乱码 oddata.to_csv(r'oddata.csv',index=None,encoding='utf-8_sig')
二、出租车数据的集计与基础图表绘制
1、读取数据
import pandas as pd data = pd.read_csv(r'data-sample/TaxiData-Sample',header=None) data.columns = ['VehicleNum','Stime','Lng','Lat','OpenStatus','Speed'] data.head(5)
TaxiOD = pd.read_csv(r'data-sample/TaxiOD.csv') TaxiOD.columns = ['VehicleNum','Stime','SLng','SLat','ELng','ELat','Etime'] TaxiOD.head(5)
2、字符串提取
(1)把时间当成字符串,用列自带的str方法,取前两位
# 是一个字符串 data['Stime'].iloc[0]
![]()
# pandas str 内置方法 slice # 提取出0-1位 data['Stime'].str.slice(0,2)
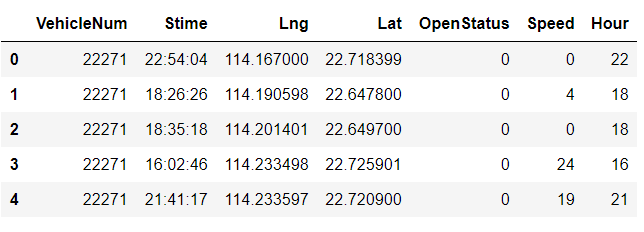
# 放到hour列 data['Hour'] = data['Stime'].str.slice(0,2) data.head(5)
(2)把时间当成字符串,遍历取字符串前两位
# apply 方法来提取 r = data['Stime'].iloc[0] def f(r): return r[:2] f(r) # 输出‘22’ data['Stime'].apply(f) # 对这一列都应用f
# 写成lamlambda表达式 data['Stime'].apply(lambda r:r[:2])
# 直接对dataframe使用apply # 效率比较低,结果一样 data.apply(lambda r:r['Stime'][:2],axis=1)
(3)转换为时间格式,后提取小时
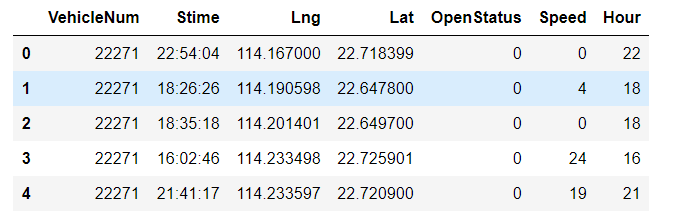
# 先转换成datetime类型,然后再取hour tmp = pd.to_datetime(data['Stime']) data['Hour'] = tmp.apply(lambda r:r.hour) # 这种方法非常的慢,但好处在于datetime类型可以直接相减算时差,而字符串做不到这一点 data.head(5)
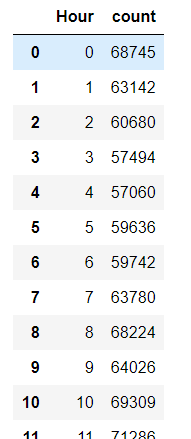
3、每小时GPS数据量计算
# 按小时groupby,然后count每一组的数量,其中只取VehicleNum一列打印,因为其他列count都一样 # data.groupby('Hour')['VehicleNum'].count() # 将这一个Series重命名为count,然后再重置index,同时把Hour作为一列加进来(#groupby的列都会变成index,所以我们用.reset_index(),将index重新变成列) hourcount = data.groupby('Hour')['VehicleNum'].count().rename('count').reset_index() hourcount
4、每小时数据量画图(matplotlib)
import matplotlib.pyplot as plt # fig可以看成一个画板,ax是画板上的一张纸(一个画板上可以有多张纸),plt想象成画笔 # figure(图像编号1,大小8*4英寸) fig = plt.figure(1,(8,4)) # 三个整数。第一个参数代表子图的行数;第二个参数代表该行图像的列数;第三个参数代表每行的第几个图像。 # 1行1列里面的第1个纸 ax = plt.subplot(111) plt.sca(ax) # 笔指向纸 # x轴,y轴的数据,画到折线图 plt.plot(hourcount['Hour'],hourcount['count']) # 图名 plt.title('Hourly Data Volumn') plt.show() # 显示的同时会清空画板
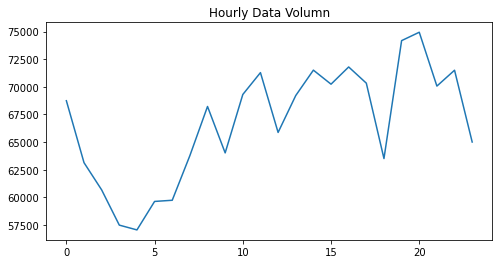
fig = plt.figure(1,(8,4),dpi=250) # 增加分辨率使图更清晰,一般学术出图300以上 ax = plt.subplot(111) plt.sca(ax) # k表示黑色,-表示实线,.表示画点 plt.plot(hourcount['Hour'],hourcount['count'],'k-',hourcount['Hour'],hourcount['count'],'k.') # 绘制条形图 plt.bar(hourcount['Hour'],hourcount['count'],width=0.5) plt.title('Hourly Data Volumn') # 小时之间实际波动没有那么大,原因是从50000多开始,这里调整y轴范围0开始到80000 plt.ylim(0,80000) # 保存必须放在show之前,否则画板会被清空 # 保存图片为svg格式,因为矢量图可以无限放大保持高清 # bbox_inches='tight',保存完的图没有白色边框,直接可以贴到论文里 plt.savefig(fname='test.svg',format='svg',bbox_inches='tight') plt.show()
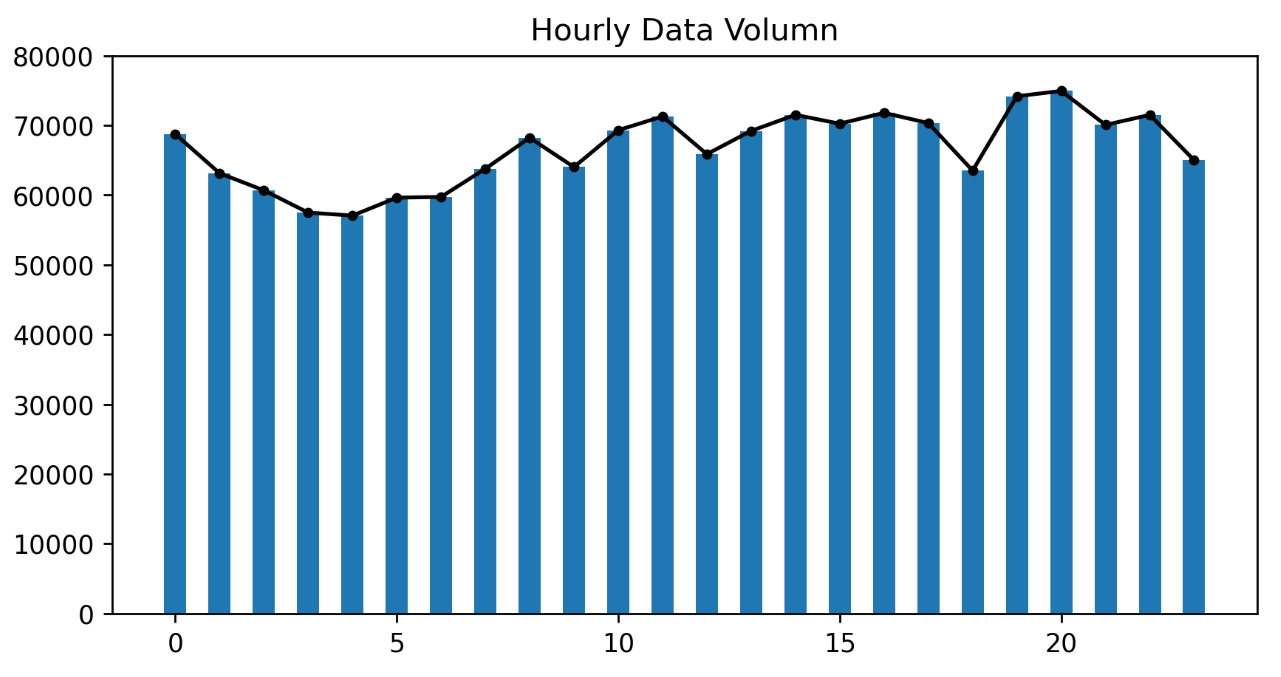
# 可以查看文档 ?plt.bar
5、每小时数据量画图(seaborn)
# 加上seaborn的主题 import seaborn as sns # darkgrid(灰色网格)whitegrid(白色网格)dark(黑色)white(白色)ticks(十字叉) sns.set_style('darkgrid',{'xtick.major.size':10,'ytick.major.size':10}) fig = plt.figure(1,(8,4),dpi=250) ax = plt.subplot(111) plt.sca(ax) plt.plot(hourcount['Hour'],hourcount['count'],'k-',hourcount['Hour'],hourcount['count'],'k.') plt.bar(hourcount['Hour'],hourcount['count'],width=0.5) plt.title('Hourly Data Volumn') plt.ylim(0,80000) plt.xlabel('Hour') plt.ylabel('Data Volumn') plt.show()
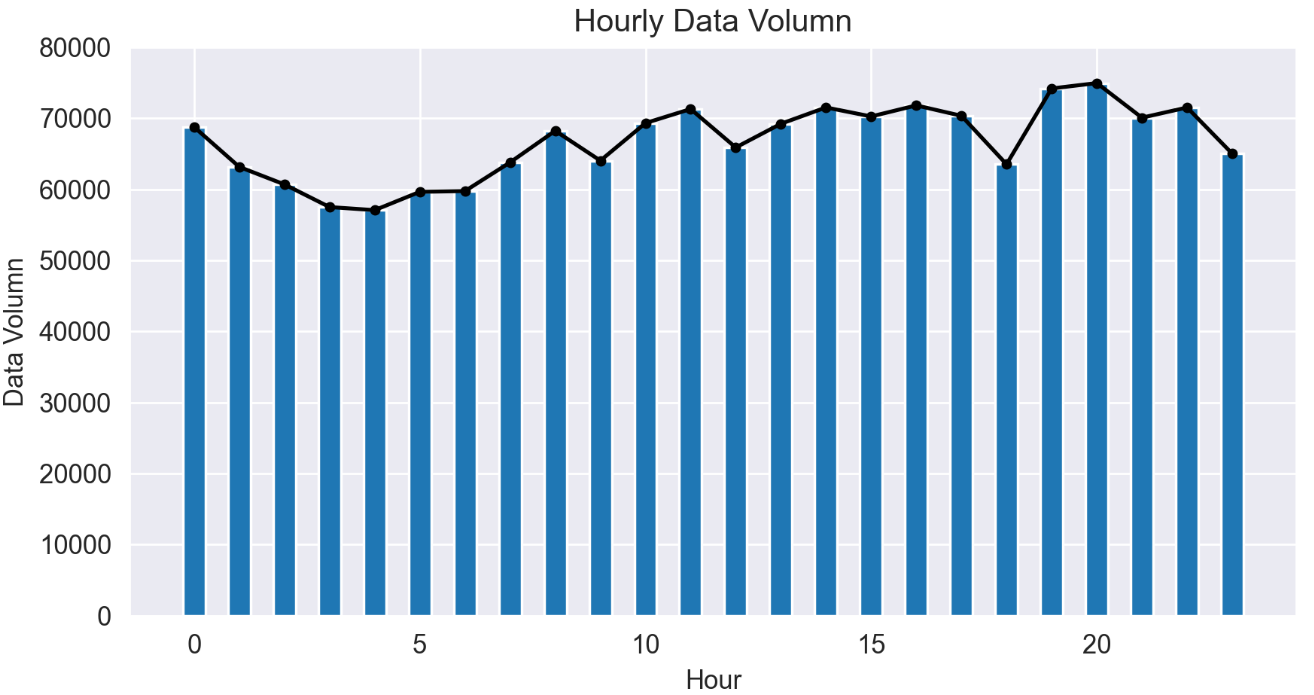
6、订单量统计
TaxiOD = pd.read_csv(r'data-sample/TaxiOD.csv') TaxiOD.columns = ['VehicleNum','Stime','SLng','SLat','ELng','ELat','Etime'] TaxiOD.head(5)
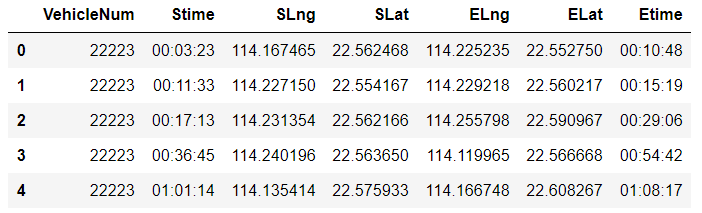
根据:来分割
TaxiOD['Hour'] = TaxiOD['Stime'].apply(lambda r:r.split(':')[0]) TaxiOD['Hour']
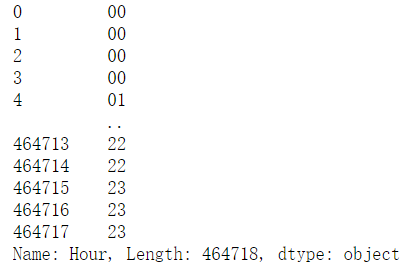
ODcount = TaxiOD.groupby('Hour')['VehicleNum'].count().rename('count').reset_index() ODcount
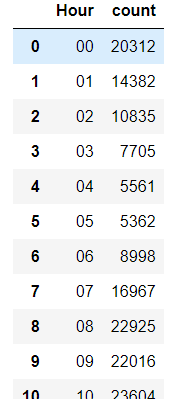
sns.set_style('darkgrid',{'xtick.major.size':10,'ytick.major.size':10}) fig = plt.figure(1,(8,4),dpi=250) ax = plt.subplot(111) plt.sca(ax) plt.plot(ODcount['Hour'],ODcount['count'],'k-',ODcount['Hour'],ODcount['count'],'k.') plt.bar(ODcount['Hour'],ODcount['count'],width=0.5) plt.title('Hourly Order Volumn') plt.ylim(0,30000) plt.show()
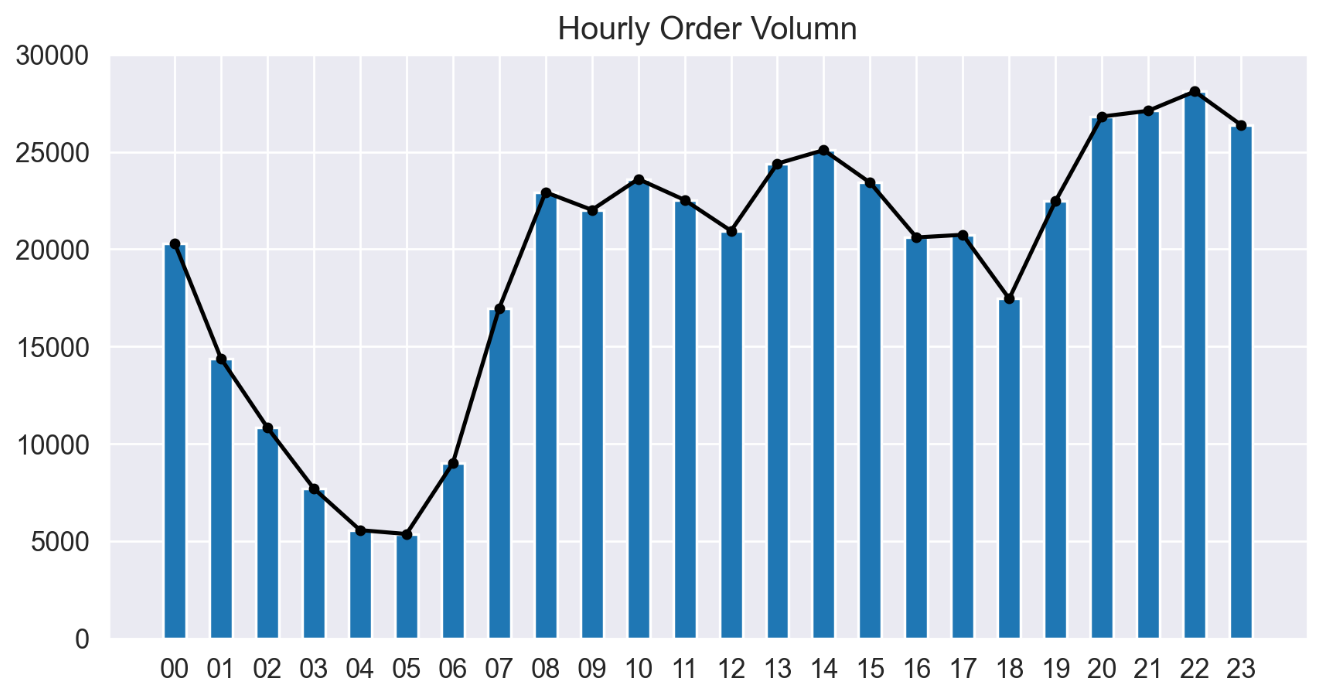
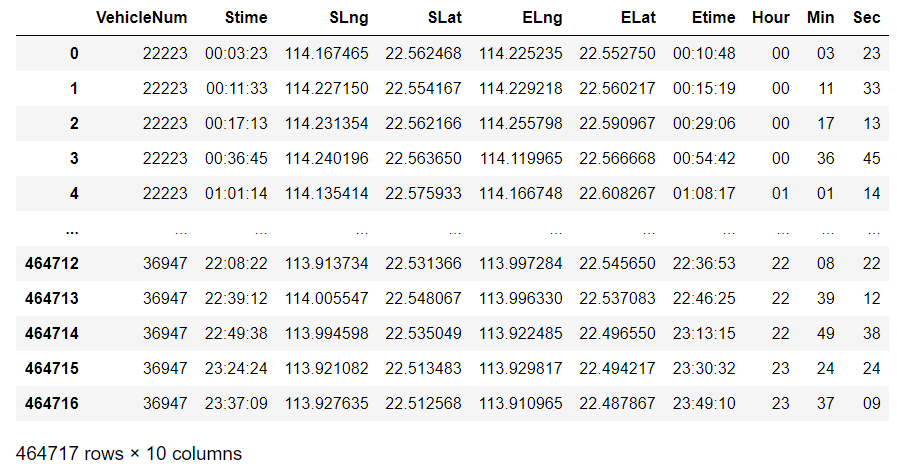
7、订单的持续时间计算
TaxiOD['Hour'] = TaxiOD['Stime'].apply(lambda r:r.split(':')[0]) TaxiOD['Min'] = TaxiOD['Stime'].apply(lambda r:r.split(':')[1]) TaxiOD['Sec'] = TaxiOD['Stime'].apply(lambda r:r.split(':')[2])
# 因为用了shift,最后一行是NaN的,需要删掉它 TaxiOD = TaxiOD[-TaxiOD['ELng'].isnull()] TaxiOD
# 方法一:计算出秒数再相减,得到Duration列 TaxiOD = TaxiOD.drop(['order_time','Duration'],axis=1) STime_st = TaxiOD['Hour'].astype('int')*3600+TaxiOD['Min'].astype('int')*60+TaxiOD['Sec'].astype('int') ETime_st = TaxiOD['Etime'].str.slice(0,2).astype('int')*3600+\ TaxiOD['Etime'].str.slice(3,5).astype('int')*60+\ TaxiOD['Etime'].str.slice(6,8).astype('int') TaxiOD['Duration'] = ETime_st - STime_st TaxiOD
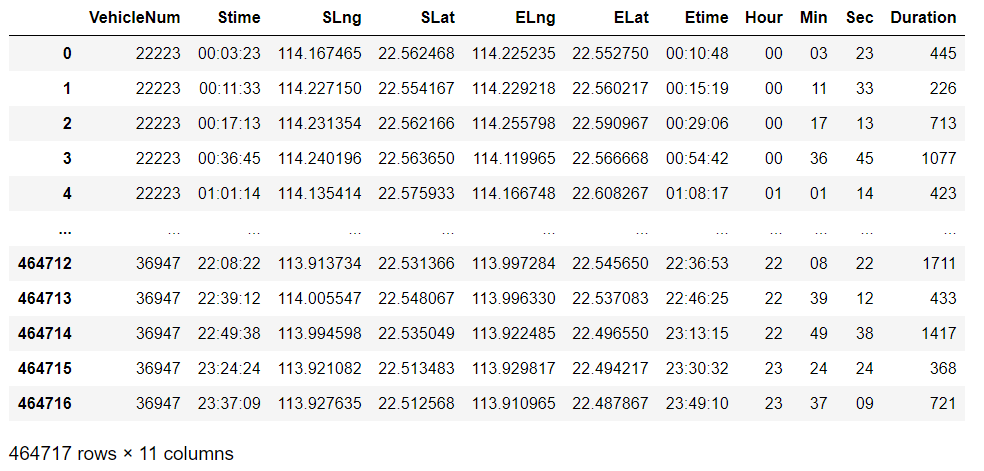
# 第二种方法:转换成datetime类型直接相减,得到order_time列 TaxiOD['order_time'] = pd.to_datetime(TaxiOD['Etime'])-pd.to_datetime(TaxiOD['Stime']) TaxiOD['order_time'].iloc[0].seconds
445
TaxiOD['order_time'] = TaxiOD['order_time'].apply(lambda r:r.seconds) TaxiOD
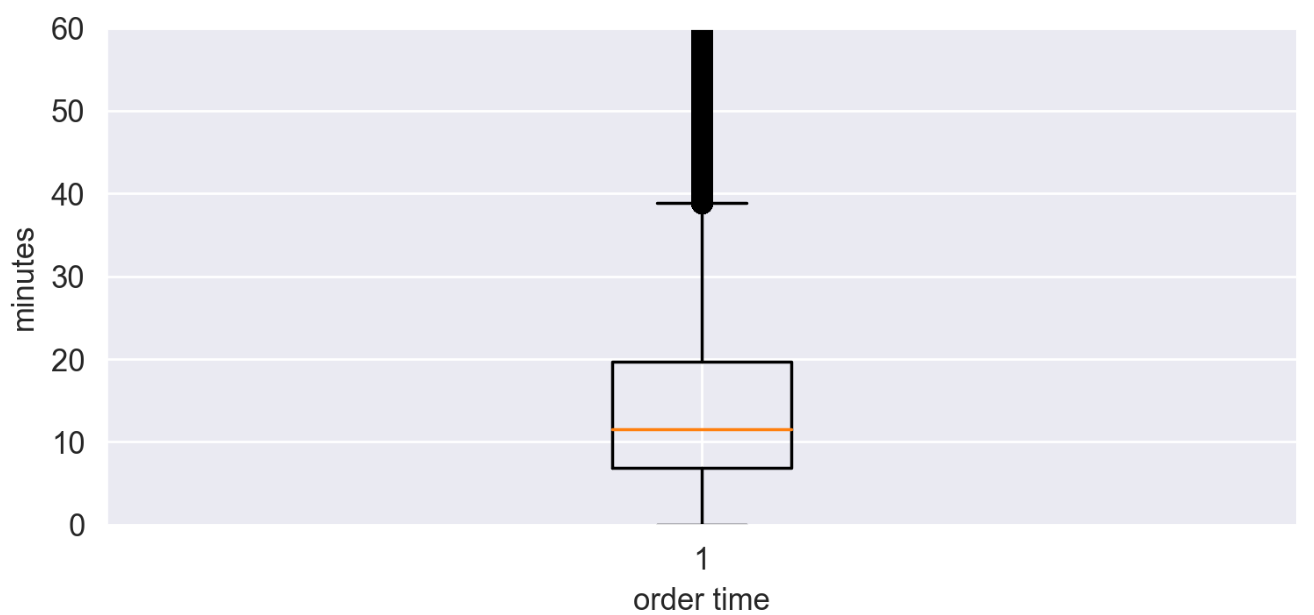
8、订单持续时间箱型图绘制
fig = plt.figure(1,(7,3),dpi=250) ax = plt.subplot(111) plt.sca(ax) # 箱型图 plt.boxplot(TaxiOD['order_time']/60) plt.ylabel('minutes') plt.xlabel('order time') plt.ylim(0,60) plt.show()
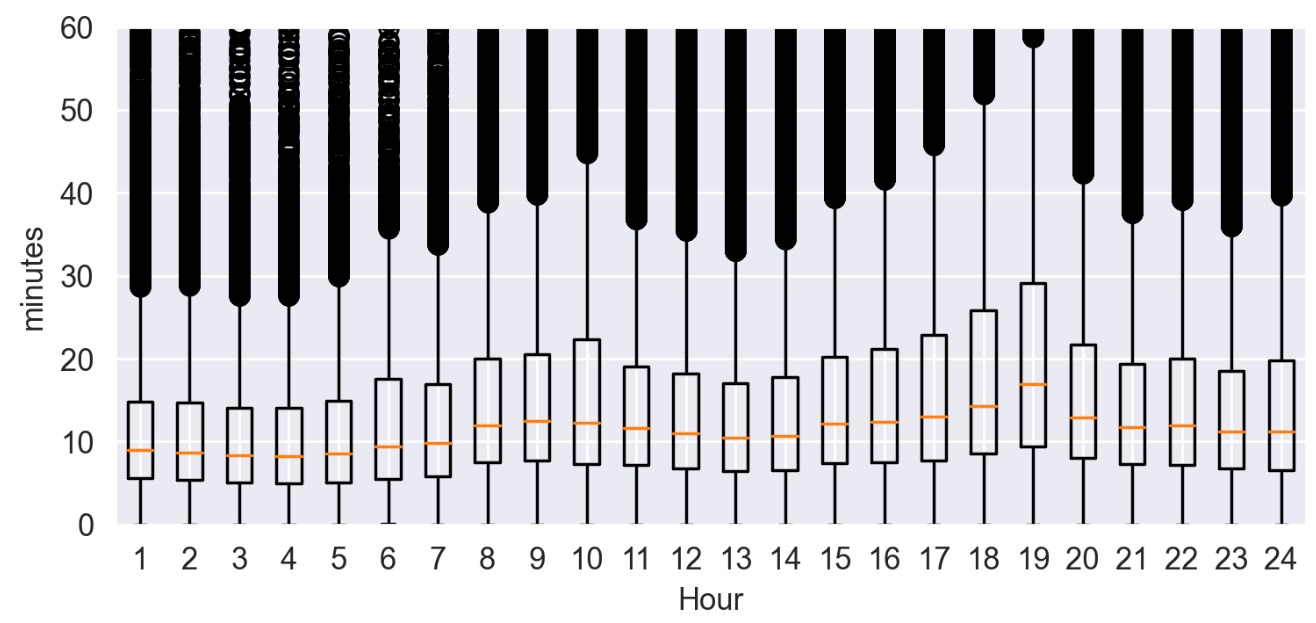
TaxiOD['Hour'] = TaxiOD['Hour'].astype('int') Datatoplot = [] for hour in range(24): Datatoplot.append(TaxiOD[TaxiOD['Hour']==hour]['order_time']/60)
fig = plt.figure(1,(7,3),dpi=250) ax = plt.subplot(111) plt.sca(ax) # 箱型图 传入一个list,list有几个元素就画几条线 plt.boxplot(Datatoplot) plt.ylabel('minutes') plt.xlabel('Hour') plt.ylim(0,60) plt.show()
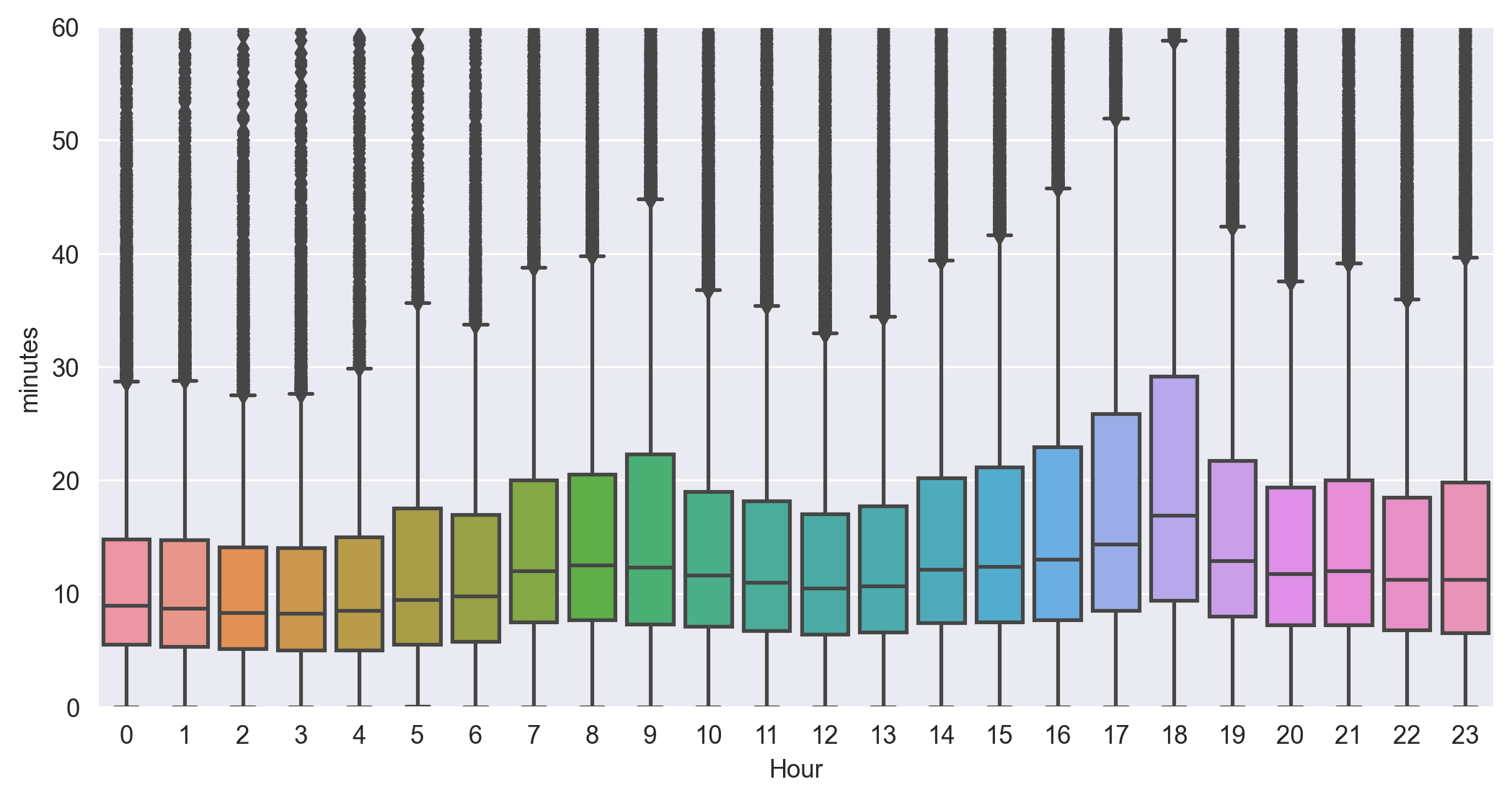
9、使用seaborn绘制箱型图
fig = plt.figure(1,(10,5),dpi=250) ax = plt.subplot(111) plt.sca(ax) # seaborn的箱型图只需一行,不需要手动计算每小时 sns.boxplot(x='Hour',y=TaxiOD['order_time']/60,data=TaxiOD,ax=ax) plt.ylabel('minutes') plt.xlabel('Hour') plt.ylim(0,60) plt.show()