
一、introduction
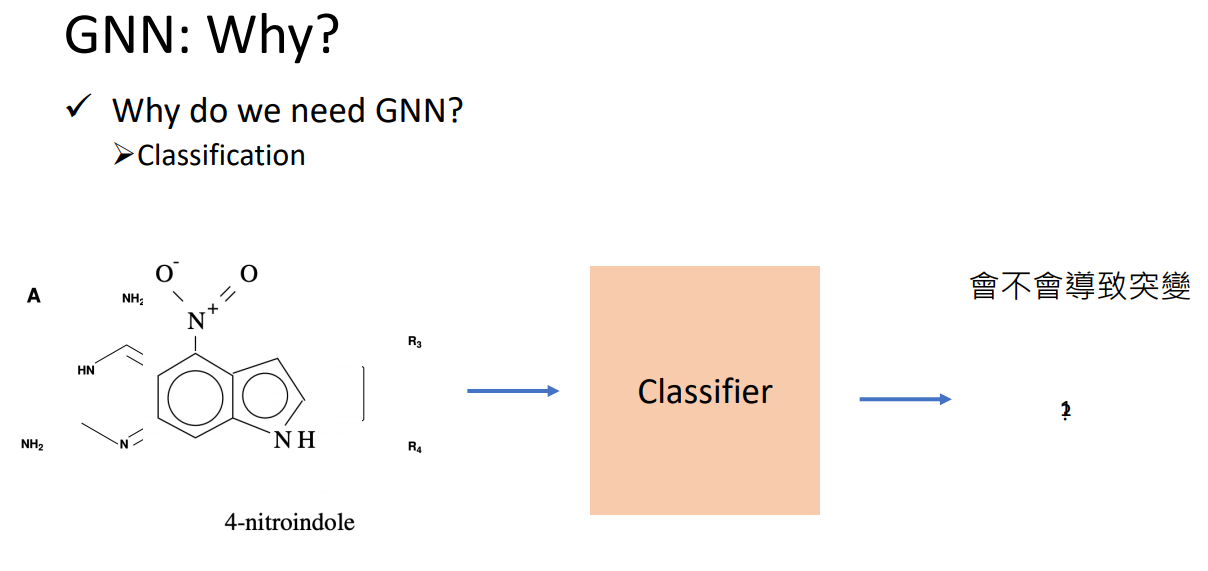
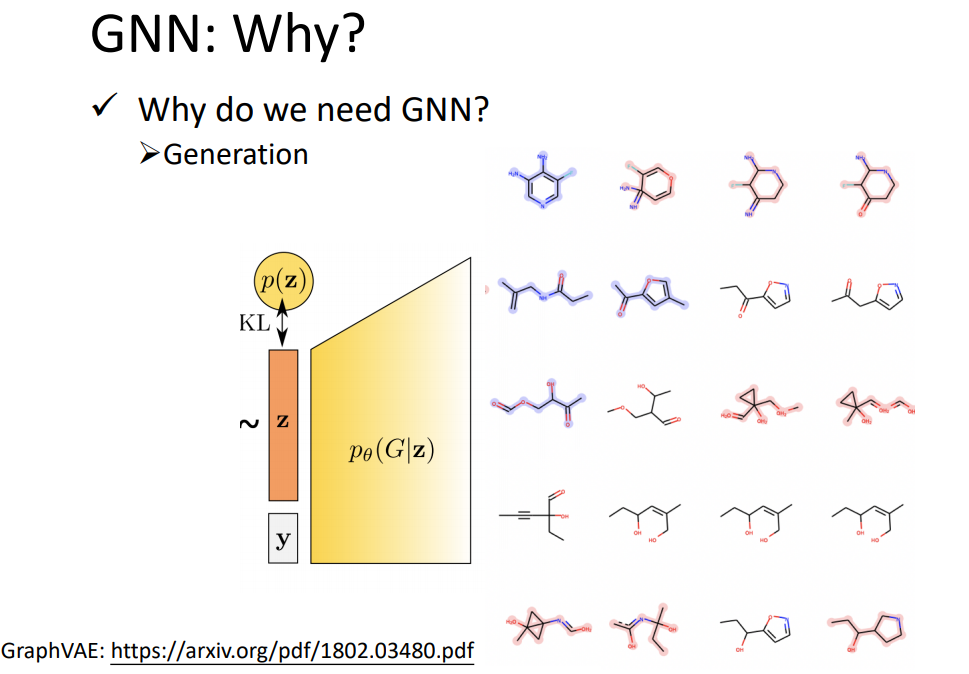


How do we utilize the structures and relationship to help our model?
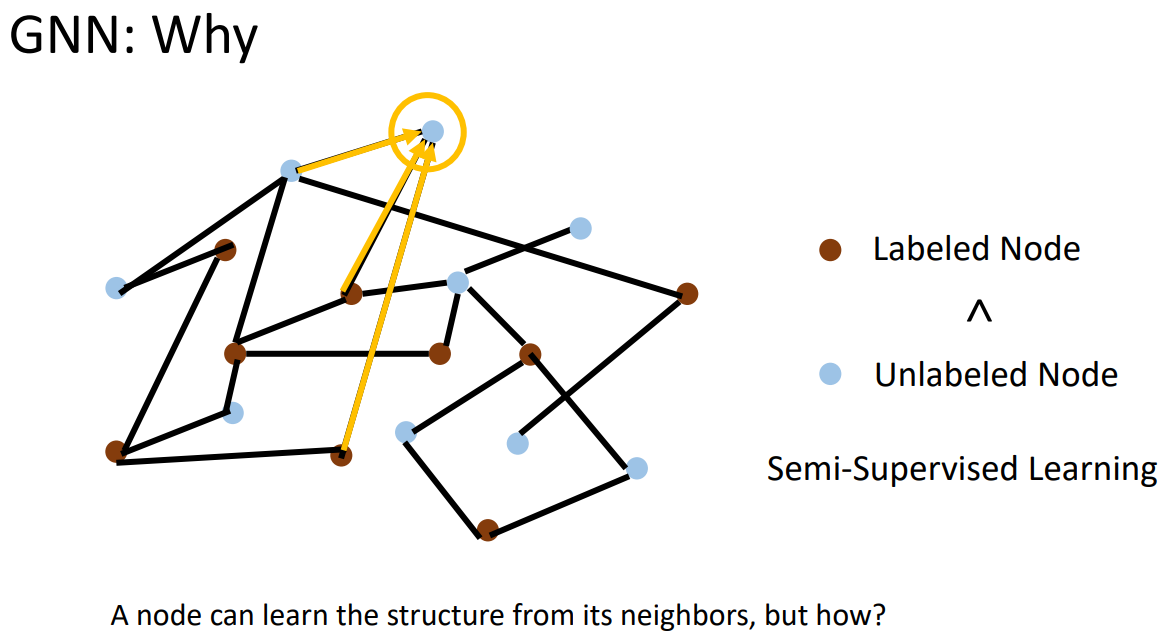
What if the graph is larger, like 20k nodes?
What if we don‘t have the all the labels?
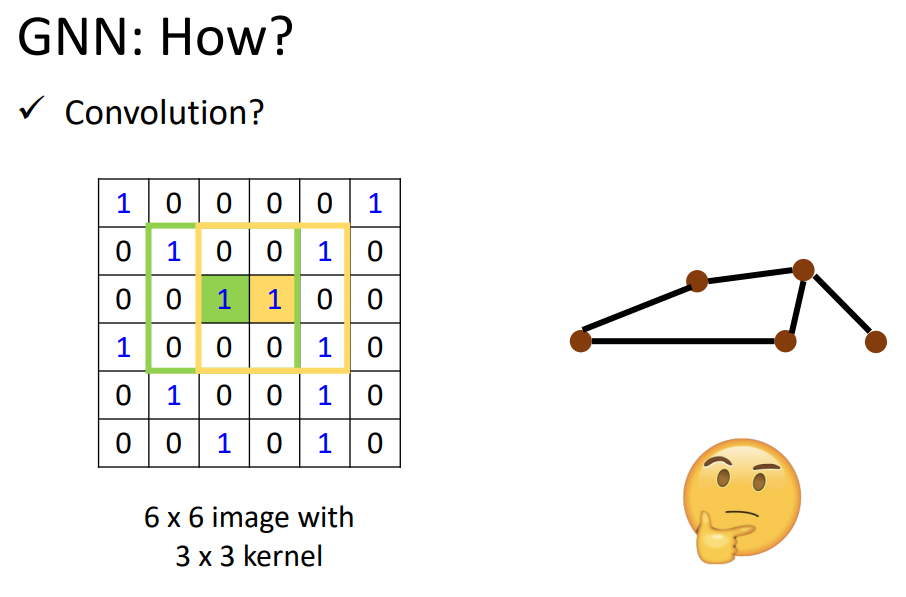

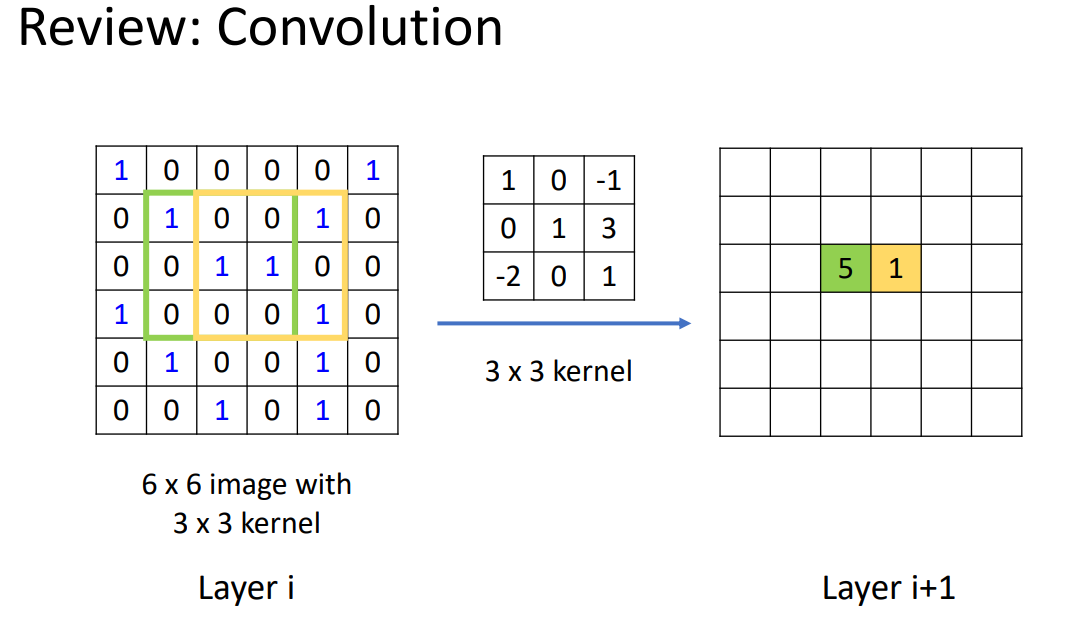
在data structure上做convolution
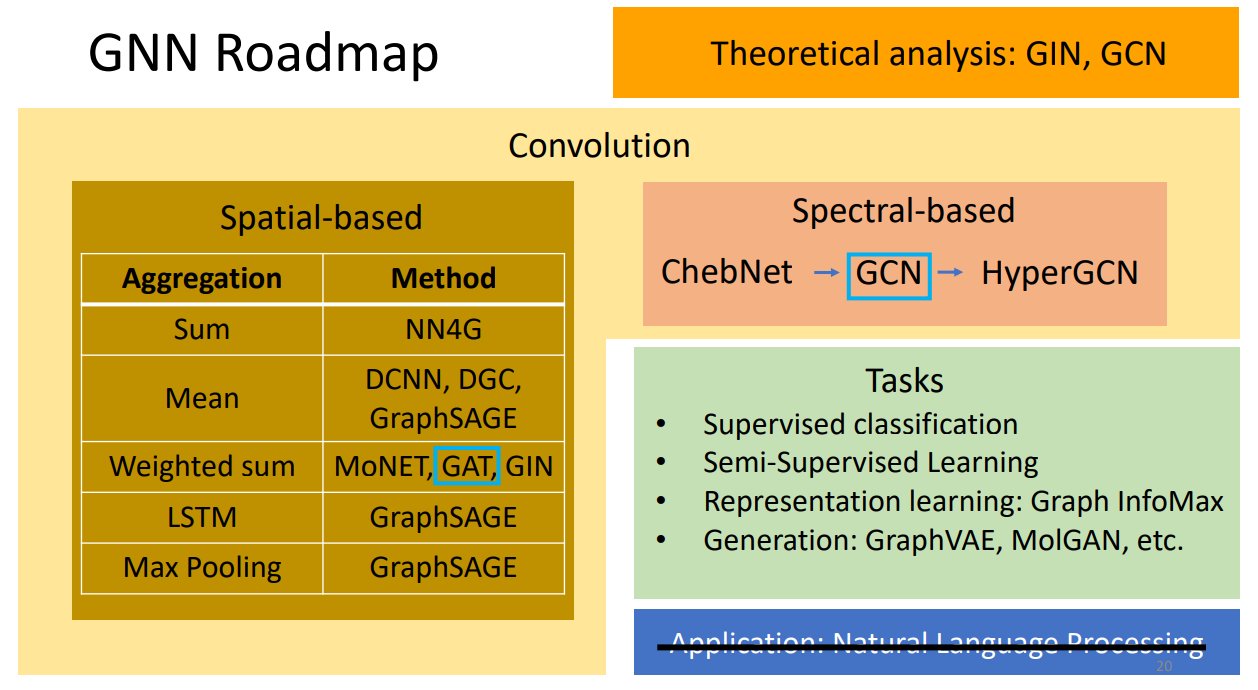

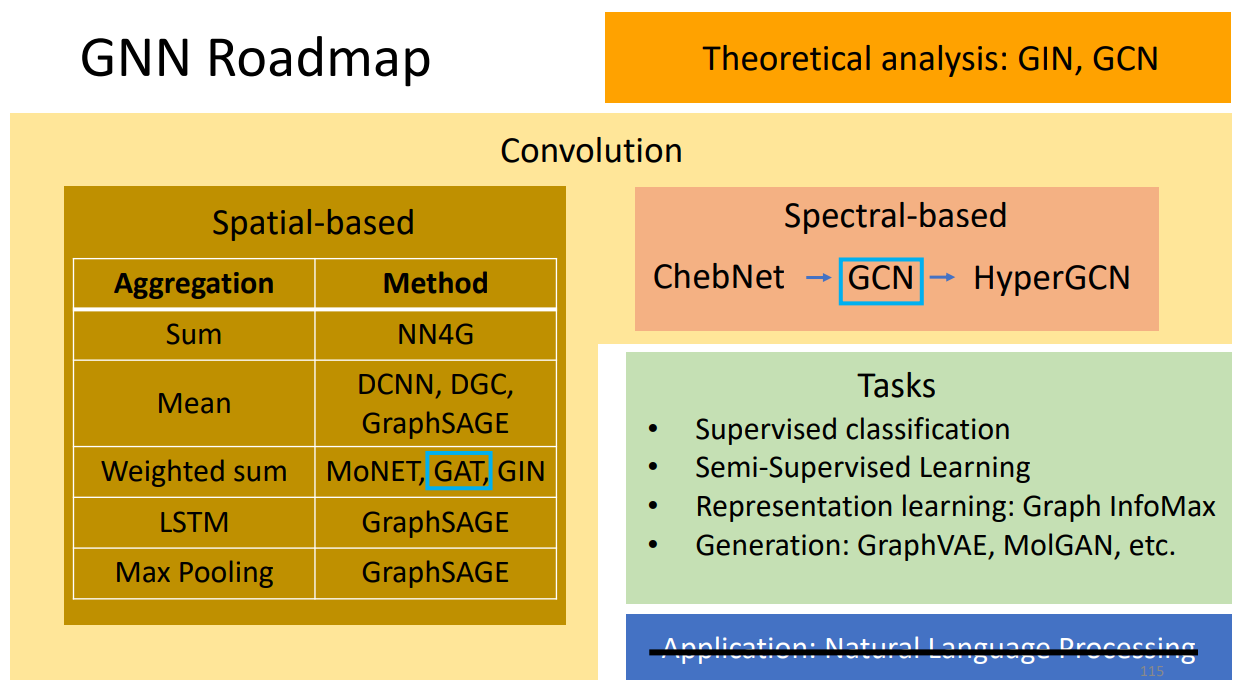
二、spatial-based GNN
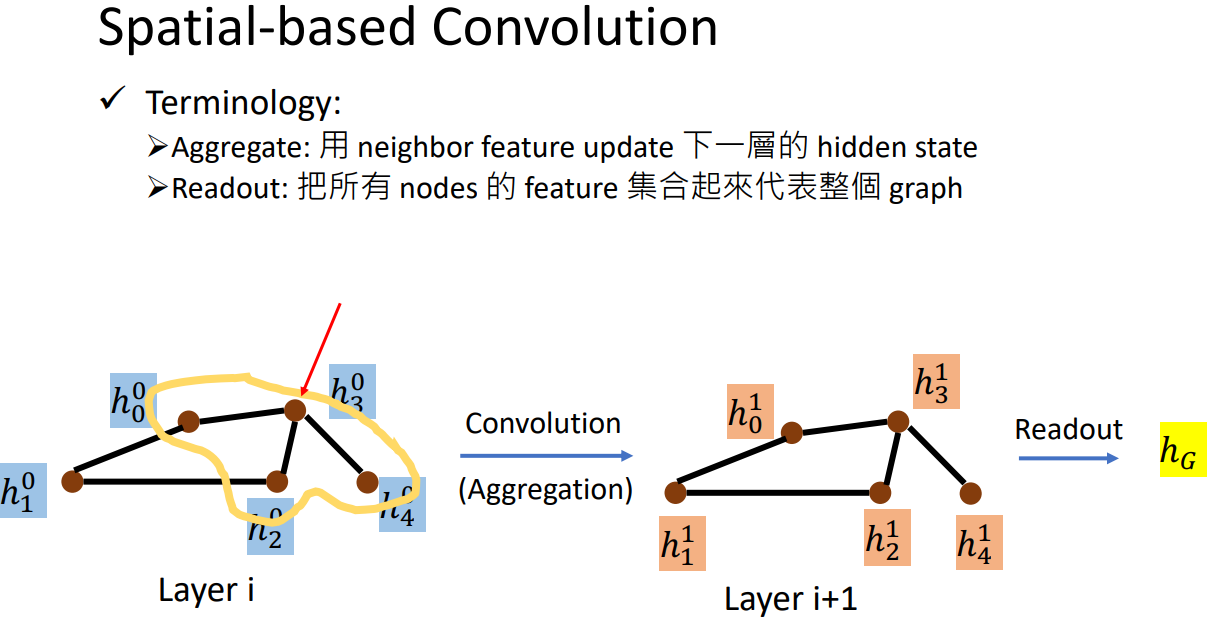
1、NN4G
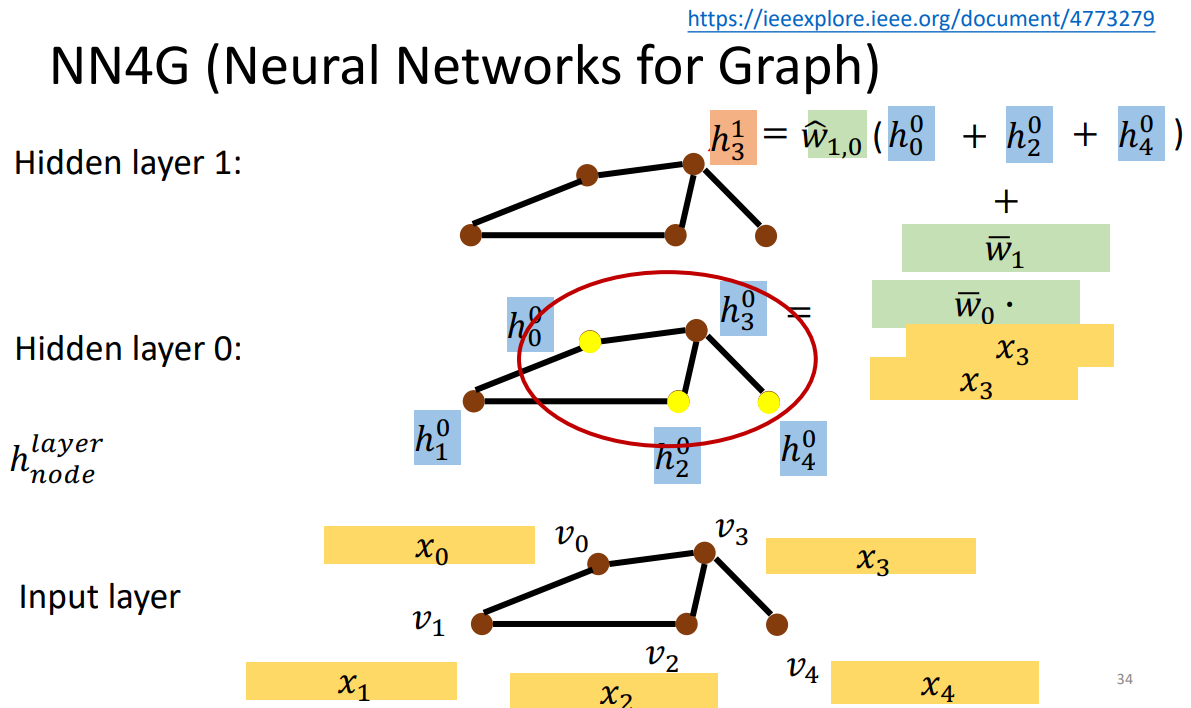
每个node feature先经过embedding layer(embedding matrix)得到feature。
然后通过aggregation,把相邻节点的feature加起来经过transform再加上原本的input feature,得到这个节点在第一层对应的hidden feature。
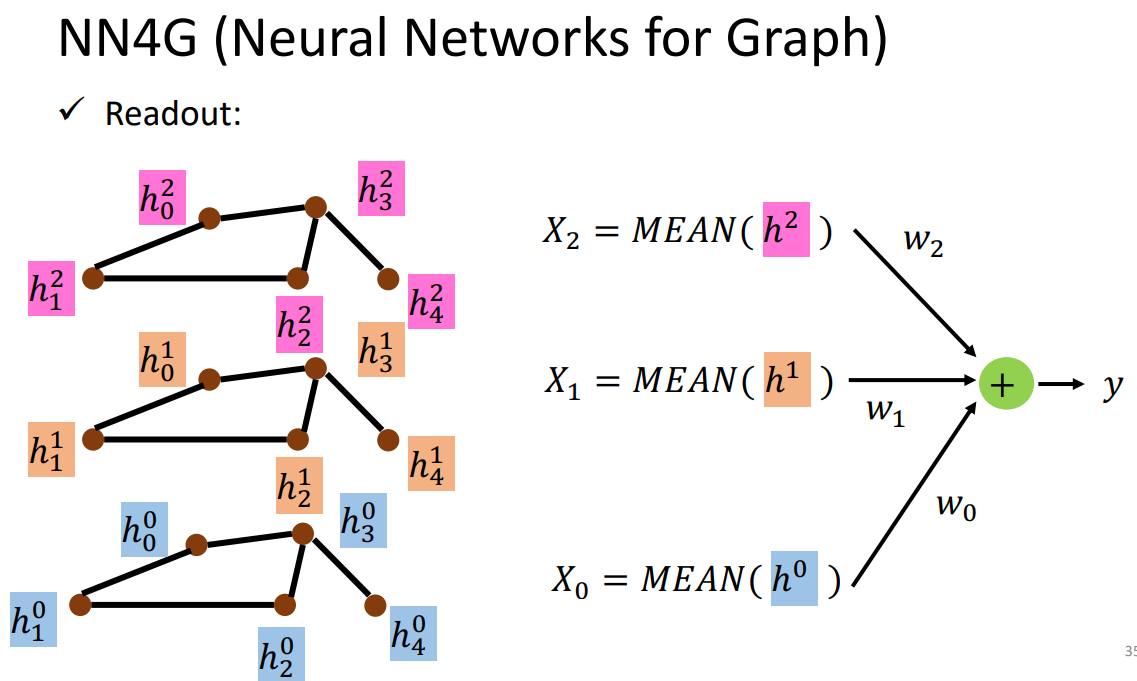
把每一层的node feature全部加起来各自经过一个transform,再加起来变成一个feature,代表整个graph。
2、DCNN
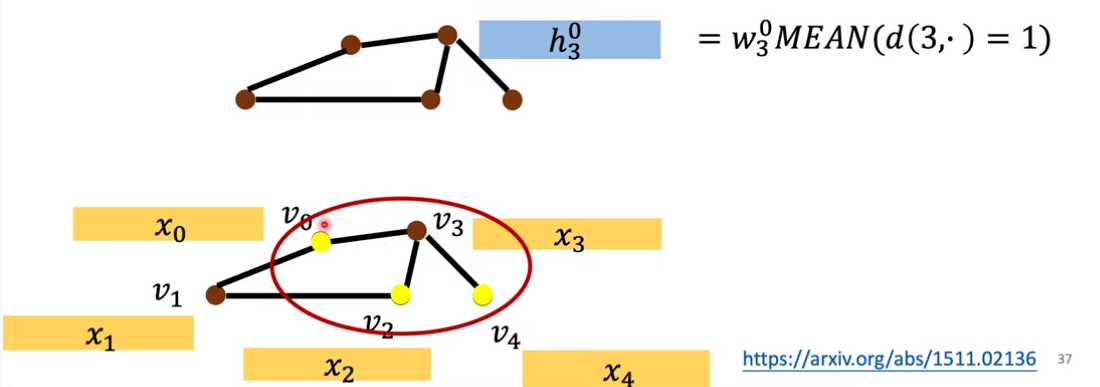
第一层把和每个结点距离是1的节点全部加起来取平均。
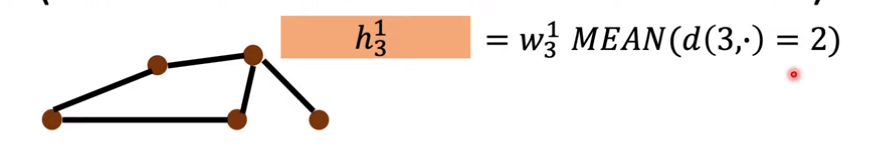
第二层把和每个结点距离是2的取平均。
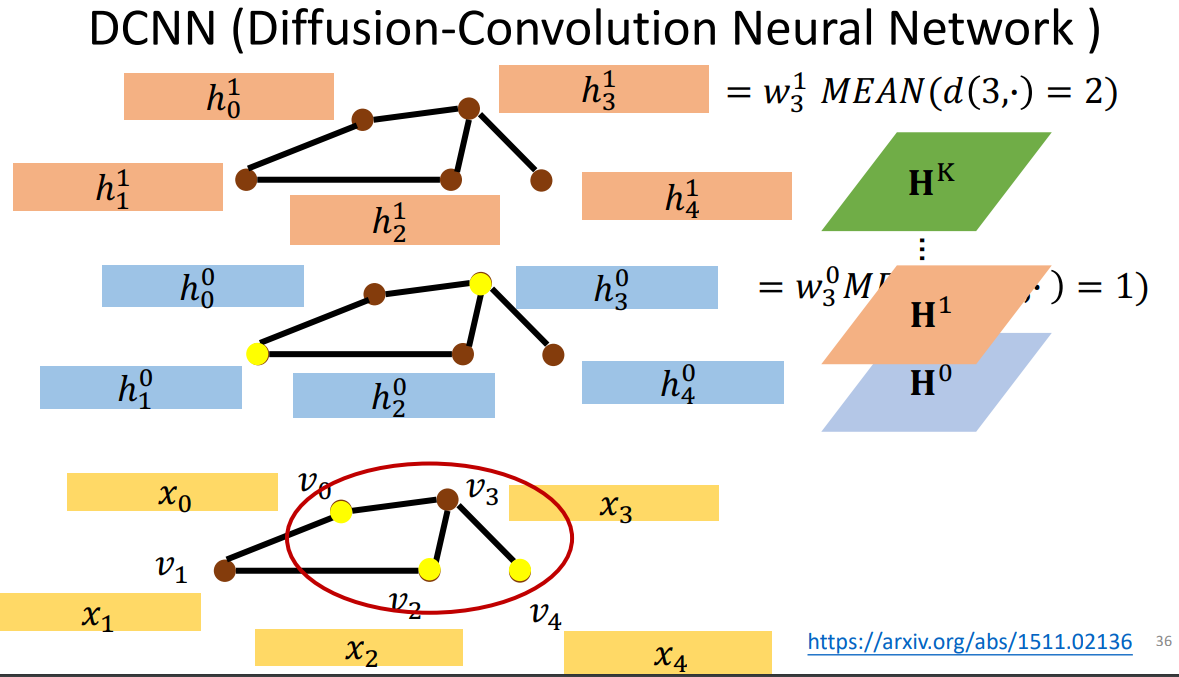
把k层的矩阵叠在一起。
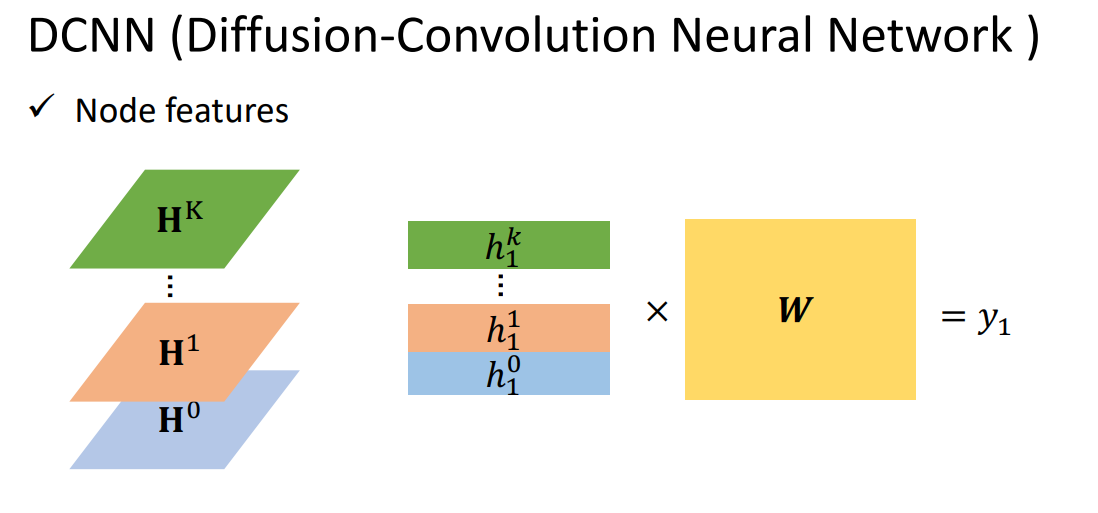
把每一个结点的feature经过transform,得到代表这个结点的feature。
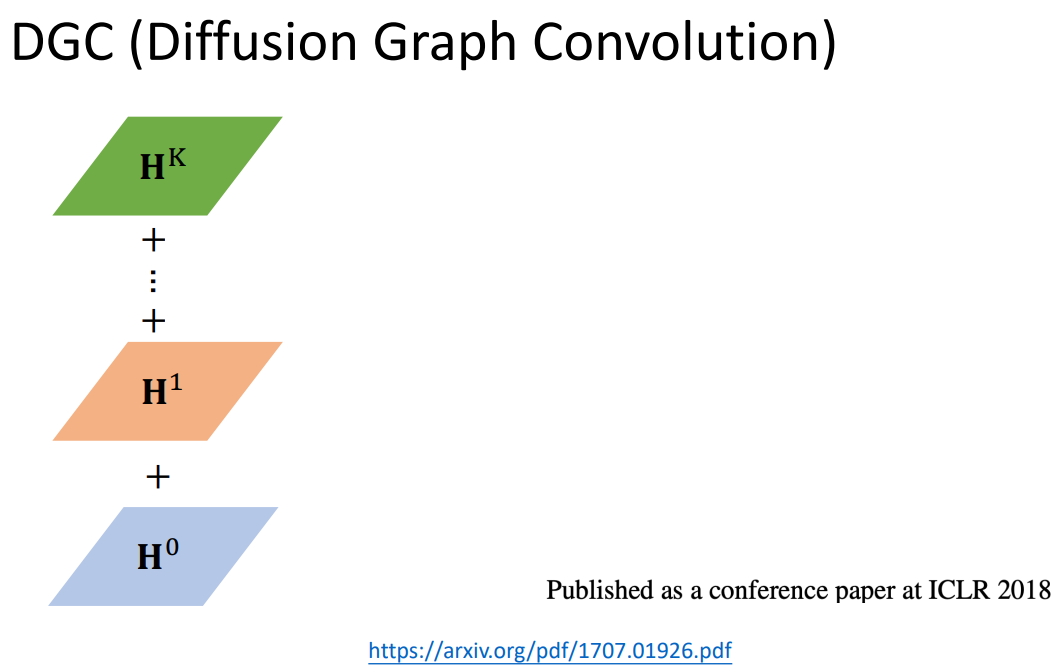
还有一种方法是全部加起来。
3、MoNet
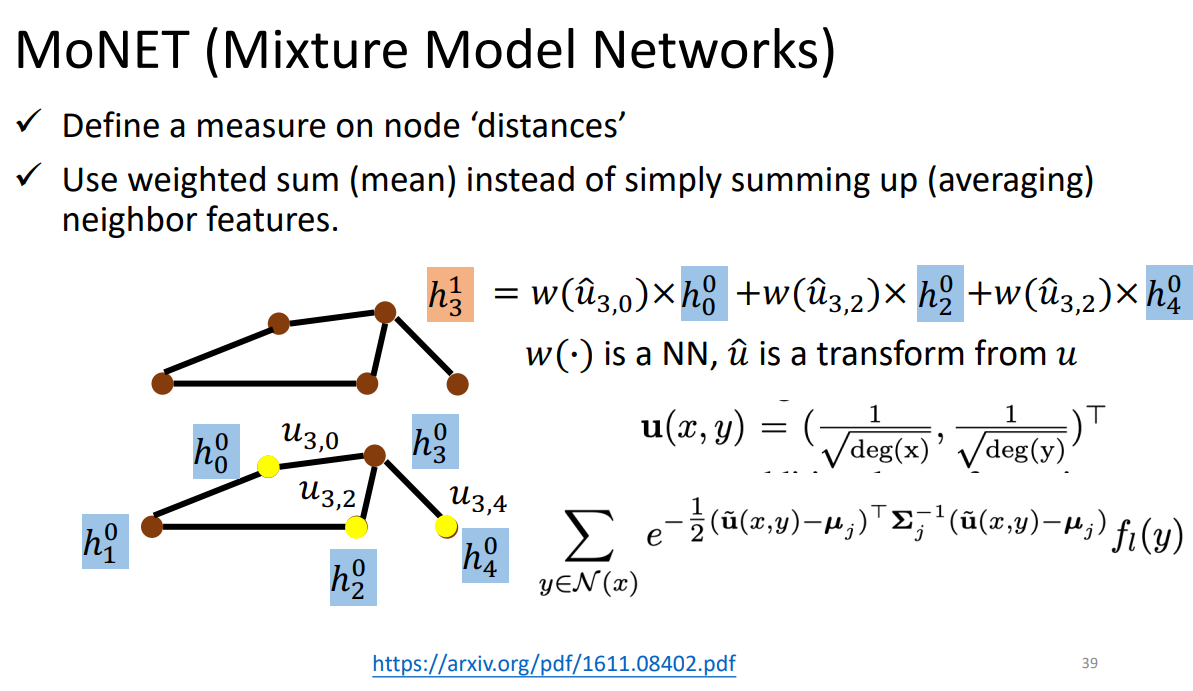
考虑每个邻居重要性是不同的,定义U代表距离。
4、GraphSAGE

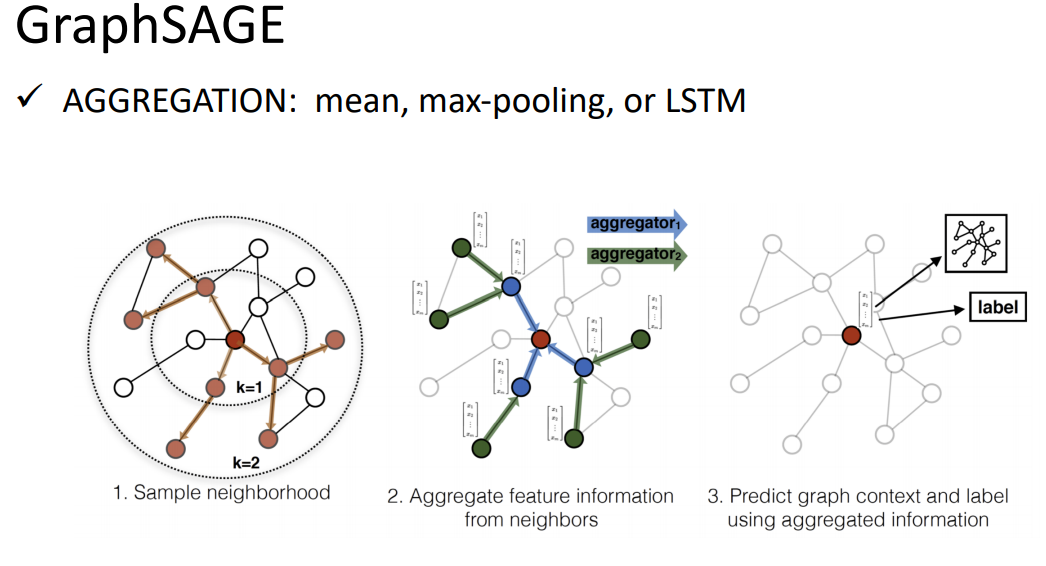
lstm每次都会按不同的顺序sample邻居,最后学到的结果就可以忽略顺序的影响。
5、GAT
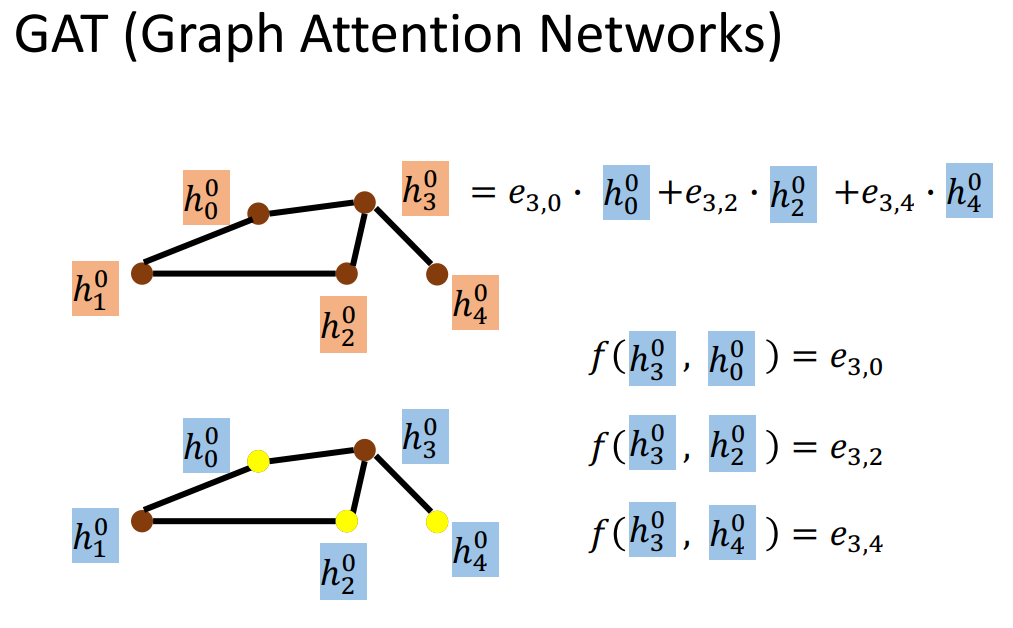
对邻居做attention,计算邻居对当前节点的不同重要程度e。
6、GIN

GIN是对哪一种方法更有效的理论推导。
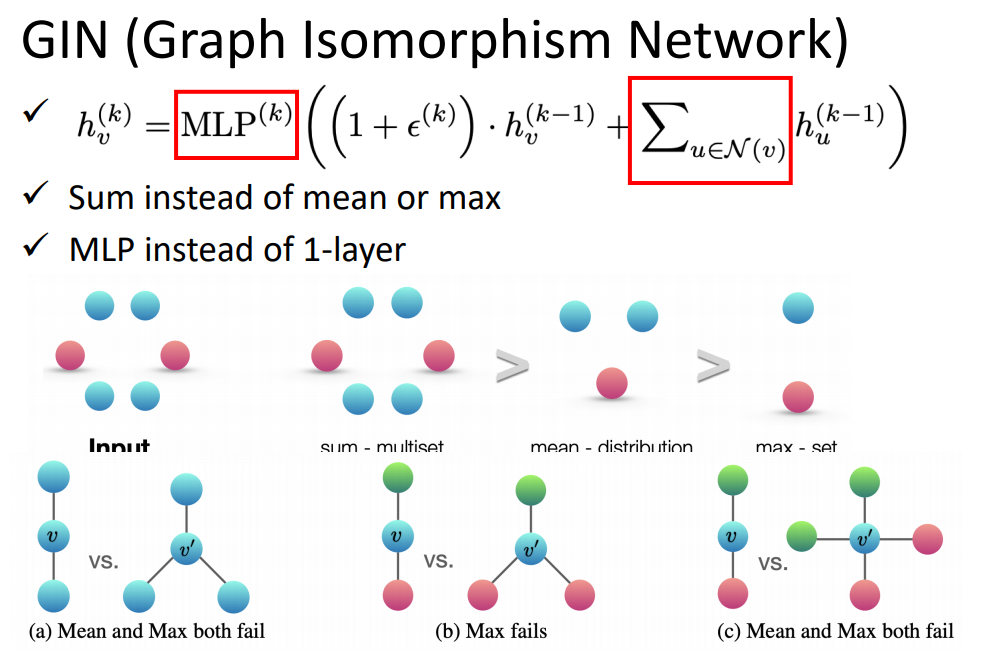
更新feature的方式参照上面的公式,其中其它节点要相加而不是mean或者max。
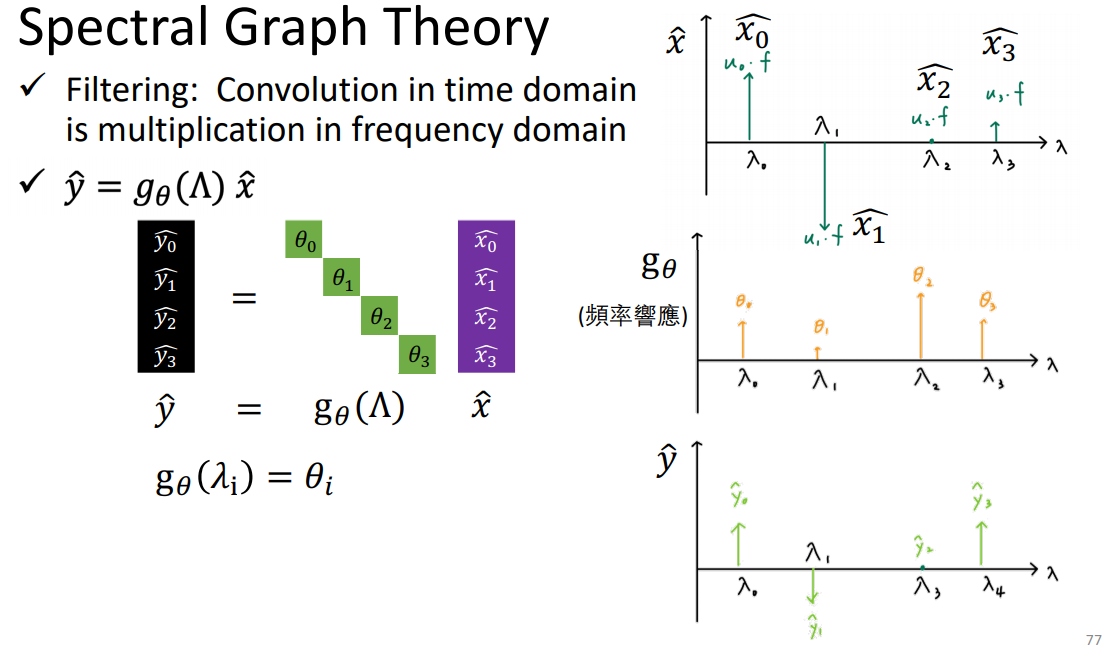
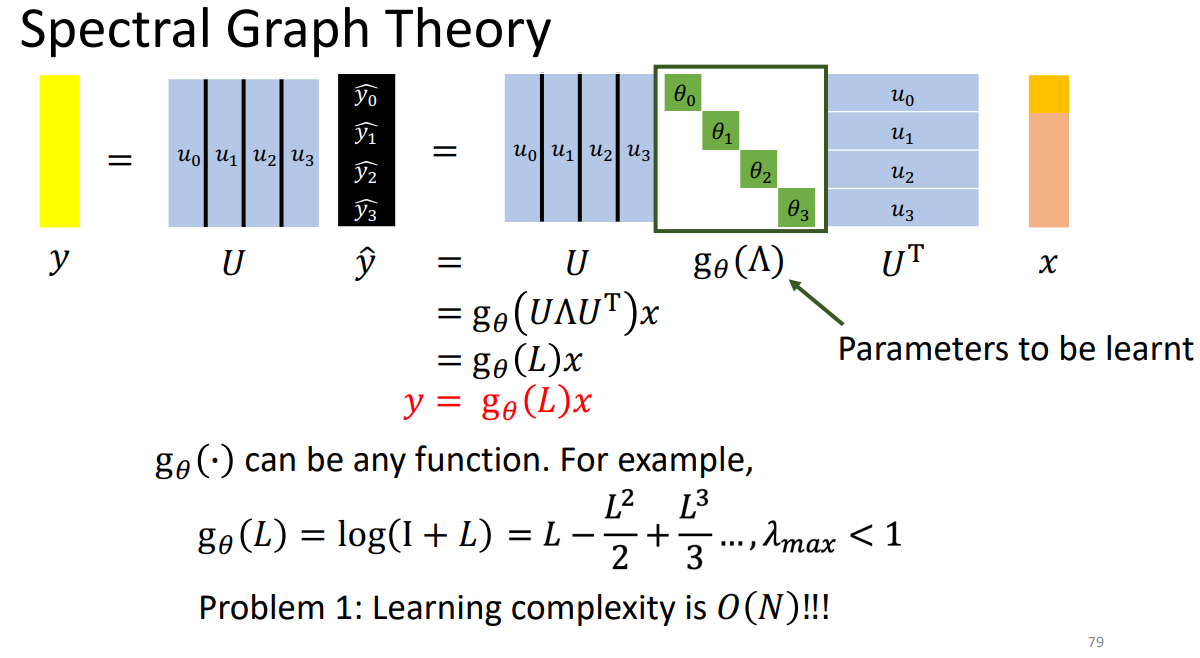
三、Spectral-Based Convolution
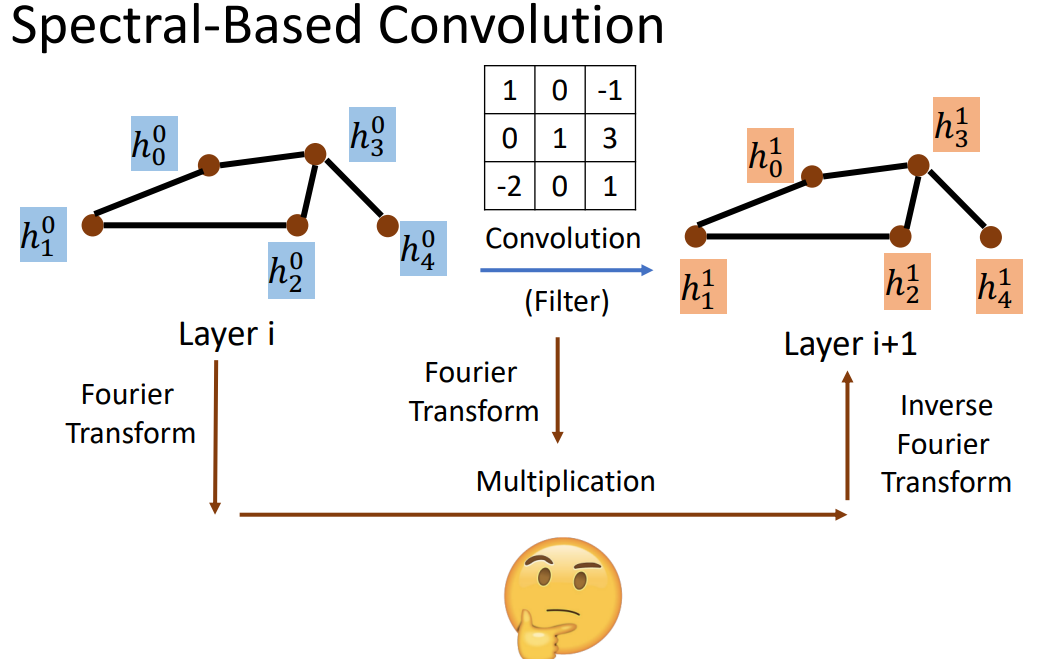
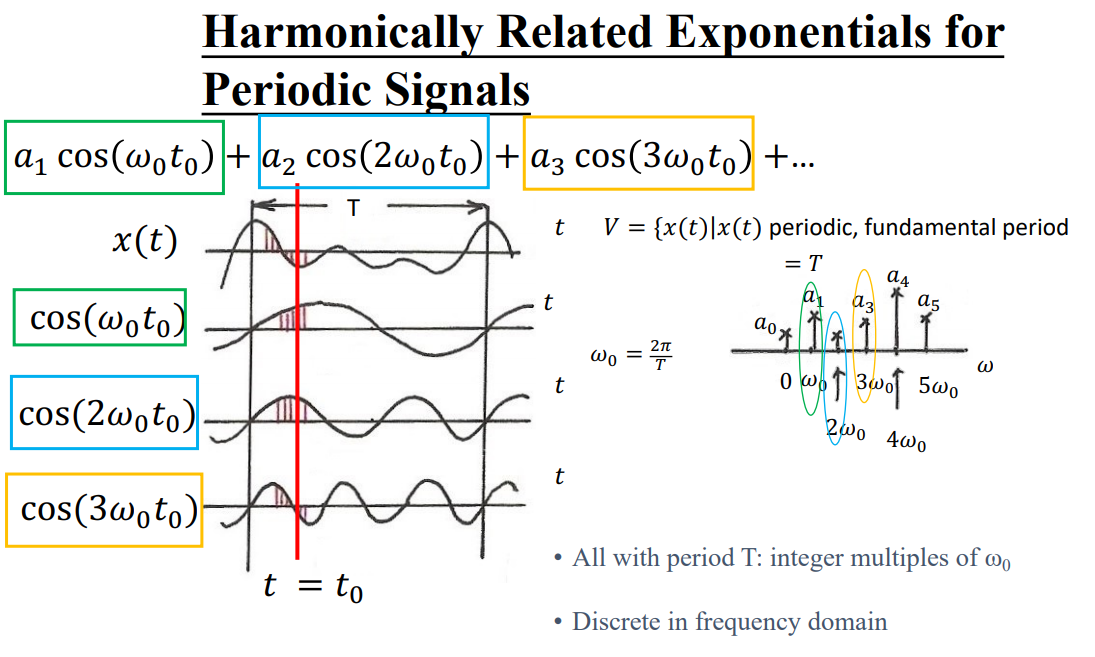
signal通过傅里叶变换,相乘后再变回去。

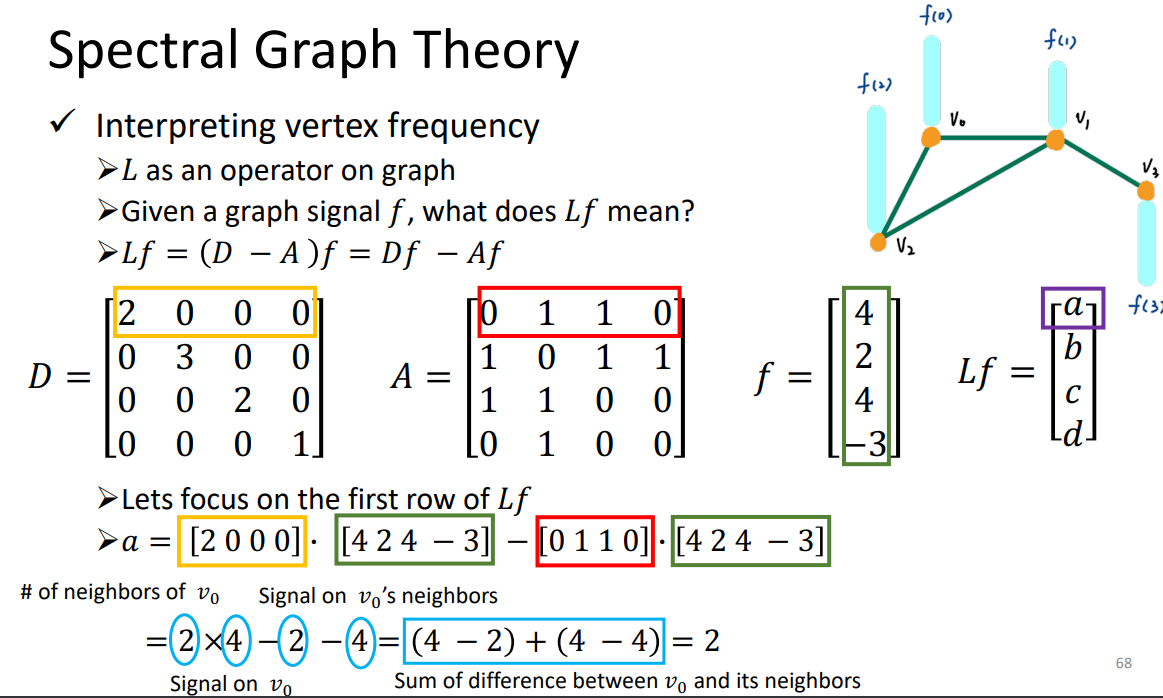
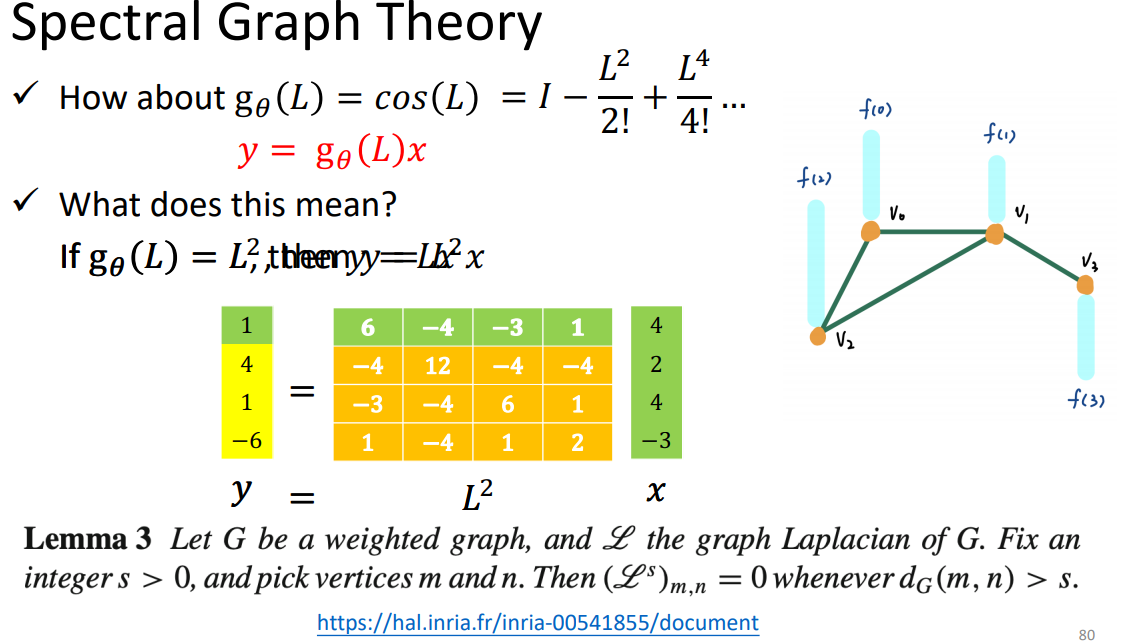
谱图理论:

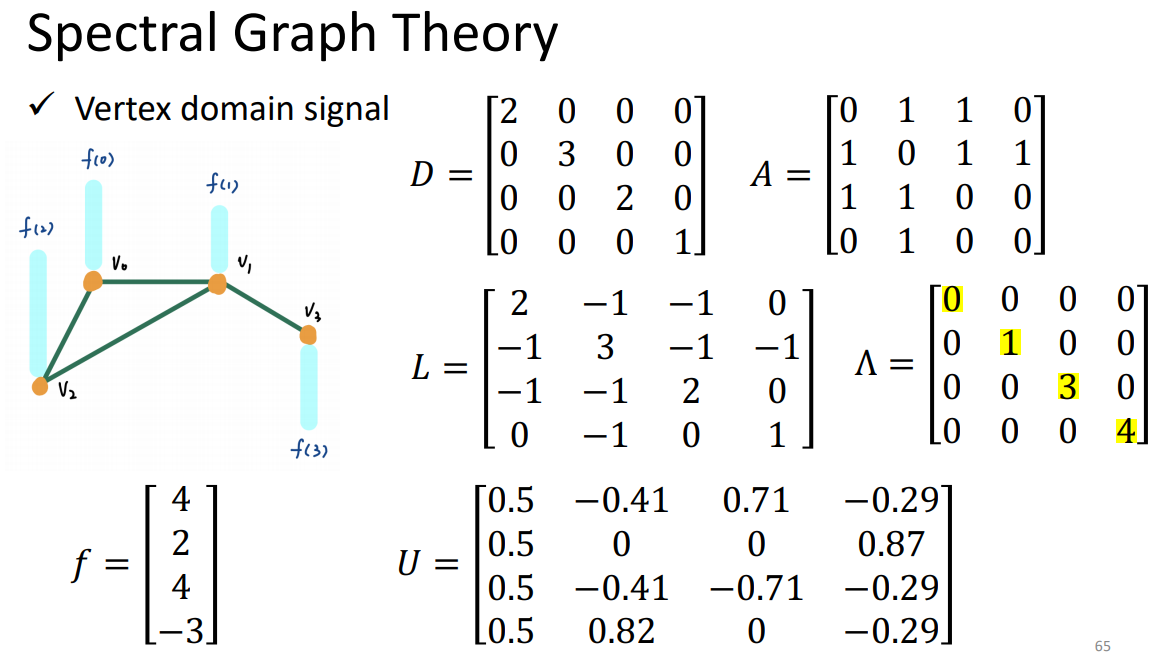
0表示没有相连。
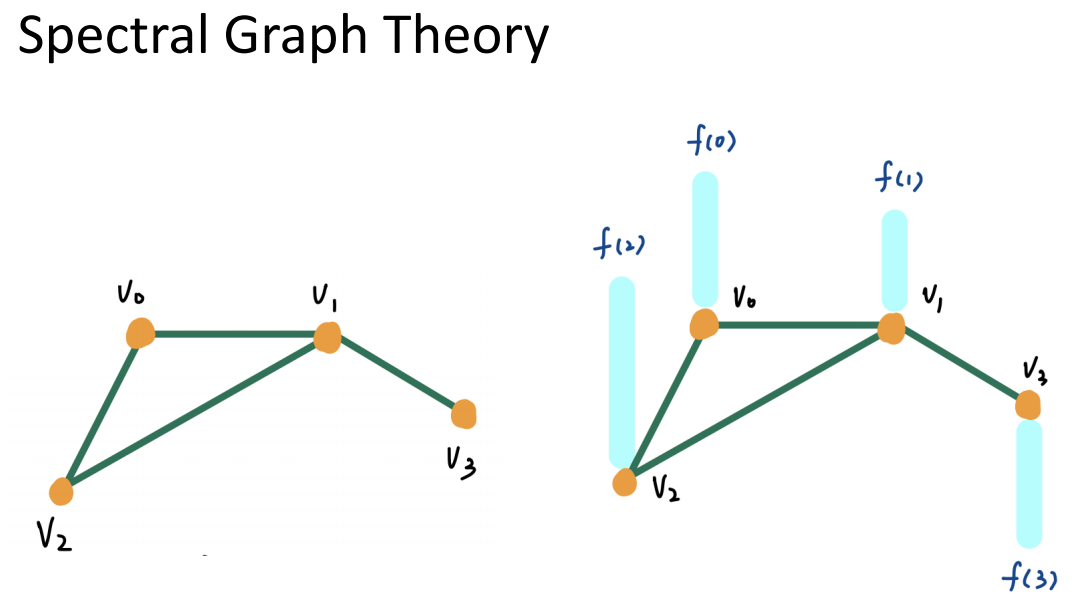
信号可以代表一些信息,如城市路网图中代表气温、人口增长等
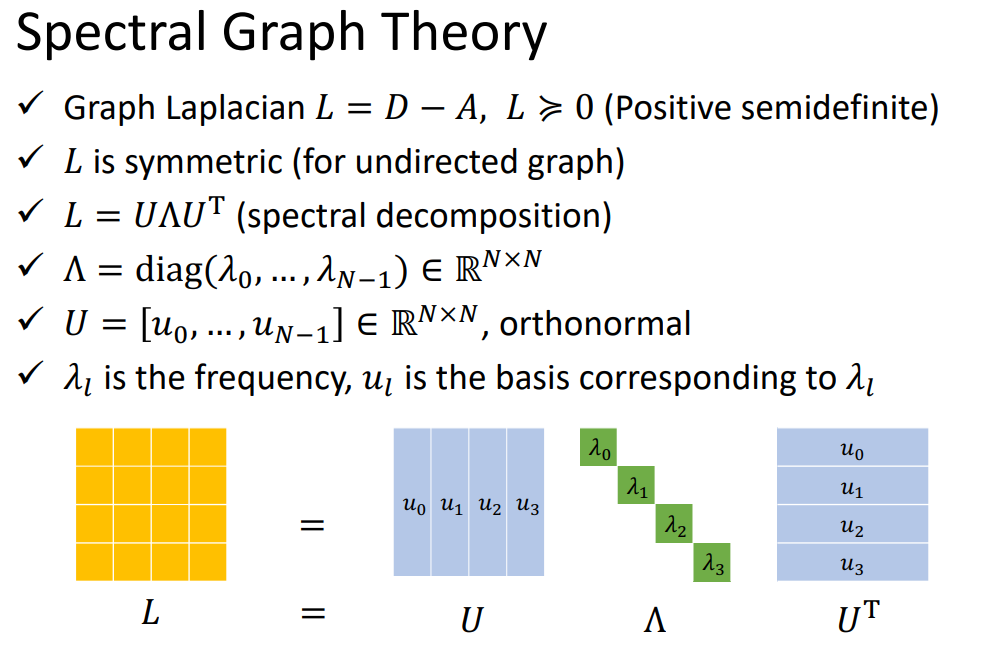
举例:
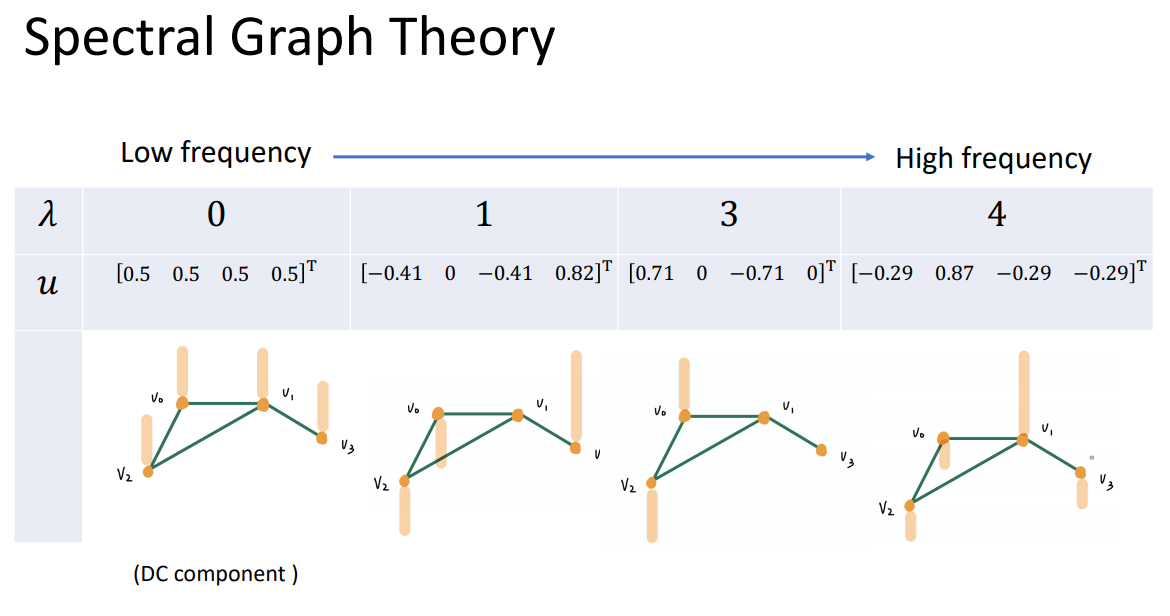
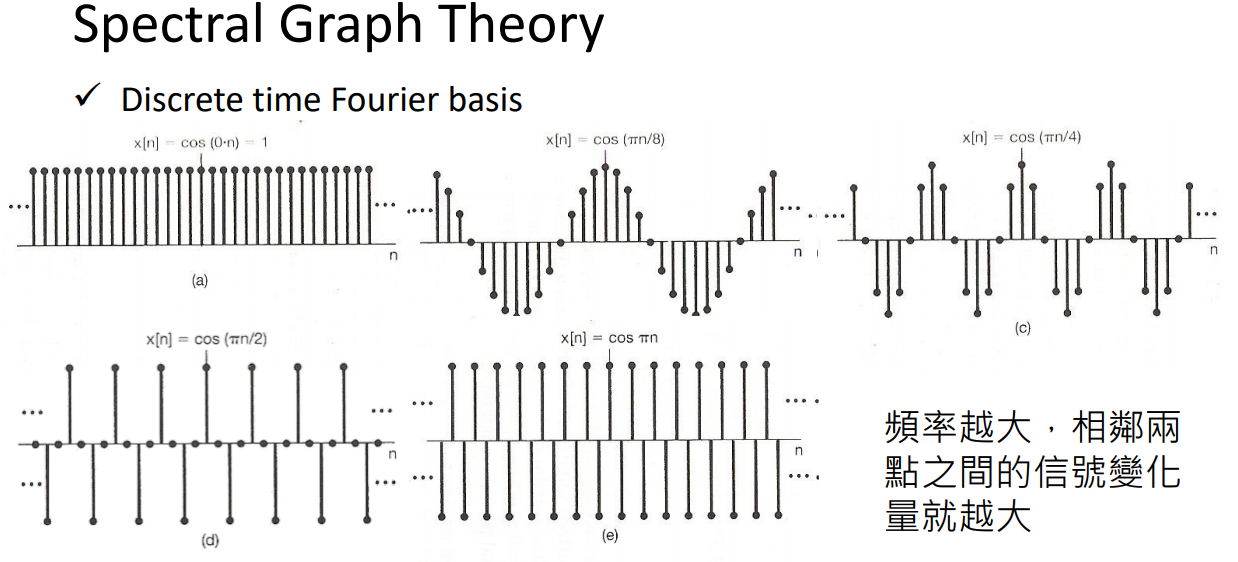

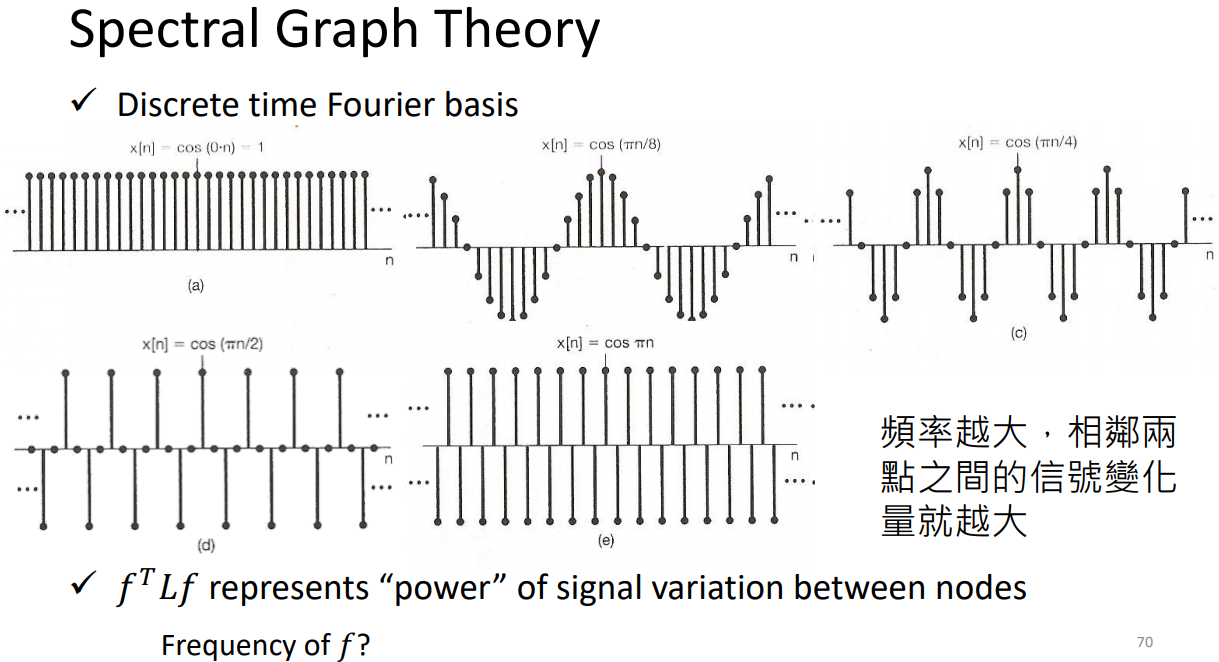
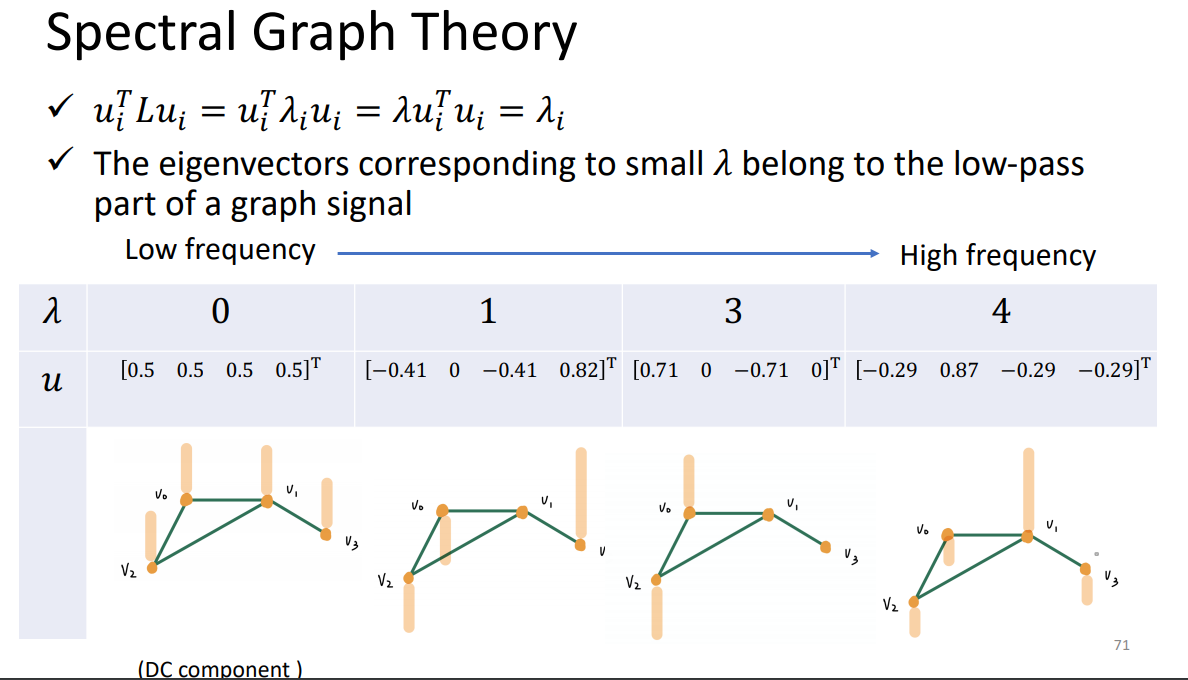
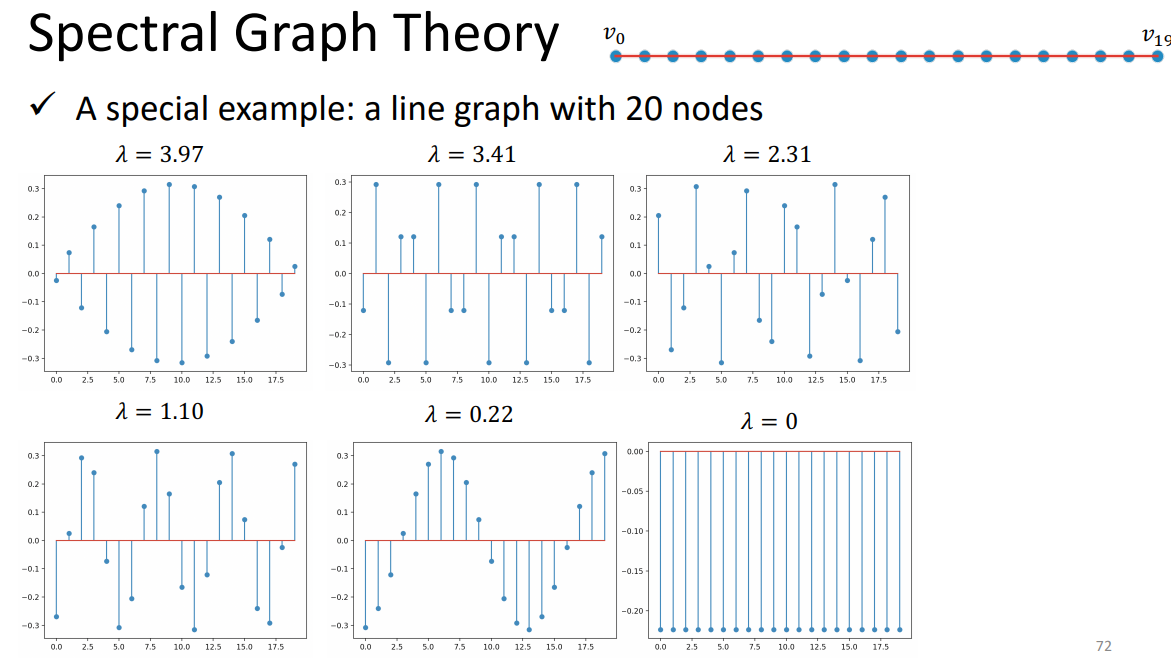
λ代表频率大小。
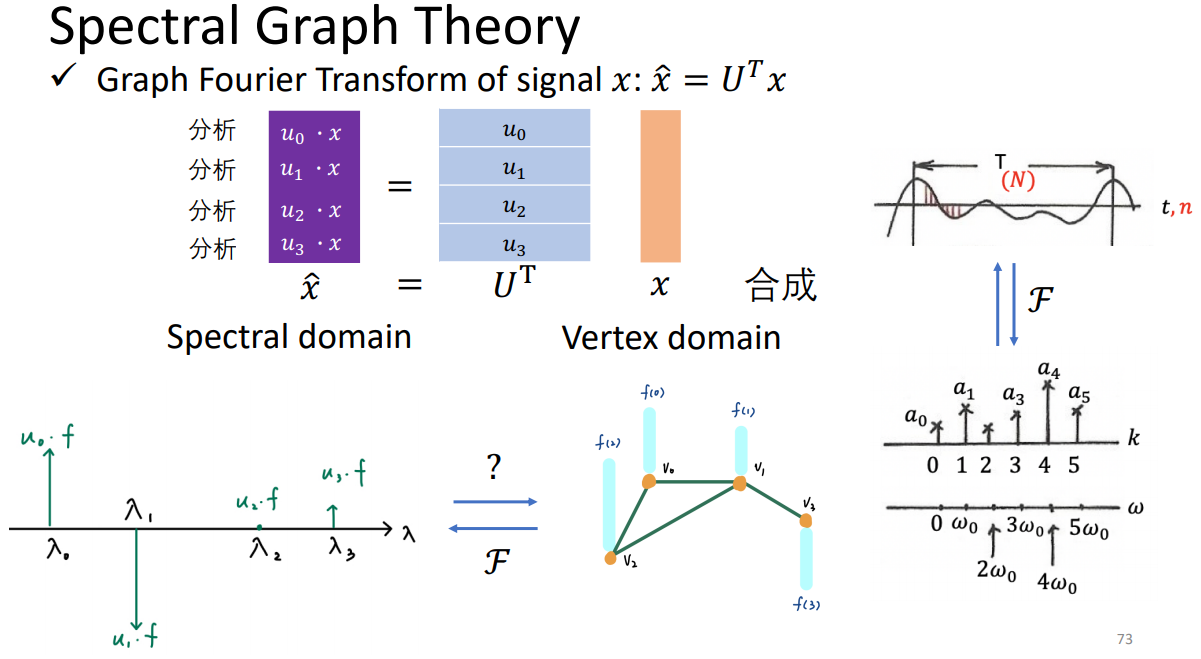
合成就是分析每个component的大小。
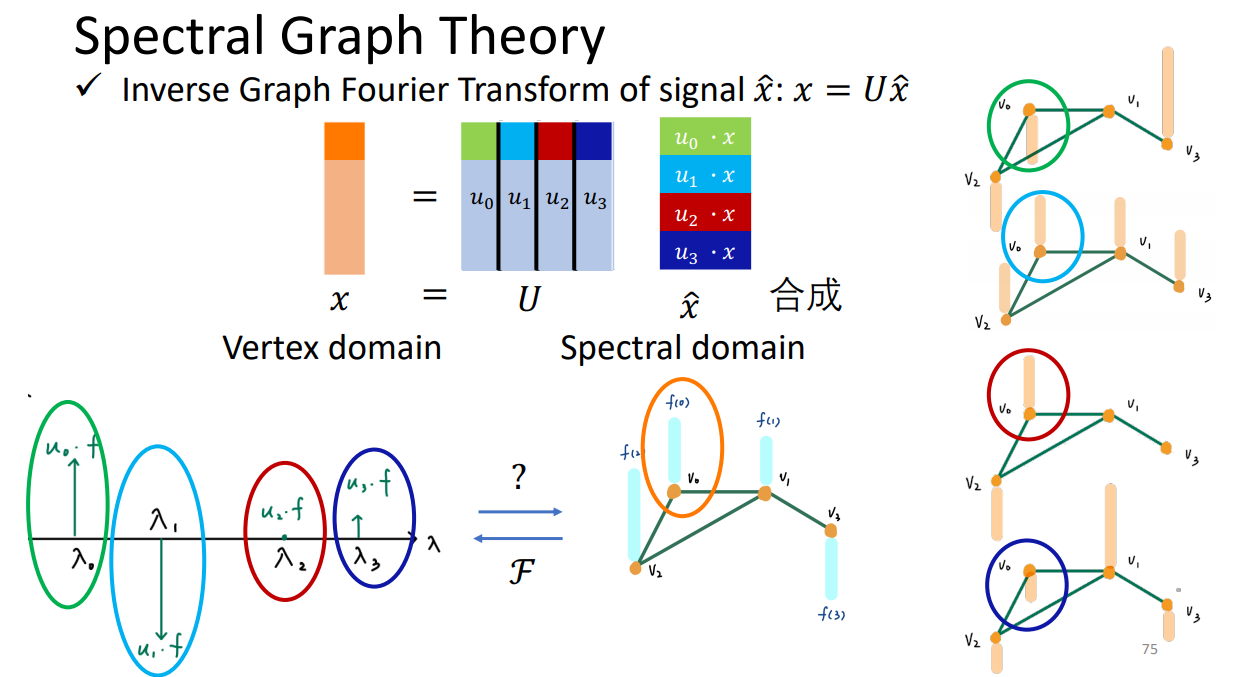

1、ChebNet

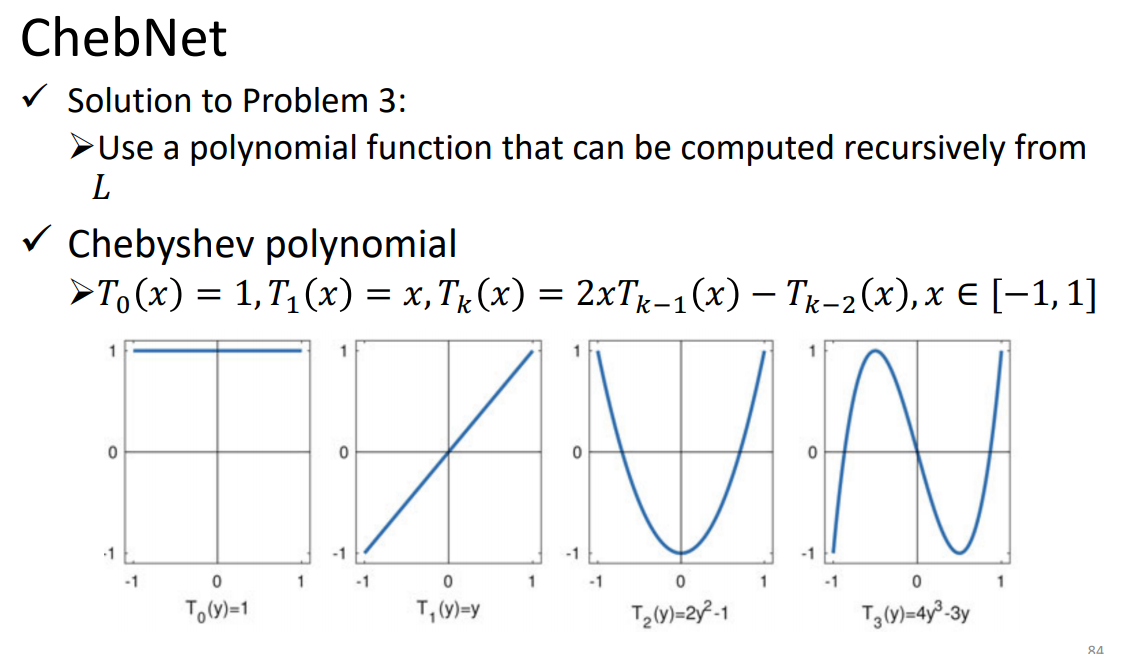
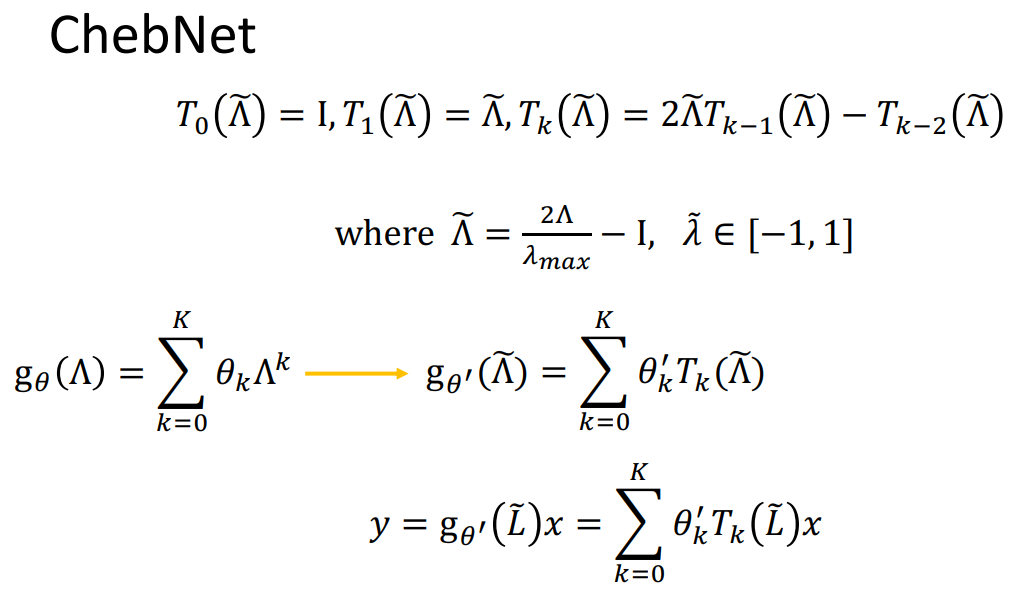
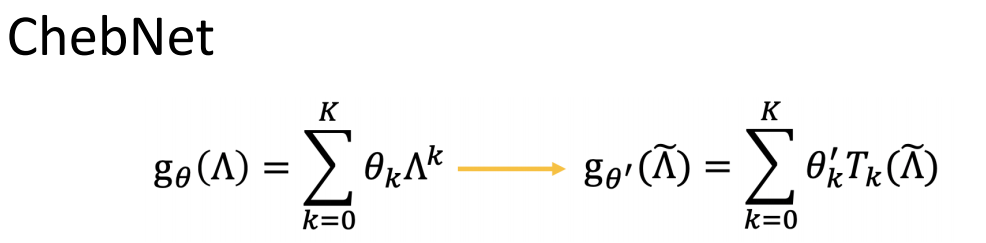
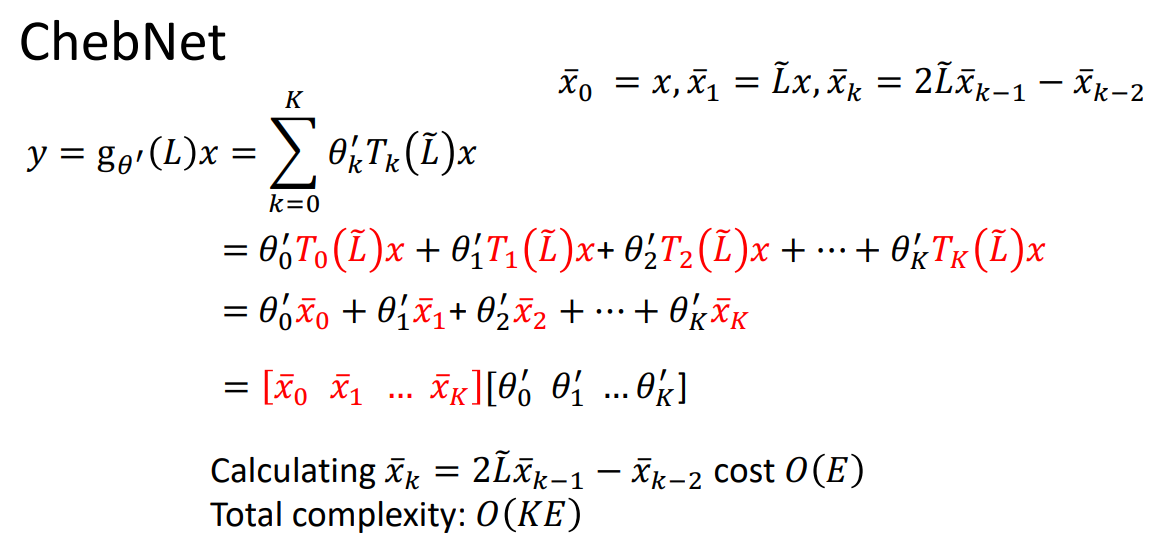
这种方法计算[x0...xk]可以降低复杂度。
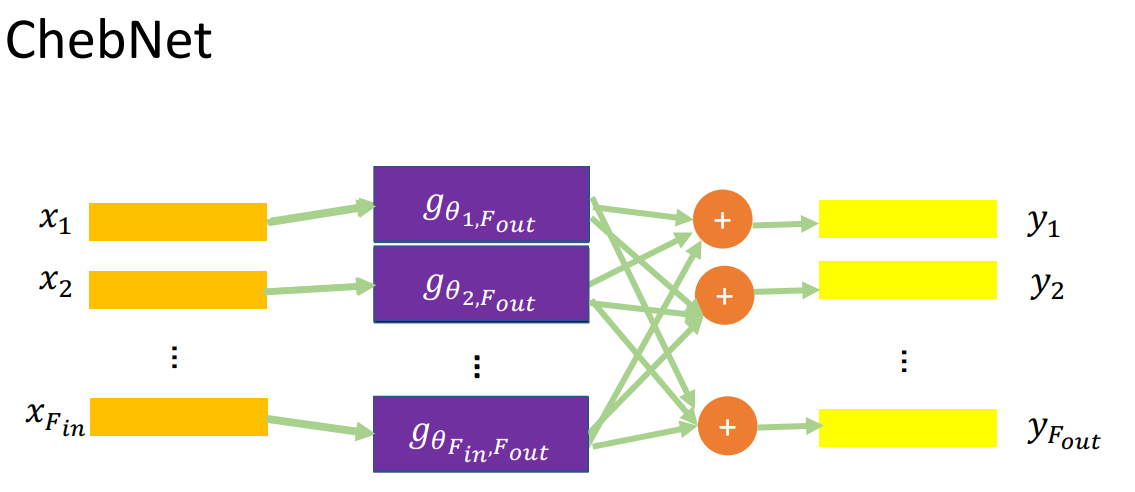
2、GCN
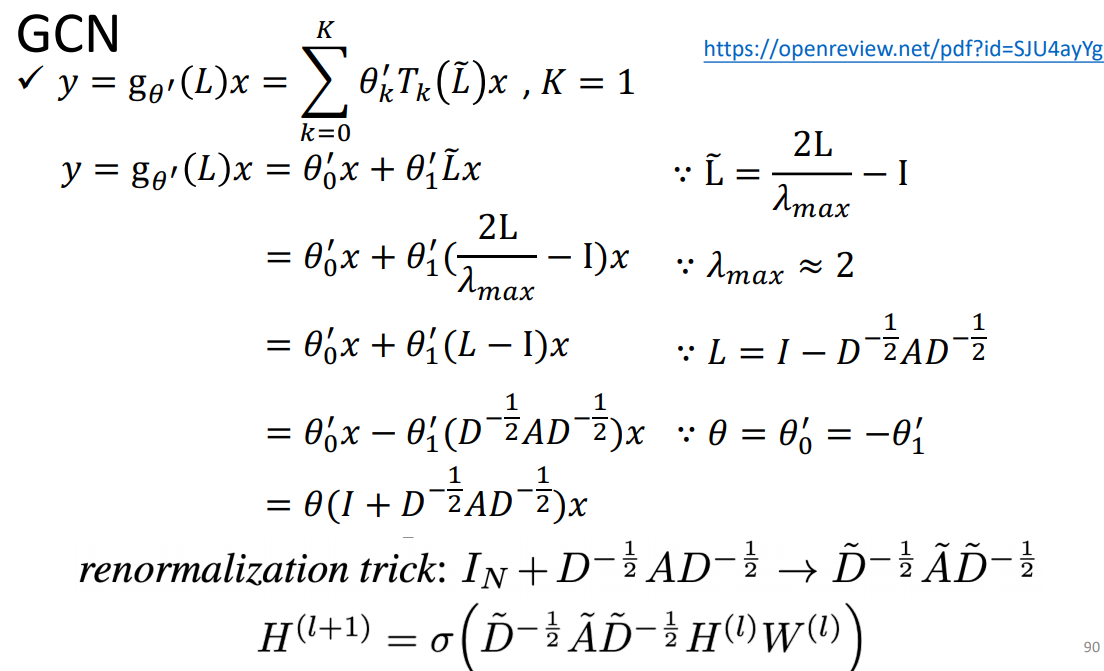
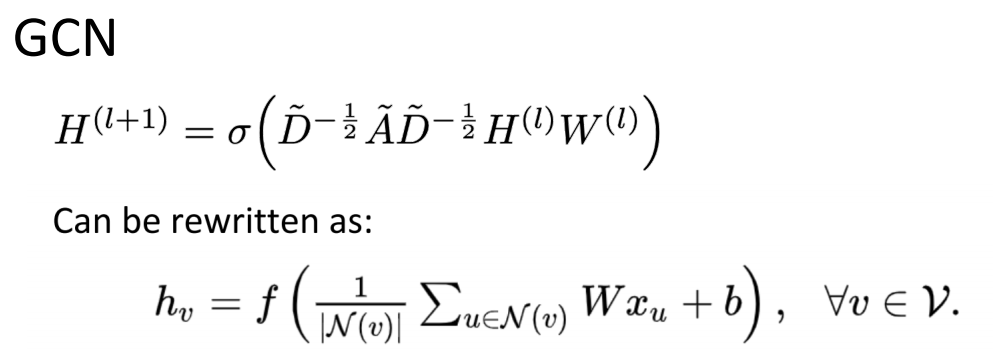
小结:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号