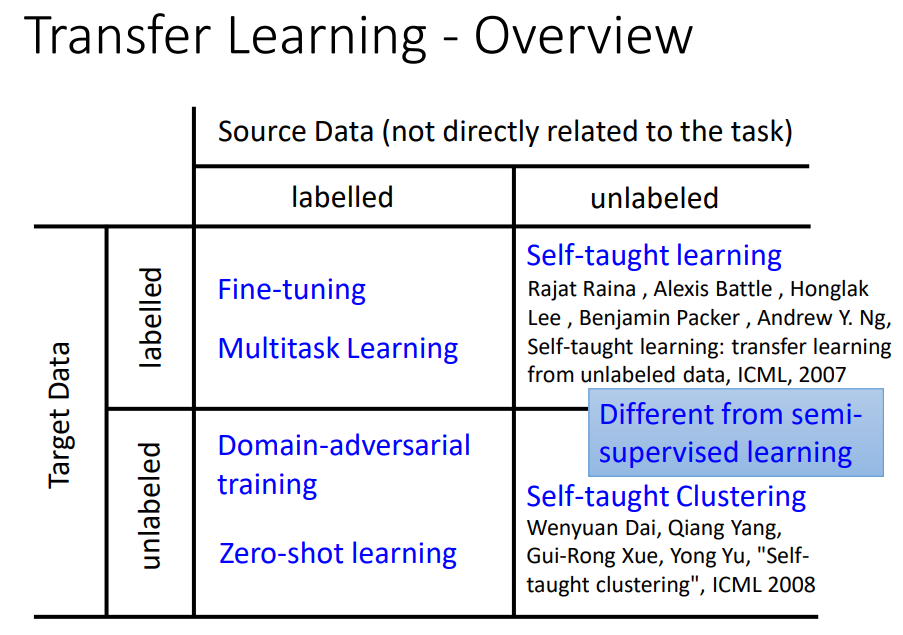
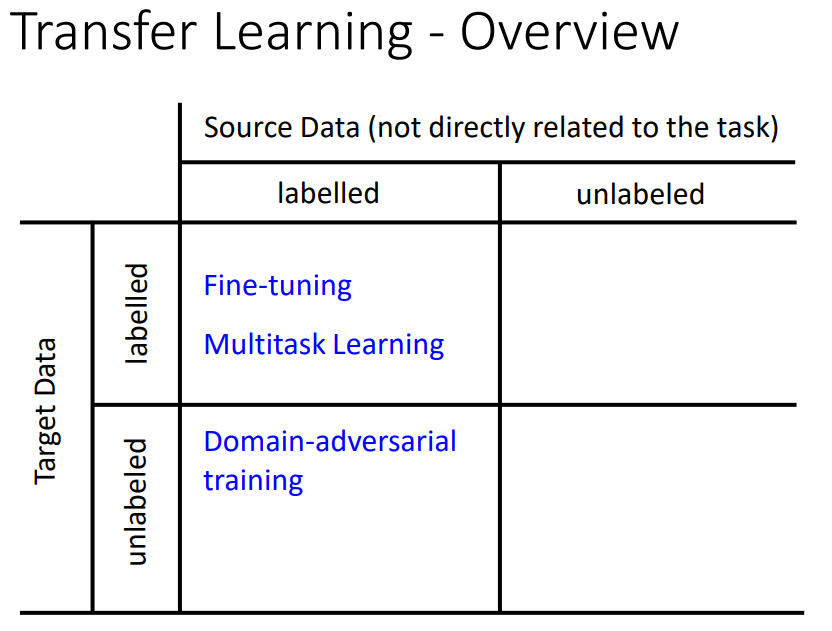
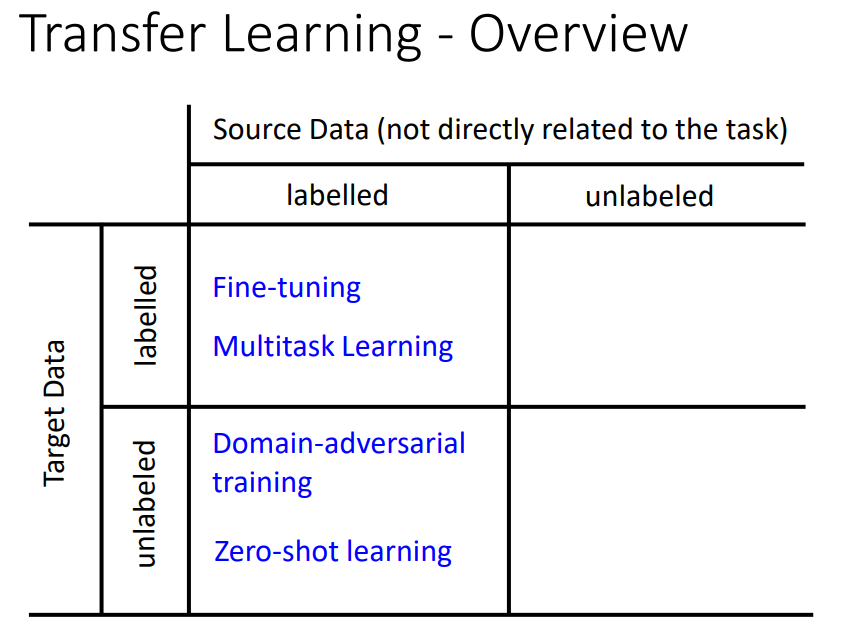
一、transfer learning


target data:现在要考虑的task直接相关。
source data:和现在要考虑的task没有直接关系。
四种可能:有label和无label。
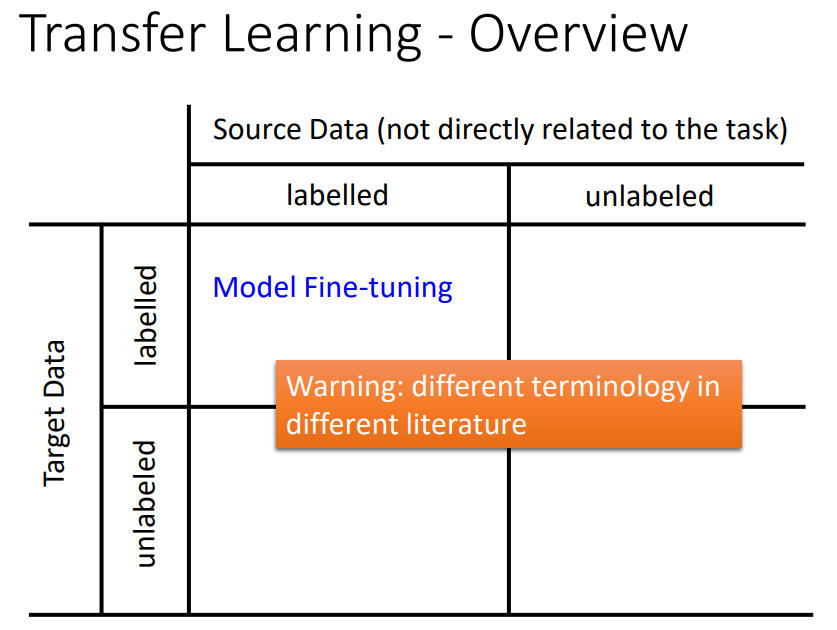
二、fine-tuning
target data和source data同时都有label。
target data量非常少(叫做one-shot learning),source data很多。

某个人的语音很少。
用source data直接去train model,然后用target data去fine-tune model(就是把source data train的值当做初始值,直接train下去就结束了)
fine-tune的挑战:target data非常少,需要一些技巧。
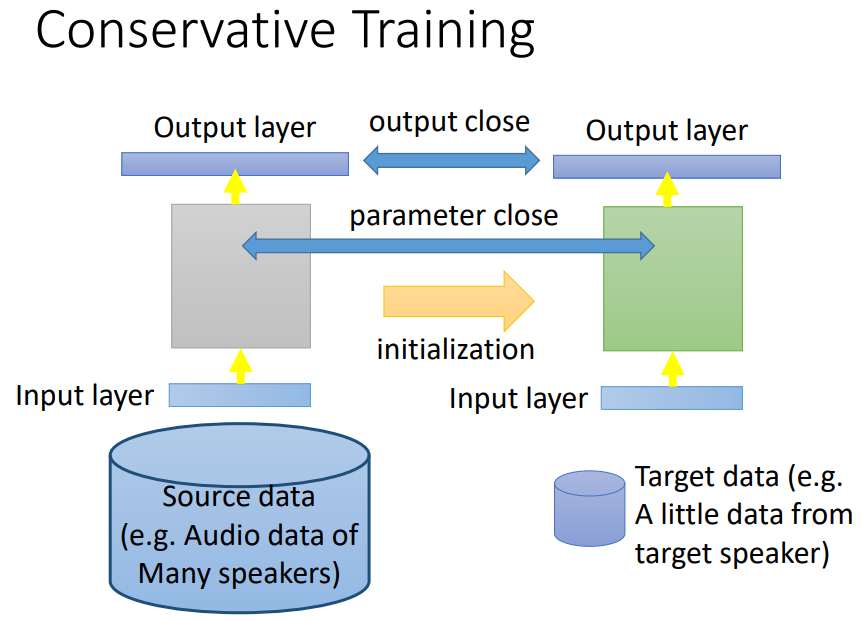
加一个regularization,希望右边新的model的output和旧的model的output在看到同一笔data时不要差太多,就可以防止overfitting。

把source data train好的model中的几个layer直接copy到新的model里面,
用target data只去train没有copy的layer(只需要考虑非常少的参数,就可以避免过拟合),
如果target data够多,也可以fine-tune整个model。
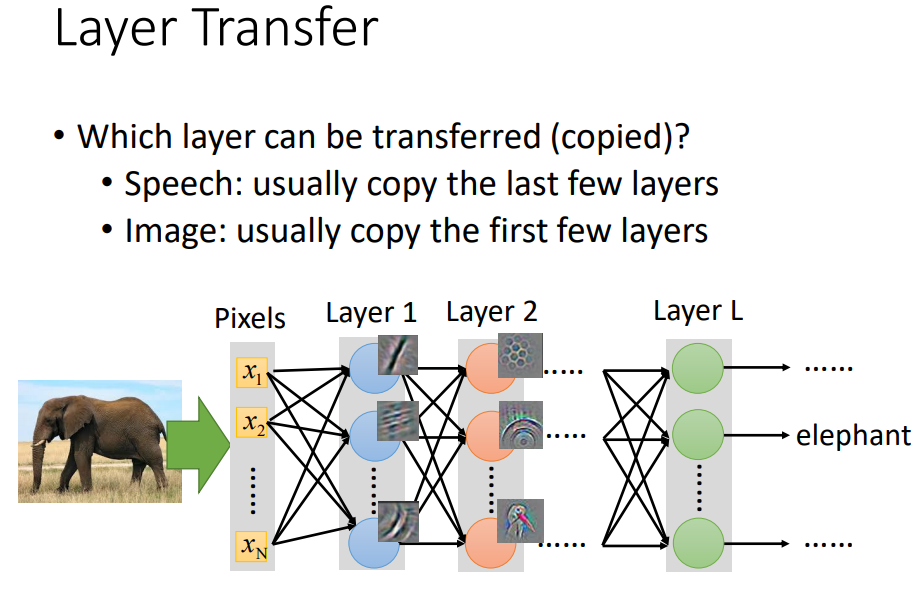
那么哪些layer应该被transfer呢?
speech:前几层是从声音讯号得到说话人的发音方式(口腔结构差异),再根据发音方式得到辨识结果(跟说话的人没关系,所以可以被copy)。
image:前几层detect简单的pattern如直线曲线简单的几何图形,所以可以被transfer到其它的task上面,后面的层就比较abstract。
三、multitask learning
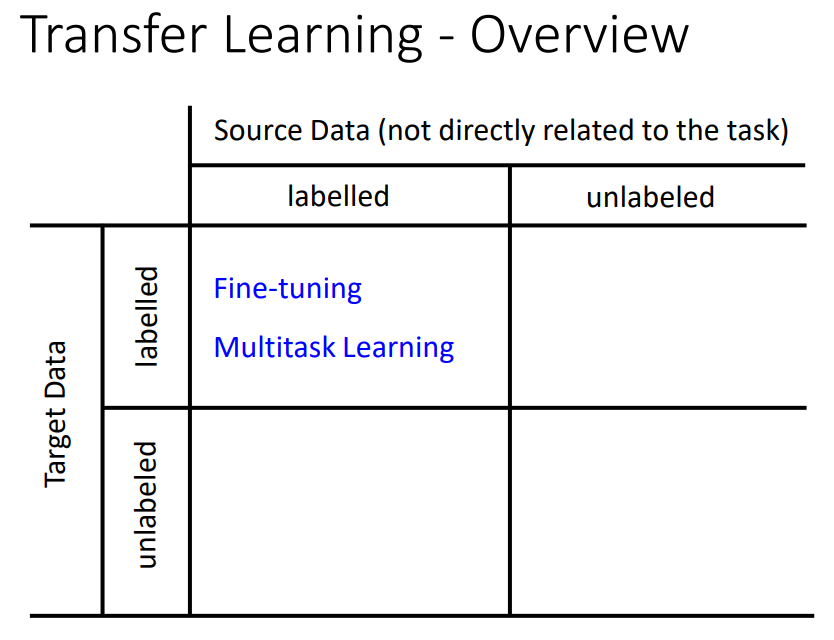
fine-tuning只care在target domain做的好不好。
同时care target domain和source domain做得好不好。
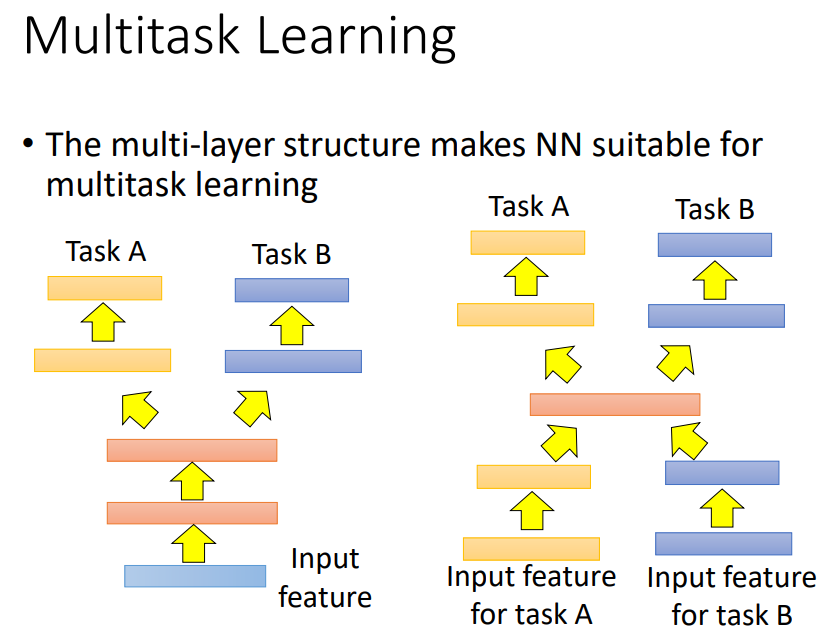
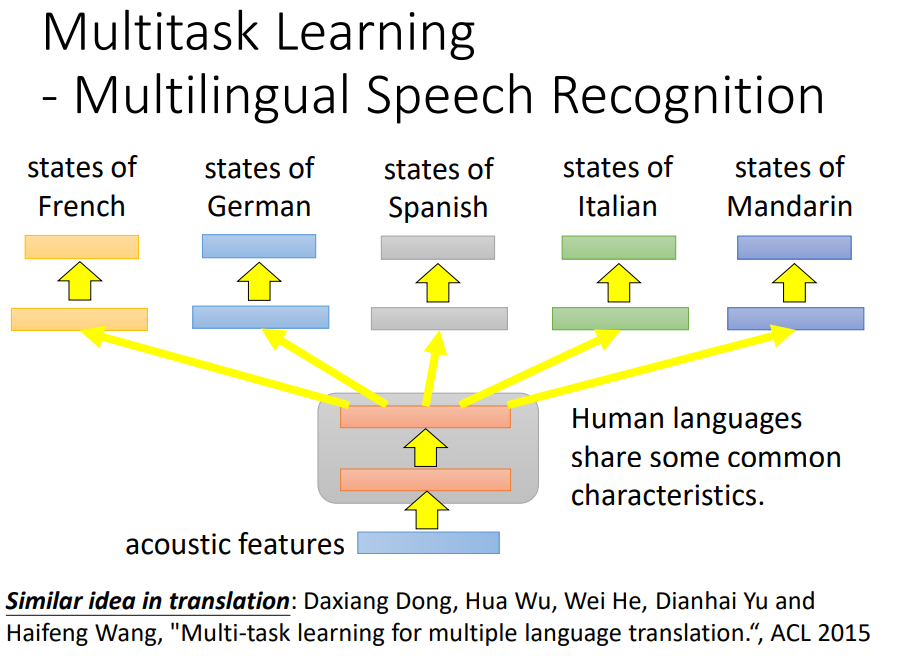
前面几个layer可以share同样的参数。在语音辨识(目前研究发现所有语言之间都可以transfer)和翻译都可以把model一起train。

蓝色表示只用中文data的error rate,红色表示有欧洲语言来帮助中文model的前面几层,做transfer learning,可以得到比较好的performance。
但如果两个task不像的话,transfer就是negative的。
有人提出了progressive neural networks:
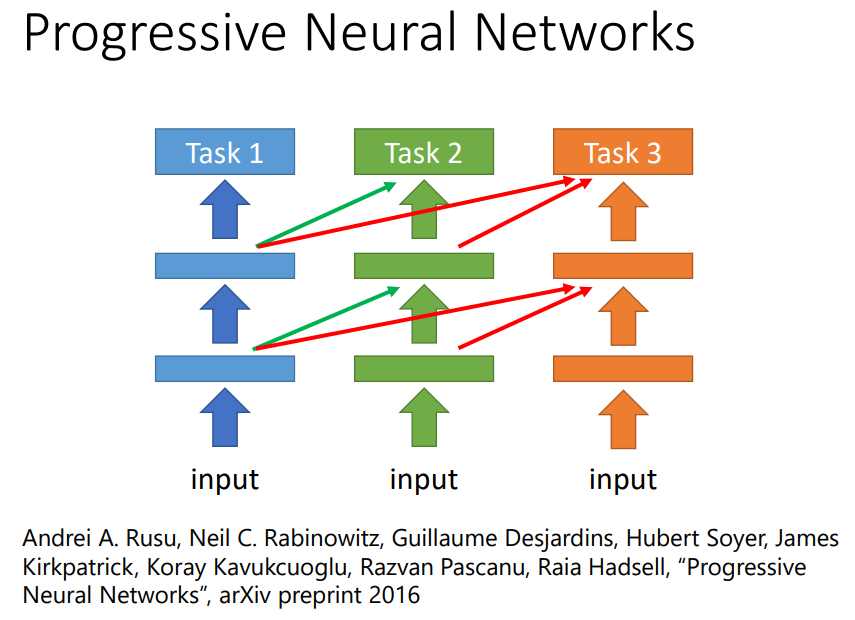
把第一个任务做好,参数fix住,第二个任务每一个hidden layer接面某一个hidde layer的output,就算task2和task1不像,task2的data不会动到task1的model,task1一定不会变差,task2借用task1的参数,并可以把这些参数直接设成0,也不会影响task2的performance,task3会同时从1和2的hidden layer得到information。
四、Domain-adversarial training
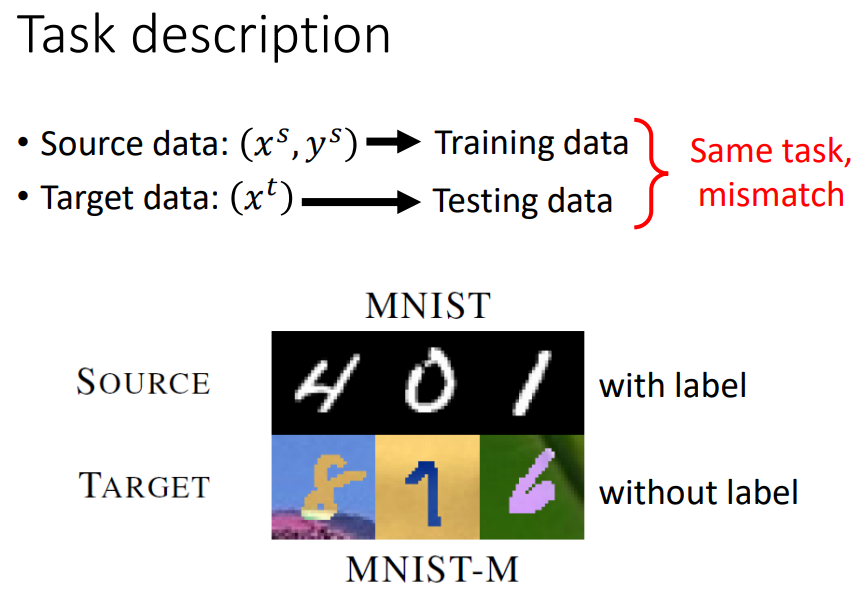
target data没有output。
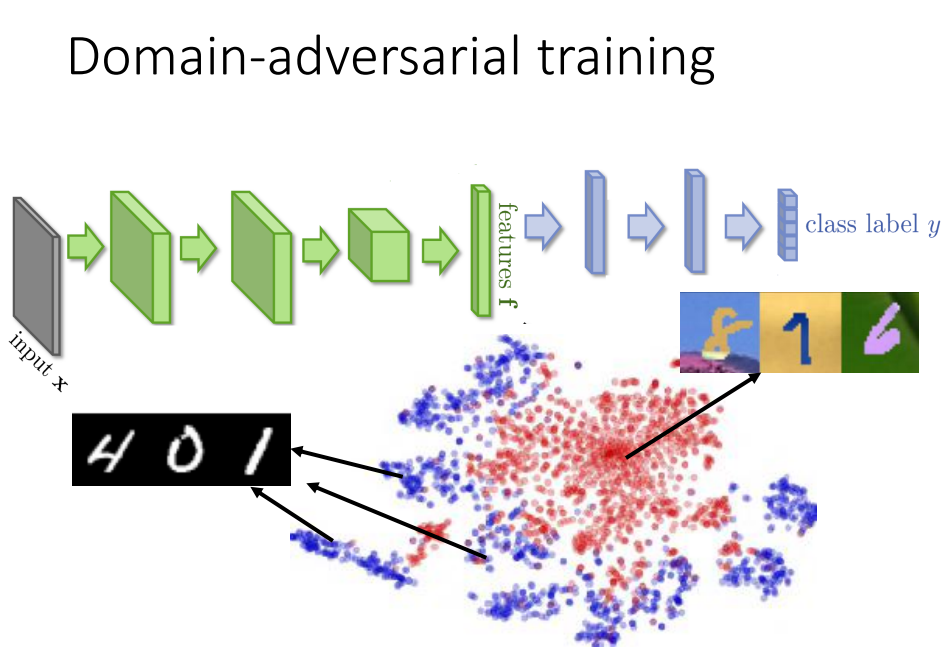
前面几层可以看做在抽feature,后面几层可以看做是classification。
mnist的feature是蓝色点明显分成几类,但另外一个domain抽出来的feature就是红色的点。
希望前面的feature extract可以把domain的特性去除掉。
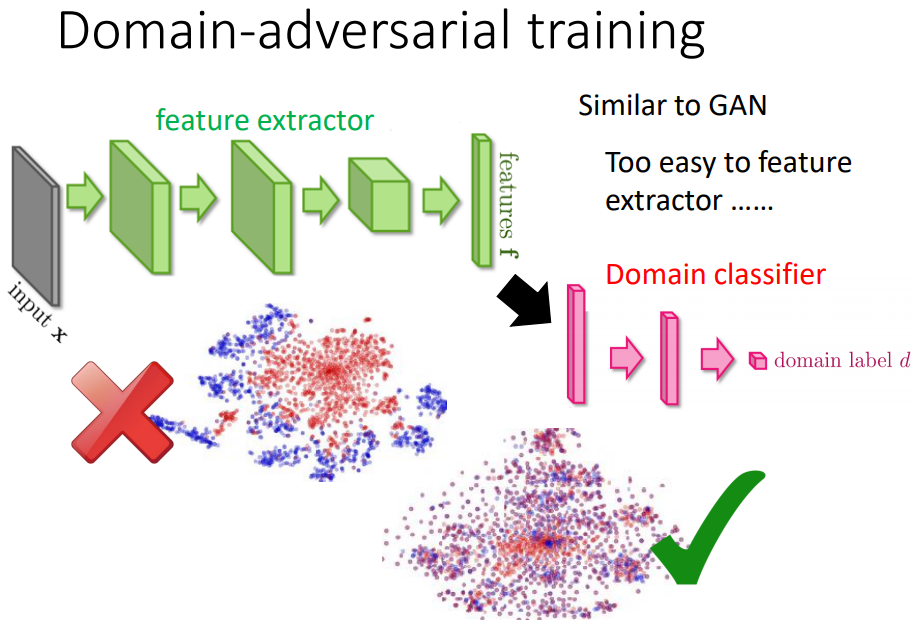
希望特征抽取可以把不同domain的image混在一起,把不同domain的特性取消掉。
接上一个domain classifier,根据feature判断这个feature来自哪个domain。
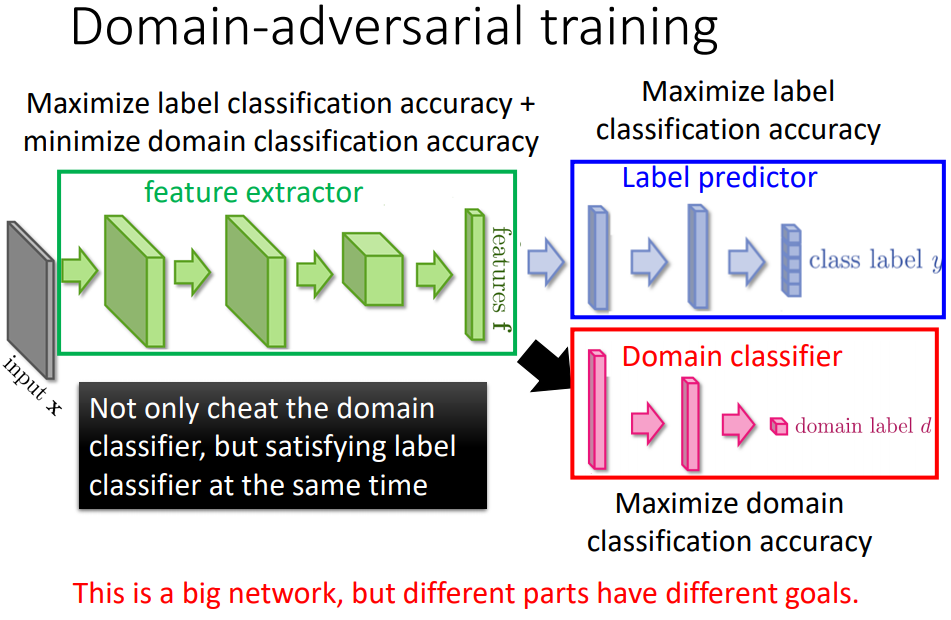
特征抽取不仅要骗过domain classifier还要同时满足label predictor的需求。
消除domain的特性,保留digit的特性。
蓝色部分目标是把class正确率做得越高越好,红色部分要正确predict一个image属于哪一个domain,特征抽取是同时想要improve label preditor的accuracy,又要minimize domainclassifier的accuracy。
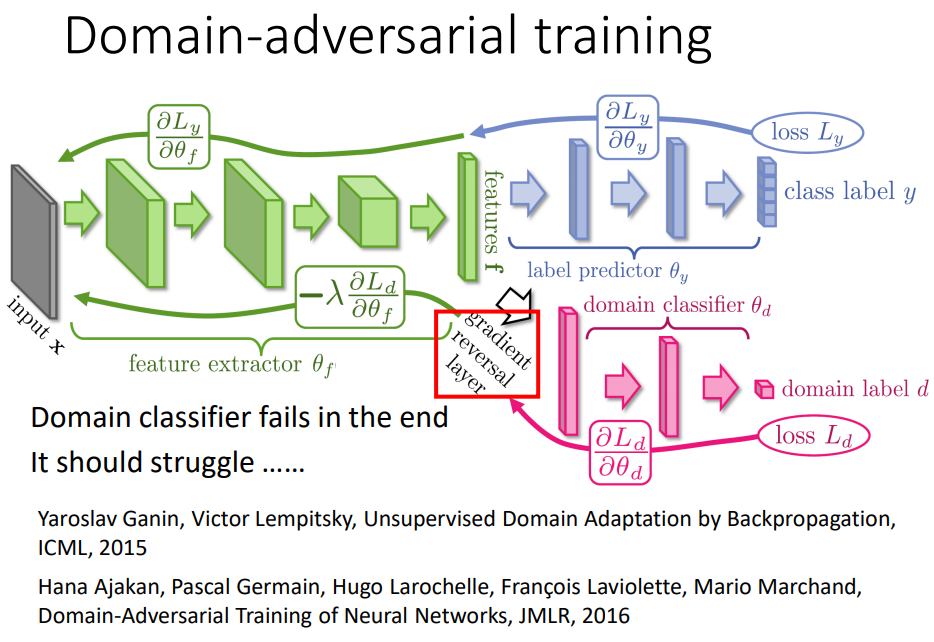
加一个gradient reversal layer:在计算back propagation的back path时,domain classifier传给feature抽取什么样的value都要加上负号,故意做和domain classifier要求相反的事情,最终一定会混淆掉来自哪个domain。
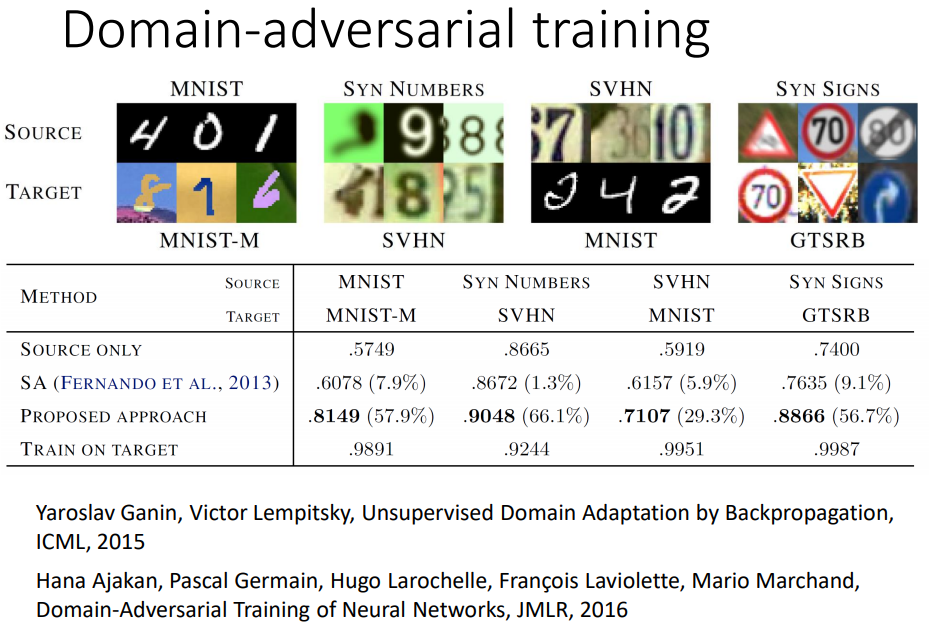
五、zero-shot learning
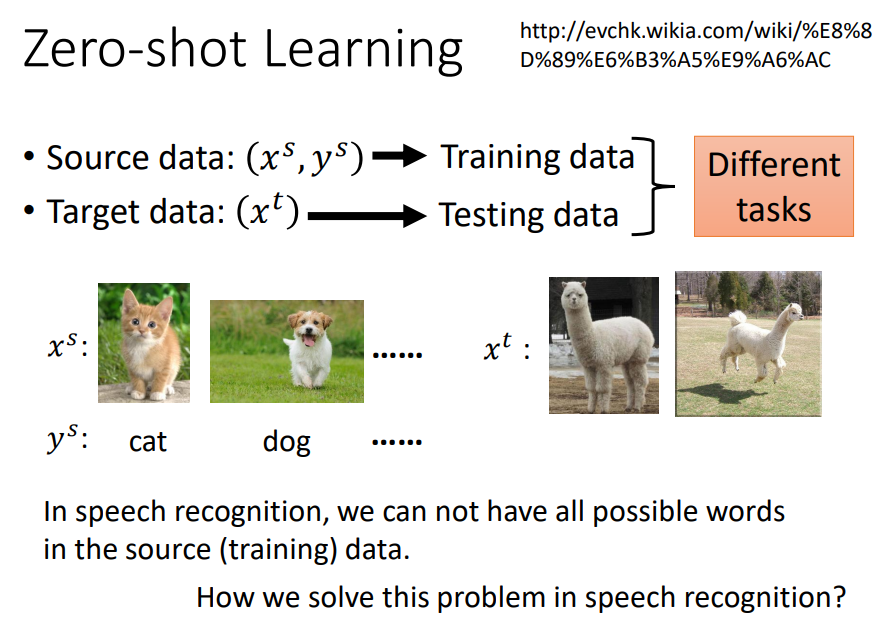
在语音辨识中,辨识的单位不是word而是phoneme,做一个phoneme与文字对应的表,只要辨识出phoneme再去查表就好,就算有一些word没有出现在training data,也可以处理这个问题。
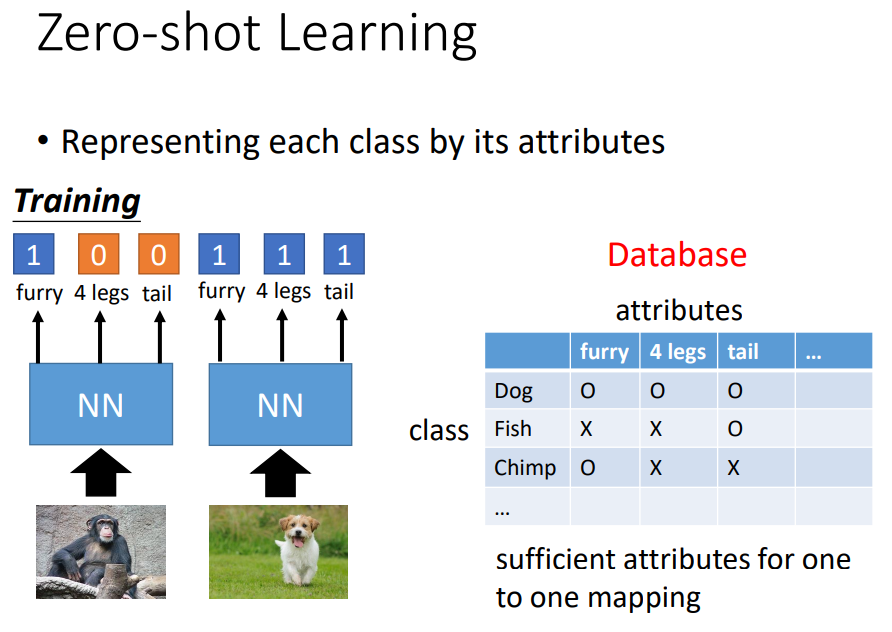

在影响中,把每个class用它的attribute来表示,也就是有一个database,其中有所有不同可能的object和它的特性,然后training时只需要去辨识每一张image具备什么样的attribute。
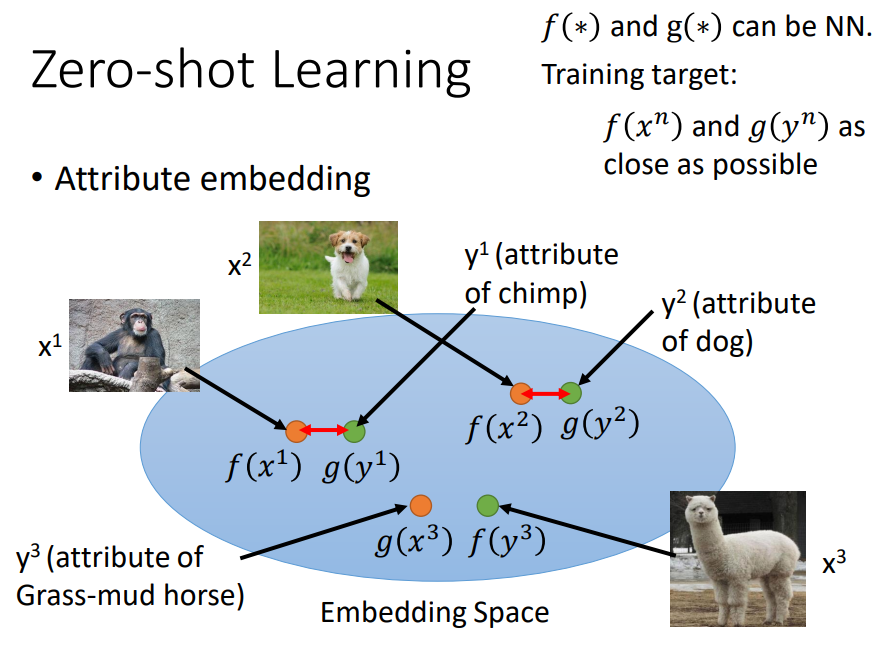
image和attribute都可以描述成vector,我们想把它们投影到同一个空间(降维),通过不同function分别变成embedding space上的vector。
希望找到的f和g使得投影后的vector越接近越好。

最小化f和g的距离会有问题,只会学习到把所有不同的x和y都投影到同一点,这样就结束了。
还要考虑x和另外一个y不是同一个pair,距离应该被拉大。
从0和式子里面选最大的,k是一个自己define的constant。
f和g的内积的值大于不是yn的y中最接近的一个,与它相比还是多一个k,也就是大过所有其它的y和x的内积。
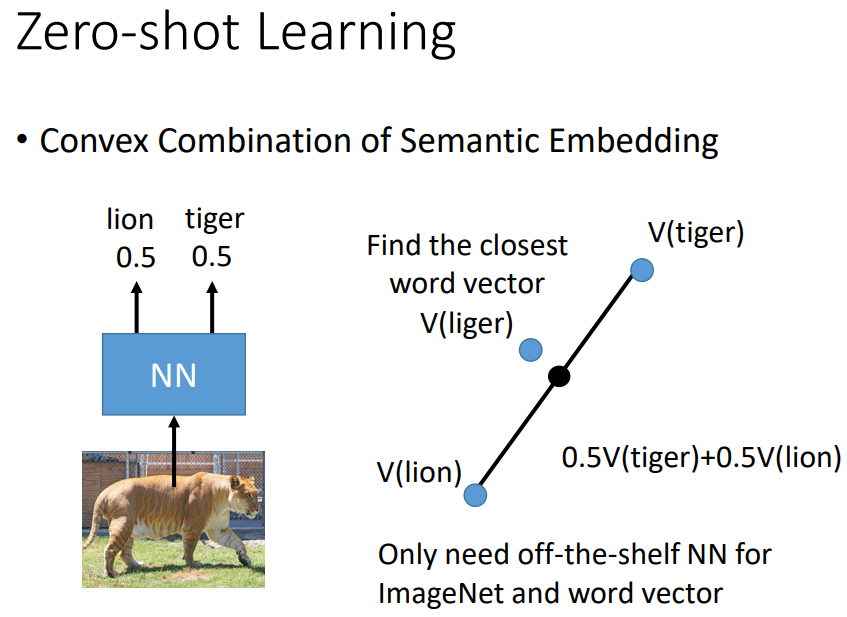
一比一混合,找哪个word vector与混合以后的结果最接近。
六、self-taught learning/clustering