


一、半监督学习
1、定义

unlabeled的数量远大于labeled的数量。
半监督学习分为直推学习(用了训练集的feature)和归纳学习(手上没有测试集)。
人类也一直在做半监督学习。


没有标签的数据(灰色点)的分布会影响划分。半监督学习有没有用取决于假设是否符合实际。
2、生成模型中的半监督学习

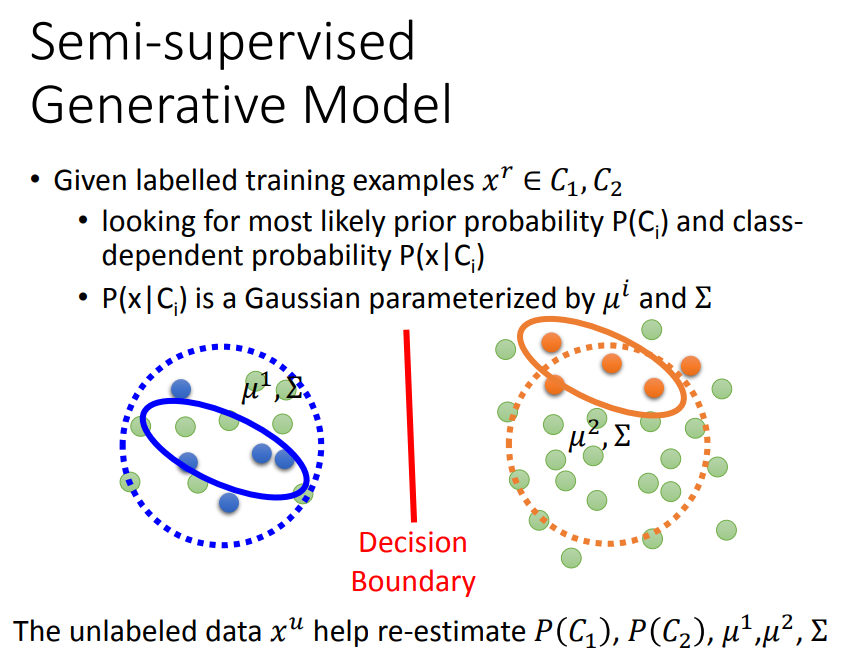
无标签数据会影响对先验概率的μ和Σ的估测,进一步影响分布的式子,影响boundary。

一、E step:初始化一组参数,然后可以估算每一笔无标签数据属于c1的几率。
二、M step:更新参数。不考虑无标签数据时,直接计算N1/N。当考虑了无标签数据,加上无标签数据是c1的概率的和。
三、计算μ1时除了计算mean,还要对c1的先验概率做weighted sum,然后再除掉所有weight的和得到μ。
理论上方法收敛,但初始值会影响结果。

无标签数据出现的几率为c1产生这笔数据的几率加c2产生它的几率。
然后最大化这个式子,这个式子不是convex的,要用EM算法解。
3、低密度分离假设(LDS)

基于低密度分离假设,在两个类之间有明显的分界。

先从带标签的数据训练一个模型f*,然后引用到无标签数据得出预测值yu,然后拿出(怎么拿自行设计)一些加到数据集中一起训练,有了更多的label data可以再去train model。
这个方法对regression无效。
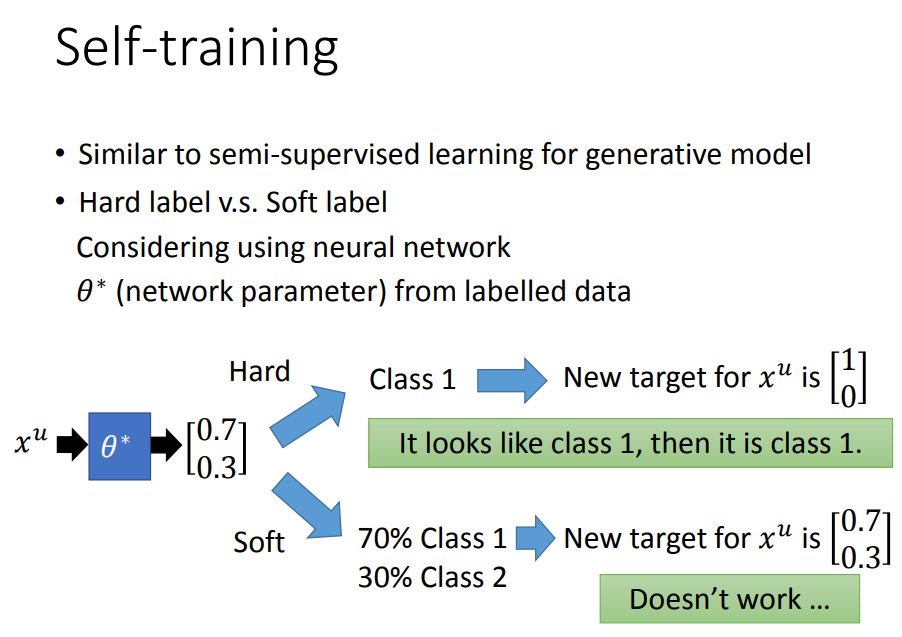
这个方法与前面讲的生成模型中的半监督很像,但是这里是hard label,前面是soft label。
假设用的是神经网络,从标签数据中得到一组参数θ*,现在有一笔无标签数据,根据θ*分为两类,属于c1几率0.7,属于c2几率0.3,分别以软硬两种方法表示。
soft label是没有用的,因为还是0.7 0.3,同样的参数就可以做到同样的事情。用hard label就是应用了低密度分离的概念。

如果输出是一个分布,不限制一定要是c1 c2,我们只假设输出的分布一定要很集中(如果在每个类分布很均匀就不好 如左下图)。
用一个数值entropy来估计这个分布是否集中:y表示对第m个class的几率,与它的ln相乘再sum。entropy要越小越好。
这样就可以重新设计loss function:cross entropy + entropy,因为很像正则化,所以叫做entropy-based regularization。
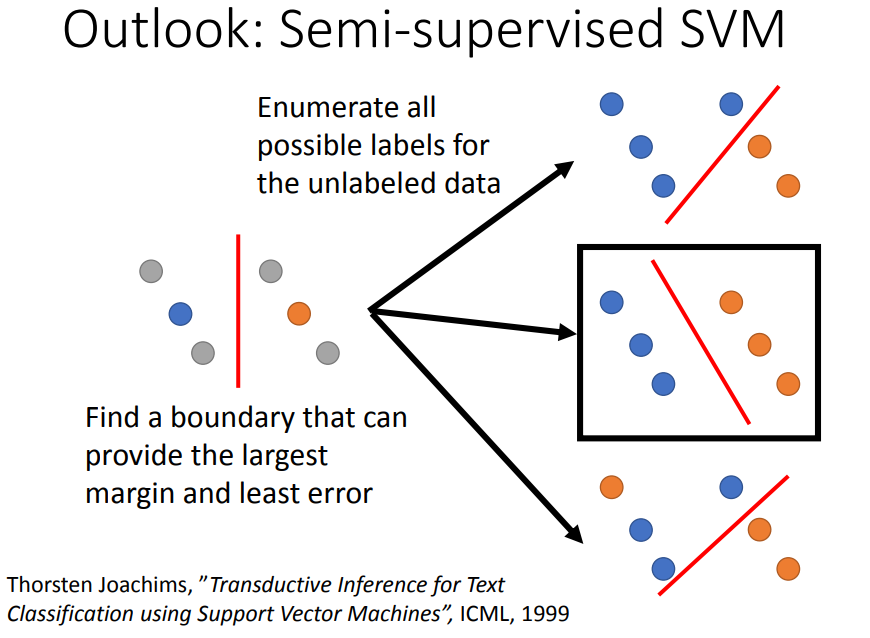
SVM:找到一个边界有最大的margin和最小的error。
半监督SVM:穷举所有可能的label,再看哪个可能性可以让margin最大error最小。
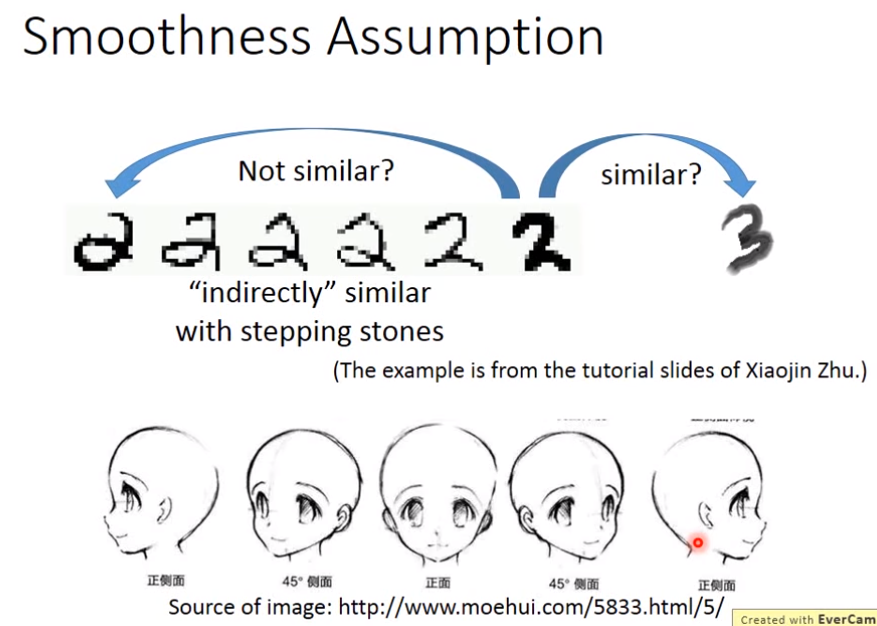
4、平滑性假设

精神:近朱者赤、近墨者黑
如果x是相似的那么它们的y也相似,更准确的说它们在同一个高密度区域很接近,而不仅是距离接近。

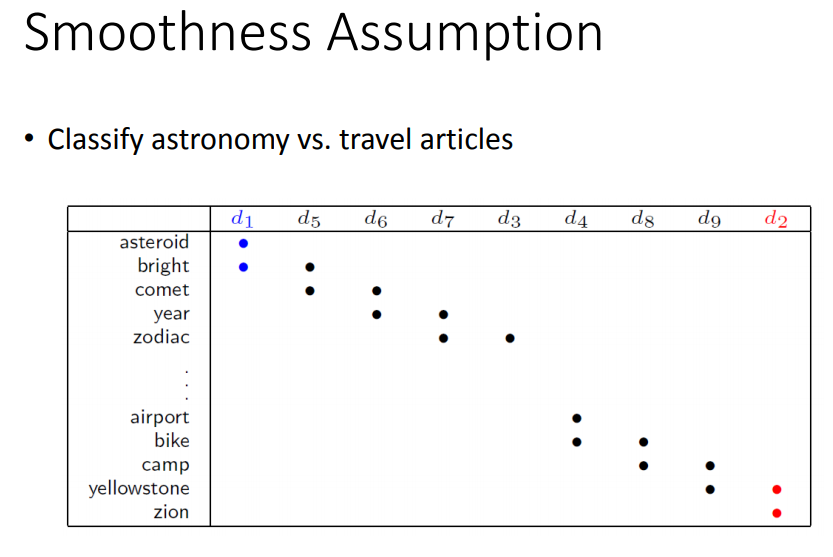
文献分类:天文学和旅游的文章。由于世界上的单词很多,一篇文章中的词汇就很稀疏,两篇文章中间重复单词的比例很少,
如果能收集到够多的无标签数据,可以从d1和d5像d5和d6像一路propagate过去。
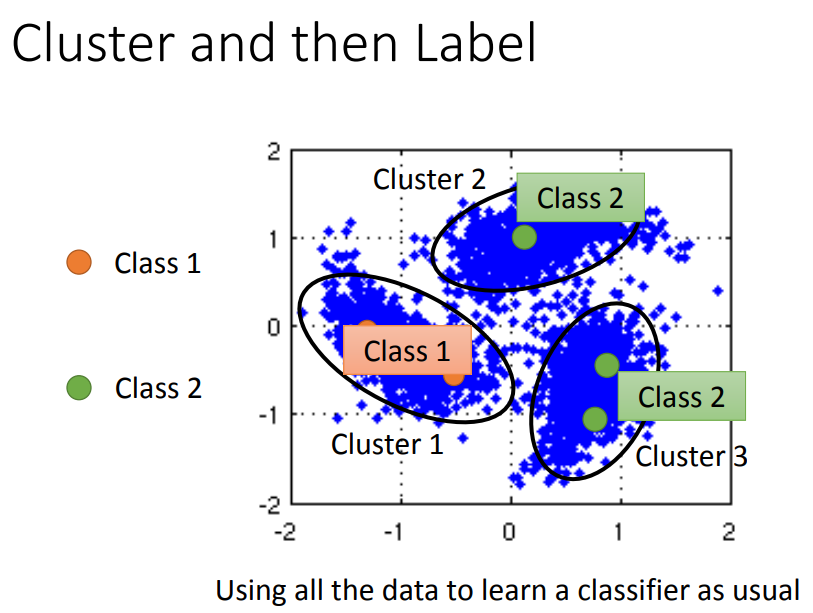
聚类然后label。但这种方法cluster要很强。
另外一个方法是引入图结构:
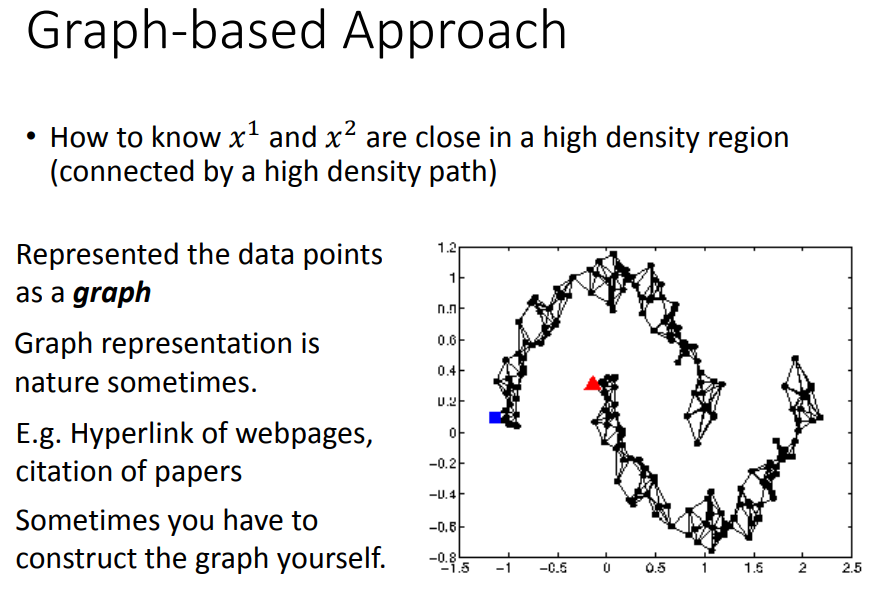
如果两个点在图上是相连的,他们就是同一个class。
怎么建立图:网页分类中网页间hyperlink,论文分类中论文之间引用关系。

但更多时候需要自己想办法建图:
定义两个对象之间相似度的计算方法(如基于像素计算相似度可能不太好,基于自编码器抽出来的特征算相似度表现可能比较好)
建图方法有很多,如k-近邻的图、e-neighborhood。
可以给边一些weight,weight和两个节点的相似度是成正比的。
比较好的一种相似度定义是RBM方法,用了exp可以使每个点之和同一个密集区域的点连,和其它区域的不连。
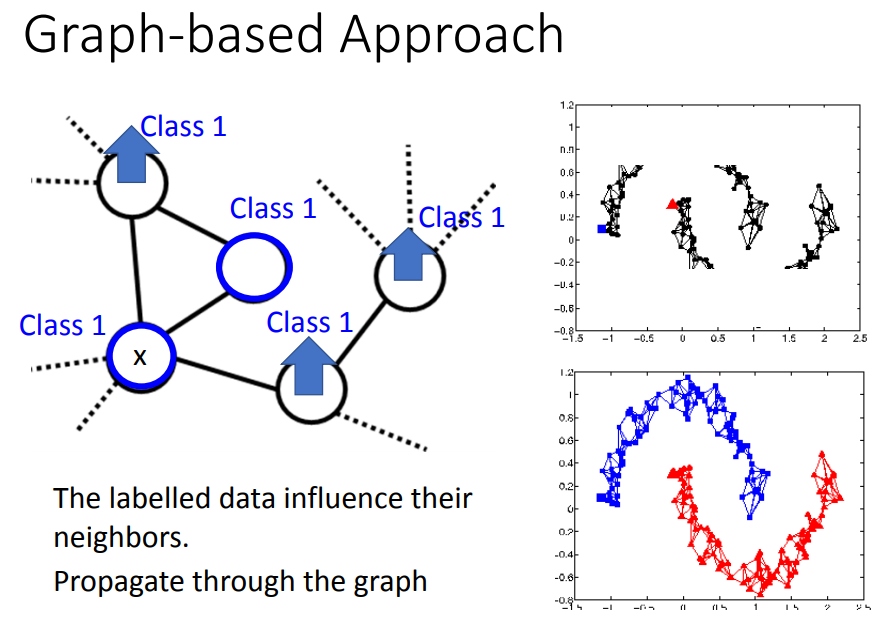
已知图上一些data属于class1,则与之相连的data也属于class1的几率也会上升,并且沿着图传递。
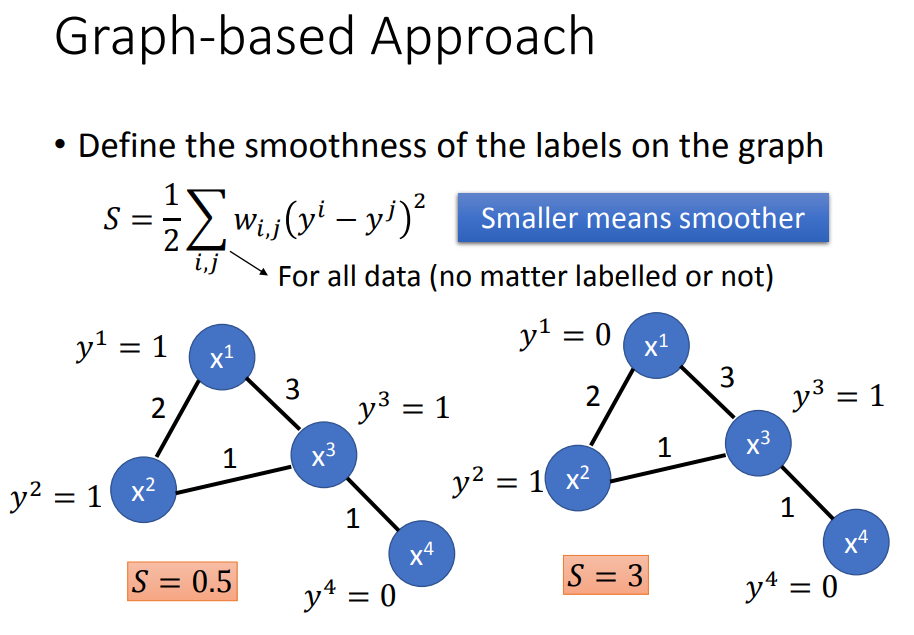
在图结构上定义一个标签的smoothness:两两相减,平方乘以权重,相加再除以二。smoothness越小越好。
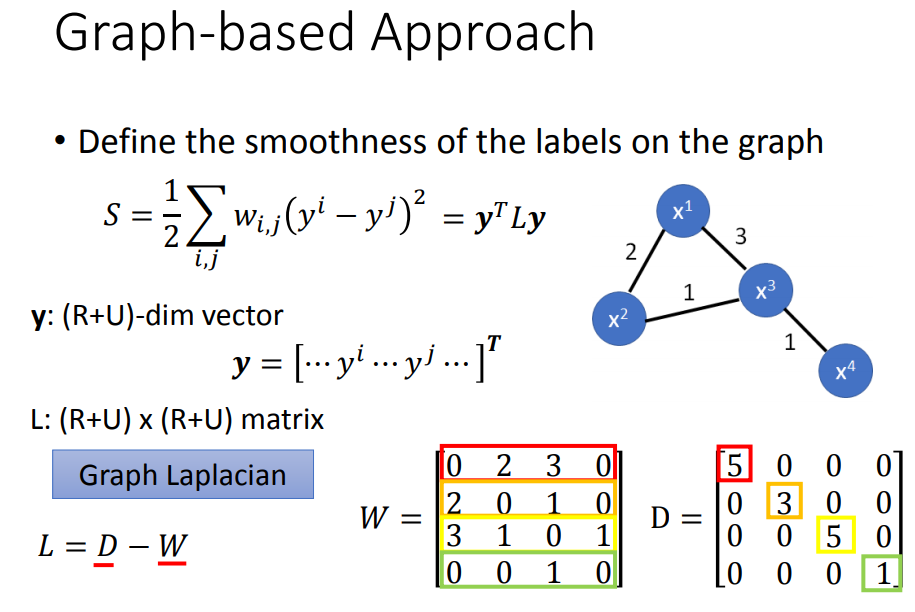
这个L可以化简成矩阵相减的形式。
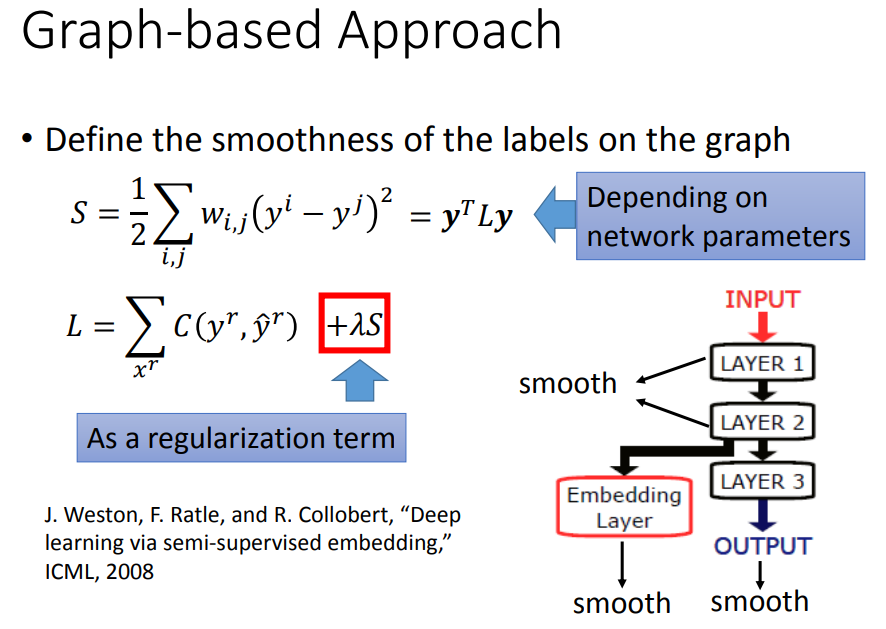
于是损失函数就可以加上这一项,以获得更低的smoothness,这也相当于做正则化。
不一定要算output的smoothness,深度网络也可以算某个隐藏层的smoothness。
5、更好的表示

化繁为简,看透本质。
