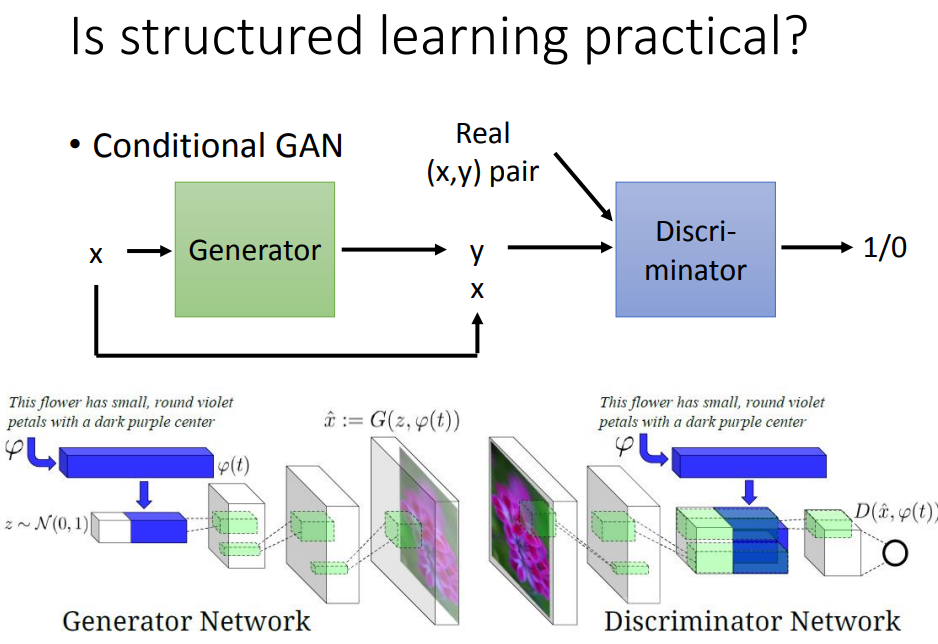
一、问题提出
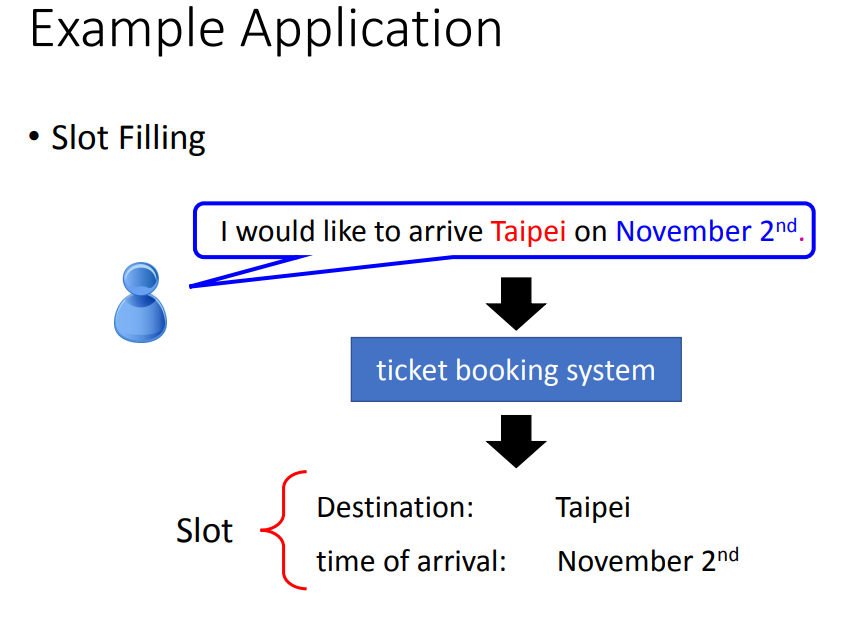
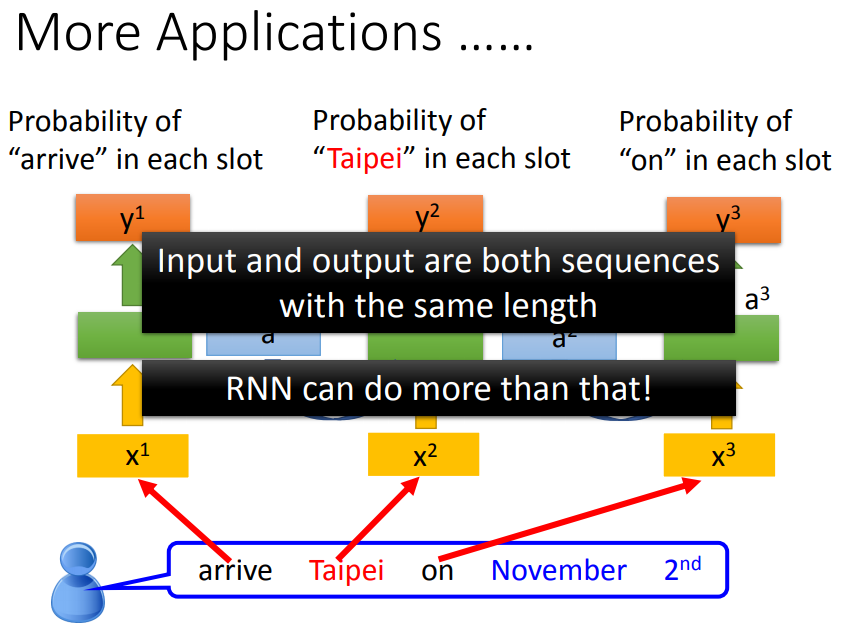
slot filling(槽填充):智慧客服、智慧订票系统中往往需要自动将词汇与slot对应。
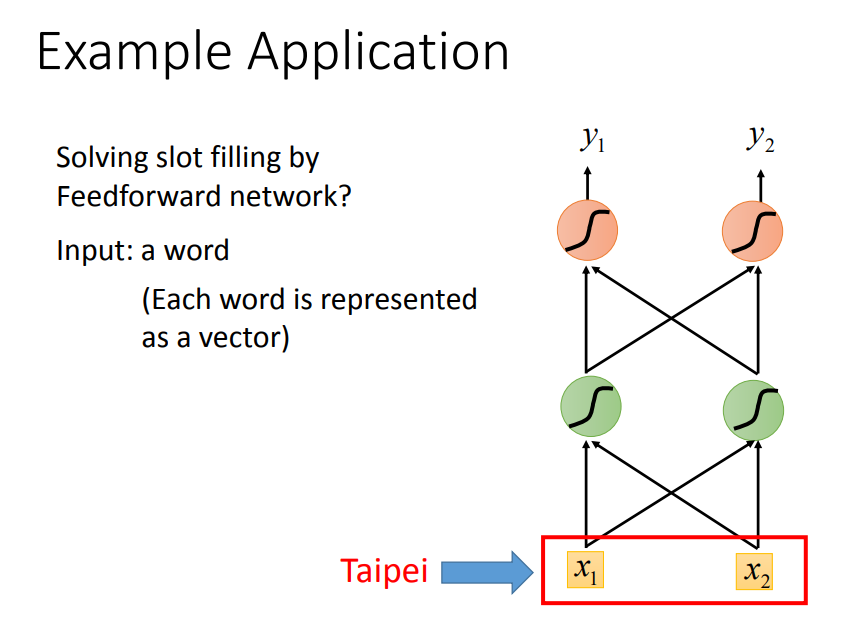

把词汇用向量表示。

多加一个other维度,不在词典中就归类到other。
也可以用一个词汇的字母的n-gram,如apple中包含app、ppl、ple。
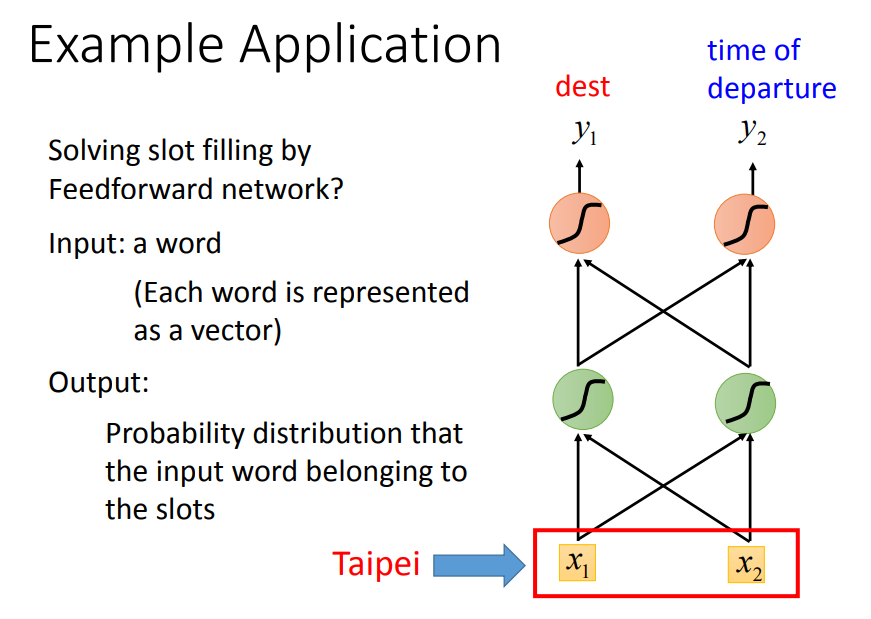
把这个vector放进network,得到的输出是input属于每个slot的几率。
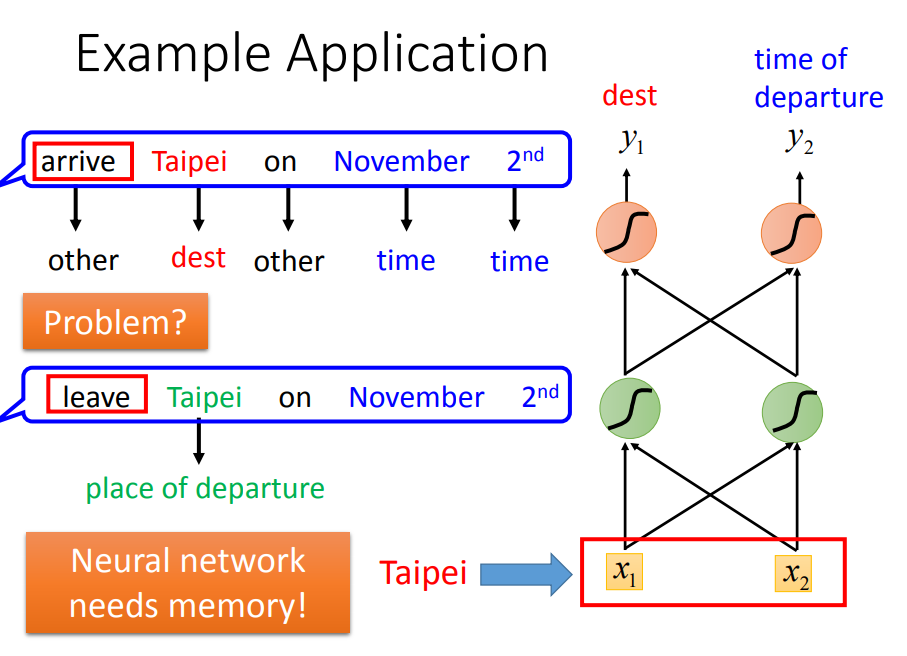
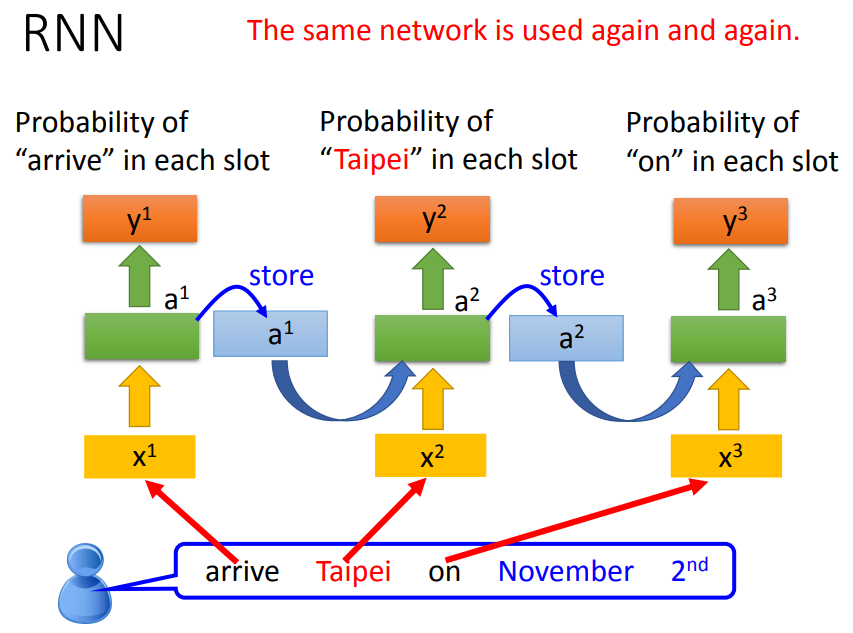
第二句话输出的taipei是出发地而不是目的地。我们希望network能记得上下文,根据不同的上下文产生不同的output。
二、RNN
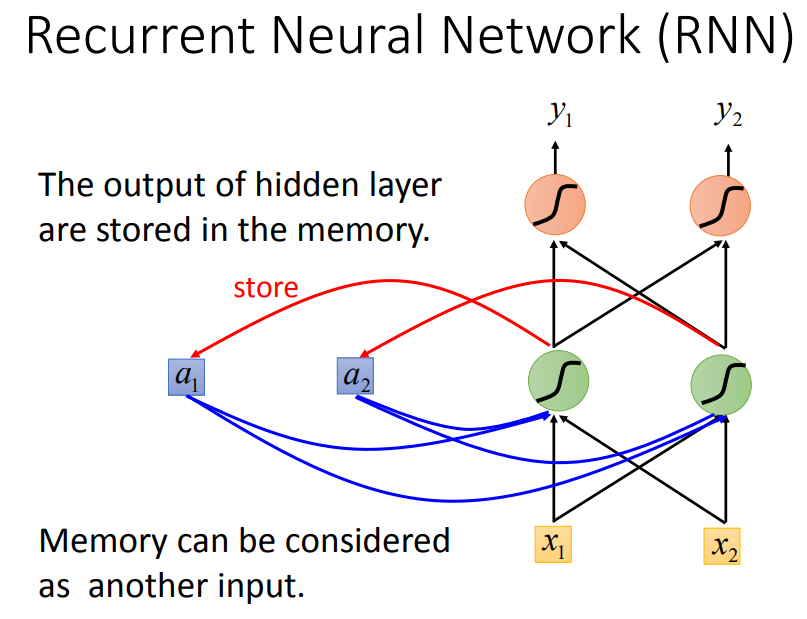
每次隐藏层的neural产生output时,都会存到memory中,下一次如果有input,这些neural不会只考虑input,还会考虑存在memory中的值。
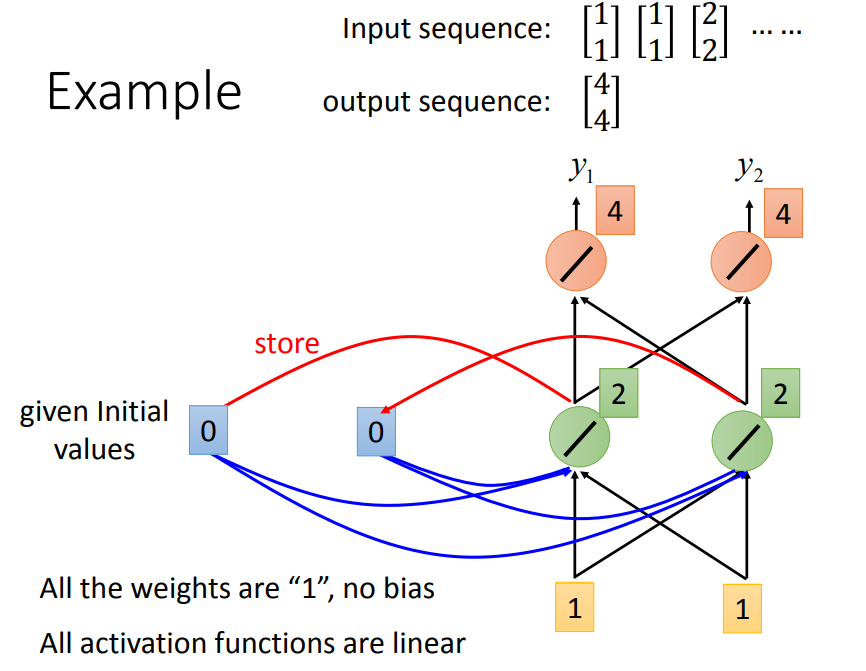
所有的weight都设为1,memory给起始值0 0,第一个1 1,输出2 2,2 2存到memory。
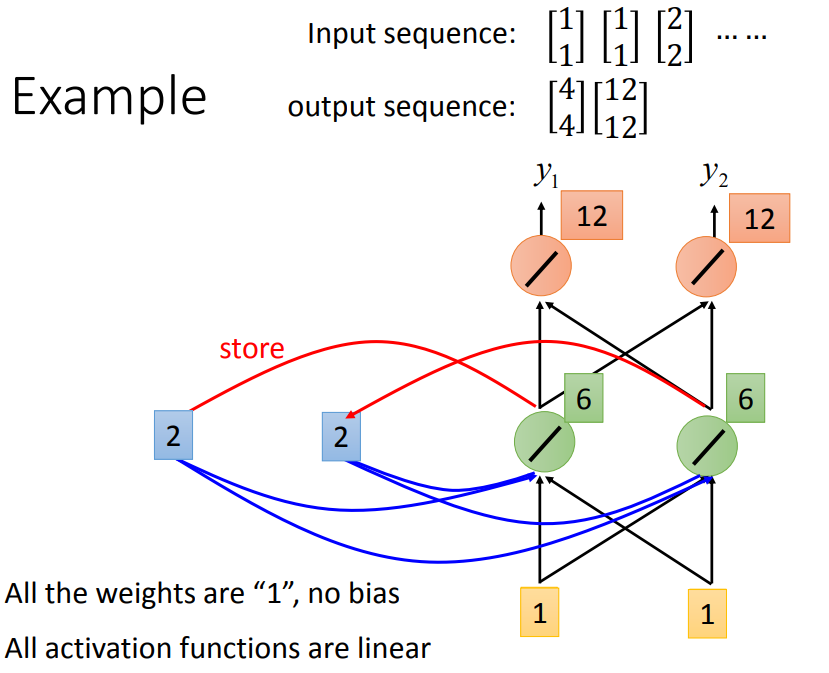
输入有四个1 1 2 2,输出12 12。
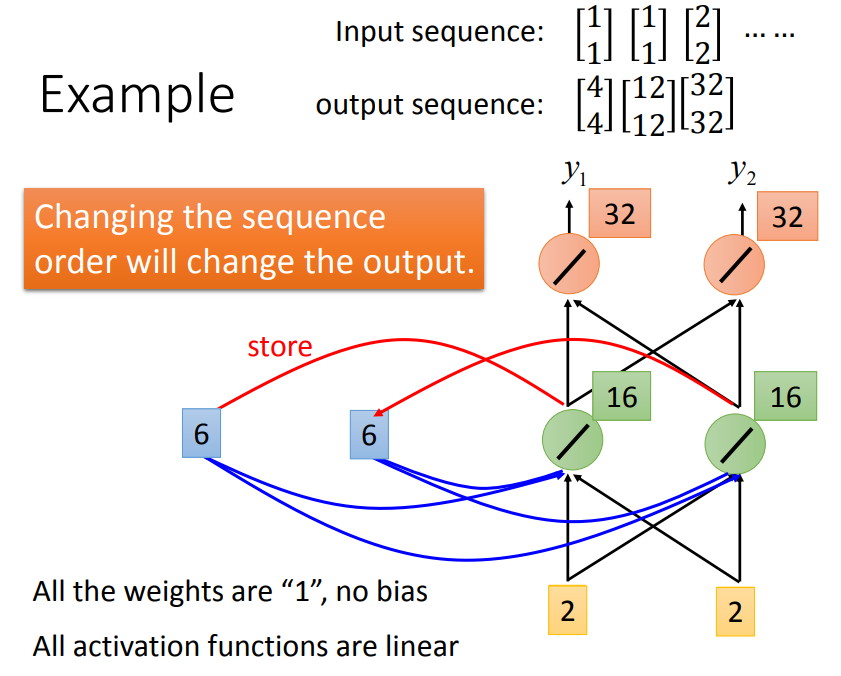
就算给一模一样的input,output也不一样,因为存在memory中的值不一样。
RNN会考虑input的顺序,调换顺序得到的结果不同。
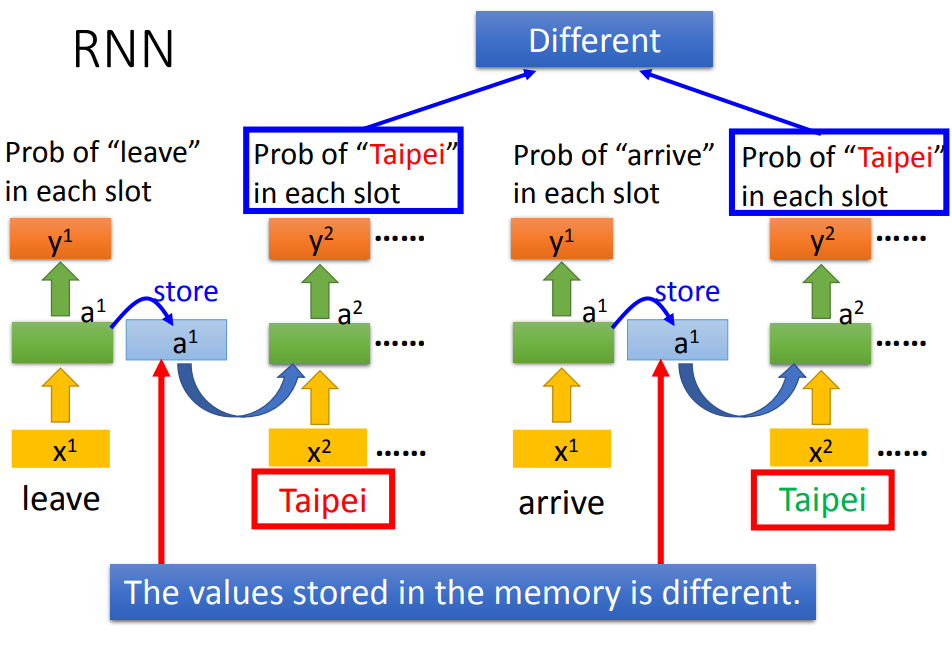
输入同样的词,得到不同的output。
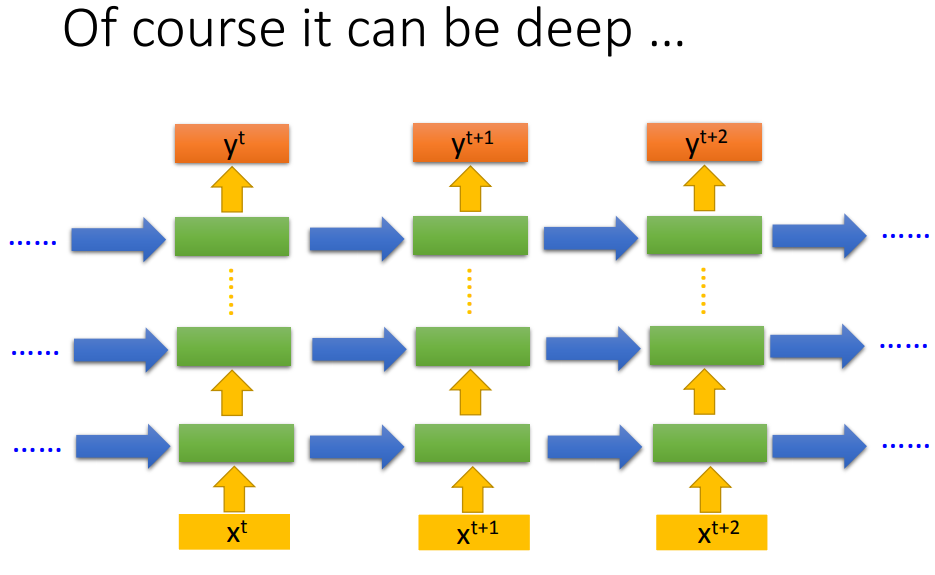
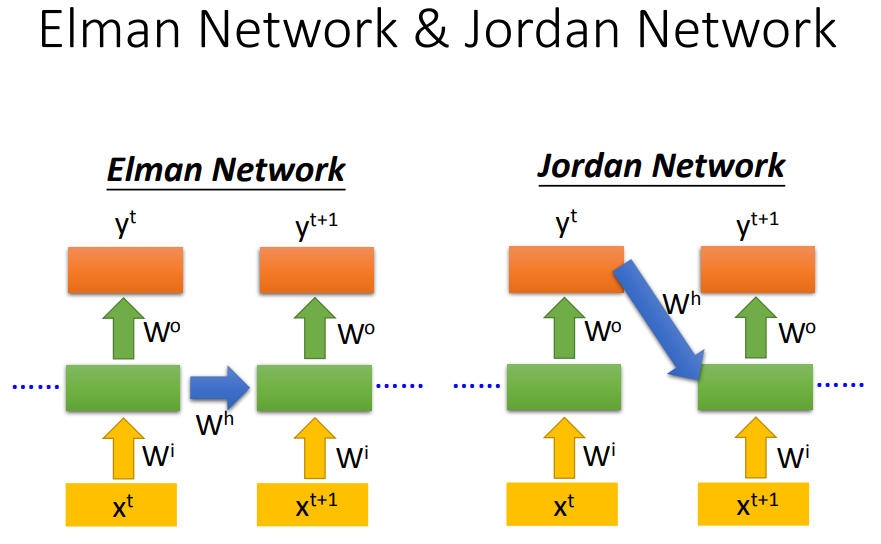
Jordan network可以得到比较好的performance,因为隐藏层没有target比较难控制。
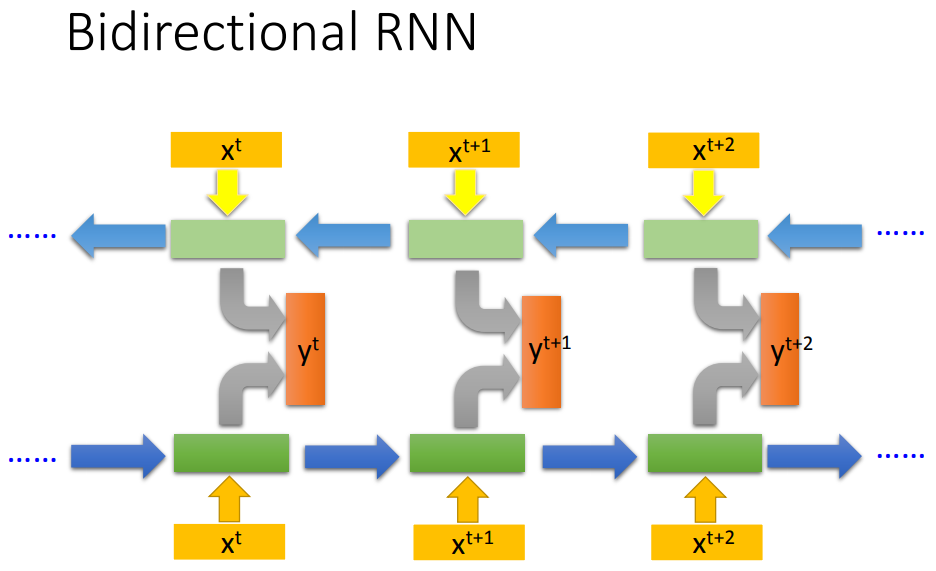
RNN还可以是双向的,好处是每个output都看过了整个input sequence。
三、LSTM
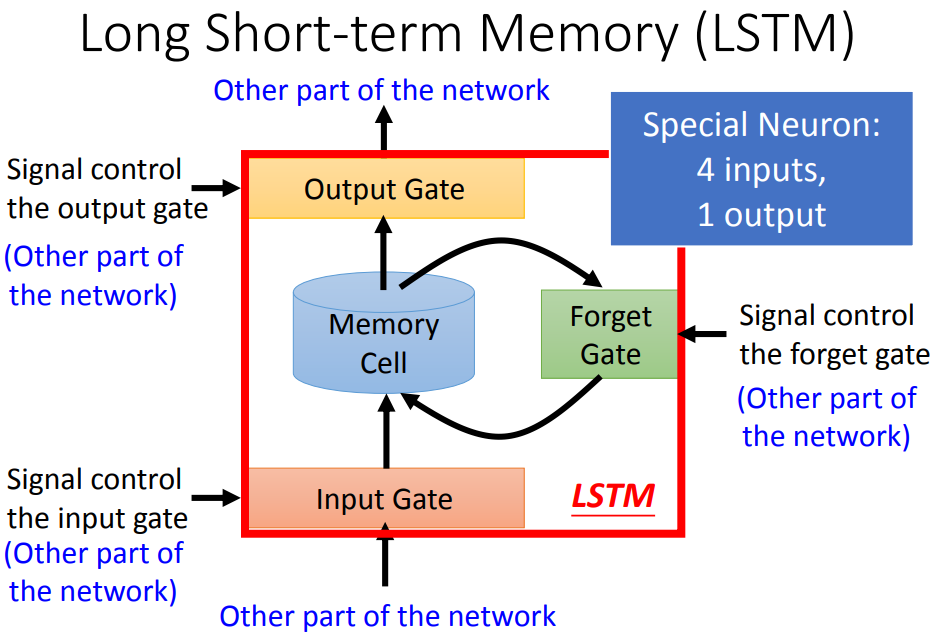
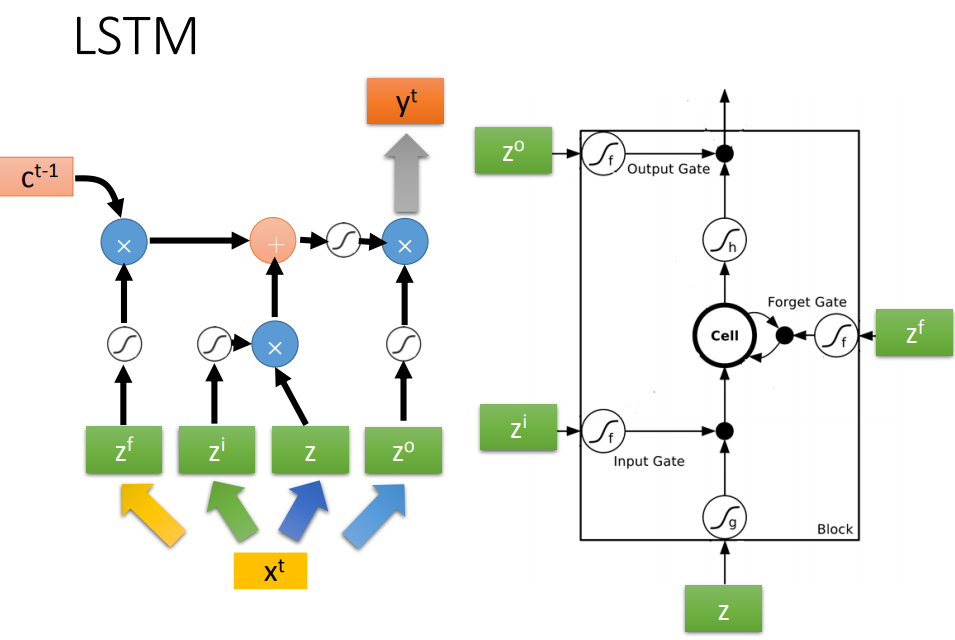
输入门打开时,其它neural才能把写入memory cell,什么时候打开关闭是network自己学的。
输出门决定neural能不能把值读出来,什么时候打开关闭也是network自己学的。
遗忘门决定什么时候把过去记得的东西忘掉(format),什么时候format也是network自己学的。
整个LSTM可以看成有四个input(想要存进去的值和操控三个门的信号),一个output。
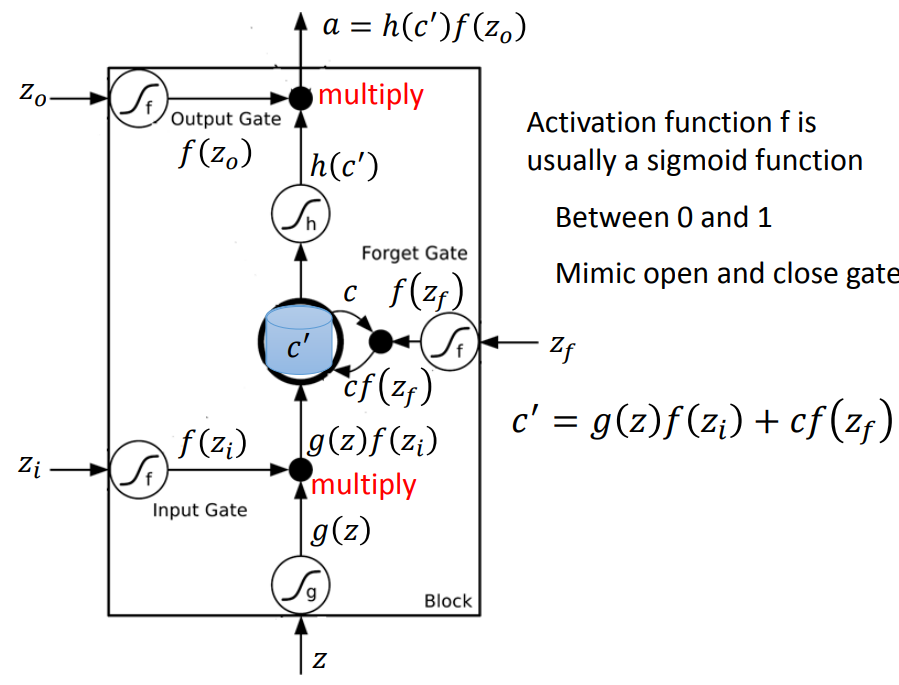
操控gate的z也是一个数值,通过sigmoid function(0-1)代表被门打开的程度。
输入的值z经过激活函数,再乘以输入门的信号值经过激活函数,g(z)f(zi)。
把存在memory中的值c,乘上f(zf),将两项相乘的结果加起来c'=g(z)f(zi)+cf(zf)。
c'就是新的存在memory中的值。
输出信号通过激活函数,再与h(c')相乘,得到输出a。
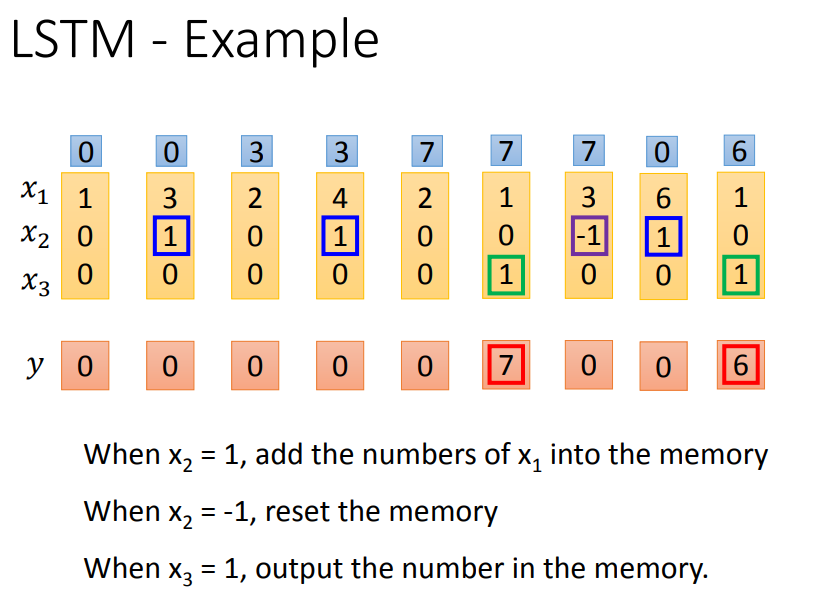
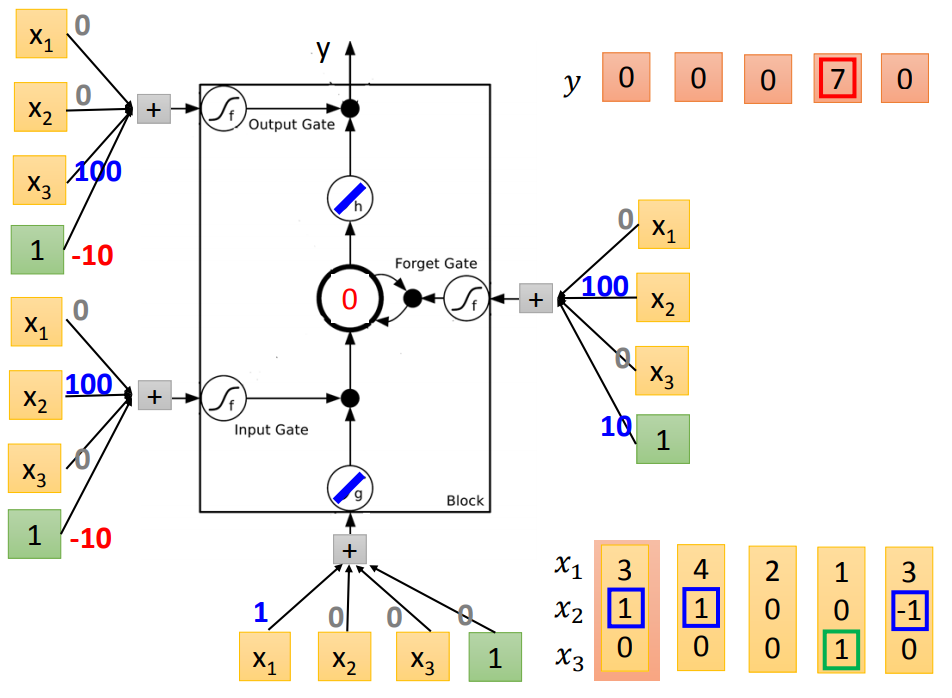
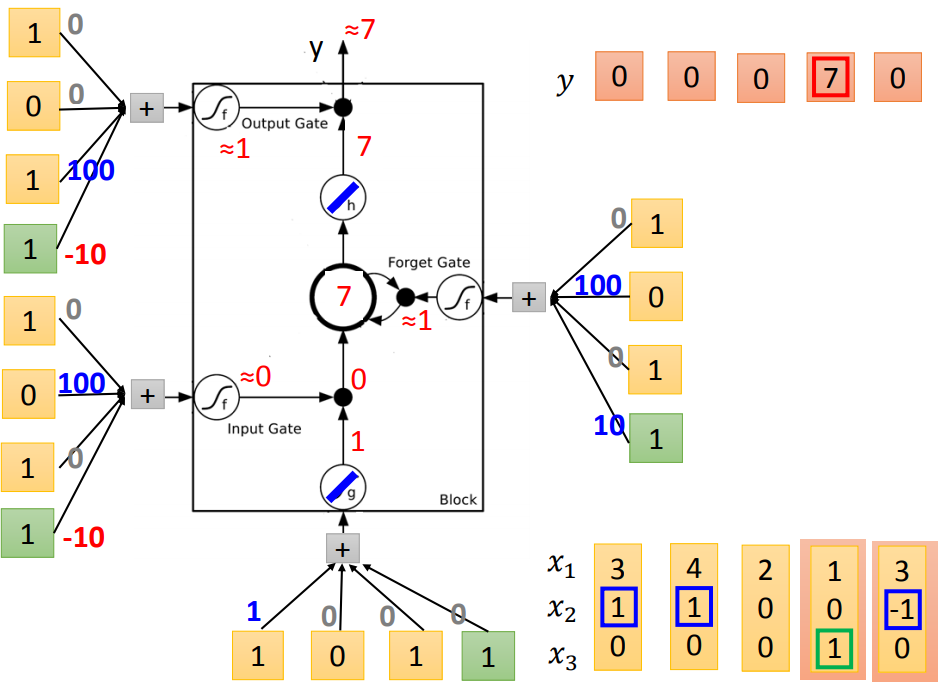
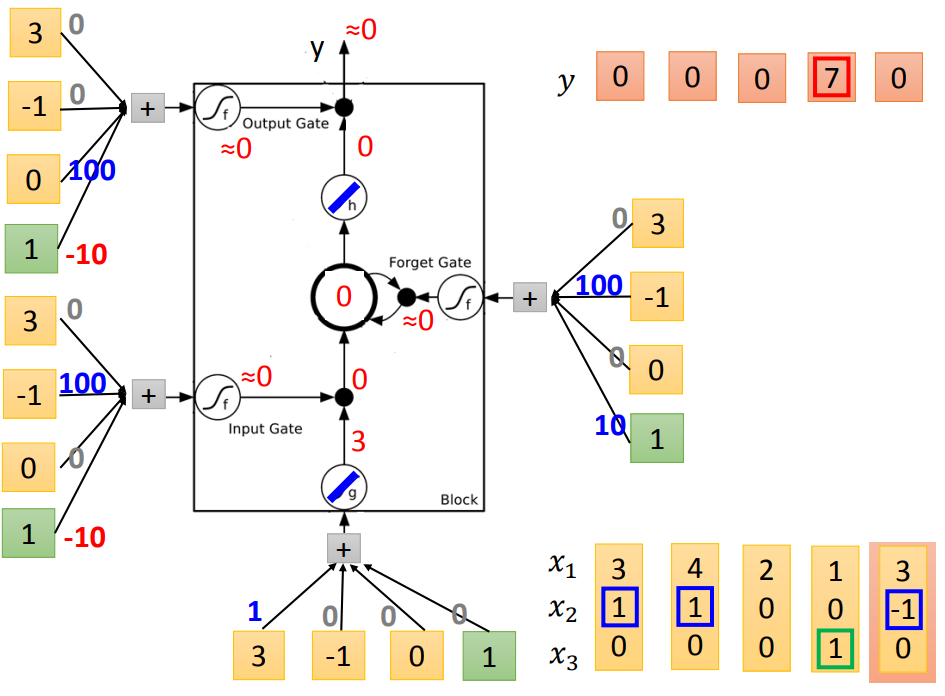
输入门平常是-10,x2=1时为100,打开输入门;
遗忘门平常是10,x2=-1时为-100,打开遗忘门;
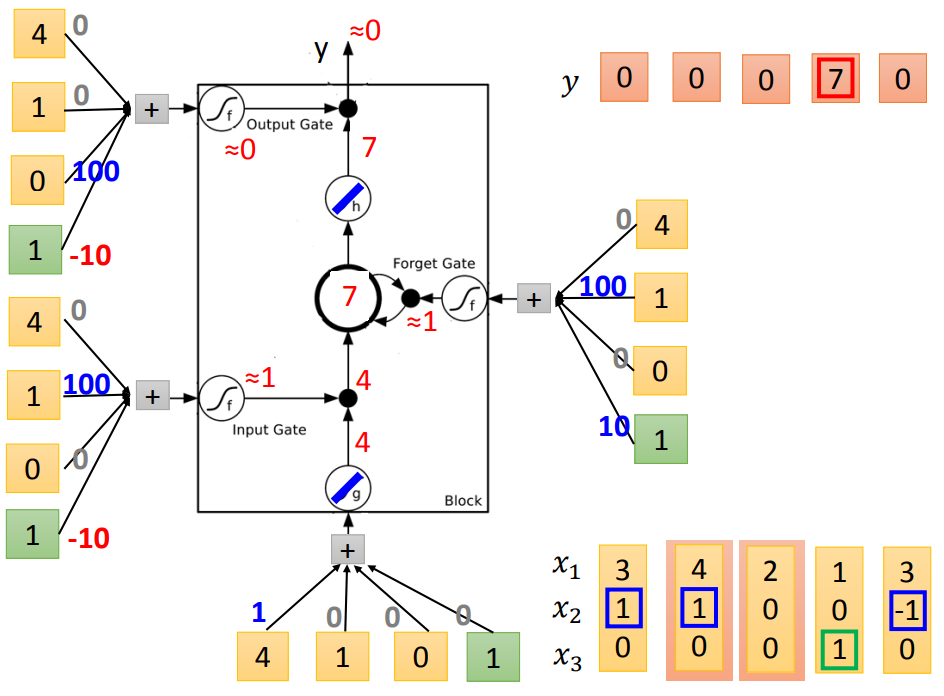
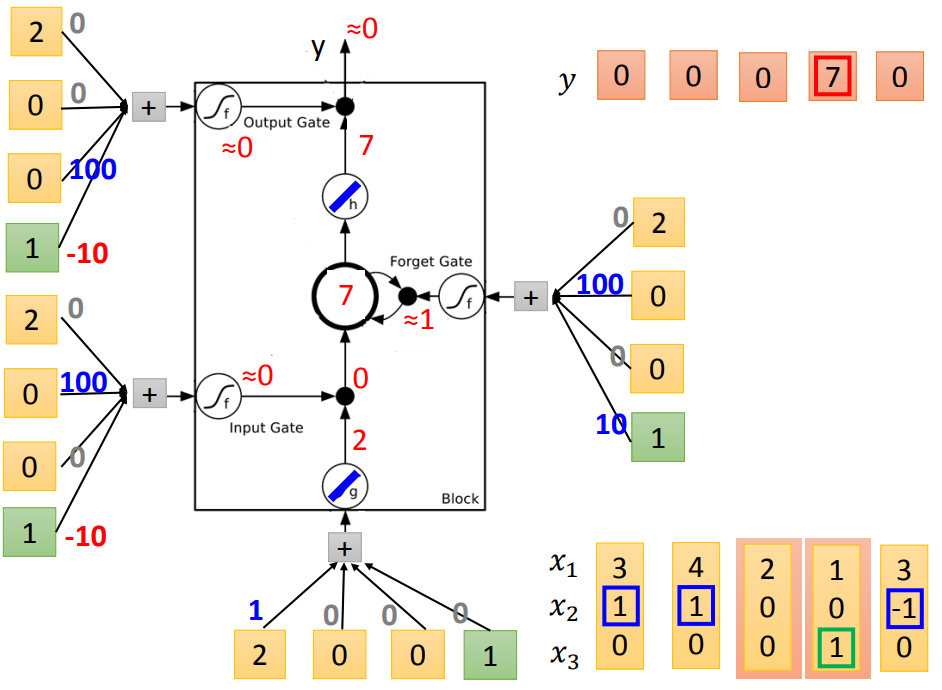
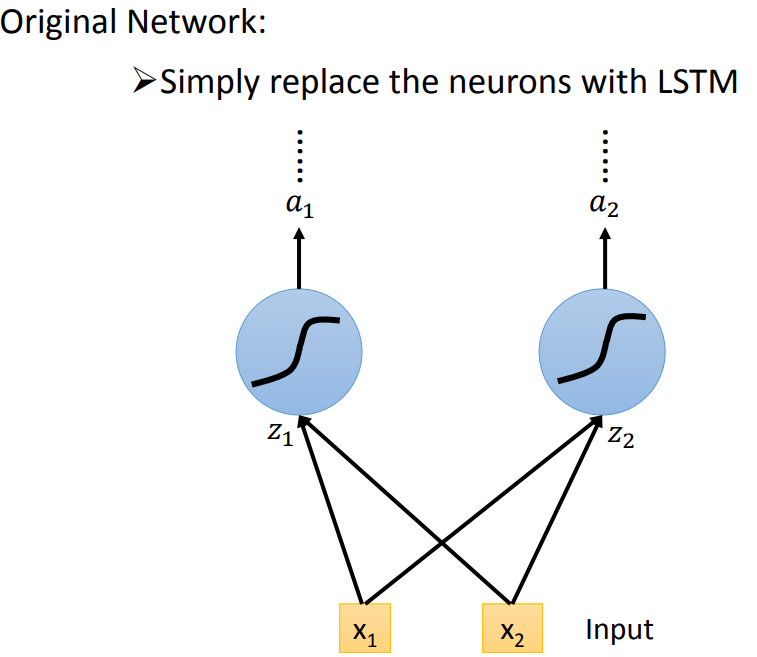
跟原来神经网络有什么关系呢?
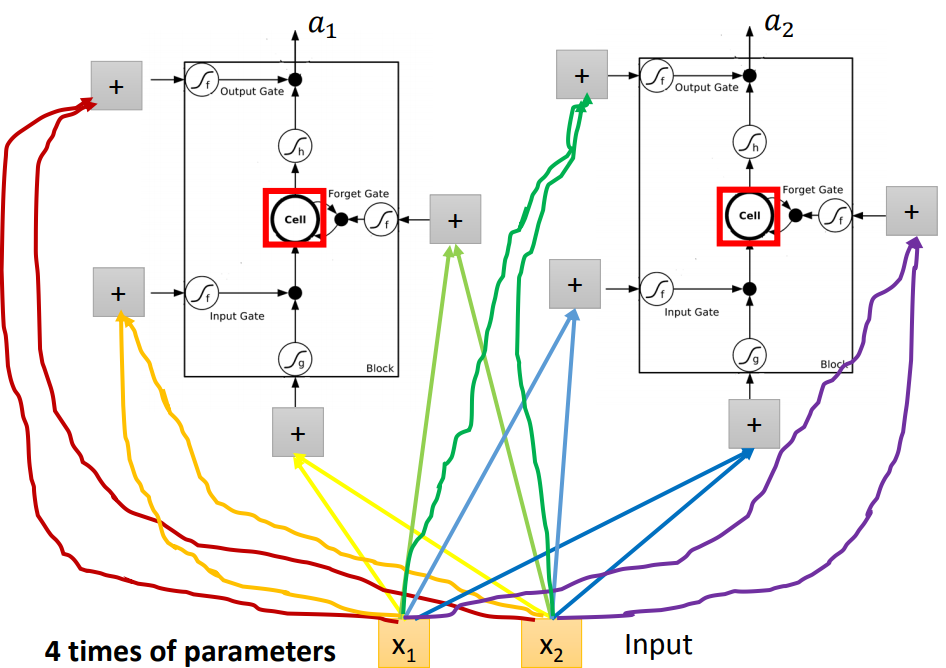
把memory cell想成一个neural,这个neural需要4个input,才能够产生一个output。
neural相同的情况下,LSTM需要的参数量是一般network的4倍。
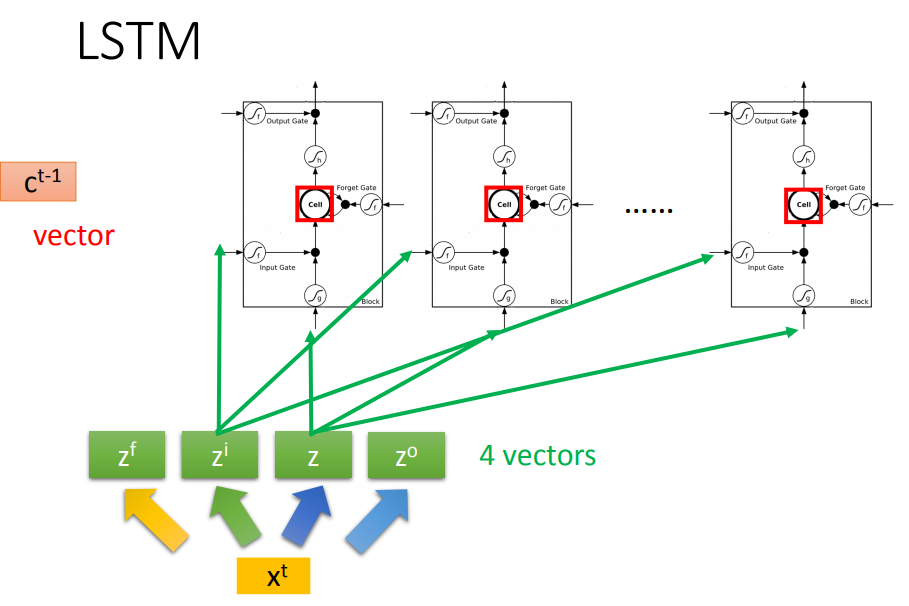
每个cell存了一个scalar,把这些scalar接起来就得到了一个vector,记作c^{t-1}。
在时间点t输入一个vector x^t,vector会乘上一个matrix变成z,vector z的每个维度表示操控每个LSTM的input。
同样也可以得到另外三个z,操控输入门、输出门、遗忘门。

这个计算过程反复进行。

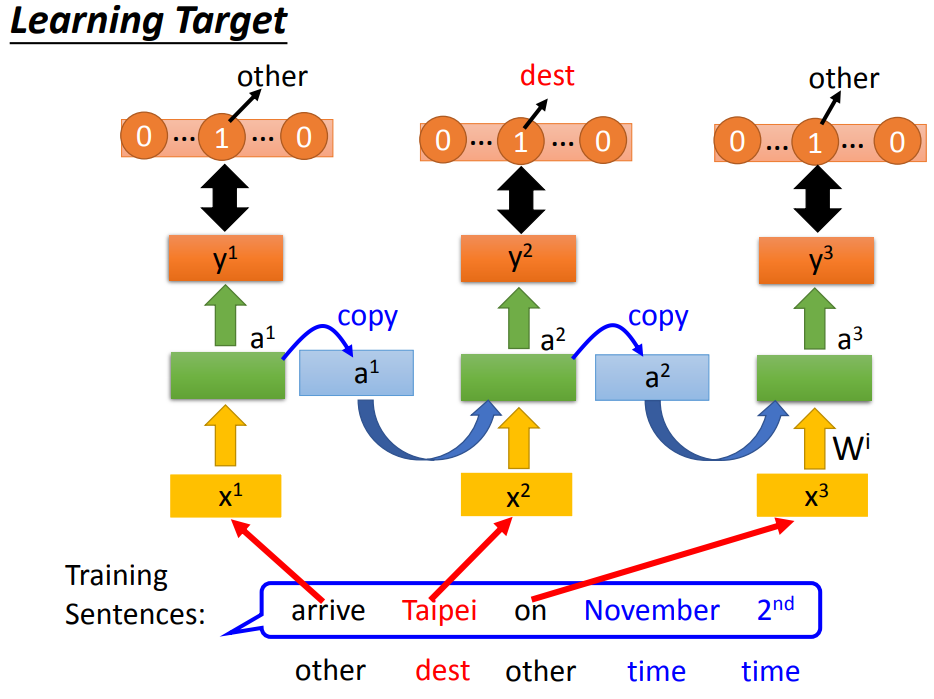
minimize 交叉熵计算损失。
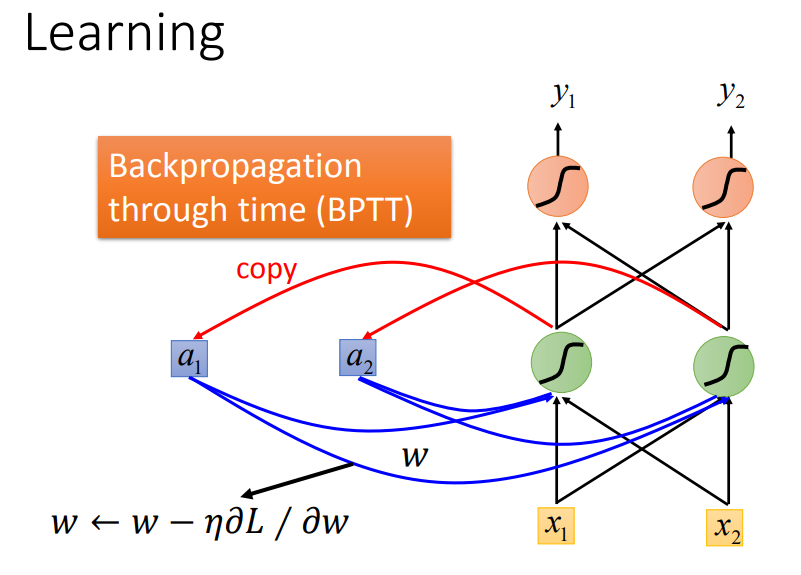
参数更新:梯度下降原理一样,为了提高计算效率使用反向传播的进阶版BPTT,考虑了时间信息。
四、RNN的问题

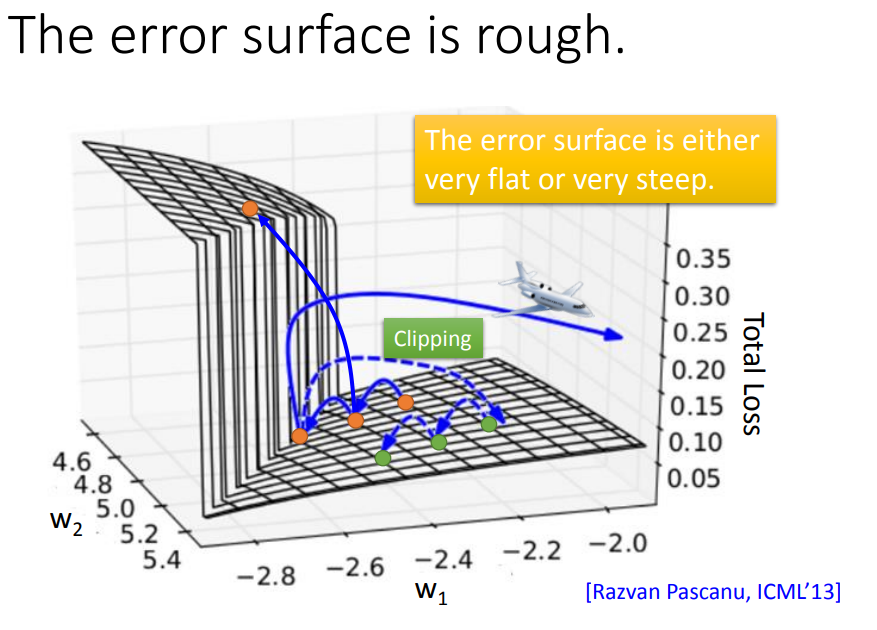
error surface会非常平坦或非常陡峭。clipiping:不让梯度大于某个值,防止踩到悬崖飞出去。
为什么RNN会有这种特性呢?问题不是出于激活函数,RNN的激活函数一般都用sigmoid,换成ReLU的话performance会变差。
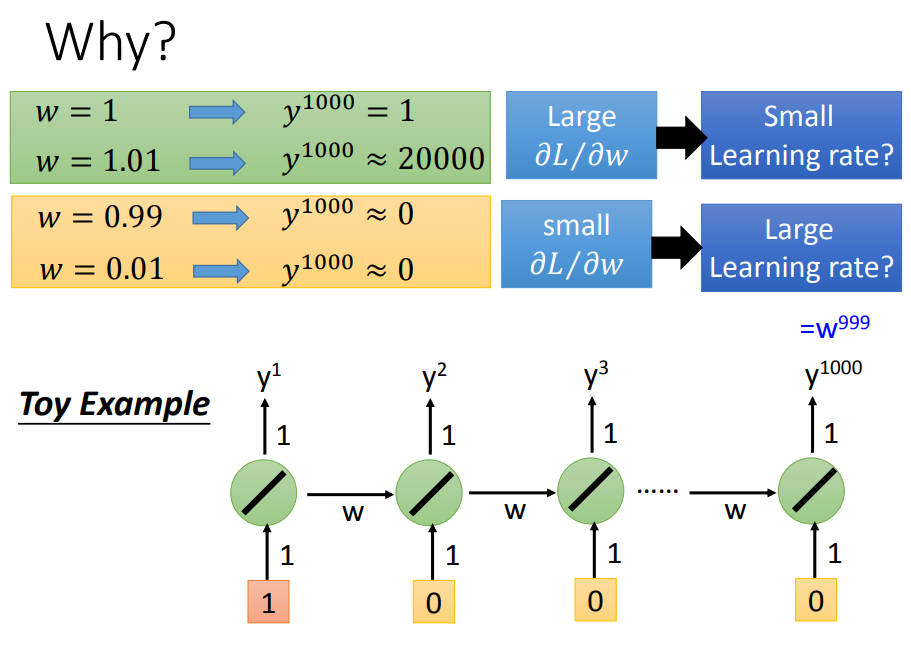
1输进去,得到的output是w^999。为了知道w的梯度变化,我们来试验改变w的值,可以发现w很小的变化对output影响很大。
RNN的问题在于同样的w在不同的时间点都被反复使用,w只要一有变化,有可能完全没有造成任何影响,也有可能造成很大影响。
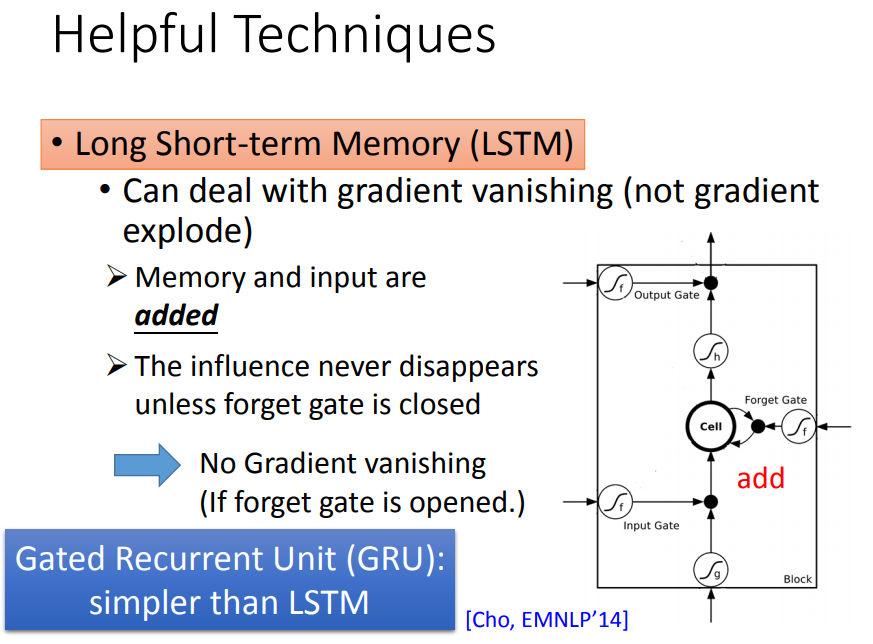
LSTM解决了梯度消失的问题,但是不能解决梯度爆炸的问题。
因为有遗忘门:memory和input是相加的,除非遗忘门决定要把memory中的值清洗,不然每次都只会有新的值加进来,不会让原来的值消失。
LSTM就是为了解决梯度消失的问题,遗忘门常被设特别大的阈值,确保多数情况是开启的,只有少数情况会被format。
另外一个用gate操控memory cell的是GRU,GRU的gate只有两个,需要的参数量少,所以也不容易overfitting。
还有一些其他的技术帮助解决梯度消失或者梯度爆炸的问题。
五、其他应用
5.1、情感分析、文章关键词
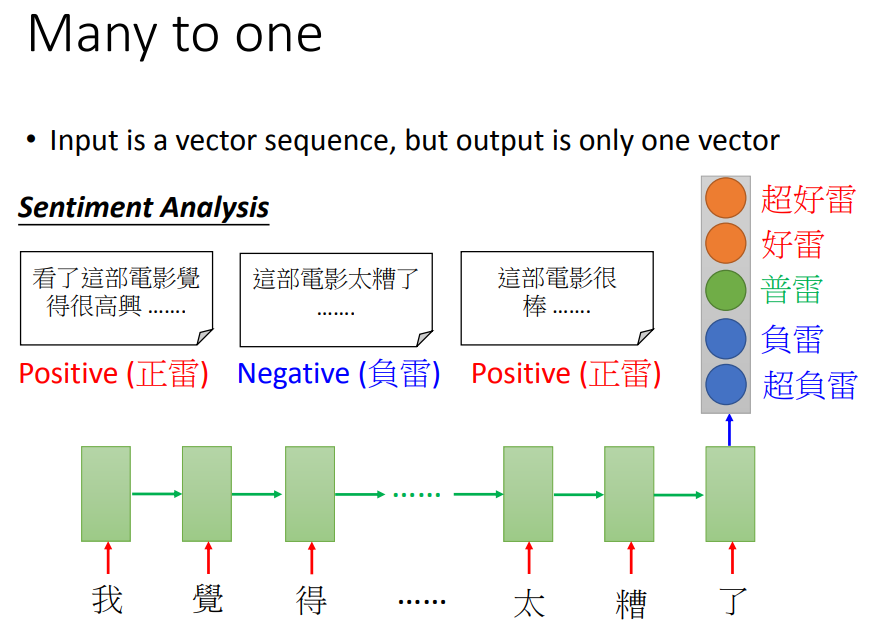
评论的正负情感分析:input是一个character sequence,在最后一个时间点output,再通过几个transform,得到结果vector。
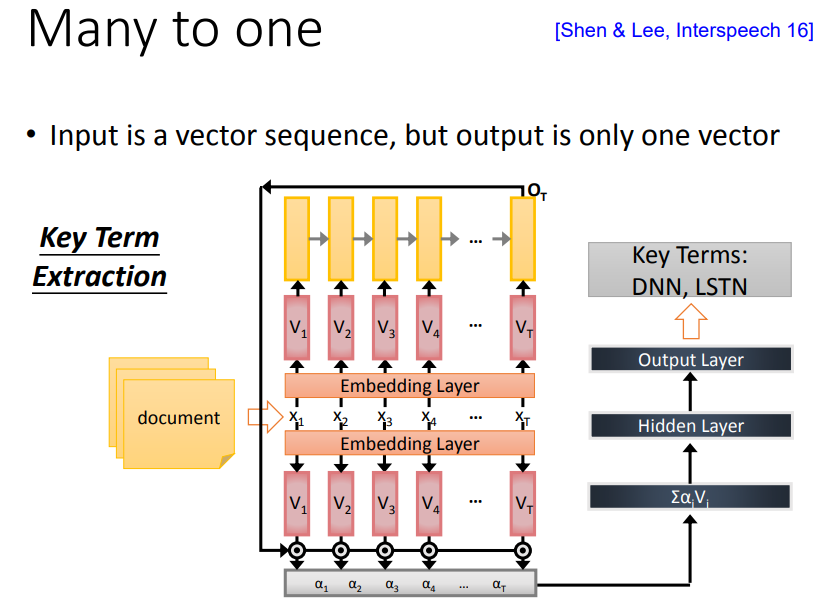
给机器看一篇文章,机器预测其中关键词:输入document words sequence,通过embedding layer,用RNN读一次,把出现在最后一个时间点的output拿过来做attention,再把重要的信息抽出来,丢进前馈网络,得到最后的output。
5.2、语音辨识
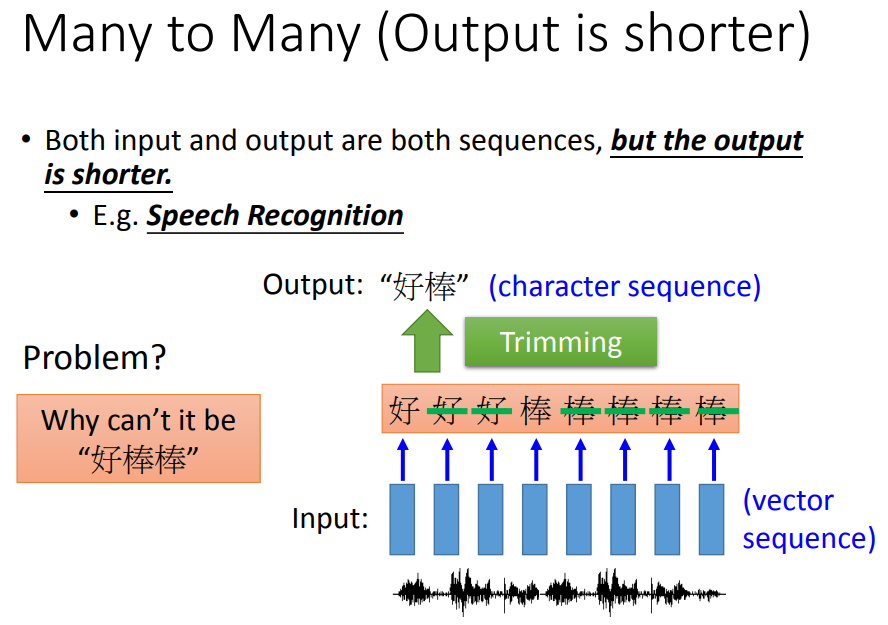
输出比输入短,如语音辨识:每个vector都输出一个字,然后再做trimming(去重)。但是这样不能把“好棒”和“好棒棒”分开。

CTC:多output一个null符号

不知道每个字对应哪几个frame,就穷举所有的情况,全部当做是正确的。
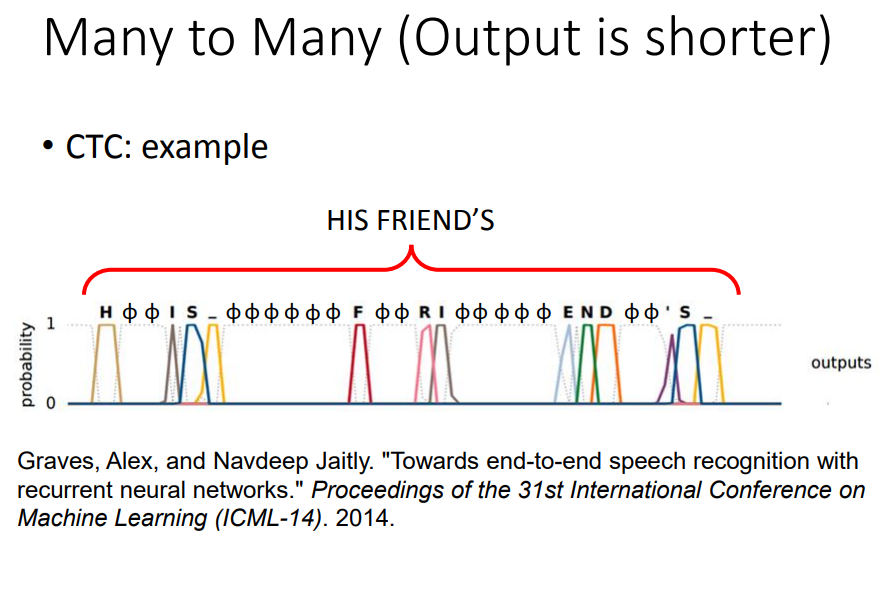
不用告诉机器his friends是两个单词,它会自己学到这件事,因此CTC可以辨识人名、地名等,是现在主流的方法。
5.3、机器翻译
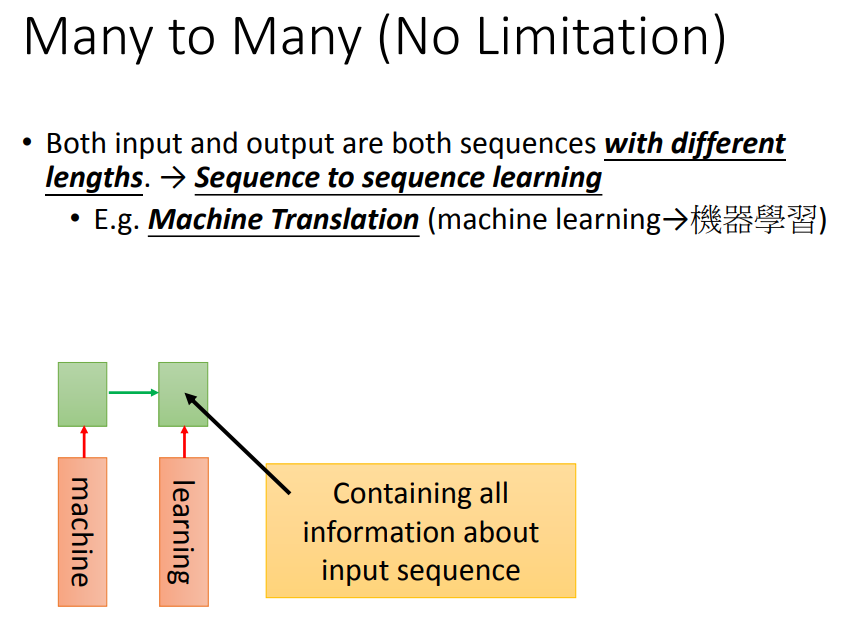
不确定输入输出的长短,如机器翻译:最后一个时间点,memory存了input的整个sequence的信息。
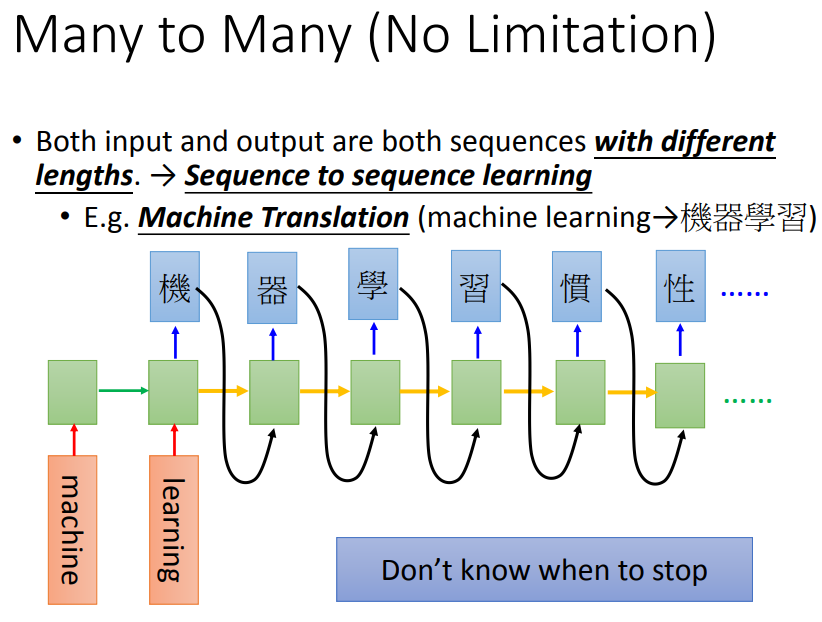

然后让机器吐一个character,再output下一个的时候把之前的当做input。
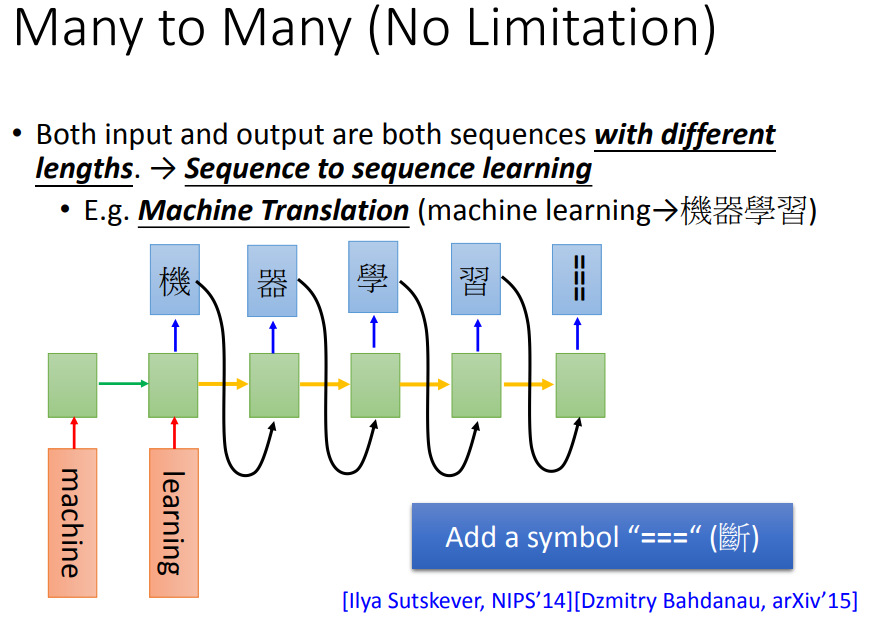
为了阻止机器不断产生词汇,需要多加一个symbol “===”。

输入语音直接输出翻译后的文字。
5.4、sequence-to-sequence
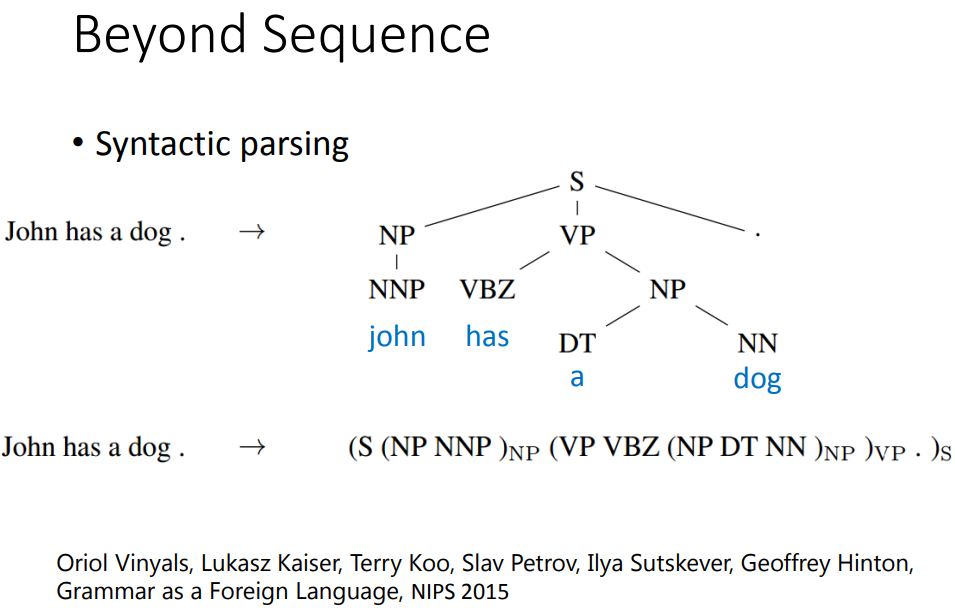
句法分析树:过去用structure learning才能解决,现在有了sequence-to-sequence技术,只要把这个树状图描述成一个sequence。
LSTM有记忆力,不会忘记加上右括号。
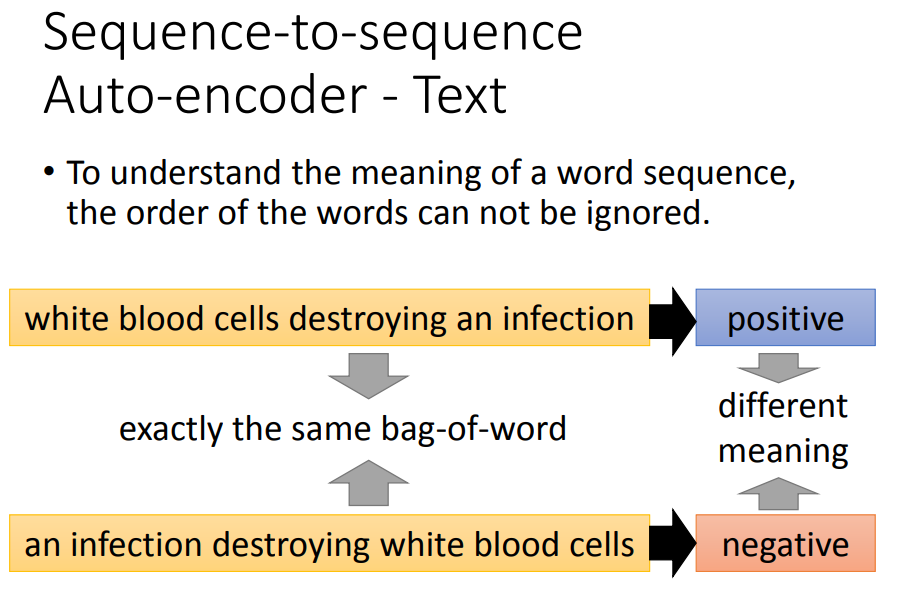
词袋模型往往会忽略掉单词顺序信息。
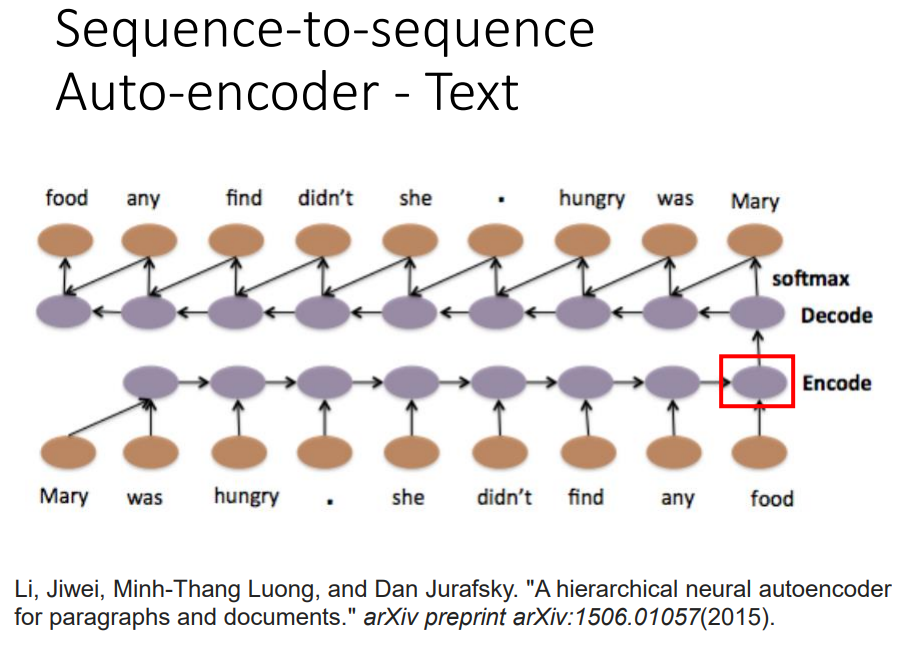
想要在考虑word sequence order的情况下,把一个document变成一个vector。
输入一个word sequence,通过一个RNN,把它变成一个embedding的vector,再把这个embedding vector当做decoder的输入,让decoder变回一模一样的句子。
这个过程RNN能做到的话,就说明这个vector能够代表word sequence重要的咨询。这个train不需要label,收集大量的文章直接train就好。
还有另外一个版本skip-thought,output target是下一个句子。如果要得到语义的意思,用skip-thought会得到比较好的结果。
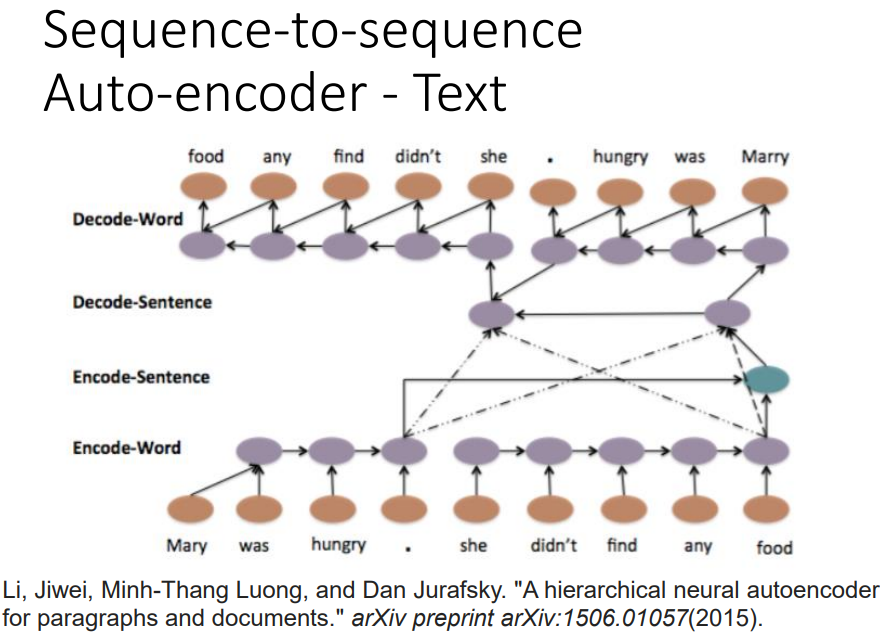
还可以每一个句子先得到一个vector,再把这些vector变成high-lever vector,再把整个的vector产生一串句子的vector,再根据每个句子的vector解回word sequence。
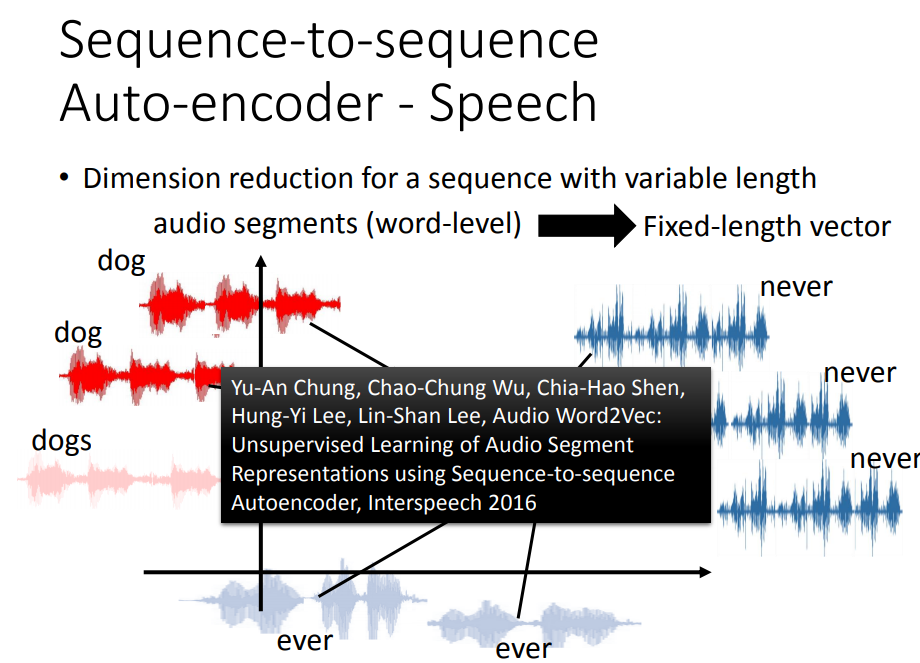

声音讯号变成vector,可以拿来做语音搜索。
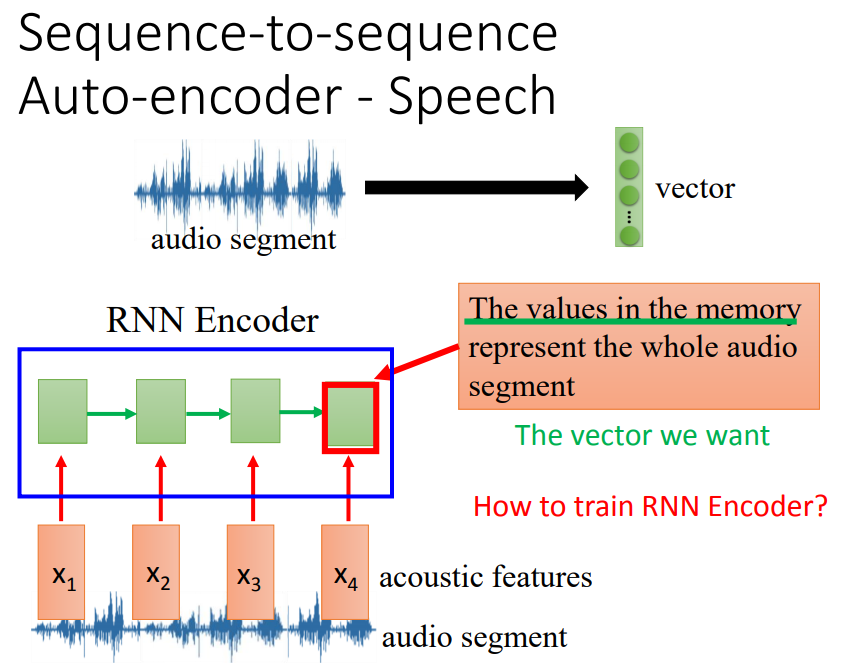
先把audio segment抽成acoustic feature sequence,然后放进RNN(encoder),最后一个时间点存在memory里面的值就代表了声音信息,就是我们想要的vector。
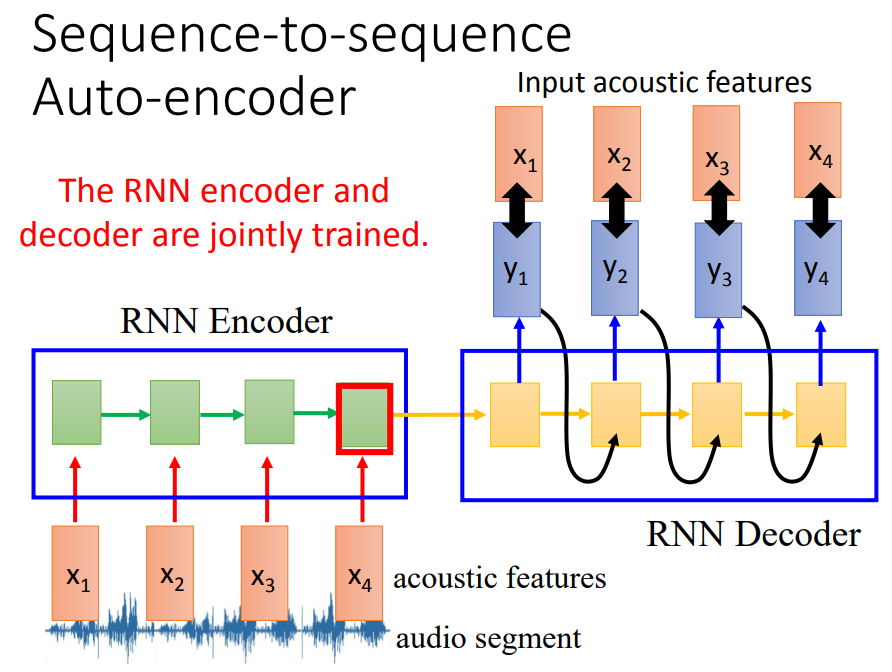
还需要train decoder,训练target是希望y1和x1越接近越好。

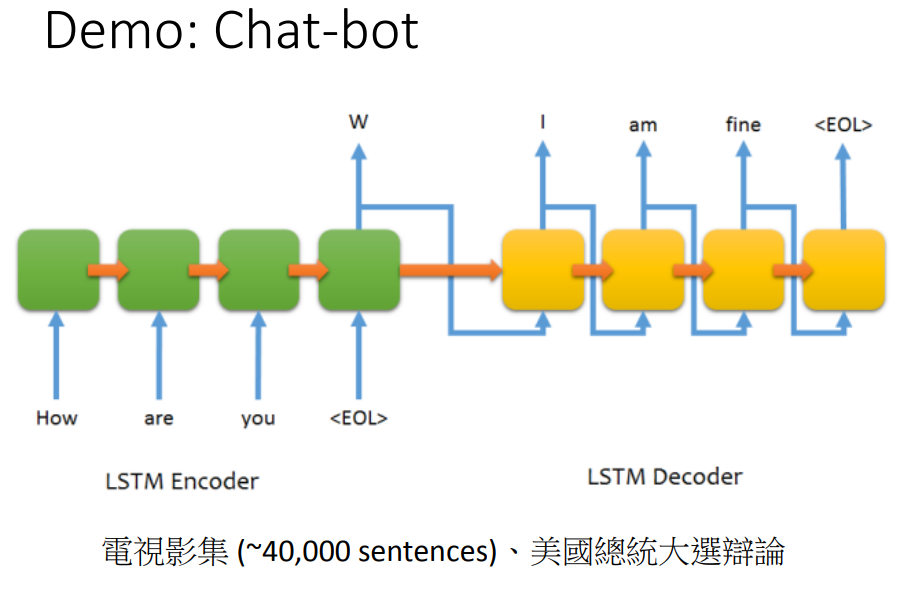
decoder输出的值是应答的内容。
六、attention-based model
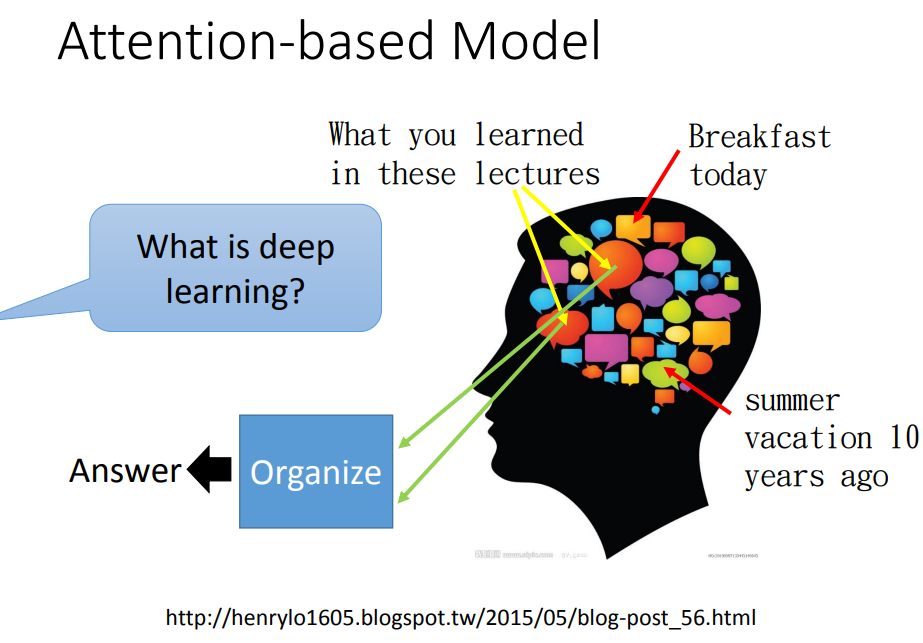
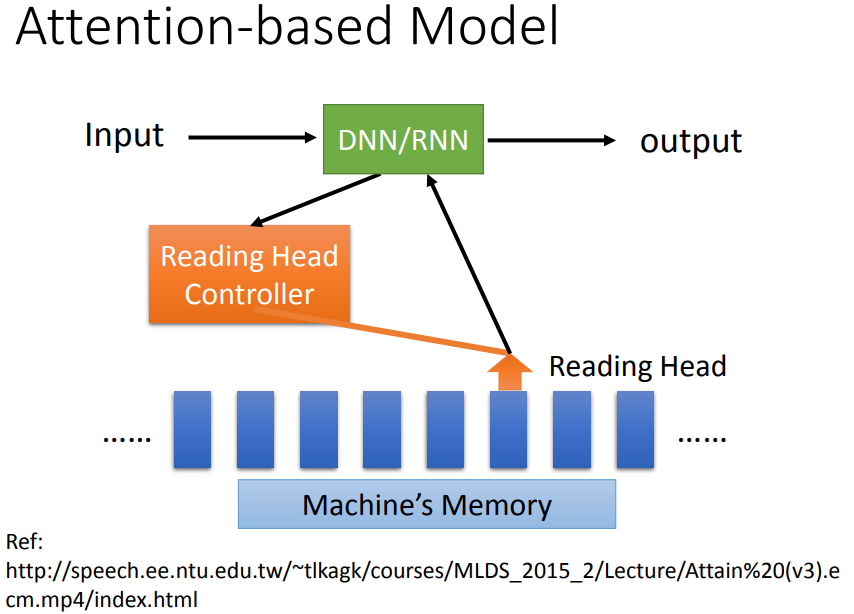
机器也可以有很大的记忆容量,DNN/RNN会操控一个读写头,决定reading head放的位置,机器再从这个位置读取数据,产生最后的output。
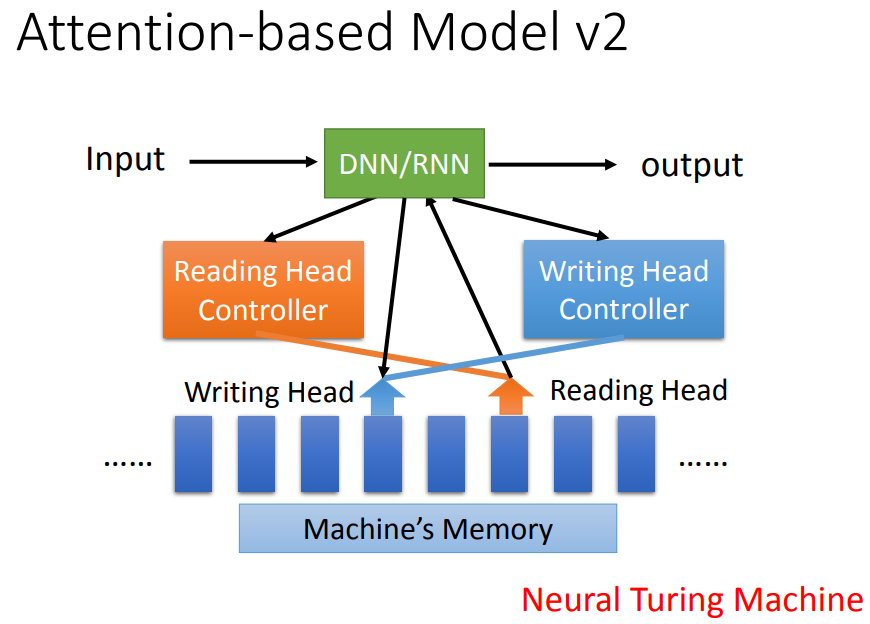
进阶版,还可以把发现的东西写进memory,这个就是neural turing machine。
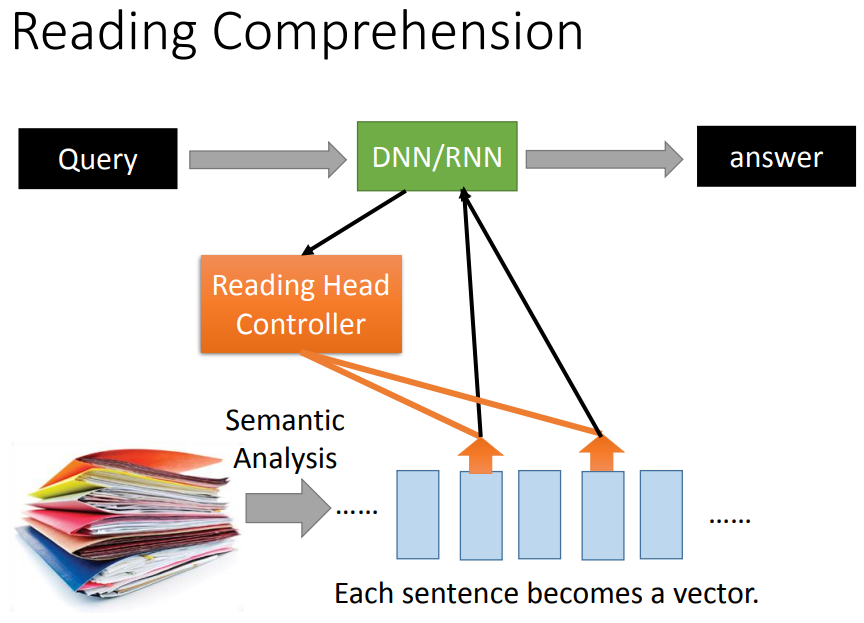
读取过程可以是重复的,并不会只从一个地方读取。

从哪个位置读是由机器自己学习的。
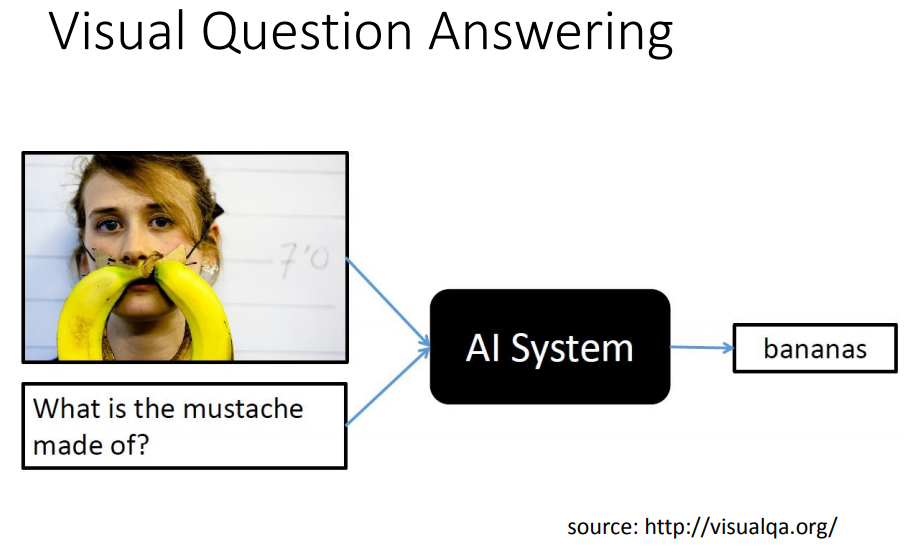
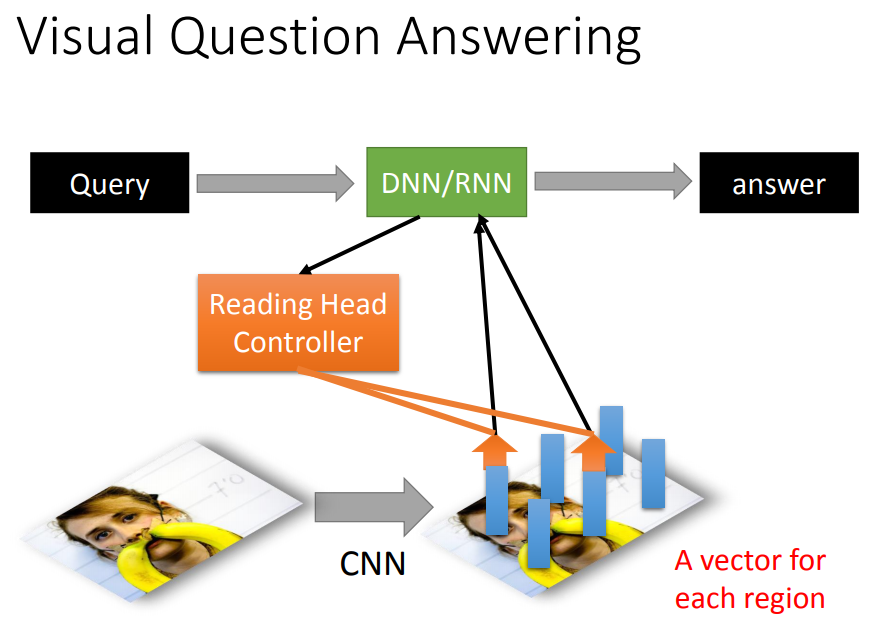
用CNN把每一块region用vector表示,问题输入后同样由reading head controller来决定要读取的咨询位置。
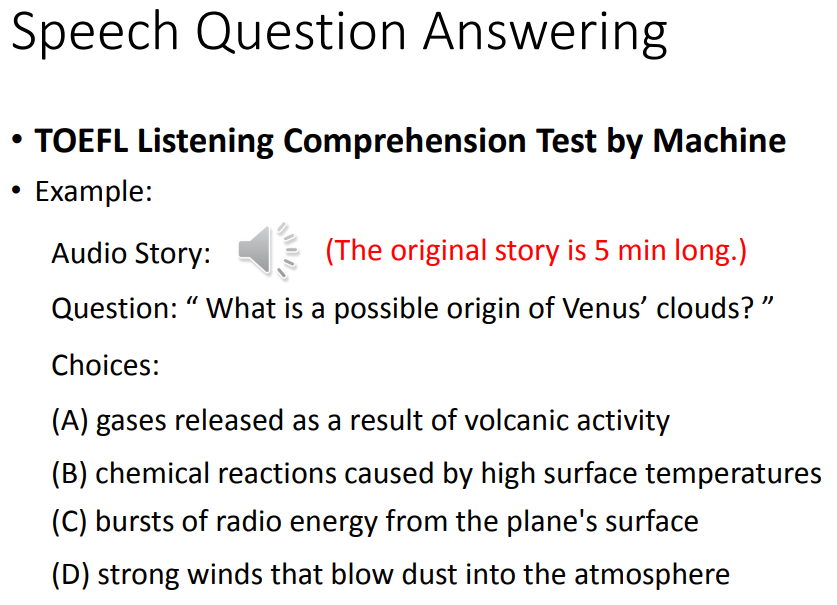
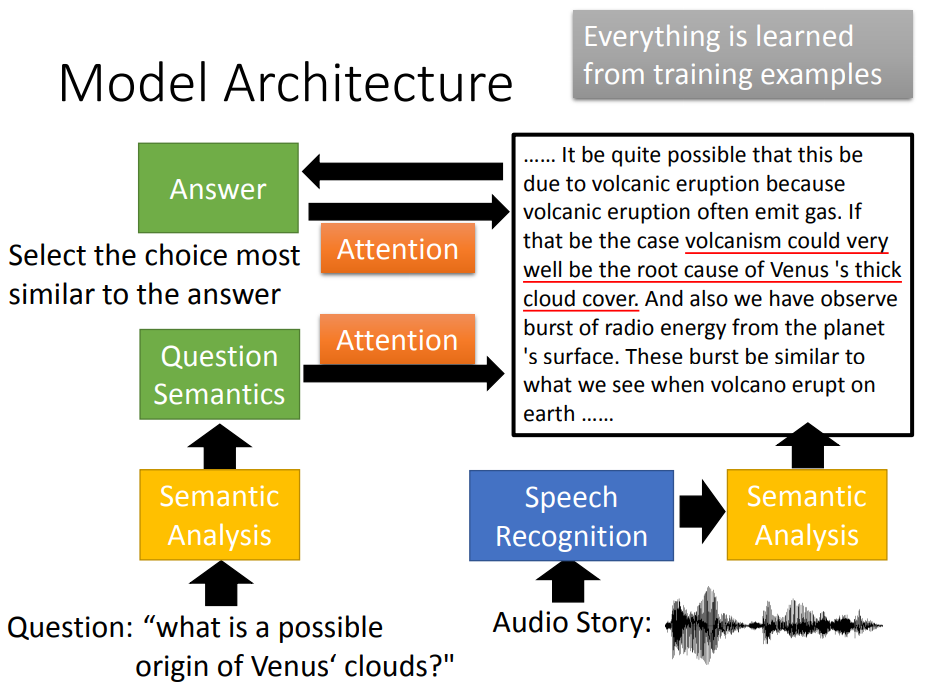
机器了解了问题的语义和audio story的语义,就可以做attention,找出哪些部分和问题有关。
将答案与其它选项计算相似度。
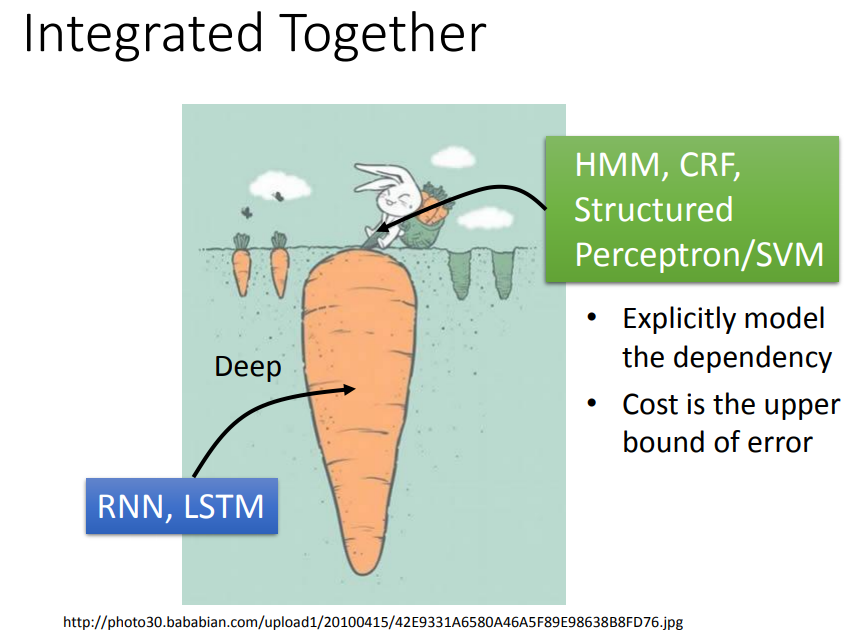
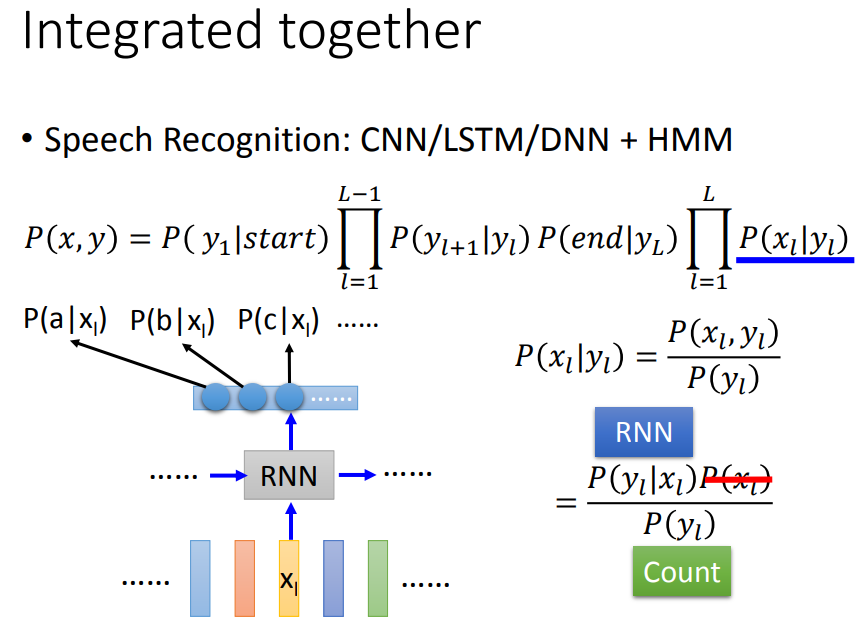
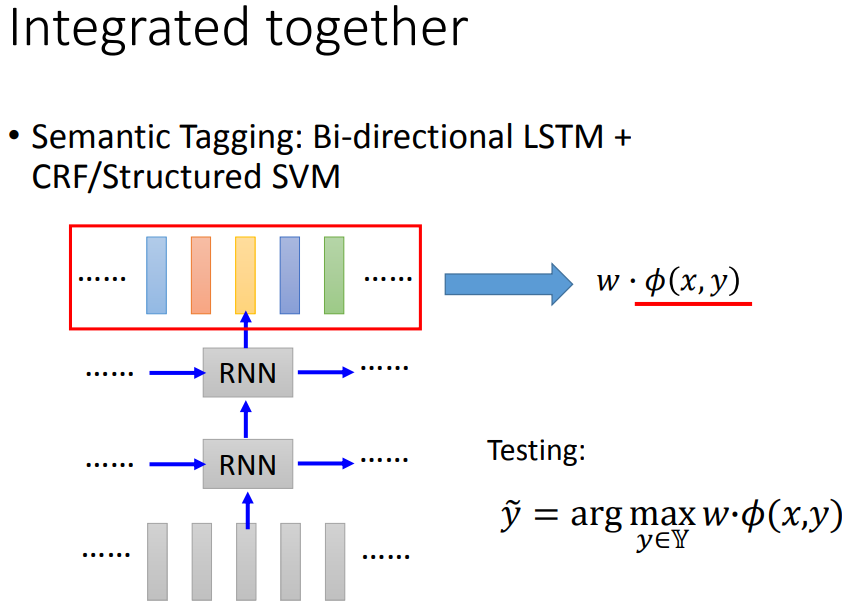
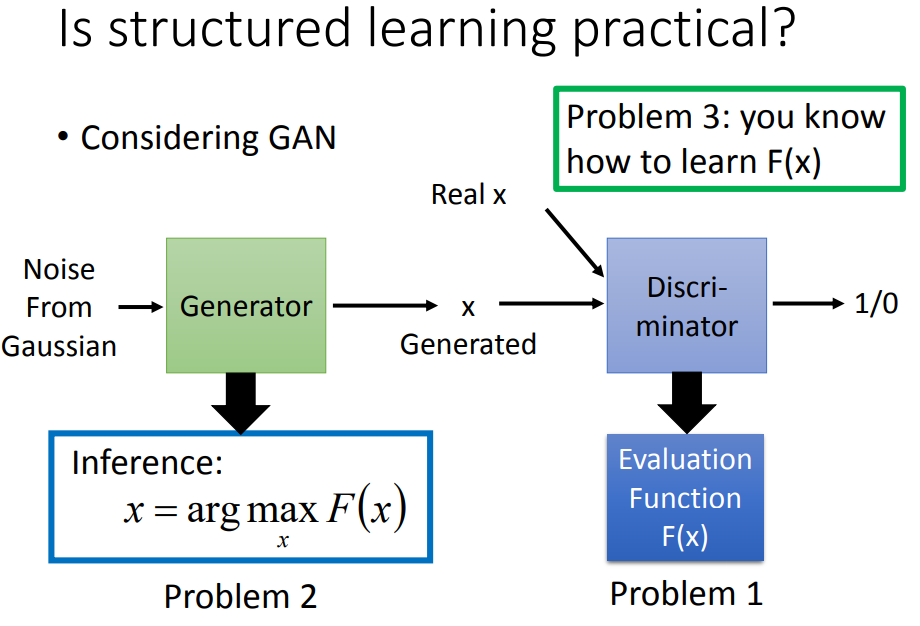
七、对比