一、numpy
1、array的创建
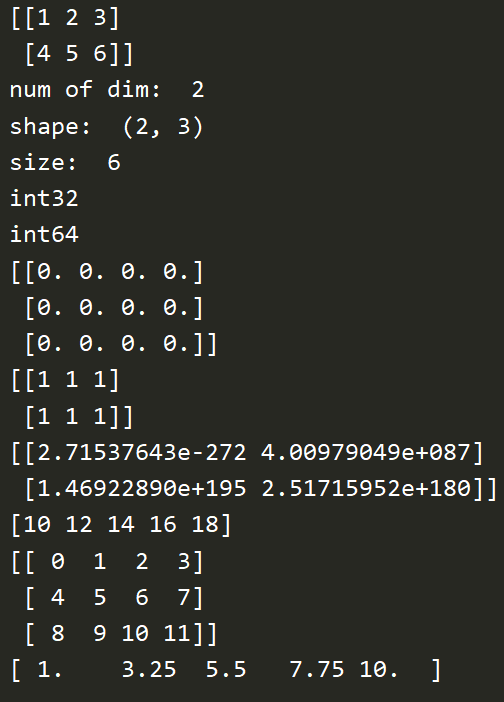
import numpy as np # 定义矩阵/数组 array1 = np.array([[1,2,3],[4,5,6]]) print(array1) print("num of dim: ", array1.ndim) print("shape: ", array1.shape) print("size: ", array1.size) array2 = np.array([2,3,4], dtype=np.int64) print(array1.dtype) print(array2.dtype) # 自动生成数组 array3 = np.zeros((3,4)) print(array3) array4 = np.ones((2,3), dtype=np.int16) print(array4) array5 = np.empty((2,2)) print(array5) array6 = np.arange(10, 20, 2) # 起止步长 print(array6) array7 = np.arange(12).reshape((3,4)) # 0-11,3行4列 print(array7) array8 = np.linspace(1, 10, 5) # 1-10,生成5段 print(array8)
2、基础运算
所有的方法都可以指定axis(0按列、1按行)
a = np.array([10,20,30,40]) b = np.arange(4) print(a+b) print(a-b) print(b**2) # 2次幂 print(10*np.sin(a)) # sin print(np.tan(a)) # tan print(a<25) print(b==3)
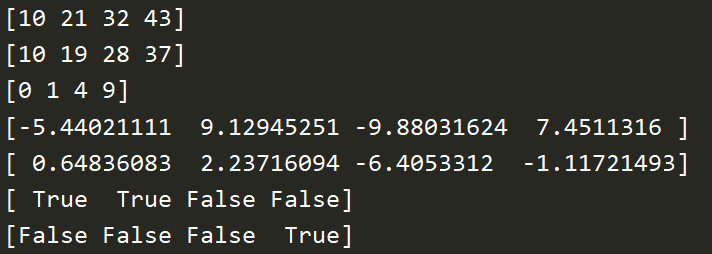
c = np.array([[1,2],[3,4]]) d = np.arange(4).reshape((2,2)) print(c) print(d) print(c*d) # 逐个相乘 print(np.dot(c,d)) # 矩阵乘法 print(c.dot(d)) # 矩阵乘法
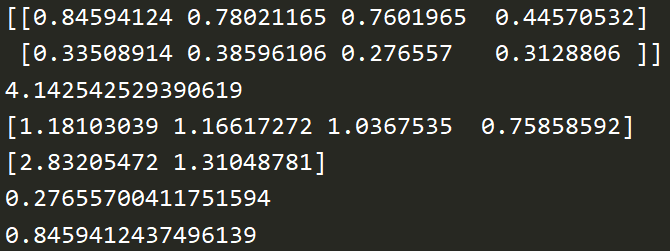
e = np.random.random((2,4)) # 创建随机生成(0-1)的array print(e) print(np.sum(e)) # 求和 print(np.sum(e, axis=0)) # 列上求和 print(np.sum(e, axis=1)) # 行上求和 print(np.min(e)) # 最小值 print(np.max(e)) # 最大值
a = np.arange(2,14).reshape((3,4)) print(a) print(np.argmin(a)) # 最小值的索引 print(np.argmax(a)) # 最大值的索引 print(np.mean(a)) # 平均值 print(np.median(a)) # 中位数 print(np.cumsum(a)) # 顺序累加 print(np.diff(a)) # 两两之差 print(np.nonzero(a)) # 对应每个非0位置的行列号和类型
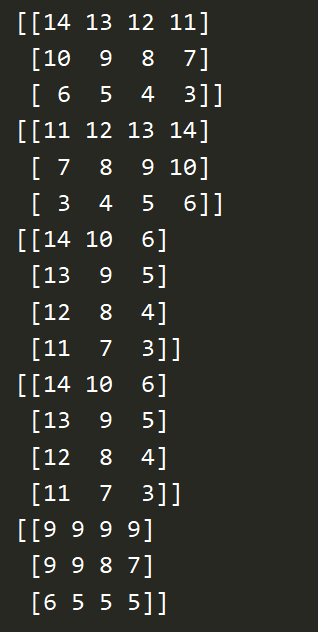
b = np.arange(14,2,-1).reshape((3,4)) print(b) print(np.sort(b)) # 逐行排序 print(np.transpose(b)) # 转置 print(b.T) # 转置 print(np.clip(b,5,9)) # 大于9的变成9,小于5的变成5
3、索引和迭代
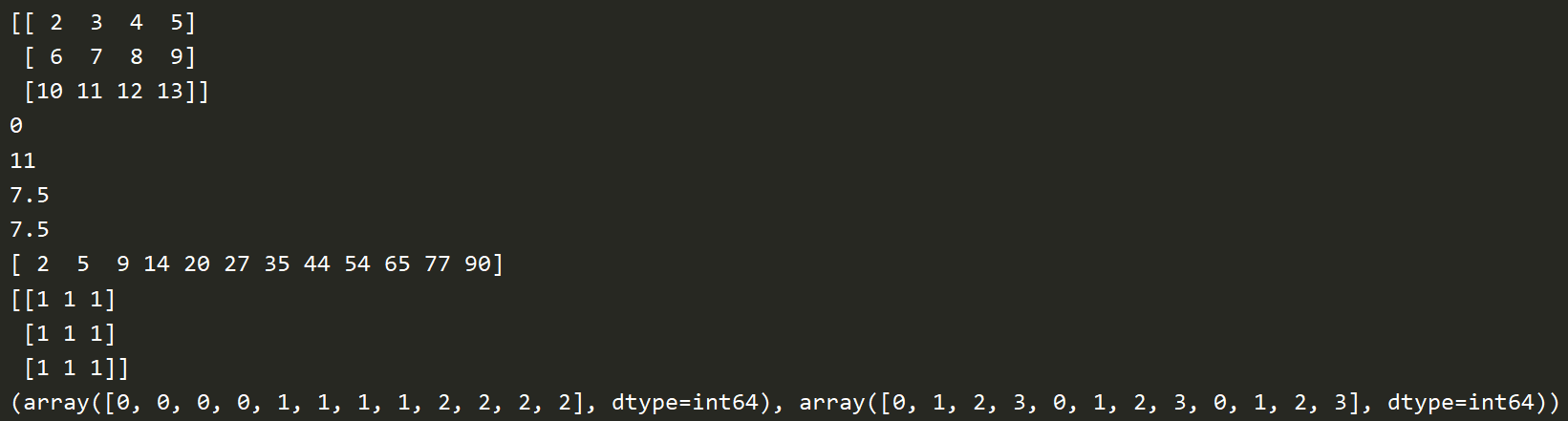
a = np.arange(3,15).reshape((3,4)) print(a) print(a[2]) # 打印第2行 print(a[2][3]) print(a[2,3]) print(a[2,:]) # 打印第2行 print(a[:,1]) # 打印第1列 print(a[1,1:3])
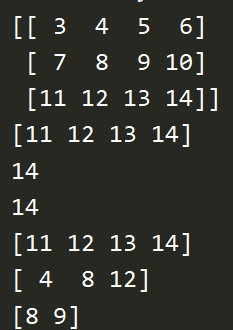
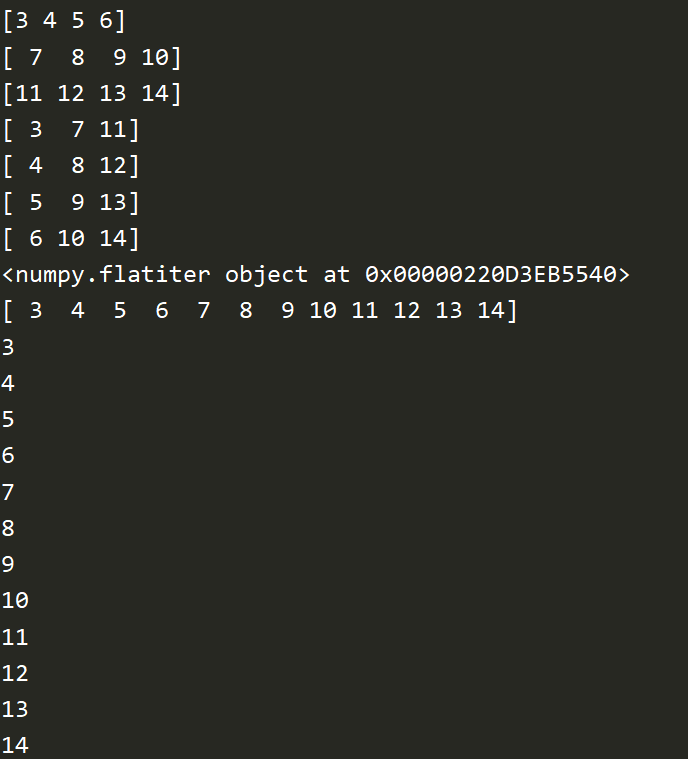
for row in a: print(row) for column in a.T: print(column) print(a.flat) # 迭代器 print(a.flatten()) # 返回迭代的值 for item in a.flat: print(item)
4、合并
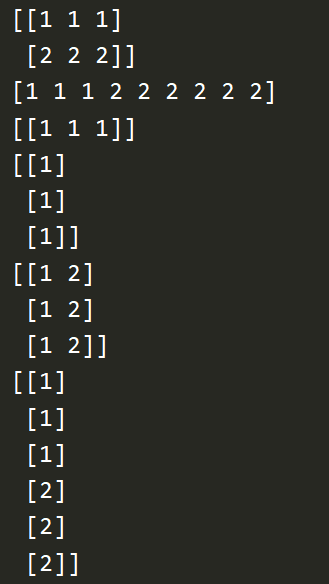
import numpy as np a = np.array([1,1,1]) b = np.array([2,2,2]) print(np.vstack((a,b))) # vertical stack 上下合并[[1,1,1],[2,2,2]] print(np.hstack((a,b,b))) # horizontal stack 左右合并[1,1,1,2,2,2,2,2,2] print(a[np.newaxis, :]) # 在列上加维度 [[1,1,1]] print(a[:,np.newaxis]) # 在行上加维度 [[1],[1],[1]] a = a[:,np.newaxis] b = b[:,np.newaxis] print(np.hstack((a,b))) # [[1,2],[1,2],[1,2]] print(np.vstack((a,b))) # [[1],[1],[1],[2],[2],[2]] # 多个array纵向或横向合并 print(np.concatenate((a,b,b), axis=0)) print(np.concatenate((a,b,b), axis=1))
5、分割
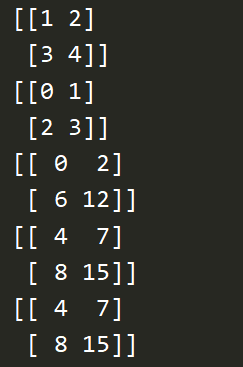
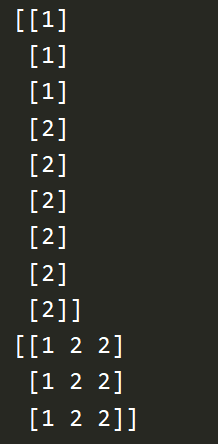
import numpy as np a = np.arange(12).reshape((3,4)) print(a) # 只能进行等分 print(np.split(a, 2, axis=1)) print(np.split(a, 3, axis=0)) # 可以不等分 print(np.array_split(a, 3, axis=1)) print(np.vsplit(a, 3)) print(np.hsplit(a, 2))
6、copy
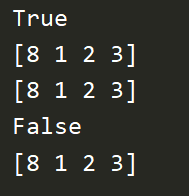
b = np.arange(4) c = b print(c is b) # 同一块内存 b[0] = 8 print(c) d = c print(d) # 跟着改变 c = b.copy() # 深拷贝 print(b is c) b[3] = 9 print(c) # 没有改变
二、pandas
1、初始化DataFrame
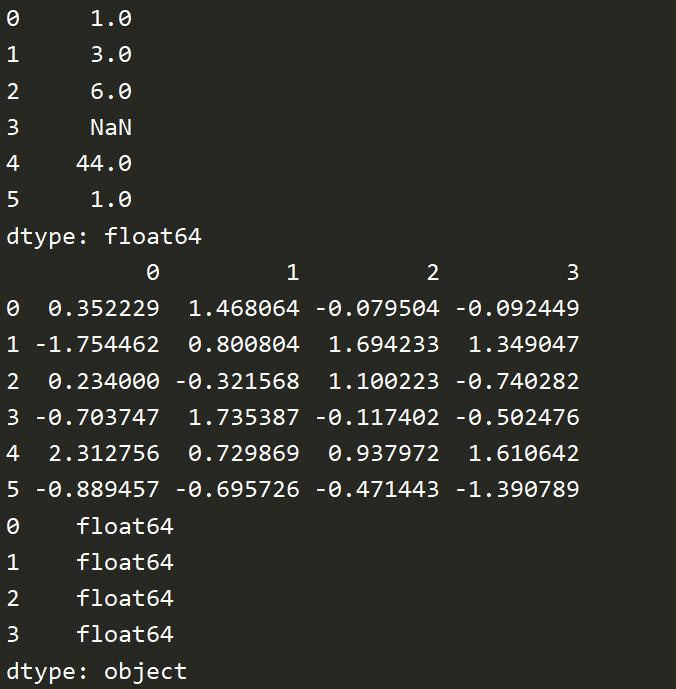
import pandas as pd import numpy as np s = pd.Series([1,3,6,np.nan,44,1]) print(s) # 默认行列名为0 1 2 3... df = pd.DataFrame(np.random.randn(6,4)) print(df) print(df.dtypes)
date = pd.date_range('20200101',periods=6) print(date) # index 行索引 columns 列索引 df2 = pd.DataFrame(np.random.randn(6,4),index=date,columns=['a','b','c','d']) print(df2) print(df2.dtypes)
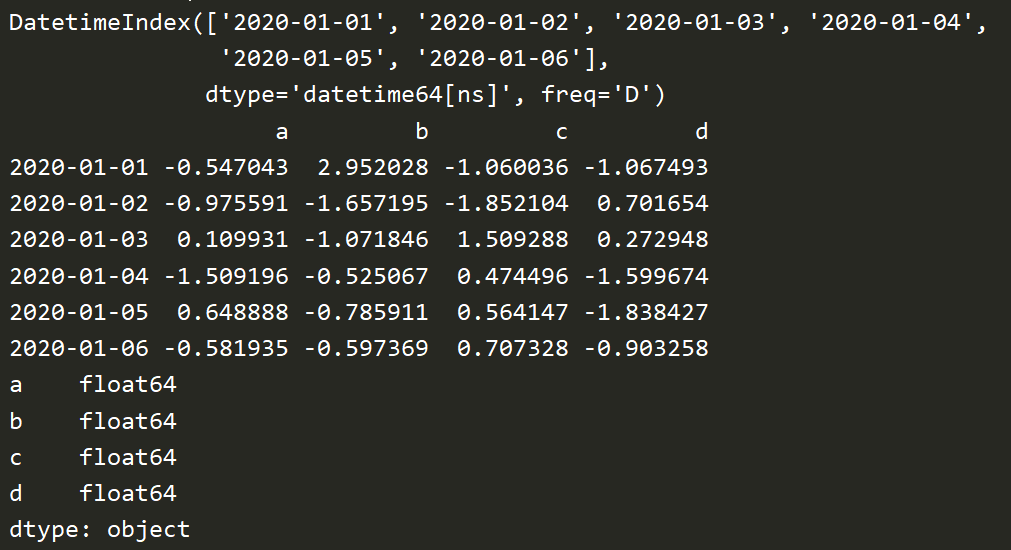
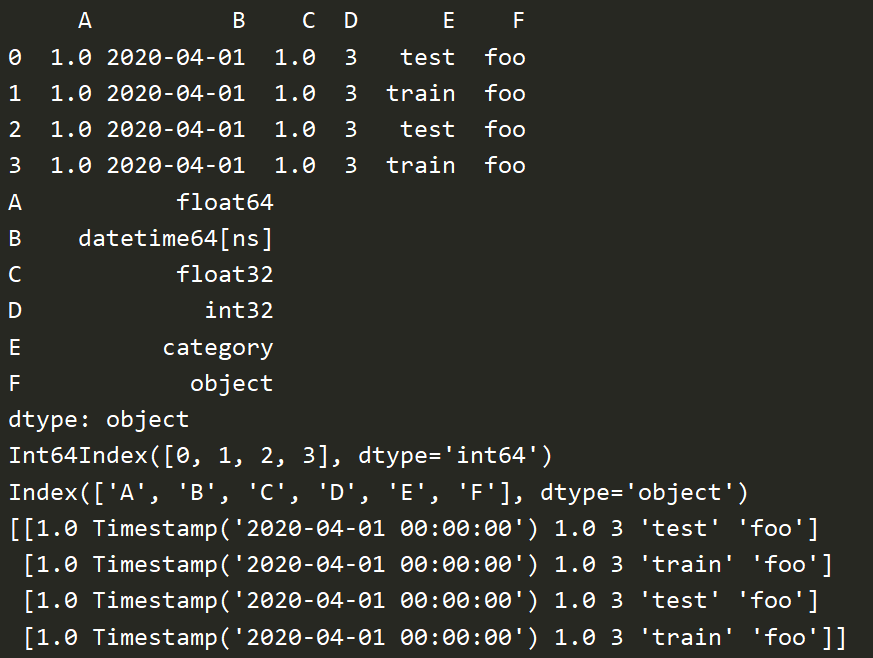
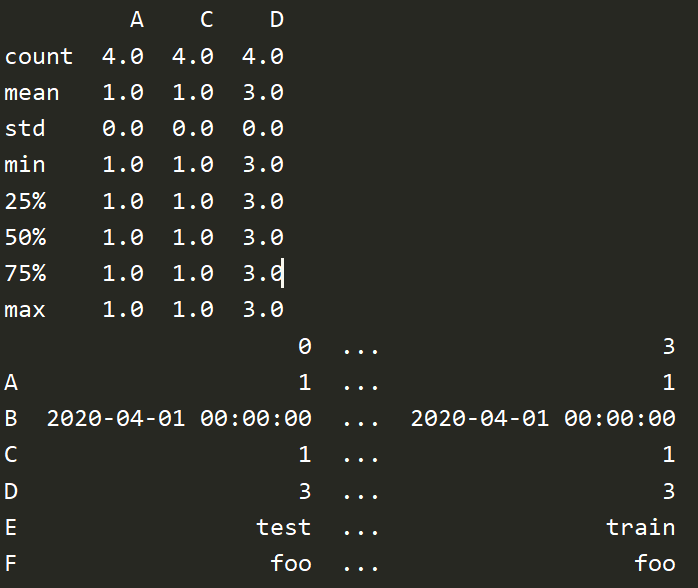
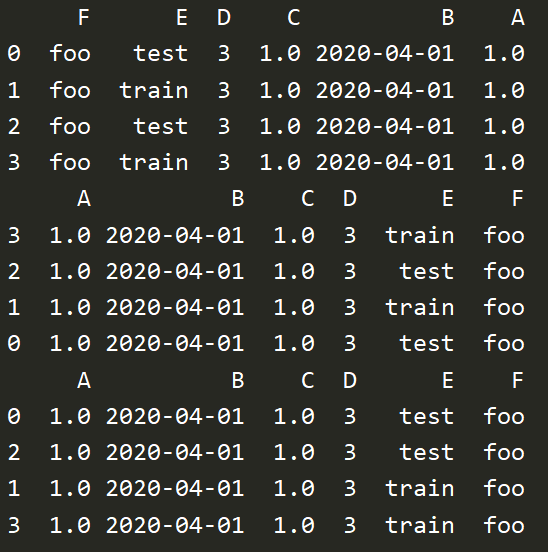
# 字典 df3 = pd.DataFrame({'A':1., 'B':pd.Timestamp('20200401'), 'C':pd.Series(1,index=list(range(4)),dtype='float32'), 'D':np.array([3]*4,dtype='int32'), 'E':pd.Categorical(["test","train","test","train"]), 'F':'foo'}) print(df3) print(df3.dtypes) print(df3.index) print(df3.columns) print(df3.values) print(df3.describe()) # 描述 print(df3.T) # 转置 print(df3.sort_index(axis=1,ascending=False)) # 按行,倒序 print(df3.sort_index(axis=0,ascending=False)) # 按列,倒序 print(df3.sort_values(by='E')) # 单列排序
2、选择数据
import pandas as pd import numpy as np dates = pd.date_range('20200101',periods=6) df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D']) print(df) # 打印列 print(df.A) # 打印一列 print(df['A']) # 打印一列 print(df[['A','B']]) # 打印多列 # 打印行 print(df[:1]) # 打印一行 print(df[0:3]) # 打印多行 print(df['20200101':'20200104']) # 打印多行 # select by label print(df.loc['20200103']) # 打印一行 print(df.loc['20200101':'20200104', ['A','B']]) # select by position print(df.iloc[3]) # 第三行 print(df.iloc[3,1]) # 三行一列 print(df.iloc[3:5,1:3]) print(df.iloc[[1,3,5],1:3]) # 1,3,5行 # mixed selection 这种方法已经移除了 # print(df.ix[:3,['A','C']]) # boolean indexing print(df[df.A>8])
3、设置值
import numpy as np import pandas as pd dates = pd.date_range('20200101',periods=6) df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['a','b','c','d']) df.iloc[2,2] = 111 df.loc['20200101','c'] = 222 df.a[df.b>8] = 0 # a列中b大于8的更改为0 df['F'] = np.nan # 增加F列 df['G'] = pd.Series([1,2,3,4,5,6],index=pd.date_range('20200101',periods=6)) print(df)
4、处理丢失数据
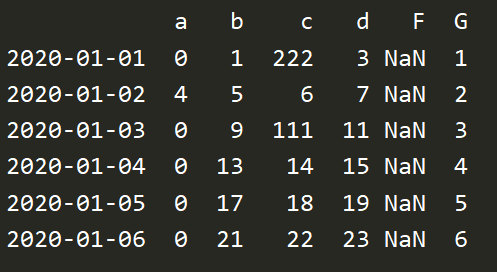
import numpy as np import pandas as pd dates = pd.date_range("20200101",periods=6) df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['a','b','c','d']) df.iloc[1,2] = np.nan df.iloc[4,3] = np.nan # 检查是否有缺失数据 print(df.isnull()) # 检查数据表中至少有一个是nan print(np.any(df.isnull() == True)) # nan位置填入0 print(df.fillna(value=0)) # how可以等于any(只要这一行有就删掉) all(这一行全都是nan才删掉) print(df.dropna(axis=0,how='any')) # 0行 1列
5、导入导出
在pandas中能被读取的格式


import pandas as pd data = pd.read_csv('student.csv') print(data) data.to_pickle('student.pickle')
6、concat合并
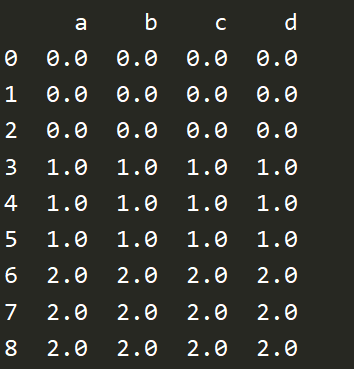
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d']) df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d']) df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d']) # 上下合并 加上ignore_index则重新排序 res = pd.concat([df1,df2,df3],axis=0,ignore_index=True) print(res)
# join ,['inner','outer'] df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3]) df2 = pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4]) res = pd.concat([df1,df2],join='outer') # 默认为outer,缺失的用nan填充 print(res) res = pd.concat([df1,df2],join='inner',ignore_index=True) # 只考虑两者都有的部分 print(res)
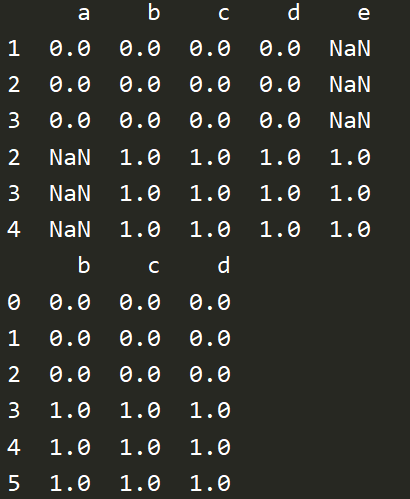
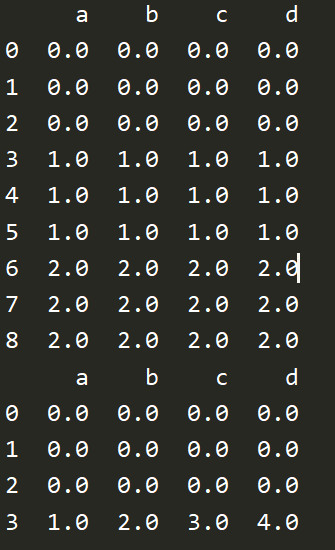
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d']) df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d']) df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'],index=[2,3,4]) res = df1.append([df2,df3],ignore_index=True) print(res) s1 = pd.Series([1,2,3,4],index=['a','b','c','d']) print(df1.append(s1,ignore_index=True))
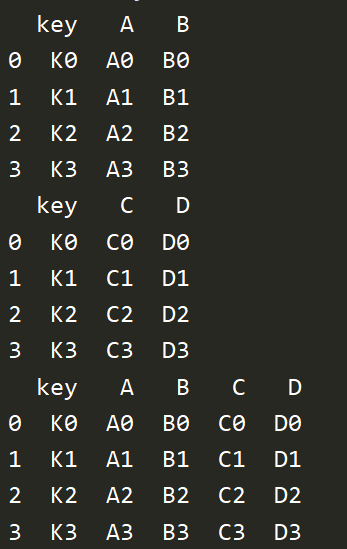
7、merge合并
left = pd.DataFrame({'key':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
print(left)
print(right)
# merge two df by key
res = pd.merge(left,right,on='key')
print(res)
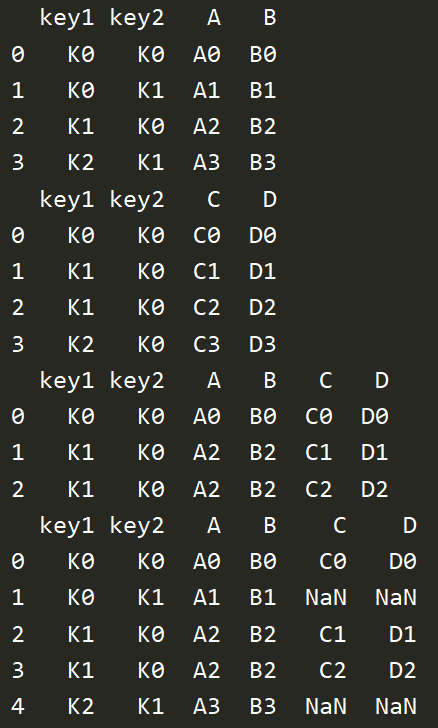
left = pd.DataFrame({'key1':['K0','K0','K1','K2'],
'key2':['K0','K1','K0','K1'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key1':['K0','K1','K1','K2'],
'key2':['K0','K0','K0','K0'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
print(left)
print(right)
# consider two keys
res = pd.merge(left,right,on=['key1','key2'])
print(res) # 只有00和10是相同的,01 20和21 都不是共有的
# how:inner(默认)、outer、left、right
res = pd.merge(left,right,on=['key1','key2'],how='left')
print(res)
# indicator df1 = pd.DataFrame({'col1':[0,1],'col_left':['a','b']}) df2 = pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]}) print(df1) print(df2) res = pd.merge(df1,df2,on='col1',how='outer',indicator=True) # give the indicator a custom name 显示每一行merge的方式 print(res)
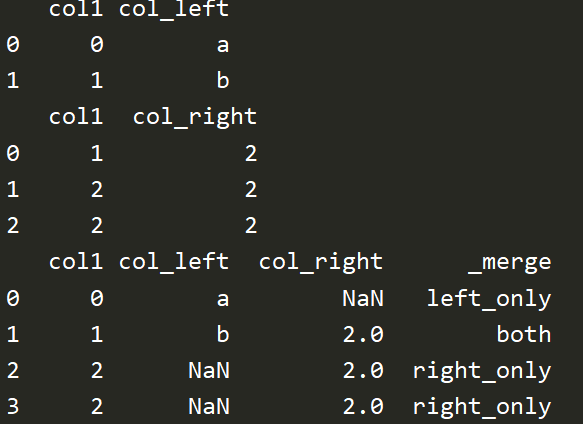
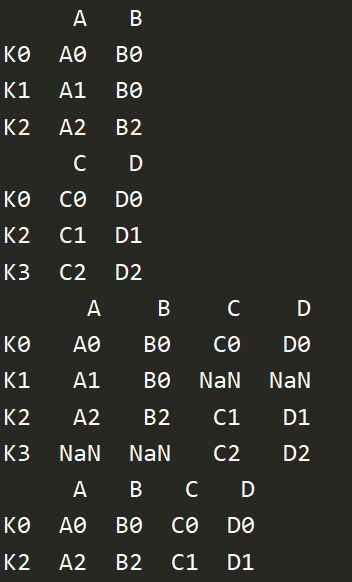
# 前面的方法都是考虑column,下面根据index合并 left = pd.DataFrame({'A':['A0','A1','A2'], 'B':['B0','B0','B2']},index=['K0','K1','K2']) right = pd.DataFrame({'C':['C0','C1','C2'], 'D':['D0','D1','D2']},index=['K0','K2','K3']) print(left) print(right) res = pd.merge(left,right,left_index=True,right_index=True,how='outer') print(res) res = pd.merge(left,right,left_index=True,right_index=True,how='inner') print(res)
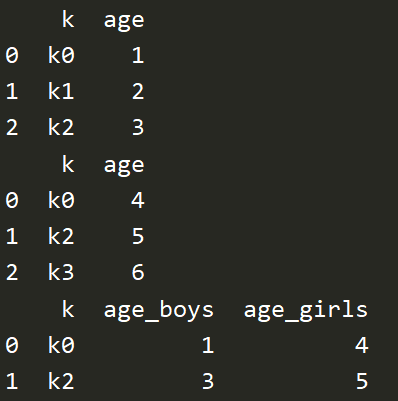
# 区别同名数据 boys = pd.DataFrame({'k':['k0','k1','k2'],'age':[1,2,3]}) girls = pd.DataFrame({'k':['k0','k2','k3'],'age':[4,5,6]}) print(boys) print(girls) res = pd.merge(boys,girls,on='k',suffixes=['_boys','_girls'],how='inner') print(res)
8、plot画图
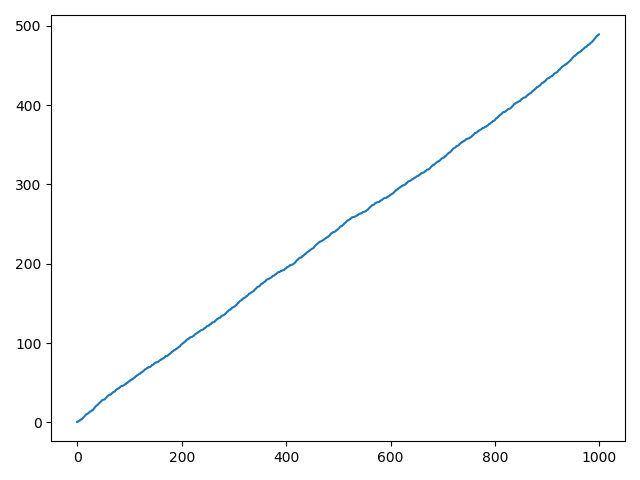
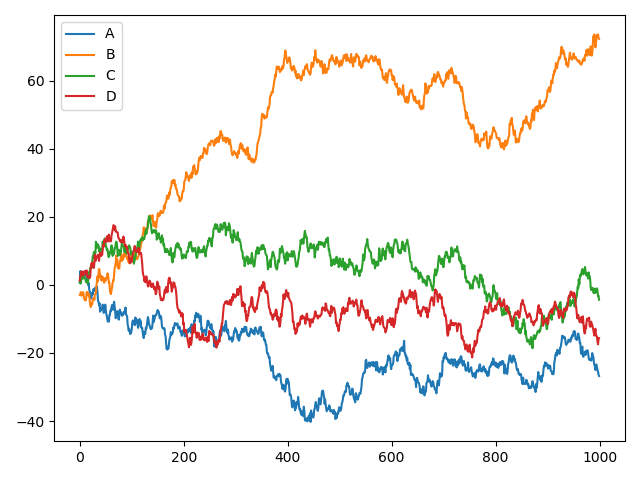
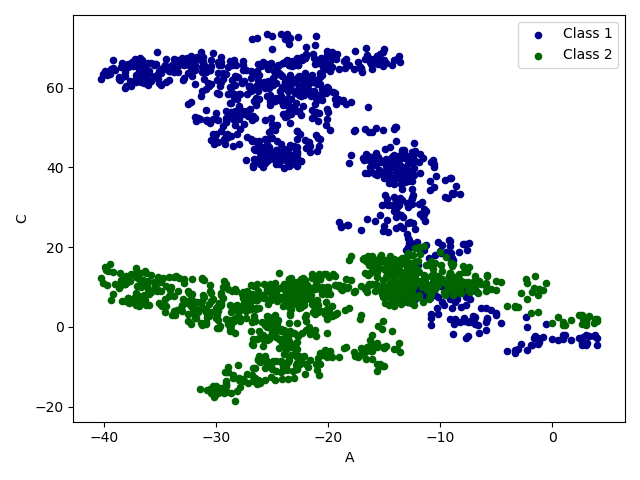
import pandas as pd import numpy as np import matplotlib.pyplot as plt # plot data # Series data = pd.Series(np.random.random(1000),index=np.arange(1000)) data = data.cumsum() # 累加 data.plot() plt.show() # DataFrame data = pd.DataFrame(np.random.randn(1000,4),index=np.arange(1000),columns=list("ABCD")) data = data.cumsum() print(data.head()) data.plot() plt.show() ax = data.plot.scatter(x='A',y='B',color='DarkBlue',label='Class 1') data.plot.scatter(x='A',y='C',color='DarkGreen',label='Class 2',ax=ax) plt.show()