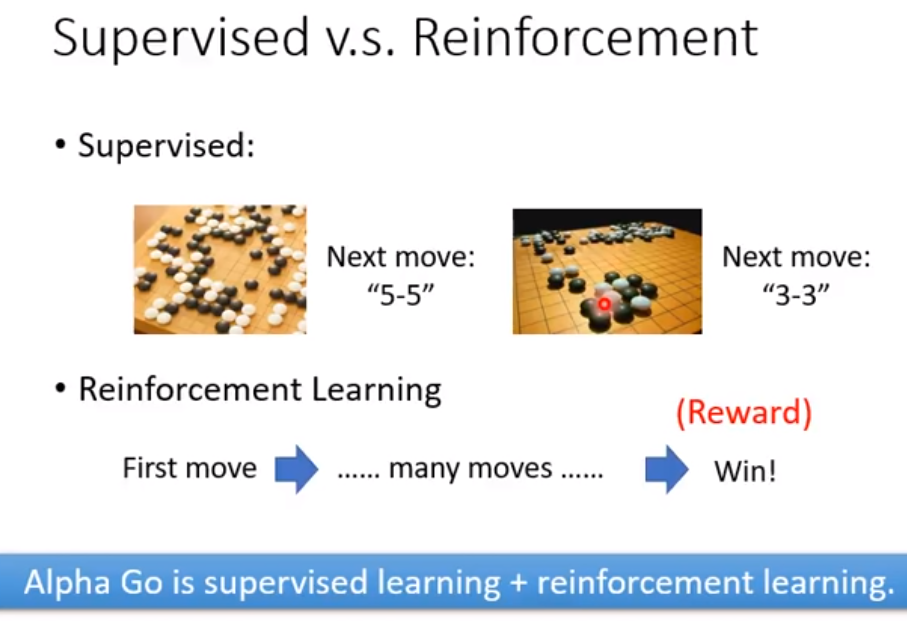
一、Course Introduction

1、机器学习就是自动找函式
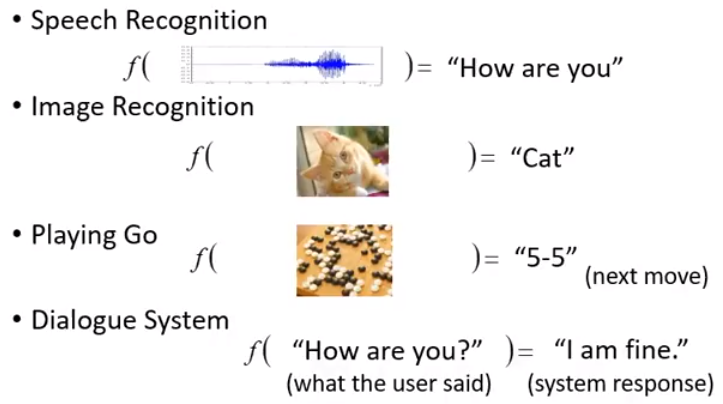
Regression: output is a scalar.
Classification:yes or no
Binary classification:RNN作业
Multi-class Classification:CNN作业
Generation: 产生有结构的复杂东西(文字 图片等)
Seq2Seq、GAN作业
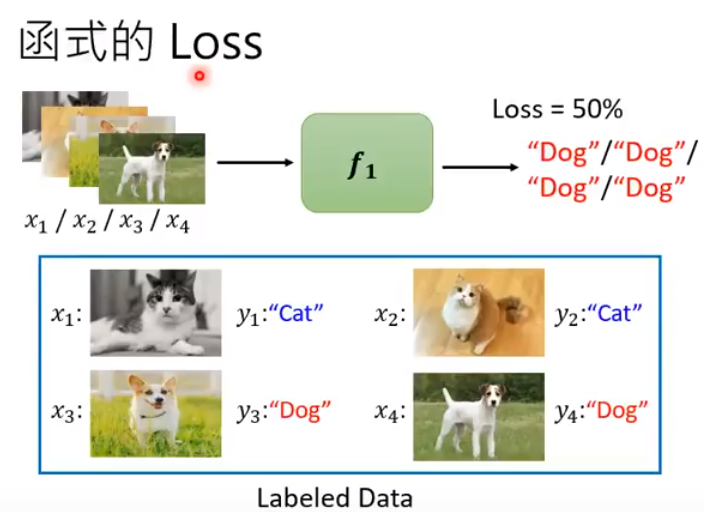
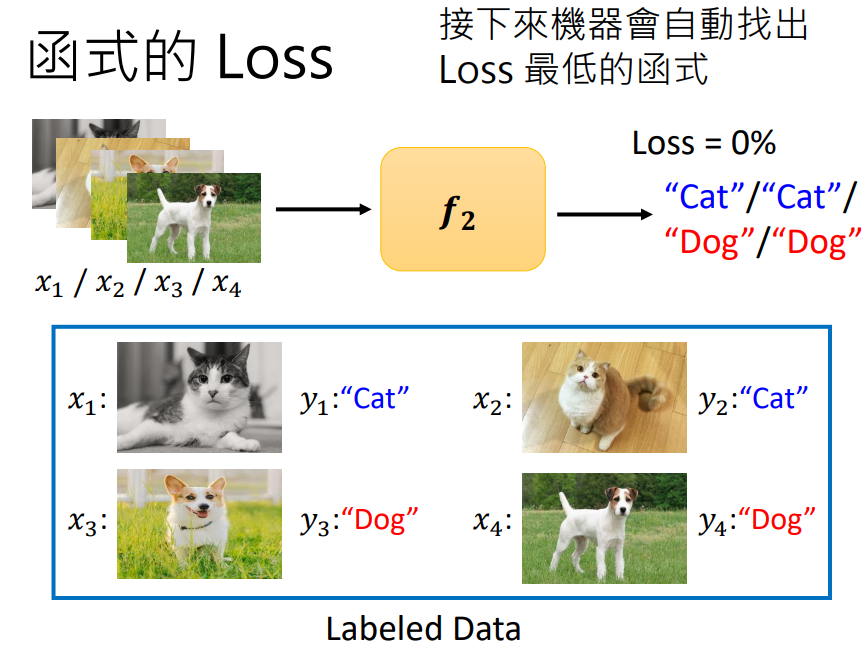
2、Supervised Learning: Labeled Data
unsuperived learning
3、前沿研究
Explainable AI

Adversarial Attack:对抗攻击

Network Compression
Anomaly Detection:异常检测(能够知道自己不知道)

Transfer Learning(Domain Adversarial Learning)

Meta Learning:learn to learn
Life-long learning:终身学习

二、Regression
1、应用


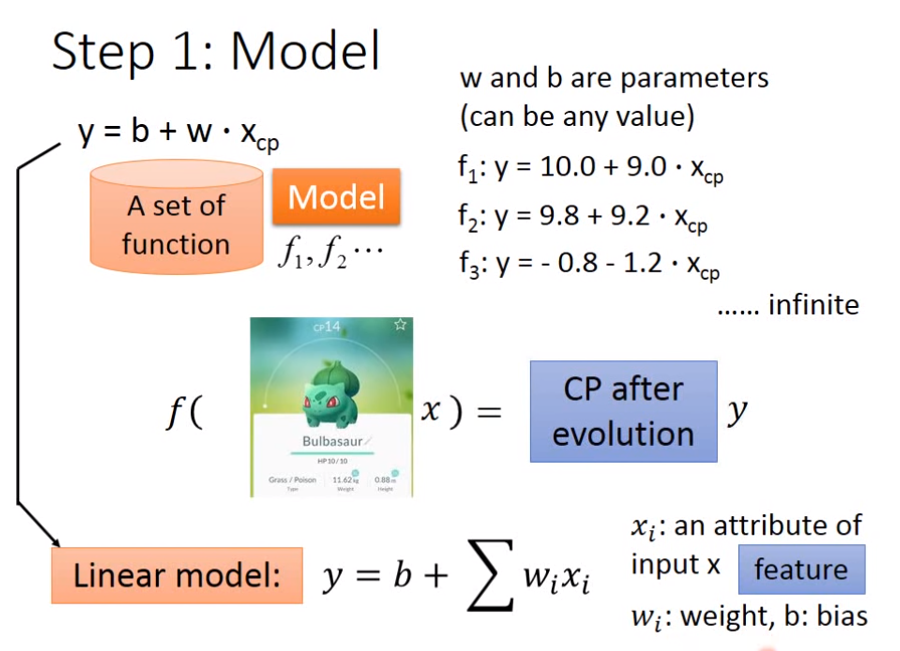
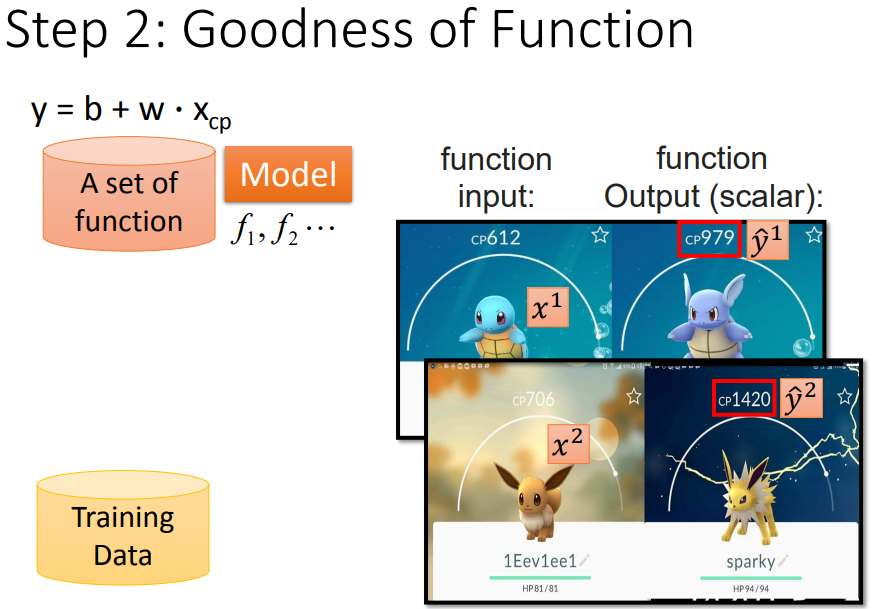
2、基本步骤
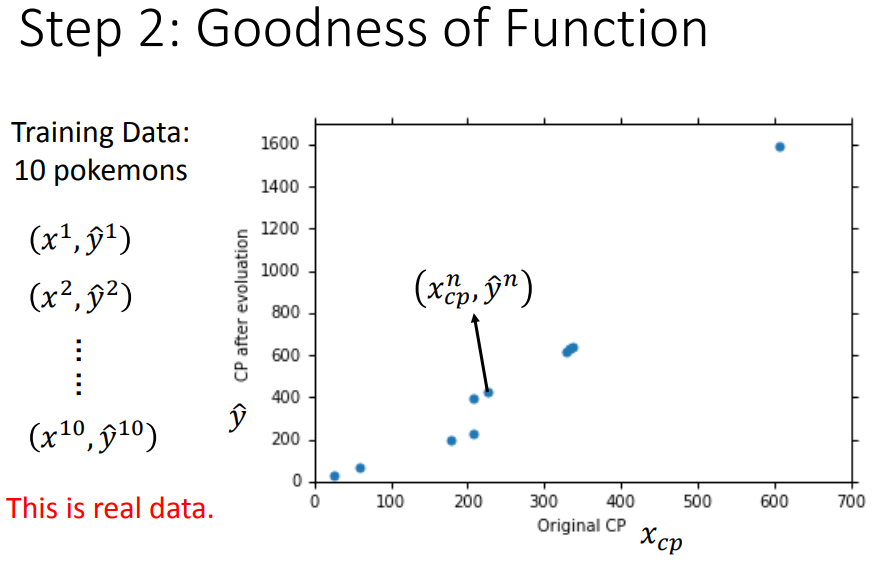





3、过拟合
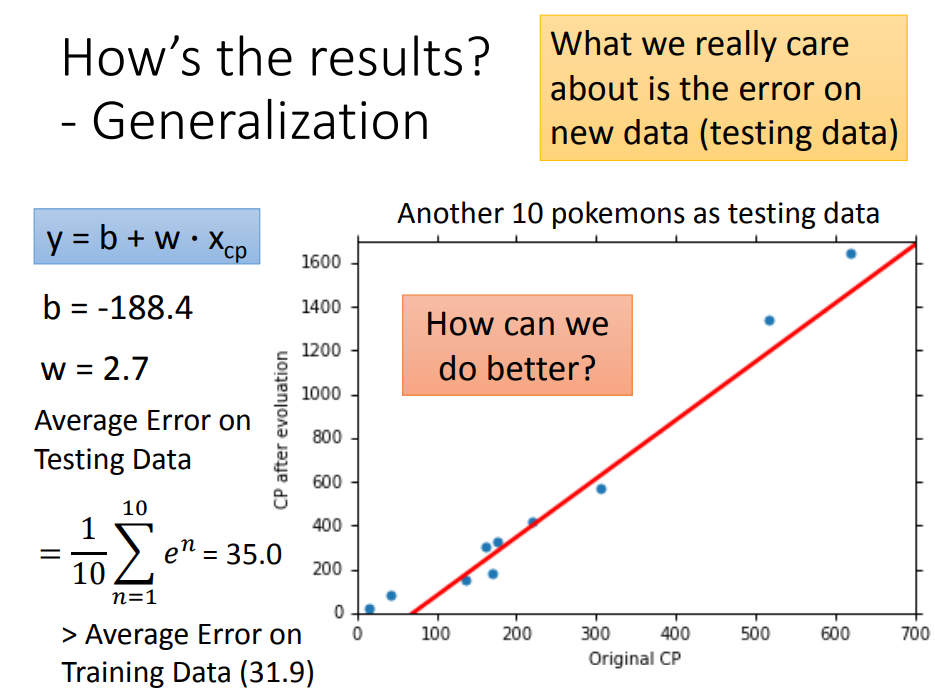
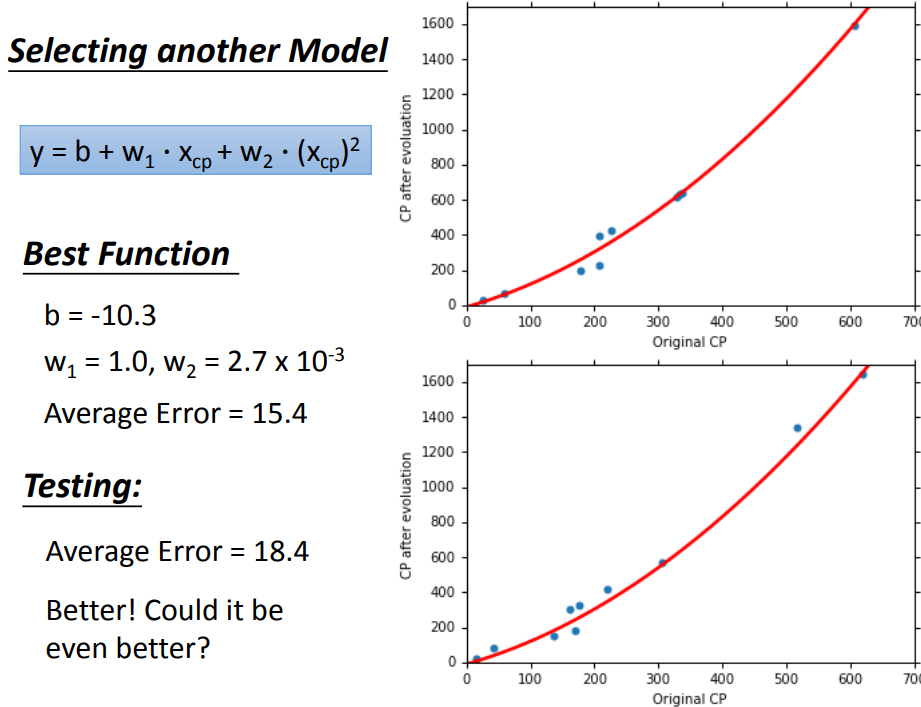
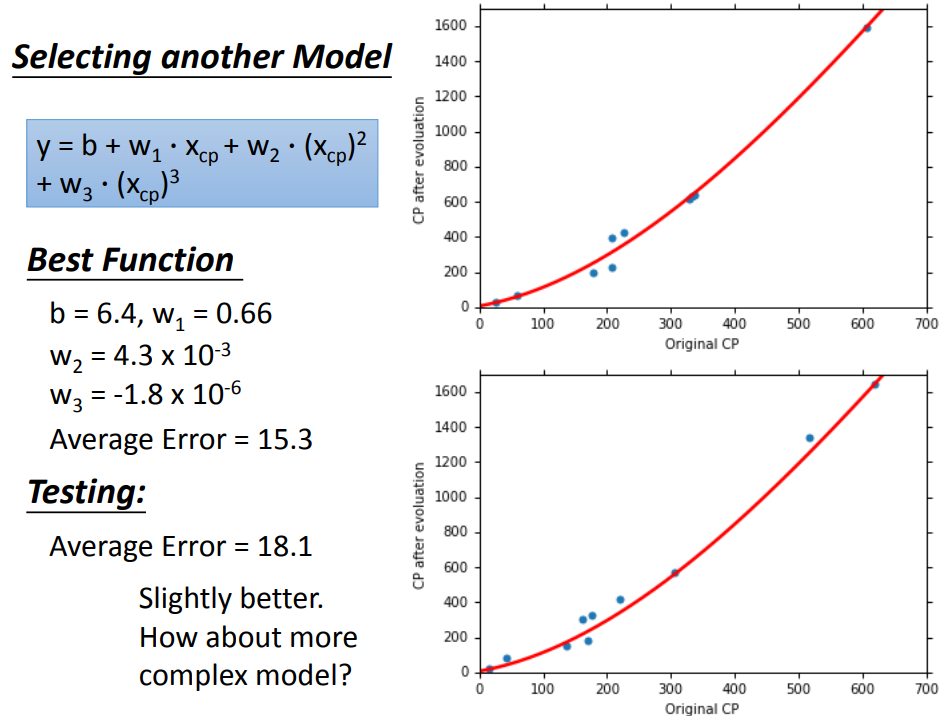
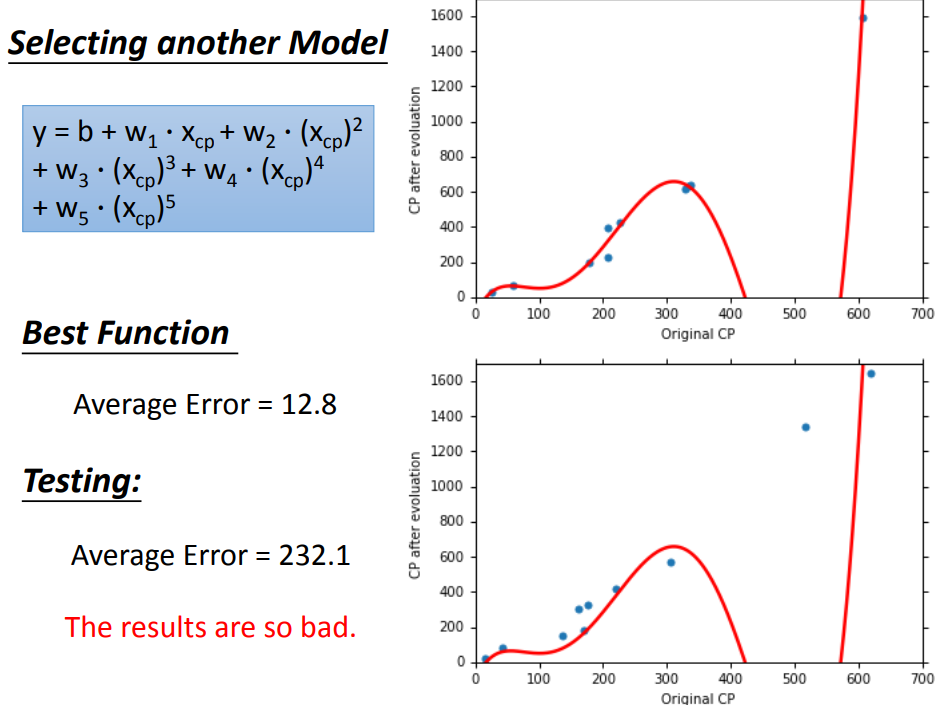
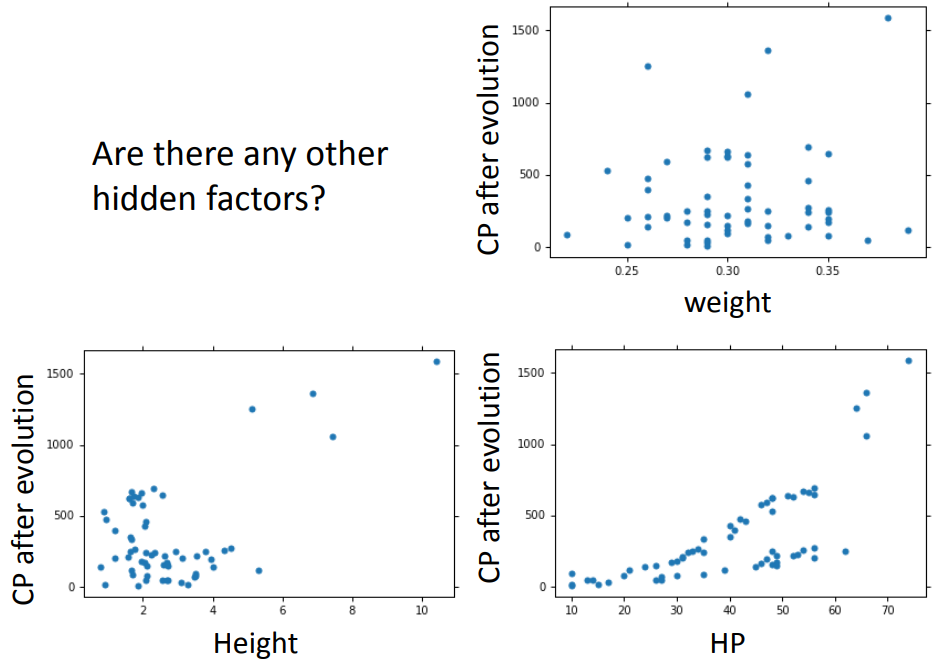
换了复杂的model,在training data上结果更好了,在testing data上结果反而更差。


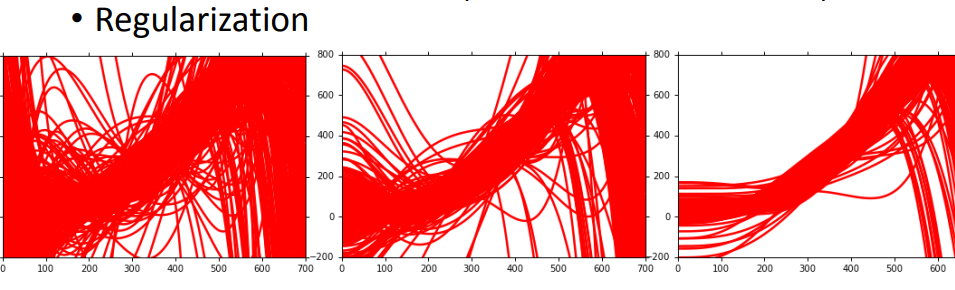
4、正则化


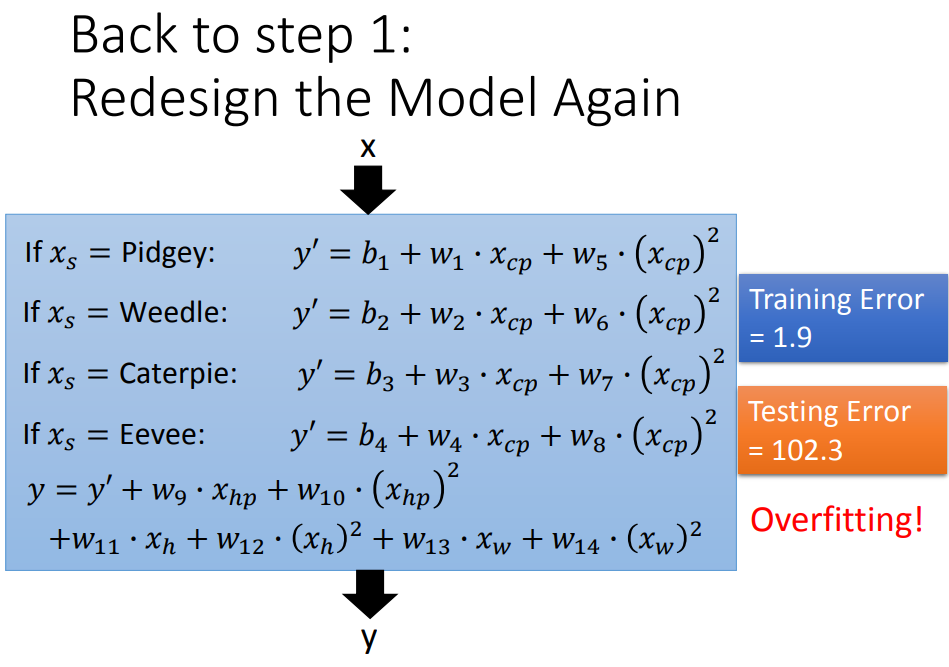

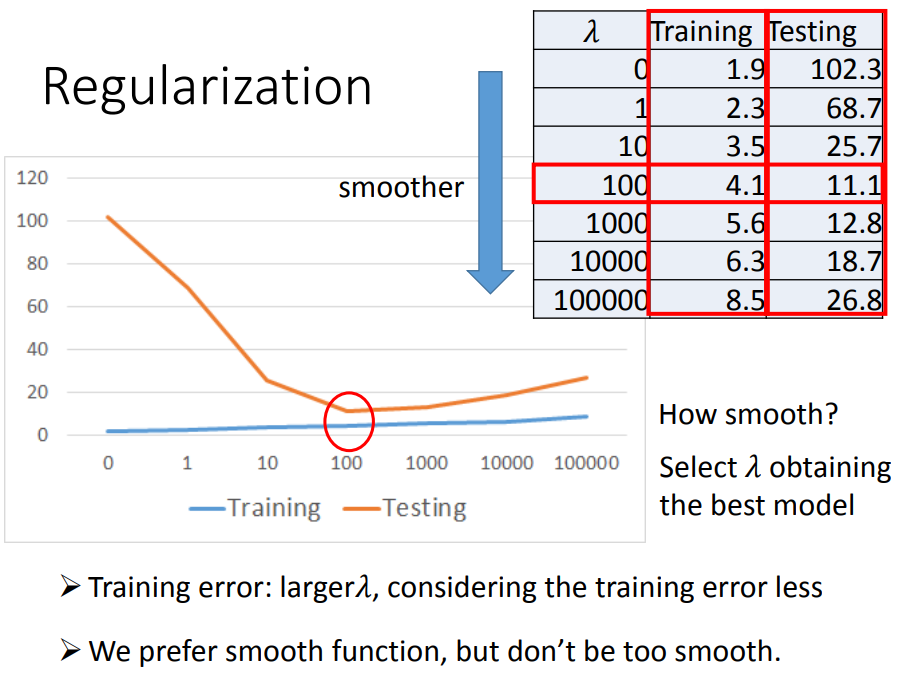
loss function既考虑error,再加上一项额外的smooth(不考虑bias,对平滑没影响),λ是自定的参数(λ越大,表示smooth项的影响越大)。
5、error来自哪里
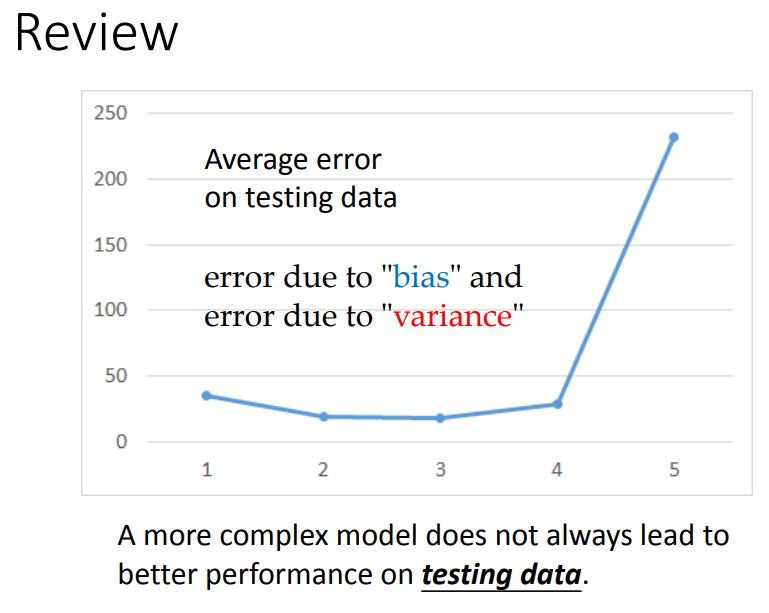
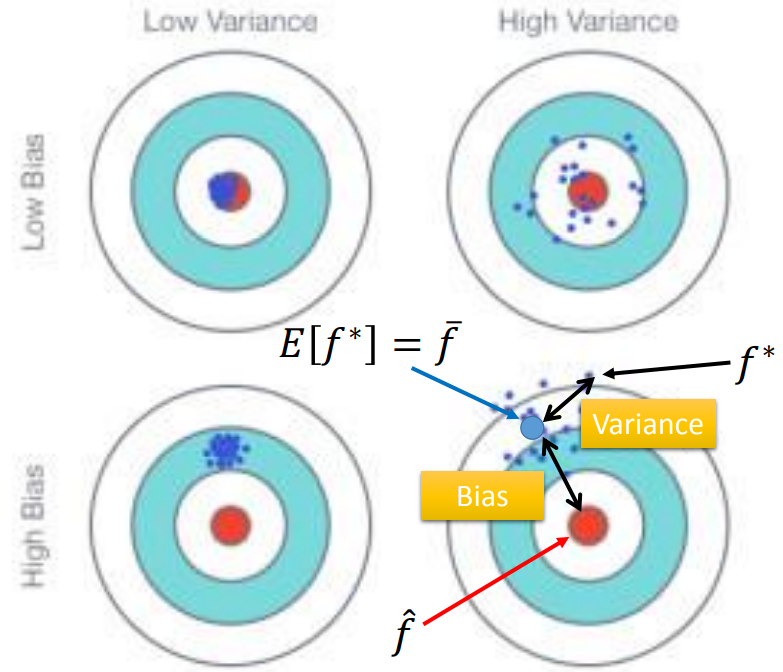
理想状态是没有bias,variance很小。
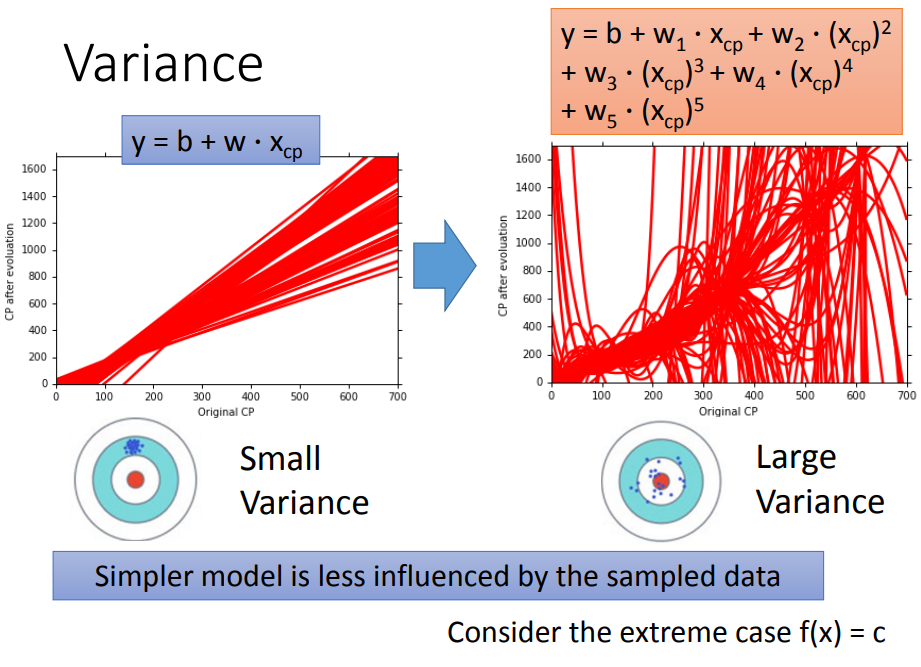
相同模型在100组不同的训练集下,越复杂的模型散布越开(方差越大);
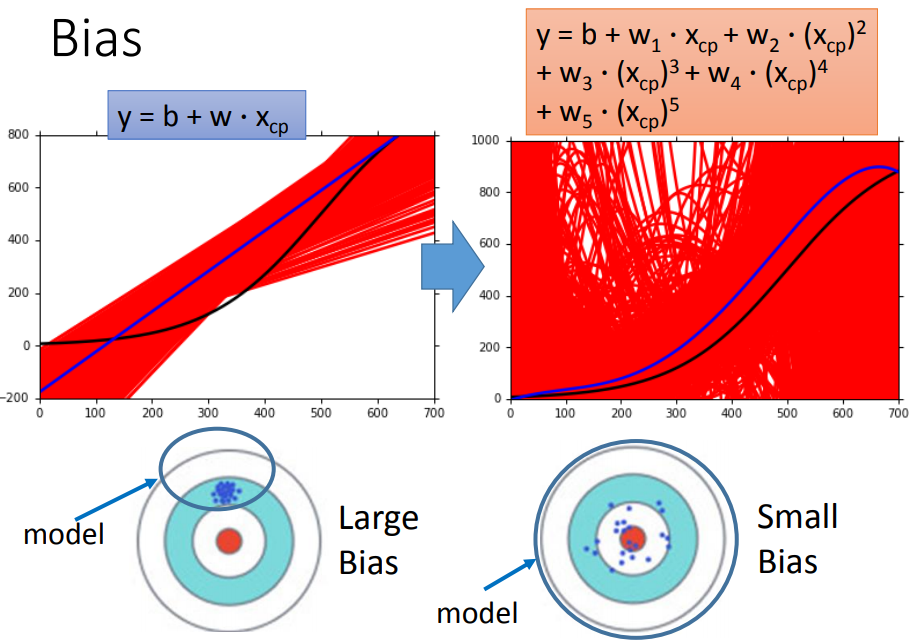
越复杂的model,有越小的bias;因为复杂的model的function set更大,更容易包含target function;
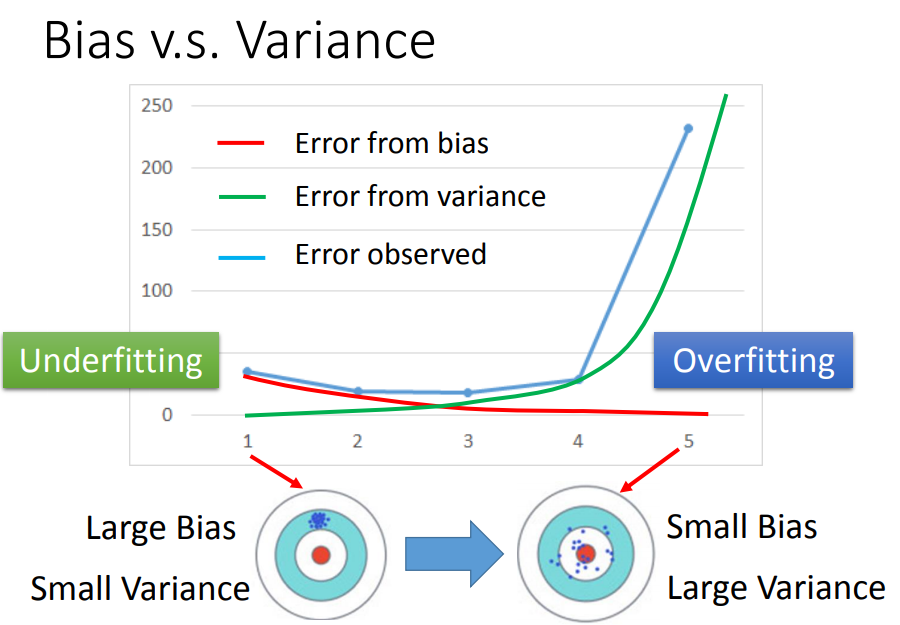

训练集:bias大,欠拟合:增加特征、设计更复杂的模型。
测试集:variance大,过拟合:更多数据、正则化(loss增加smooth,但是只包含平滑的曲线,会影响bias)
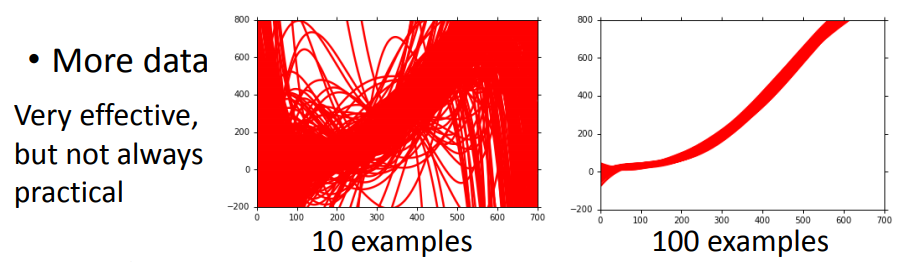
6、交叉验证
 bias与variance的平衡。
bias与variance的平衡。
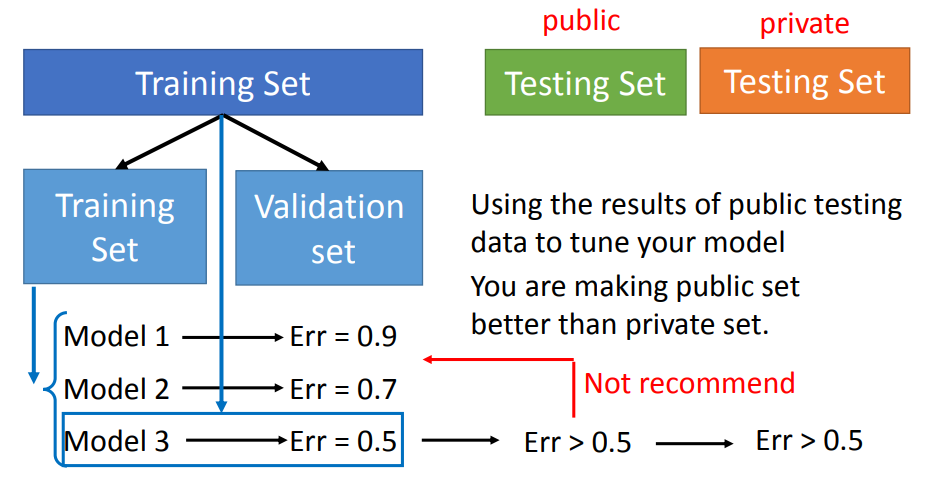 不建议这么做。
不建议这么做。
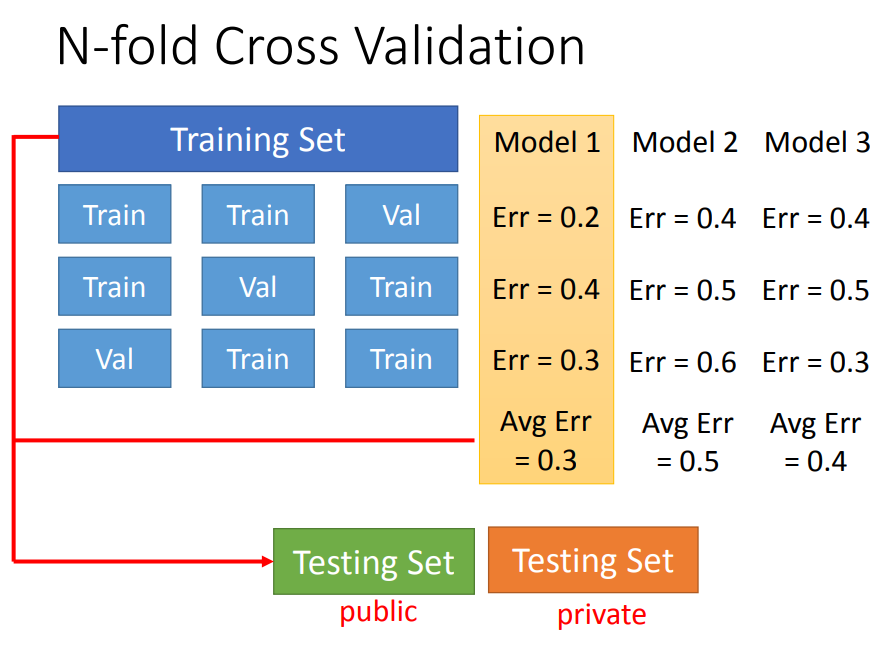
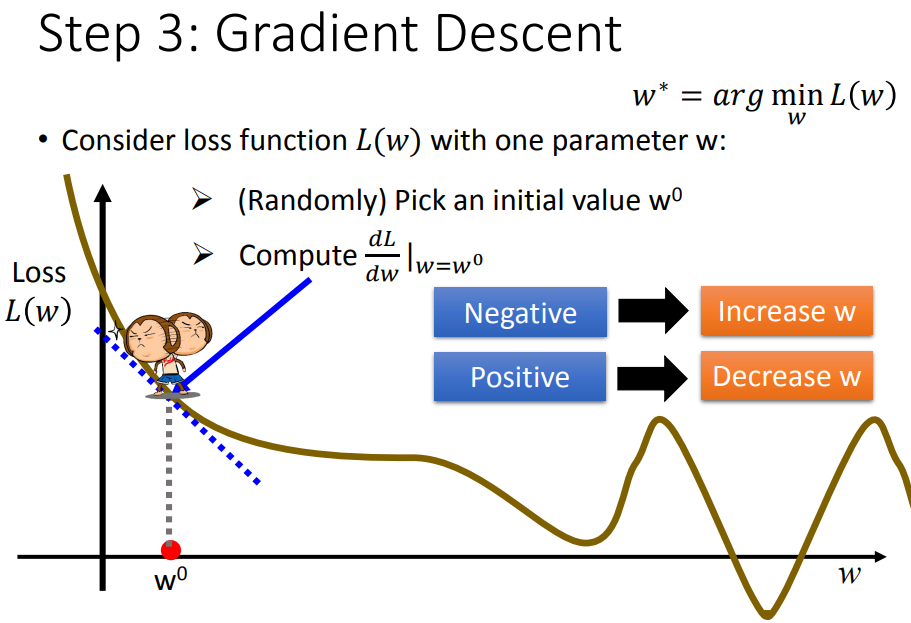
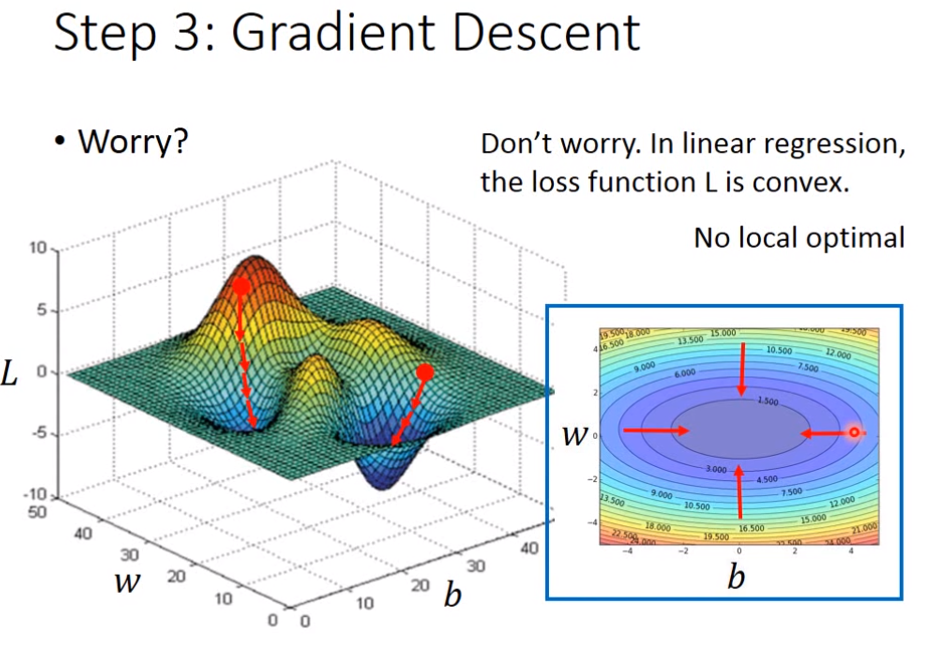
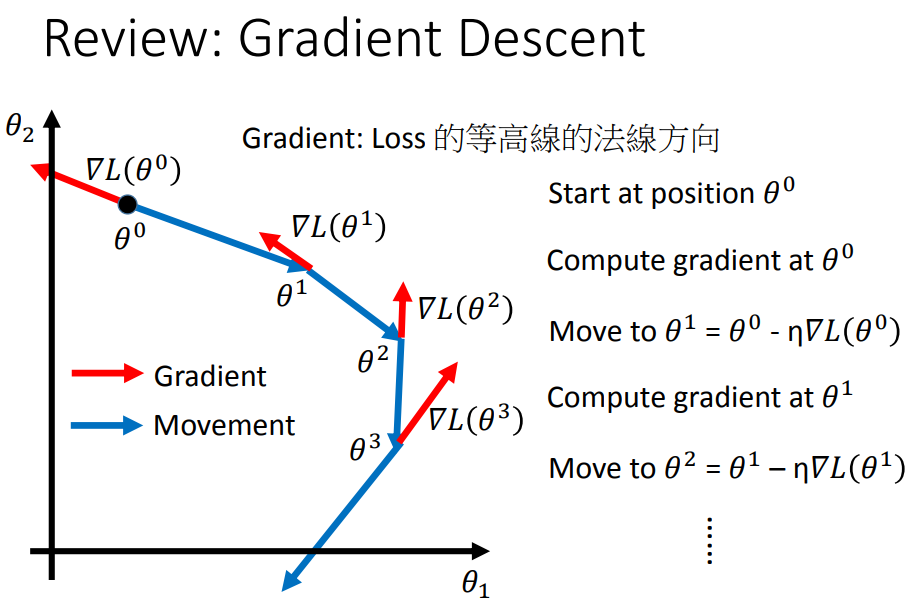
7、梯度下降

8、学习率调整
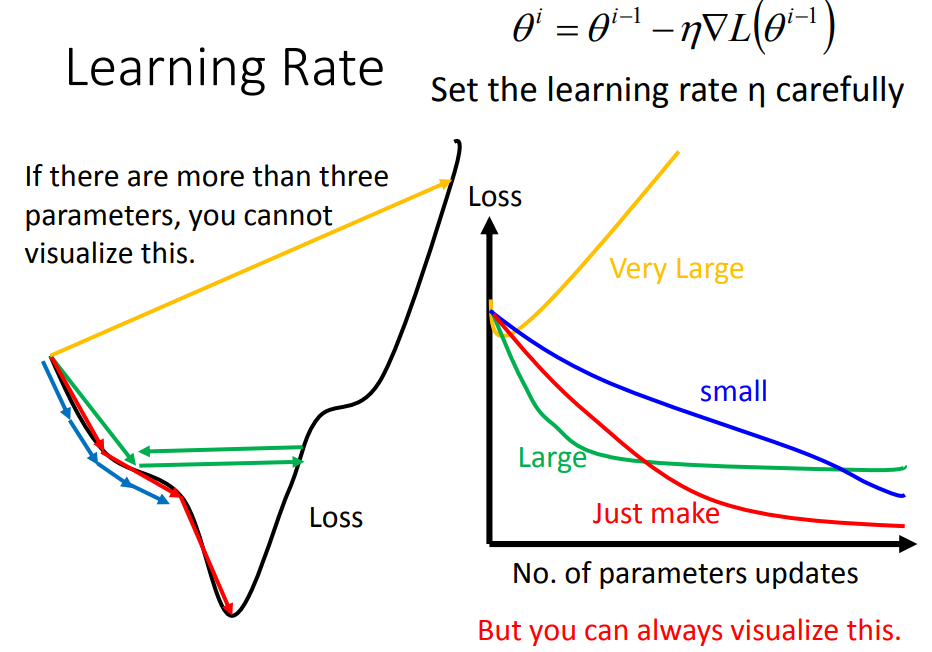
可视化调整学习率。

自动调整学习率:随着参数的update,学习率也要相应的变小,一开始采用大学习率,再逐渐减小学习率。图中公式中的t代表第t次更新参数。

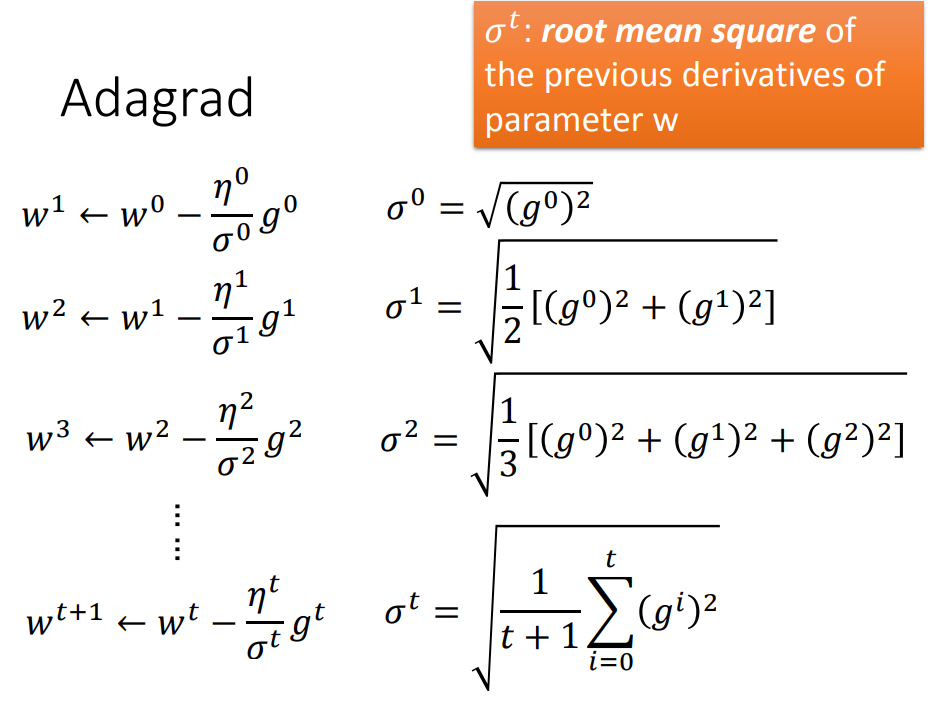
每个参数有不同的学习率;σt是过去所有微分值的平方根;
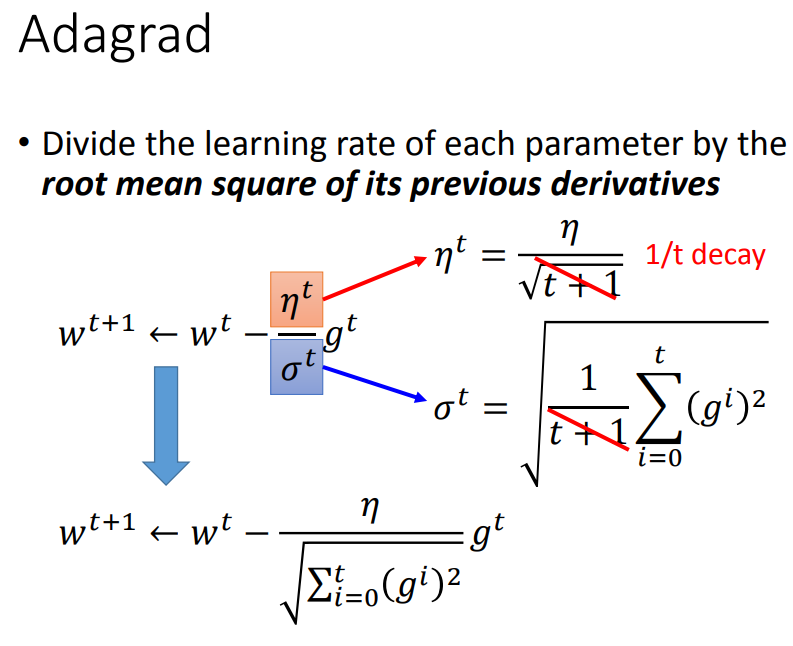
adagrad是比较简单的一种adaptive学习率方法,但使用adagrad方法速度会越来越慢
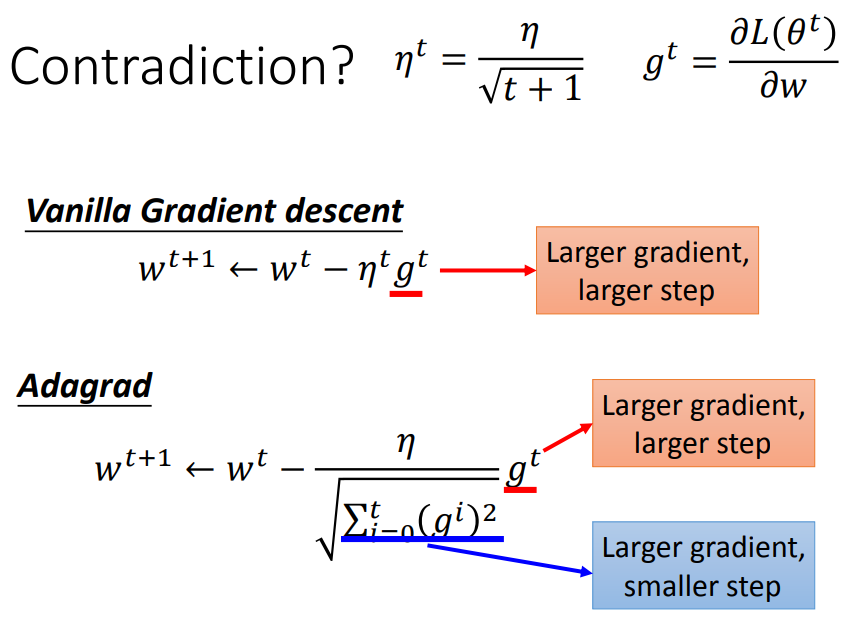

这一项的作用是衡量过去gradient和现在的反差有多大。
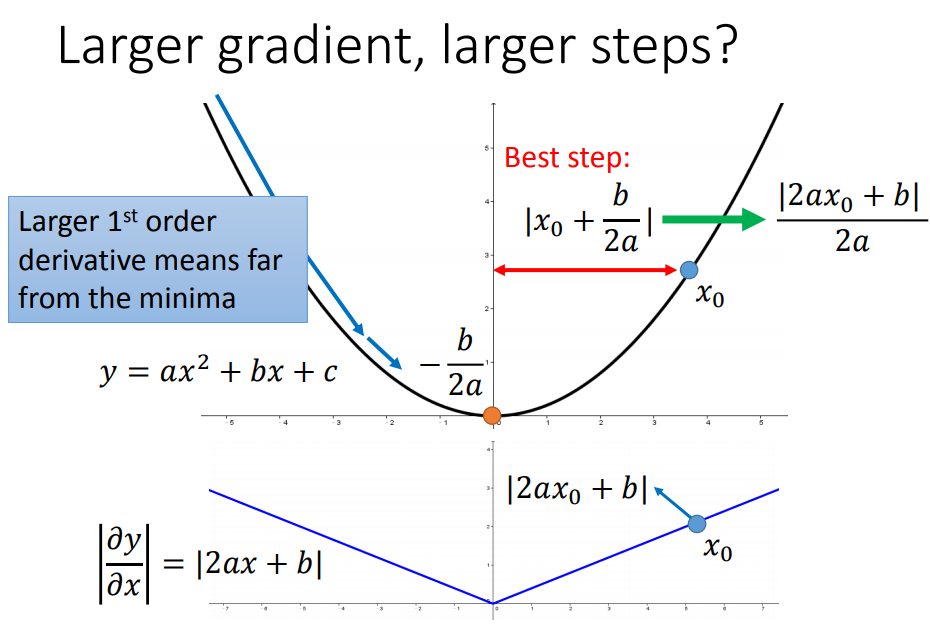
对于一个参数来说,是符合梯度越大,step越大的(|2ax+b|和|x+b/2a|成正比)
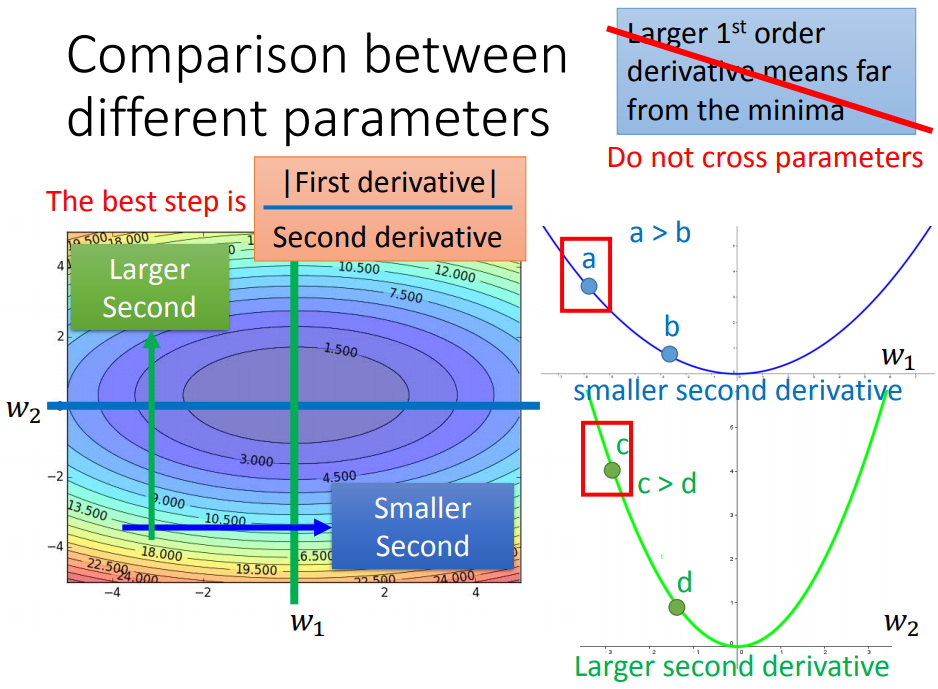
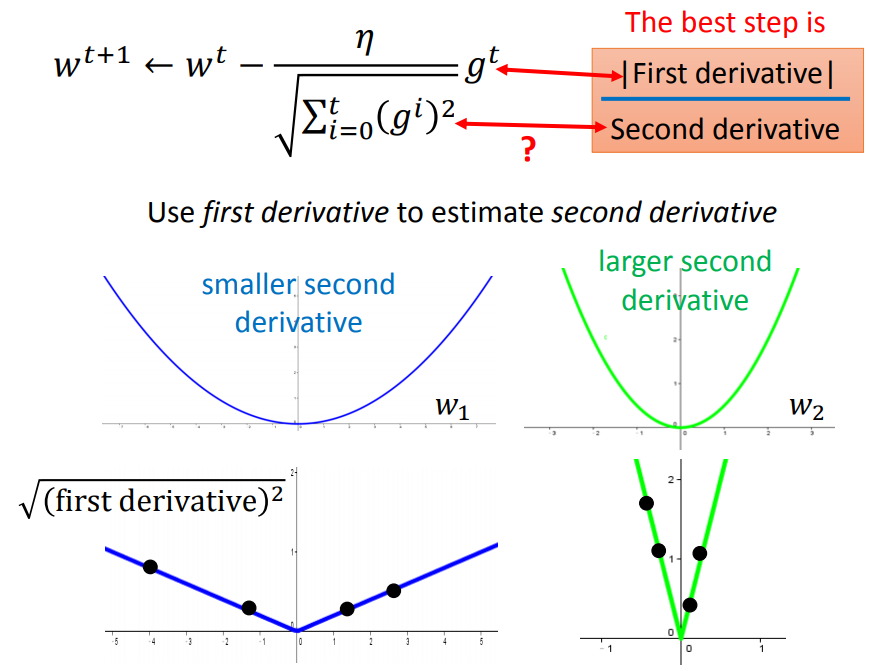
对多个参数来说,step不仅和一阶偏导有关(成正比),还与二阶偏导有关(成反比)。
8、随机梯度下降法(stochastic gradient descent,SGD)
可以使训练更快。

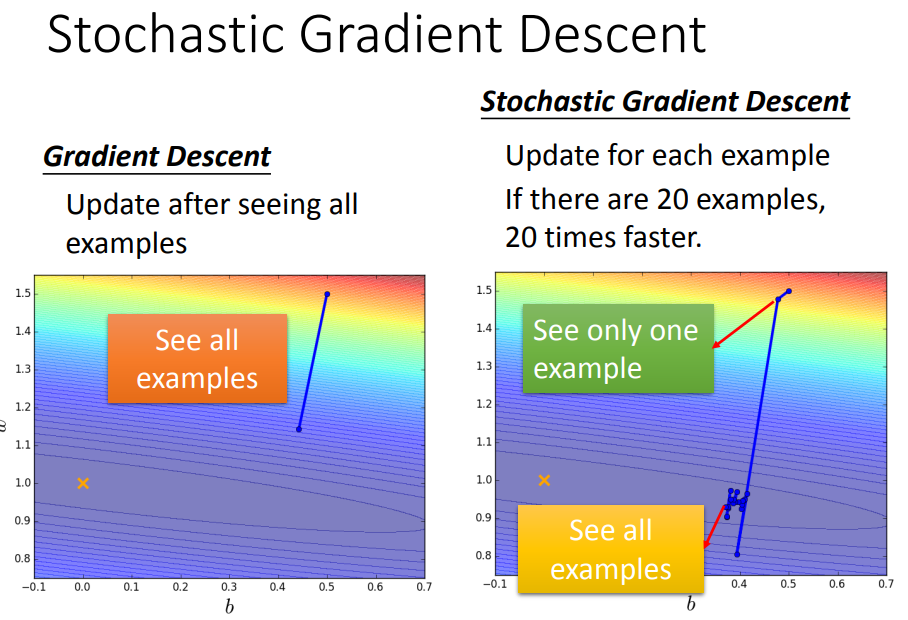
在一般的梯度下降中,计算所有data的loss,然后才更新参数;但在SGD中,只对第n个example来update参数;
9、特征标准化
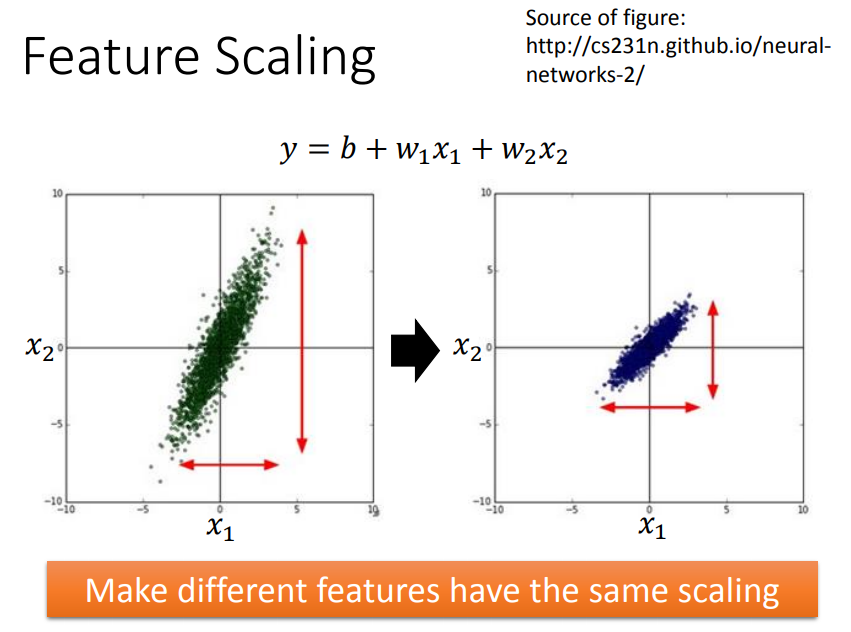
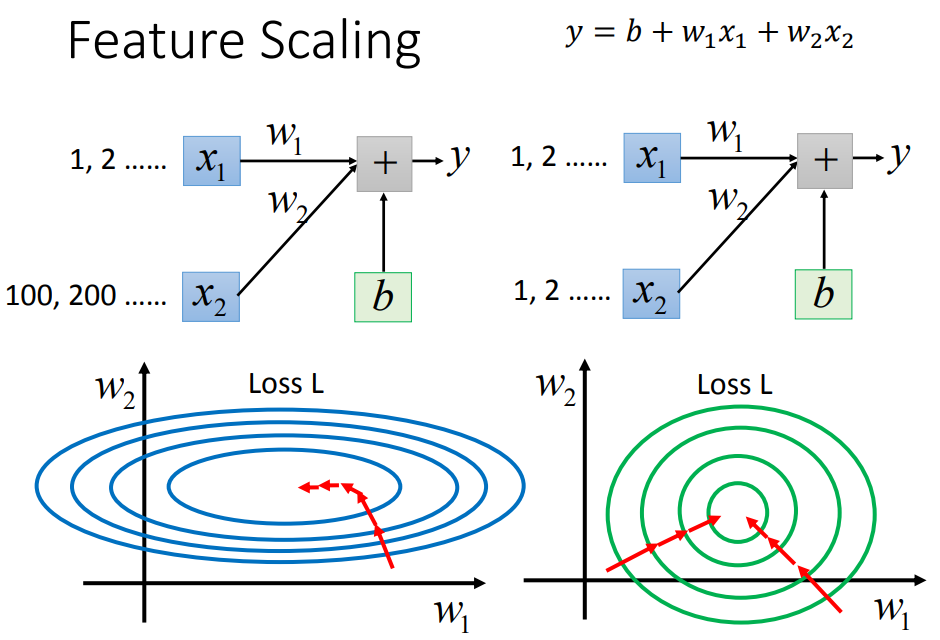
使得不同的w对loss有相同的影响力,在参数update时更加有效率。方法如下:
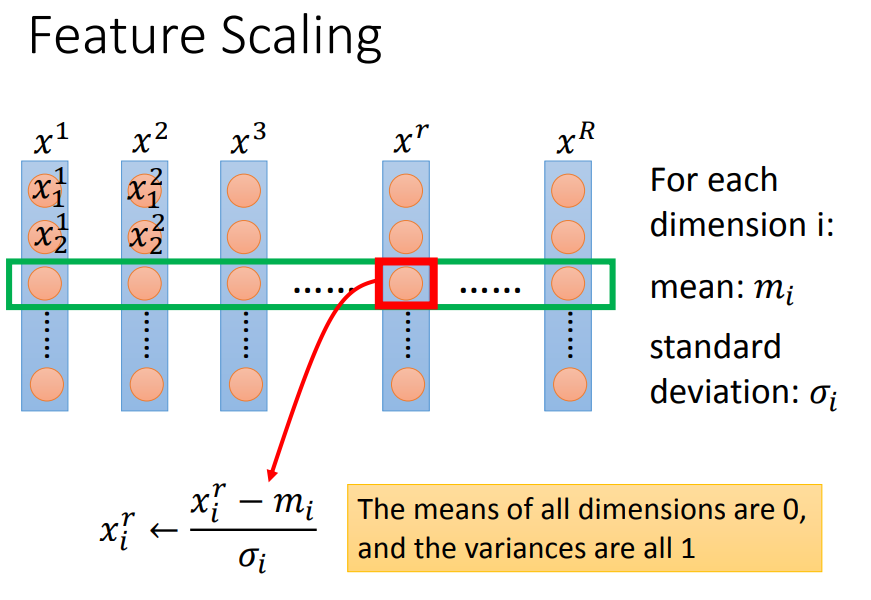
每一行是一个维度,每个维度求平均值和标准差,对这行每一个减去平均值除以标准差。
所有维度平均值是0,方差是1。
10、梯度下降为什么会work
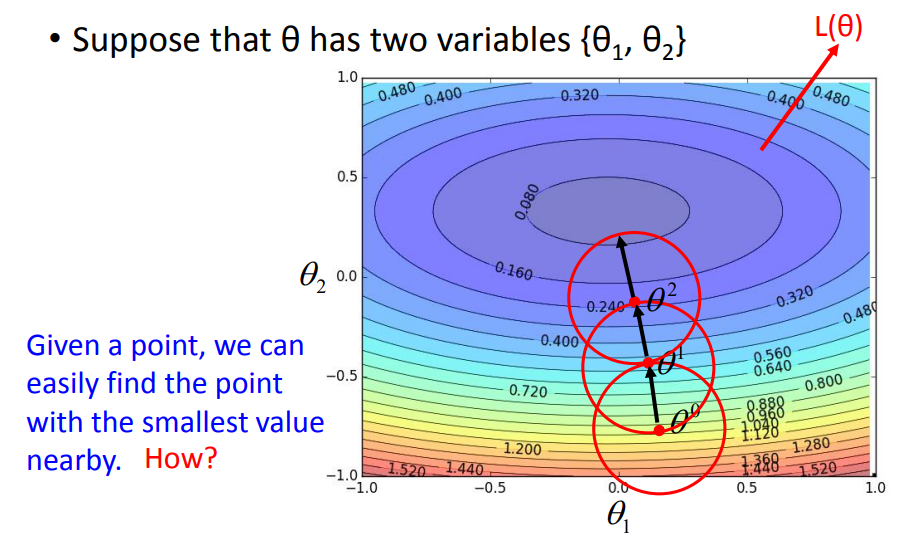
怎样在红圈范围中找到最小点?


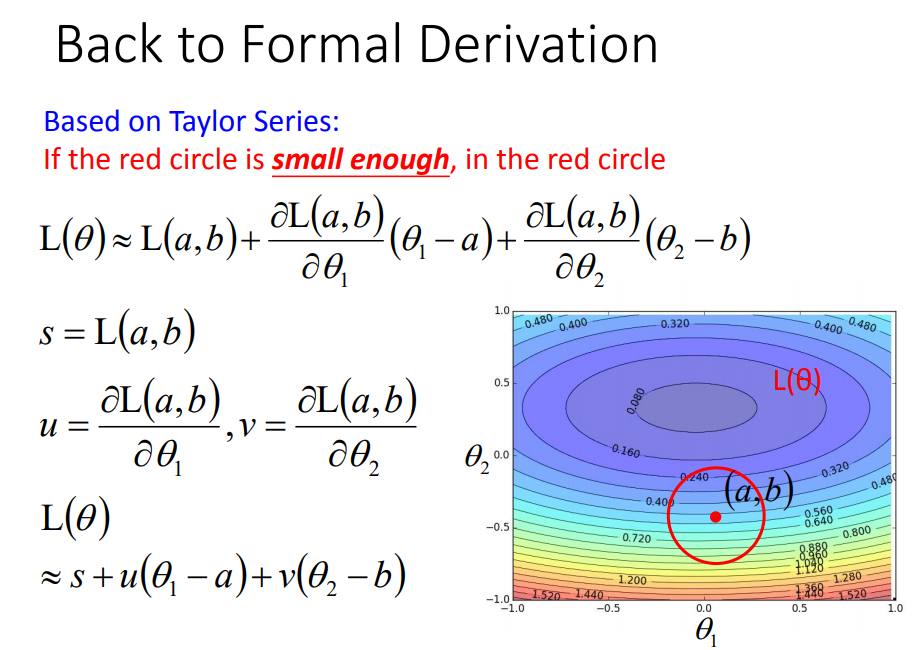

 学习率要足够小才能保证圈足够小,才能保证式子成立,才能保证梯度下降时loss越来越小。
学习率要足够小才能保证圈足够小,才能保证式子成立,才能保证梯度下降时loss越来越小。
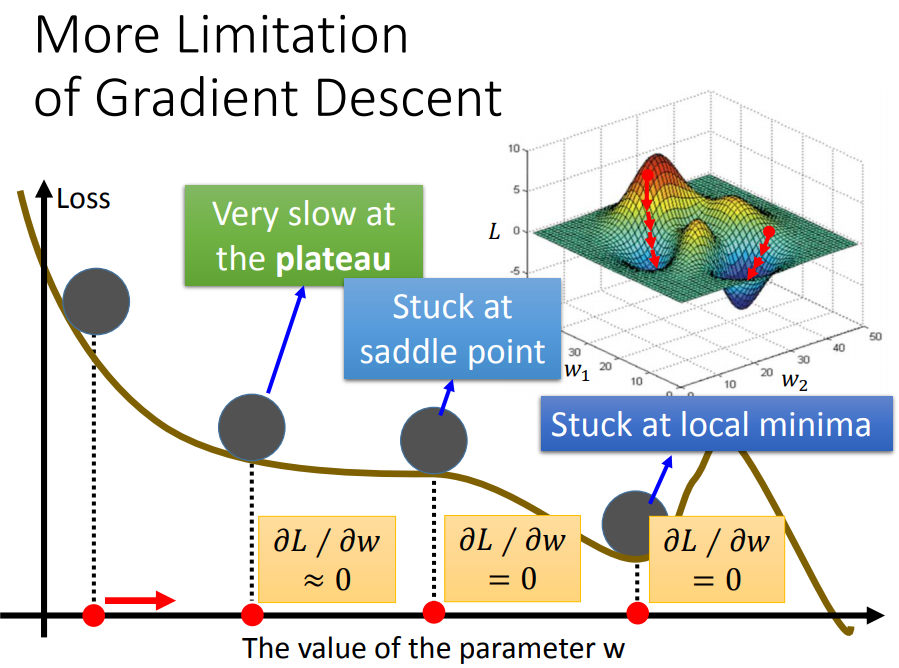
11、梯度下降的限制