


一、验证码识别

不能分割,有些验证码有字母重合的情况。
整体识别:有四个目标值。每个位置有26种可能性(假设都是大写)输出:[None, 4*26]

处理数据
图片[20, 80, 3] 与标签文件一一对应。
不能用listdir直接列图片名,列出来的是乱序的。
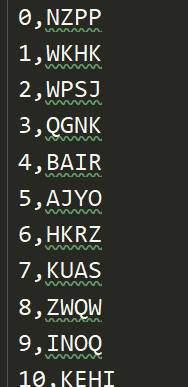
思路:先读图片,再读标签文件,将标签文件的字母转换成数字,最后写入tfrecords
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_string("tfrecords_dir", "./tfrecords/captcha.tfrecords", "验证码") tf.app.flags.DEFINE_string("captcha_dir", "./data/GenPics/", "验证码图片路径") tf.app.flags.DEFINE_string("letter", "ABCDEFGHIJKLMNOPQRSTUVWXYZ", "验证码字符的种类") def get_captcha_image(): """ 获取验证码图片数据 :return: image """ # 构造文件名 filename = [] for i in range(6000): string = str(i) + ".jpg" filename.append(string) # 构造路径+文件 file_list = [os.path.join(FLAGS.captcha_dir, file) for file in filename] # 构造文件队列 file_queue = tf.train.string_input_producer(file_list, shuffle=False) # 构造阅读器 reader = tf.WholeFileReader() # 读取图片数据内容 key, value = reader.read(file_queue) # 解码 image = tf.image.decode_jpeg(value) image.set_shape([20, 80, 3]) # 批处理 image_batch = tf.train.batch([image],batch_size=6000, num_threads=1, capacity=6000) return image_batch def get_captcha_label(): """ 读取验证码图片标签数据 :return: label """ # 不指定shuffle就会乱序 file_queue = tf.train.string_input_producer(["./data/GenPics/labels.csv"], shuffle=False) reader = tf.TextLineReader() key, value = reader.read(file_queue) # 解码 records = [[1], ["None"]] # 一列是int,一列是字符串 number, label = tf.decode_csv(value, record_defaults=records) # 批处理 只需要label label_batch = tf.train.batch([label], batch_size=6000, num_threads=1, capacity=6000) return label_batch def dealwithlabel(label_str): # 构建字符索引 {0:'A', 1:'B'......} # 把letter转化成列表,然后用enumerate加上序列,然后转化成字典 num_letter = dict(enumerate(list(FLAGS.letter))) # 键值对反转 {'A':0, 'B':1......} # zip打包成元组,再把元组列表转化成字典 letter_num = dict(zip(num_letter.values(), num_letter.keys())) print(letter_num) # 构建标签的列表 label_array = [] # 对标签数据进行处理 for string in label_str: # [[b"NZBF"]...] num_list = [] # 修改编码,b'BVCF'到字符串,并且循环找到每张验证码的字符对应的数字标记 for letter in string.decode('utf-8'): # 每一个字母,在字典中找出对应的数字 num_list.append(letter_num[letter]) # 存到标签列表中 [[13,25,17,2],[14,6,18,18]] label_array.append(num_list) print(label_array) # 把列表转换成tensor类型,二维[[13,25,17,2],[14,6,18,18]] label = tf.constant(label_array) return label def write_to_tfrecords(image_batch, label_batch): """ 将图片内容和标签写入到tfrecords文件当中 :param image_batch:特征值 :param label_batch:标签值 :return: None """ # 转换类型 label_batch = tf.cast(label_batch, tf.uint8) # 建立tfrecords存储器 writer = tf.python_io.TFRecordWriter(FLAGS.tfrecords_dir) # 循环将每一个图片上的数据构造example协议块 for i in range(6000): # 取出第i个图片数据,转换相应类型,图片的特征值要转换成字符串形式 image_string = image_batch[i].eval().tostring() # 取出第i个标签值,多个目标值不能用int存,所以也要转成string label_string = label_batch[i].eval().tostring() # 构造协议块 example = tf.train.Example(features=tf.train.Features(feature={ "image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_string])), "label": tf.train.Feature(bytes_list=tf.train.BytesList(value=[label_string])) })) writer.write(example.SerializeToString()) # 关闭文件 writer.close() return None if __name__ == '__main__': # 获取验证码文件当中的图片 image_batch = get_captcha_image() # 获取验证码文件当中的标签数据 label = get_captcha_label() print(image_batch, label) with tf.Session() as sess: coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) label_str = sess.run(label) # b'NZPP' b'WKHK' print(label_str) # 处理字符串标签到数字张量 label_batch = dealwithlabel(label_str) # 将图片数据和内容写入到tfrecords文件当中 write_to_tfrecords(image_batch, label_batch) coord.request_stop() coord.join(threads)
识别验证码
1、从tfrecords读取 每张图片有image, label:[100, 20, 80, 3] [100, 4]([[23,16,18,23],[4,17,9,10]])
2、建立模型,直接读取数据输入模型当中(全连接层)
x = [100, 20*80*3] w=[20*80*3, 100] y_predict=[100, 4*26] bias=[4*26]
3、建立损失:softmax,交叉熵损失
目标值要转成one-hot编码 [[0,0,0,1,0,...],[0,0,1,0,0,0,...],[0,0,0,...,1],[0,0,0,0,0,0,1,...]]
tf.one_hot(y_true, depth=26, axis=2, on_value=1.0)
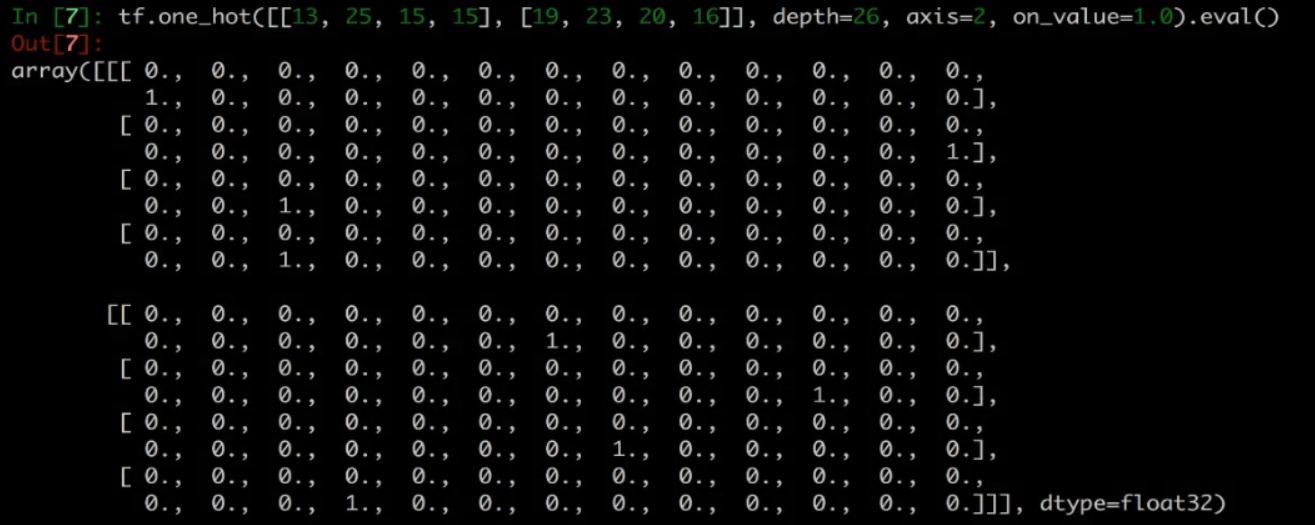
[100, 4] ---> [100, 4, 26] ----> [100, 4*26] 然后与预测值进行交叉熵损失计算
1*log(0.23)+ 1*log() + 1*log() + 1*log() = -损失值
4、梯度下降优化
计算准确率:每个样本要比较四次tf.argmax()位置是否相同,有一个不同就记为0
tf.argmax(预测值,2)

import tensorflow as tf FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_string("captcha_dir", "./tfrecords/captcha.tfrecords", "验证码数据的路径") def read_and_decode(): """ 读取数据并解码 :return: image_batch, label_batch """ # 1 构建文件队列 file_queue = tf.train.string_input_producer([FLAGS.captcha_dir]) # 2 构建阅读器,读取文件内容,默认一个样本 reader = tf.TFRecordReader() key, value = reader.read(file_queue) # 3 解码 # tfrecords文件要进行example解析 features = tf.parse_single_example(value, features={ "image": tf.FixedLenFeature([], tf.string), "label": tf.FixedLenFeature([], tf.string) }) # 解码字符串内容 # 先解析图片的特征值,用uint8 image = tf.decode_raw(features["image"], tf.uint8) # 解码图片目标值 label = tf.decode_raw(features["label"], tf.uint8) # 4 改变形状,批处理的时候形状要固定 image_reshape = tf.reshape(image, [20, 80, 3]) label_reshape = tf.reshape(label, [4]) # 5 批处理,每批次读取100个 image_batch, label_batch = tf.train.batch([image_reshape, label_reshape], batch_size=100, num_threads=1, capacity=100) print(image_batch, label_batch) return image_batch, label_batch def fc_model(image): """ 进行预测 :param image: 100图片特征值[100, 20, 80, 3] :return: y_predict [100, 4*26] """ with tf.variable_scope("model"): # 随机初始化权重和偏置 weights = weight_variables([20*80*3, 4*26]) bias = bias_variables([4*26]) # 图片形状转成二维 image_reshape = tf.reshape(image, [100, 20*80*3]) # 进行全连接层计算,矩阵运算只能是float类型 y_predict = tf.matmul(tf.cast(image_reshape, tf.float32), weights) + bias return y_predict def weight_variables(shape): w = tf.Variable(tf.random_normal(shape=shape, mean=0.0, stddev=1.0)) return w def bias_variables(shape): b = tf.Variable(tf.constant(0.0, shape=shape)) return b def ytrue_to_onehot(label): """ 将读取文件当中的目标值转换成onehot编码 :param label_batch: [100, 4] [[12,13,5,22],[3,3,25,20]...] :return: onehot [[[0,0,0,1,0...],[0,0,0,1,0,...]...],[[...],[...]...]] """ label_onehot = tf.one_hot(label, depth=26, on_value=1.0, axis=2) return label_onehot def captcharec(): """ 验证码识别程序 :return: """ # 1 从tfrecords读取验证码的数据文件 image_batch, label_batch = read_and_decode() # 2 通过输入图片特征数据,建立模型得出预测结果 # 一层全连接神经网络进行预测 # matrix [100, 20, 80, 3]-->[100, 20*80*3] * [20*80*3, 4*26] +[4*26] = [100, 4*26] y_predict = fc_model(image_batch) print(y_predict) # 3 先把目标值转换成one-hot编码 y_true = ytrue_to_onehot(label_batch) # 4 softMax计算,交叉熵损失计算 # 必须转成二维的 with tf.variable_scope("soft_cross"): loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=tf.reshape(y_true, [100, 4*26]), logits=y_predict)) # 5 梯度下降优化损失 with tf.variable_scope("optimizer"): train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss) # 6 求出每批次预测的准确率 with tf.variable_scope("acc"): # 比较预测值和目标值位置是否一样(每个样本有四个位置,全部一样才为1) # [100, 4, 26] 必须转成三维的 # 0 1 2 equal_list = tf.equal(tf.argmax(y_true, 2), tf.argmax(tf.reshape(y_predict, [100, 4, 26]), 2)) accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32)) # 7 开启会话训练 init_op = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init_op) # 定义线程协调器和开启线程(因为有数据在文件中读取提供给模型) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess, coord=coord) # 训练识别程序 for i in range(4000): sess.run(train_op) print("第%d批次的准确率为%f" % (i, accuracy.eval())) # 回收线程 coord.request_stop() coord.join(threads) return None if __name__ == "__main__": captcharec()

二、分布式
1、分布式tensorflow
由高性能的gRPC(Google remote procedure call )框架作为底层技术来支持的。这是一个通信框架,是一个高性能、跨平台的RPC框架。
RPC协议,即远程过程调用协议,指通过网络从远程计算机程序上请求服务。(对于底层协议的封装,解决一些传输错误和同步的问题,常用于分布式、视频会议等)


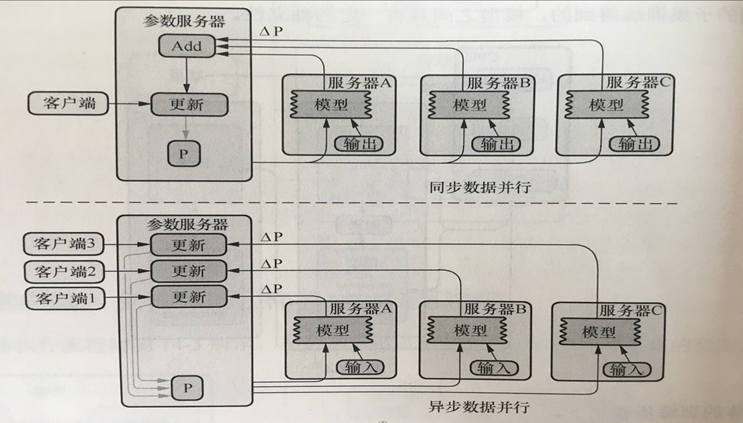
多机多卡分布式的架构:
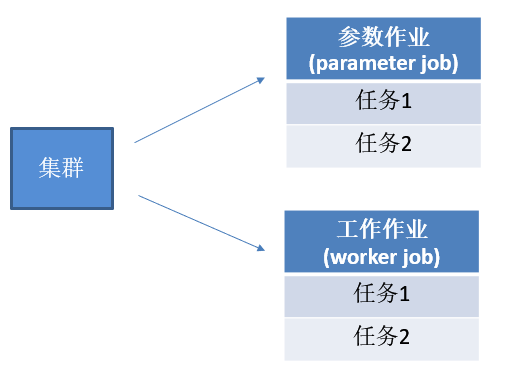
参数作业所在的服务器称为参数服务器(parameter server),负责管理参数的存储和更新;
工作节点的服务器主要从事计算的任务,如运行操作,worker节点中需要一个主节点来进行会话初始化,创建文件等操作,其他节点等待进行计算。
分布式更新参数的模式:
① 同步模式更新:得到所有服务器每批次梯度的变化量,再取平均值,更新权重;
② 异步模式更新:服务器不用互相等待,每批次运行完就把梯度的变化量传到参数服务器,不断求平均值;
2、分布式API
① 创建集群
创建一个tf.train.ClusterSpec,用于对集群中的所有任务进行描述,该描述内容对所有任务应该是相同的
- tensorflow设备命名规则:
- /job:ps/task:0 参数服务器(可以有多台)
- /job:worker/task:0 工作服务器(可以有多台)
- /job:worker/task:0/cpu:0
- /job:worker/task:1/gpu:0
cluster = tf.train.ClusterSpec({"ps": ps_spec, "worker": worker_spec})
cluster = tf.train.ClusterSpec( {“worker”: [“worker0.example.com:2222”, # /job:worker/task:0
“worker1.example.com:2222”, # /job:worker/task:1
“worker2.example.com:2222”], # /job:worker/task:2 "ps": [“ps0.example.com:2222”, # /job:ps/task:0
“ps1.example.com:2222”] # /job:ps/task:1 })
端口随便指定,不要与常用的端口冲突。
② 创建服务
创建一个tf.train.Server,用于创建一个任务(ps,worker),并运行相应作业上的计算任务。
tf.train.Server(server_or_cluster_def, job_name=None, task_index=None, protocol=None, config=None, start=True)
- 创建服务(ps,worker)
- server_or_cluster_def: 集群描述(cluster)
- job_name: 任务类型名称
- task_index: 任务数
- attribute:target 返回tf.Session连接到此服务器的目标
- method:join() 用于参数服务器端,直到服务器等待接受参数任务关闭
③ 工作节点指定设备运行
tf.device(device_name_or_function)
- 选择指定设备或者设备函数
- if device_name:
- 指定设备
- 例如:"/job:worker/task:0/cpu:0”
- if function:
- tf.train.replica_device_setter(worker_device=worker_device, cluster=cluster)
- 作用:通过此函数协调不同设备上的初始化操作
- worker_device:为指定设备, “/job:worker/task:0/cpu:0” or "/job:worker/task:0/gpu:0"
- cluster:集群描述对象
④ 开启会话
分布式不能用tf.Session()
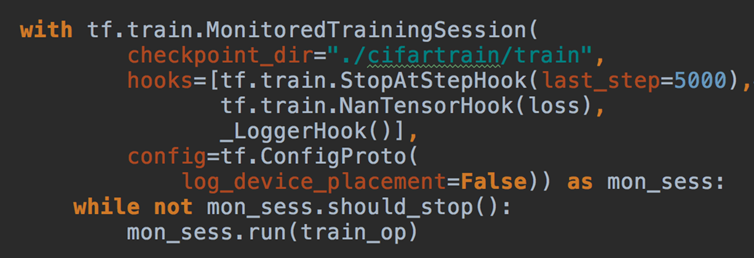
MonitoredTrainingSession(master='',is_chief=True,checkpoint_dir=None, hooks=None,save_checkpoint_secs=600,save_summaries_steps=USE_DEFAULT,save_summaries_secs=USE_DEFAULT,config=None)
- 分布式会话函数
- master:指定运行会话协议IP和端口(用于分布式)“grpc://192.168.0.1:2000”
- is_chief是否为主worker(用于分布式)
- 如果True,它将负责初始化和恢复基础的TensorFlow会话。如果False,它将等待一位负责人初始化或恢复TensorFlow会话。
- checkpoint_dir:检查点文件目录,同时也是events目录
- config:会话运行的配置项, tf.ConfigProto(log_device_placement=True)
- hooks:可选SessionRunHook对象列表(相当于指定循环次数)
- should_stop():是否异常停止
- run():跟session一样可以运行op
tf.train.SessionRunHook
Hook to extend calls to MonitoredSession.run()
- ① begin(): 在会话之前,做初始化工作
- ② before_run(run_context) 在每次调用run()之前调用,以添加run()中的参数。
- run_context:一个SessionRunContext对象,包含会话运行信息
- return:一个SessionRunArgs对象,例如:tf.train.SessionRunArgs(loss)
- ③ after_run(run_context,run_values) 在每次调用run()后调用,一般用于运行之后的结果处理
- 该run_values参数包含所请求的操作/张量的结果 before_run()。
- 该run_context参数是相同的一个发送到before_run呼叫。
- run_context:一个SessionRunContext对象
- run_values一个SessionRunValues对象, run_values.results
- 再添加钩子类的时候,继承SessionRunHook
常用钩子:
tf.train.StopAtStepHook(last_step=5000)
- 指定执行的训练轮数也就是max_step,超过了就会抛出异常
tf.train.NanTensorHook(loss)
- 判断指定Tensor是否为NaN,为NaN则结束
在使用钩子的时候需要定义一个全局步数:global_step = tf.contrib.framework.get_or_create_global_step()
小结:
① 对集群当中的一些ps,worker进行指定。
② 创建对应的服务,ps服务(join等待)、worker服务(运行模型 程序 初始化会话),初始化会指定一个默认的worker去做。
③ worker如何使用设备:
- with tf.device("/job:worker/task:0/gpu:0") : 计算等
- with tf.device(tf.train.replica_device_setter(worker_device="/job:worker/task:0/cpu:0", cluster=cluster))
- 分布式得使用第二种,指定cluster才能同步数据
3、分布式案例
① 创建集群对象
② 创建服务
③ 服务端等待接收参数
④ 客户端使用不同设备进行定义模型以进行计算
⑤ 使用高级会话类
import tensorflow as tf FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_string("job_name", " ", "启动服务的类型 ps or worker") tf.app.flags.DEFINE_integer("task_index", 0, "指定ps或worker中的第几台服务器") def main(argv): # 使用钩子必须定义全局计数的op,给钩子列表当中的训练步数计数使用,这个参数钩子会自动获取 global_step = tf.contrib.framework.get_or_create_global_step() # 指定集群描述对象,一个参数服务器,一个工作服务器 cluster = tf.train.ClusterSpec({'ps': ["10.211.55.3:2222"], 'worker': ["192.168.0.116:2222"]}) # 创建不同的服务 server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index) # 根据不同服务做不同的事情 ps:更新保存参数 worker:指定设备去运行模型计算 if FLAGS.job_name == "ps": # 参数服务器什么都不用干,只需要等待worker传递参数 server.join() else: worker_device = "/job:worker/task:0/cup:0" # 可以指定设备去运行(CPU/GPU) with tf.device(tf.train.replica_device_setter( worker_device = worker_device, cluster = cluster )): # 简单做一个矩阵乘法运算 a = tf.Variable([[1, 2, 3, 4]]) b = tf.Variable([[2], [2], [2], [2]]) mat = tf.matmul(a, b) # 创建分布式会话 with tf.train.MonitoredTrainingSession( master = "grpc://192.168.0.116:2222", # 指定主worker is_chief = (FLAGS.task_index == 0), # 判断是否是主worker config = tf.ConfigProto(log_device_placement=True), # 打印设备信息 hooks = [tf.train.StopAtStepHook(last_step=200)], # 钩子,在这里可以替代for循环 ) as mon_sess: while not mon_sess.should_stop(): mon_sess.run(mat) if __name__ == '__main__': tf.app.run() # 默认调用main函数,mian函数必须有argv参数
在虚拟机中启动ps
![]()
在本机启动worker
![]()
ps中取值,worker中计算,返回到ps

