一、神经网络基础
1、感知机
Rosenblatt在1957年,于Cornell航空实验室时所发明的一种人工神经网络
有n个输入数据,通过权重与各数据之间的计算和,比较激活函数结果,得出输出
感知机用来解决分类问题。
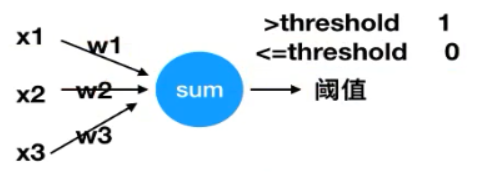
还不能称为激活函数,只是简单的阈值比较
应用:很容易解决与、或、非问题。如输入x1 x2为1,w1 w2为1,输出为2,阈值设为1.5,就解决了与问题。
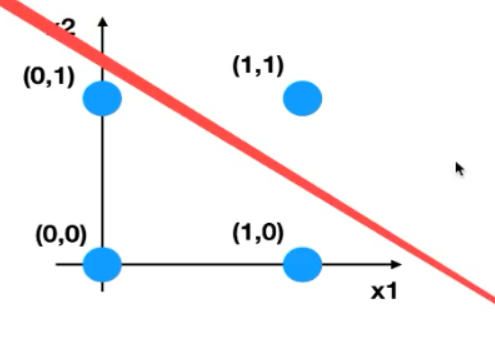
单个感知机解决不了的问题,可以增加感知机。如异或问题,可以用如下简单的方式解决:
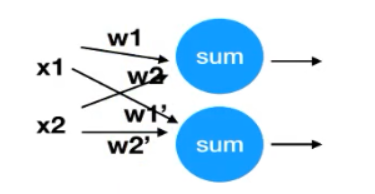
模拟神经网络:
http://playground.tensorflow.org/#activation=sigmoid®ularization=L2&batchSize=10&dataset=circle®Dataset=reg-plane&learningRate=0.03®ularizationRate=0&noise=0&networkShape=3&seed=0.84062&showTestData=false&discretize=false&percTrainData=50&x=true&y=true&xTimesY=false&xSquared=false&ySquared=false&cosX=false&sinX=false&cosY=false&sinY=false&collectStats=false&problem=classification&initZero=false&hideText=false&showTestData_hide=true&learningRate_hide=true®ularizationRate_hide=true&percTrainData_hide=true&numHiddenLayers_hide=true&discretize_hide=true&activation_hide=true&problem_hide=true&noise_hide=true®ularization_hide=true&dataset_hide=true&batchSize_hide=true&playButton_hide=false
一个感知机相当于建立了一条直线:
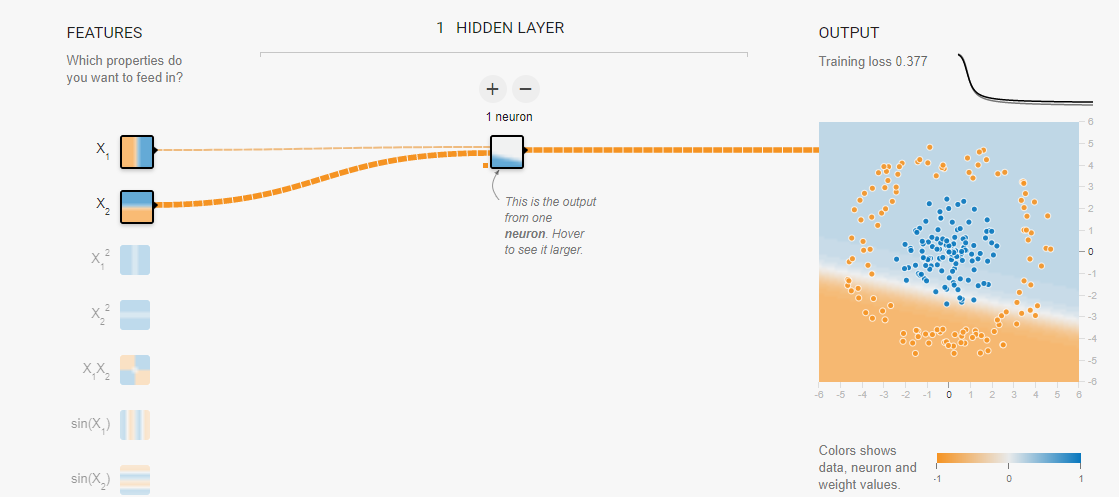
增加一个感知机的结果:
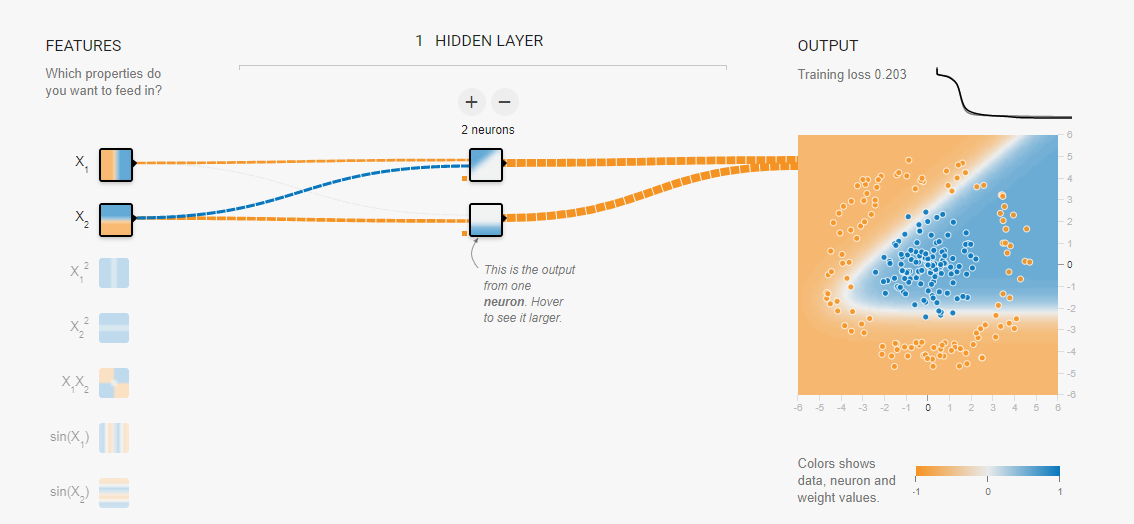
三个感知机的结果:
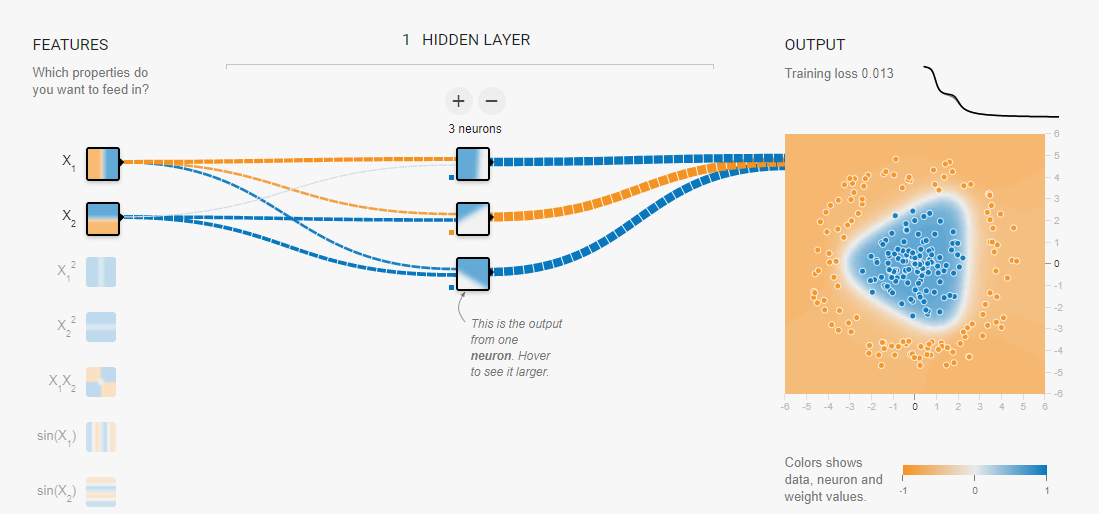
2、人工神经网络
定义:在机器学习和认知科学领域,人工神经网络(artificial neural network,缩写ANN),简称神经网络(neural network,缩写NN)或类神经网络,是一种模仿生物神经网络的结构和功能的计算模型,用于对函数进行估计或近似。
神经网络的种类:
基础神经网络:单层感知器,线性神经网络,BP神经网络,Hopfield神经网络等
进阶神经网络:玻尔兹曼机,受限玻尔兹曼机,递归神经网络等
深度神经网络:深度置信网络,卷积神经网络,循环神经网络,LSTM网络等
杰弗里·埃弗里斯特·辛顿 (英语:Geoffrey Everest Hinton)(1947年12月6日-)是一位英国出生的计算机学家和心理学家,以其在神经网络方面的贡献闻名。辛顿是反向传播算法的发明人之一,也是深度学习的积极推动者。
感知机---->神经元-----多个----->神经网络
不同的结构解决不同的问题
神经网络的特点:
- 输入向量的维度和输入神经元的个数相同
- 每个连接都有个权值
- 同一层神经元之间没有连接
- 由输入层,隐层,输出层组成
- 第N层与第N-1层的所有神经元连接,也叫全连接
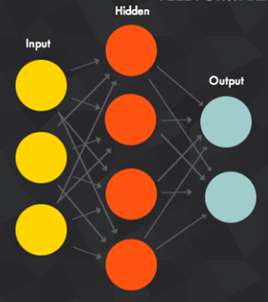
神经网络的组成
- 结构(Architecture):例如,神经网络中的变量可以是神经元连接的权重
- 激励函数(Activity Rule):大部分神经网络模型具有一个短时间尺度的动力学规则,来定义神经元如何根据其他神经元的活动来改变自己的激励值。
- 学习规则(Learning Rule):学习规则指定了网络中的权重如何随着时间推进而调整。(反向传播算法)
3、神经网络API模块
在使用tensorflow时候,tf.nn,tf.layers,tf.contrib模块有很多功能是重复的
tf.nn:提供神经网络相关操作的支持,包括卷积操作(conv),池化操作(pooling),归一化,loss,分类操作,embedding,RNN,Evaluation
tf.layers:主要提供的高层神经网络,主要和卷积相关的,对tf.nn进一步封装
tf.contrib:tf.contrib.layers提供能够将计算图中的网络层 正则化 摘要操作 是构建计算图的高级操作,但是tf.contrib包不稳定有一些实验代码
4、浅层人工神经网络模型
(1)softMax回归
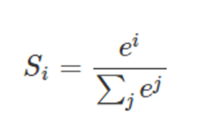
最后得出的是个概率值:
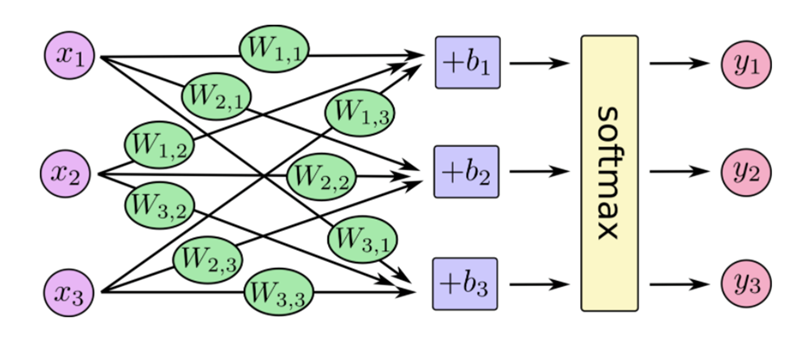
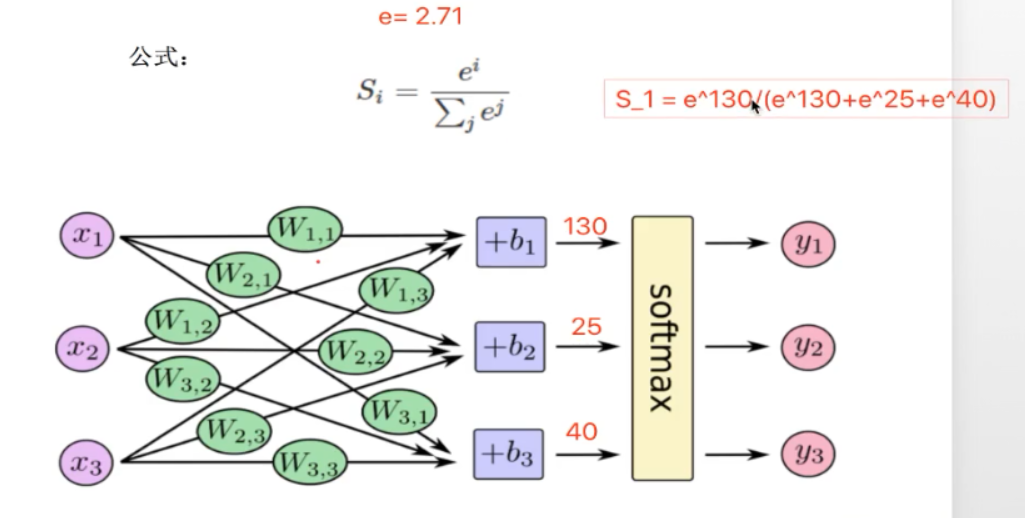
softMax作用:
计算概率值;
使得所有类别的概率值相加都等于1 ;
(2)损失计算API
交叉熵损失
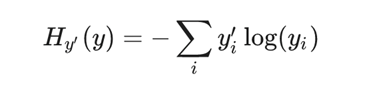
![]() 为神经网络结果,𝑦𝑖 为真实结果。每个类别都有一个损失结果。最后需要求平均损失
为神经网络结果,𝑦𝑖 为真实结果。每个类别都有一个损失结果。最后需要求平均损失


正向传播:输入经过一层层的计算得出输出
反向传播:从损失计算开始,从后往前梯度下降更新权重
5、API介绍
全连接--从输入直接到输出
特征加权
tf.matmul(a, b,name=None)+bias
- return:全连接结果,供交叉损失运算
- 不需要激活函数(因为是最后的输出)
softmax计算与交叉熵计算
tf.nn.softmax_cross_entropy_with_logits(labels=None, logits=None,name=None)
计算logits和labels之间的交叉损失熵
- labels:标签值(真实值)
- logits:样本加权之后的值
- return:返回损失值列表
损失值列表平均值计算
tf.reduce_mean(input_tensor)
- 计算张量的尺寸的元素平均值
梯度下降优化
tf.train.GradientDescentOptimizer(learning_rate)
- 梯度下降优化
- learning_rate:学习率,一般为
- minimize(loss):最小化损失
- return:梯度下降op
准确性计算
equal_list = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
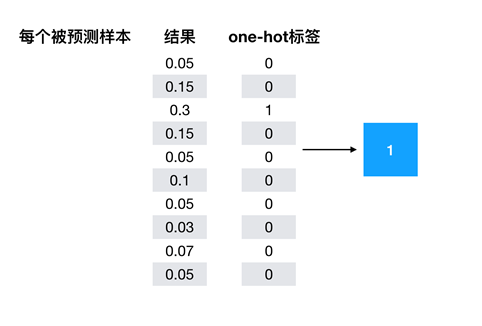

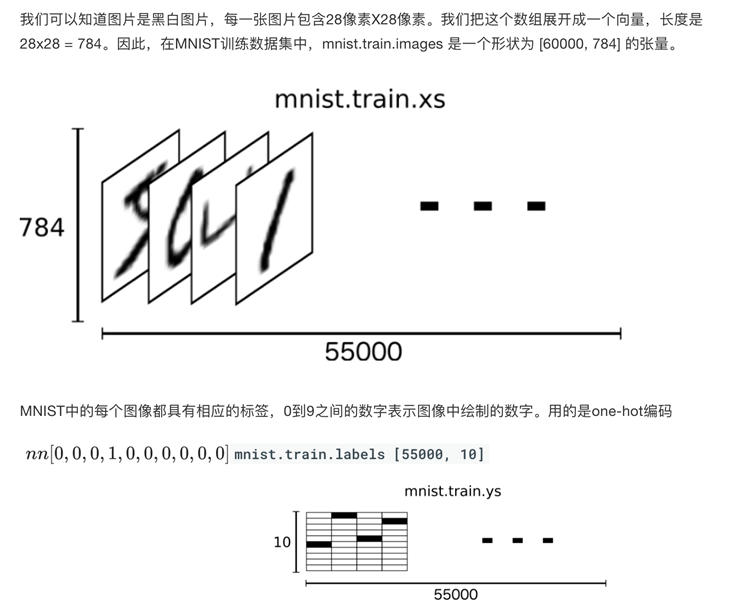
6、手写数字识别mnist数据集

http://yann.lecun.com/exdb/mnist/
one-hotAPI介绍

获取数据:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True) 通过这两步自动下载
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("./data/mnist/input_data/", one_hot=True) # print(mnist.train.images) # print(mnist.train.next_batch(50))
7、单层(全连接层)实现手写数字识别
① 准备数据
定义数据占位符
特征值[None, 784] 目标值[None, 10]
② 建立模型
随机初始化权重和偏置
w[784, 10] b[10]
y_predict = tf.matmul(x, w) + b
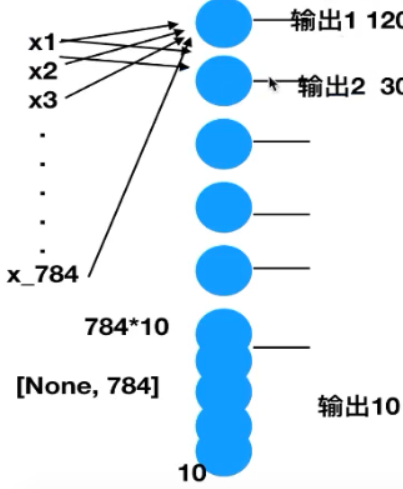
全连接结果计算
③ 计算损失
loss 平均样本损失
④ 梯度下降优化
⑤ 模型评估
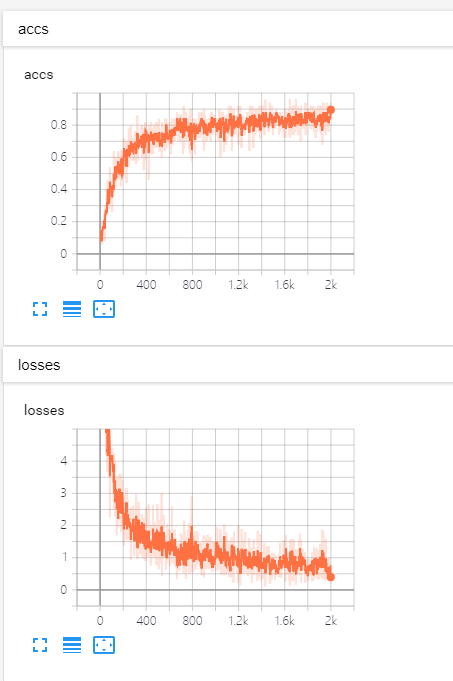
计算准确性
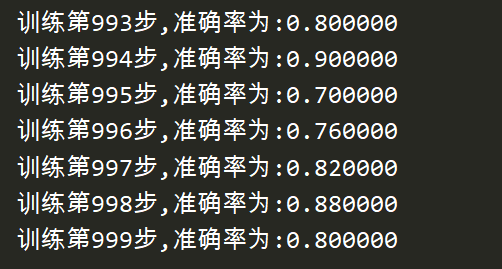
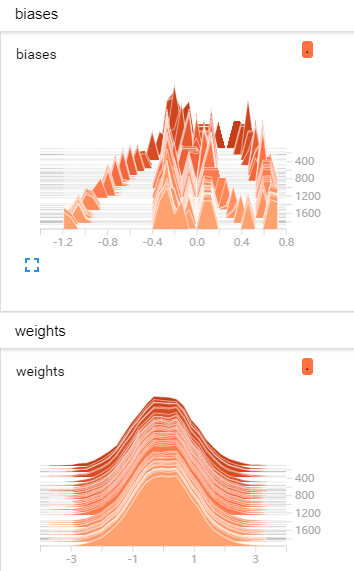
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data def full_connect(): # 1 建立数字占位符 with tf.variable_scope("data"): x = tf.placeholder(tf.float32, [None, 784]) y_true = tf.placeholder(tf.int32, [None, 10]) # 2 建立全连接层的神经网络 with tf.variable_scope("fc_model"): # 随机初始化权重和偏置 weight = tf.Variable(tf.random_normal([784, 10], mean=0.0, stddev=1.0), name="w") bias = tf.Variable(tf.constant(0.0, shape=[10])) # 预测None个样本的输出结果matrix [None,784]*[784, 10] + [10] = [None, 10] y_predict = tf.matmul(x, weight) + bias # 3 求出所有样本的损失,然后求平均值 with tf.variable_scope("soft_cross"): # softmax并计算交叉熵损失 # 损失取平均值reduce_mean对列表所有数相加求平均值 loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict)) # 4 梯度下降求出损失 with tf.variable_scope("optimizer"): train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss) # 5 计算准确率 with tf.variable_scope("acc"): # argmax十个中最大值的序号 equal相等为1 不等为0 equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1)) # 样本中只有1和0,所以可以拿所有1相加除以总样本数得出准确率 accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32)) # 获取真实数据 mnist = input_data.read_data_sets("./data/mnist/input_data/", one_hot=True) # 收集变量,单个数字值收集 tf.summary.scalar("losses", loss) tf.summary.scalar("accs", accuracy) # 高维度变量收集 tf.summary.histogram("weights", weight) tf.summary.histogram("biases", bias) # 定义一个合并变量的op merged = tf.summary.merge_all() # 定义一个初始化变量的op init_op = tf.global_variables_initializer() with tf.Session() as sess: # 初始化变量 sess.run(init_op) # 建立events文件,然后写入 fileWriter = tf.summary.FileWriter("./tmp/summary/test/", graph=sess.graph) # 迭代步数去训练 for i in range(2000): # 取出真实的特征值和目标值 mnist_x, mnist_y = mnist.train.next_batch(50) # 运行训练 sess.run(train_op, feed_dict={x: mnist_x, y_true: mnist_y}) # 写入每一步训练的值 summary = sess.run(merged, feed_dict={x: mnist_x, y_true: mnist_y}) fileWriter.add_summary(summary, i) # 打印准确率 print("训练第%d步,准确率为:%f" % (i, sess.run(accuracy, feed_dict={x: mnist_x, y_true: mnist_y}))) return None if __name__ == '__main__': full_connect()
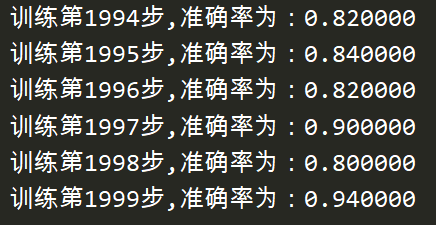
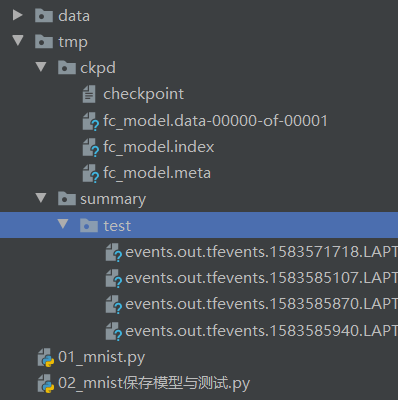
8、保存模型并在测试集上进行测试
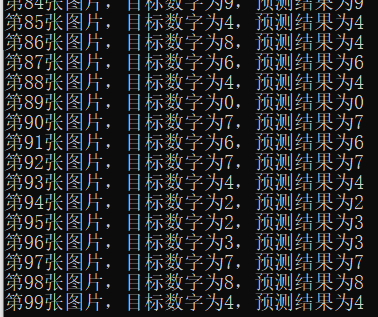
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_integer("is_train", 1, "指定程序是训练还是预测") def full_connect(): # 获取真实数据 mnist = input_data.read_data_sets("./data/mnist/input_data/", one_hot=True) # 1 建立数字占位符 with tf.variable_scope("data"): x = tf.placeholder(tf.float32, [None, 784]) y_true = tf.placeholder(tf.int32, [None, 10]) # 2 建立全连接层的神经网络 with tf.variable_scope("fc_model"): # 随机初始化权重和偏置 weight = tf.Variable(tf.random_normal([784, 10], mean=0.0, stddev=1.0), name="w") bias = tf.Variable(tf.constant(0.0, shape=[10])) # 预测None个样本的输出结果matrix [None,784]*[784, 10] + [10] = [None, 10] y_predict = tf.matmul(x, weight) + bias # 3 求出所有样本的损失,然后求平均值 with tf.variable_scope("soft_cross"): # softmax并计算交叉熵损失 # 损失取平均值reduce_mean对列表所有数相加求平均值 loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict)) # 4 梯度下降求出损失 with tf.variable_scope("optimizer"): train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss) # 5 计算准确率 with tf.variable_scope("acc"): # argmax十个中最大值的序号 equal相等为1 不等为0 equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1)) # 样本中只有1和0,所以可以拿所有1相加除以总样本数得出准确率 accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32)) # 收集变量,单个数字值收集 tf.summary.scalar("losses", loss) tf.summary.scalar("accs", accuracy) # 高维度变量收集 tf.summary.histogram("weights", weight) tf.summary.histogram("biases", bias) # 定义一个合并变量的op merged = tf.summary.merge_all() # 定义一个初始化变量的op init_op = tf.global_variables_initializer() # 创建一个saver saver = tf.train.Saver() with tf.Session() as sess: # 初始化变量 sess.run(init_op) # 建立events文件,然后写入 fileWriter = tf.summary.FileWriter("./tmp/summary/test/", graph=sess.graph) if FLAGS.is_train == 1: # 迭代步数去训练 for i in range(2000): # 取出真实的特征值和目标值 mnist_x, mnist_y = mnist.train.next_batch(50) # 运行训练 sess.run(train_op, feed_dict={x: mnist_x, y_true: mnist_y}) # 写入每一步训练的值 summary = sess.run(merged, feed_dict={x: mnist_x, y_true: mnist_y}) fileWriter.add_summary(summary, i) # 打印准确率 print("训练第%d步,准确率为:%f" % (i, sess.run(accuracy, feed_dict={x: mnist_x, y_true: mnist_y}))) # 保存模型 saver.save(sess, "./tmp/ckpd/fc_model") else: # 加载模型 saver.restore(sess, "./tmp/ckpd/fc_model") # 如果is_train为0,进行预测 for i in range(100): # 每次测试1张图片 x_test, y_test = mnist.test.next_batch(1) print("第%d张图片,目标数字为%d,预测结果为%d" % ( i, tf.argmax(y_test, 1).eval(), tf.argmax(sess.run(y_predict, feed_dict={x: x_test, y_true: y_test}), 1).eval() )) return None if __name__ == '__main__': full_connect()

二、深层的神经网络
http://playground.tensorflow.org
1、深层的神经网络
深度学习网络与更常见的单一隐藏层神经网络的区别在于深度,深度学习网络中,每一个节点层在前一层输出的基础上学习识别一组特定的特征。
随着神经网络深度增加,节点所能识别的特征也就越来越复杂。
全连接神经网络的缺点:
- 参数太多,在cifar-10的数据集中,只有32*32*3,就会有这么多权重,如果说更大的图片,比如200*200*3就需要120000多个,这完全是浪费
- 没有利用像素之间位置信息,对于图像识别任务来说,每个像素与周围的像素都是联系比较紧密的。
- 层数限制
2、卷积神经网络
卷积神经网络发展历史

LeNet:1986
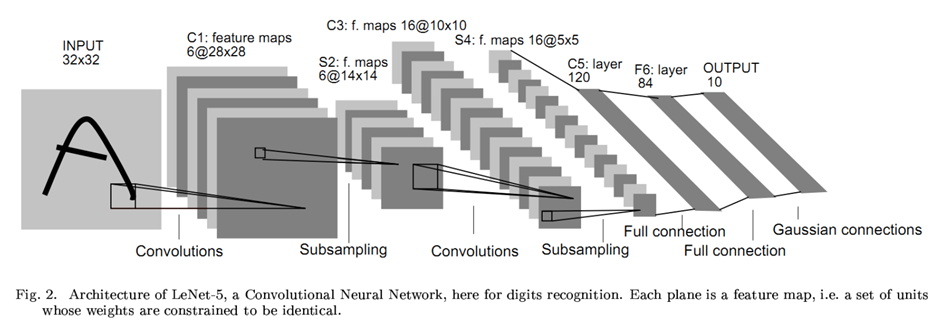
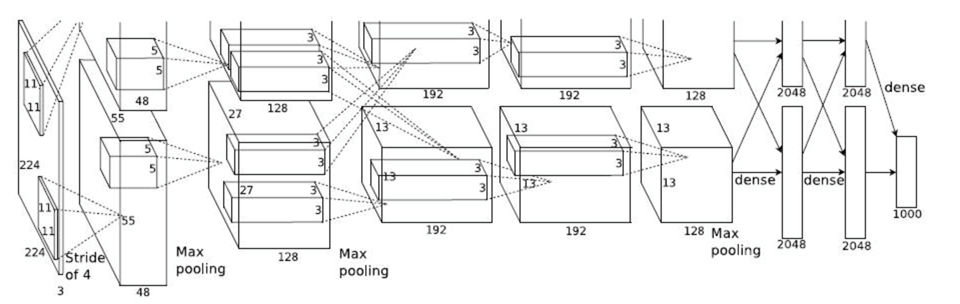
AlexNet:2012 60M以上的参数总量
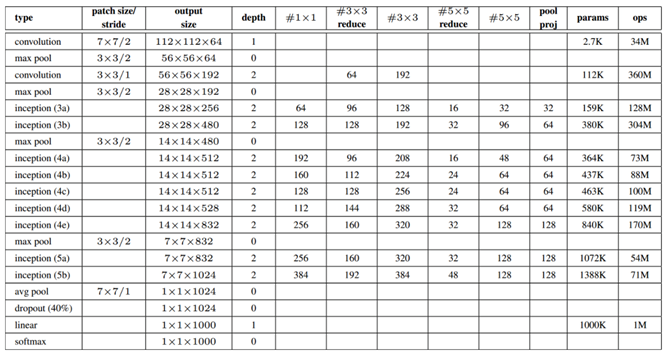
GoogleNet:
神经网络(neural networks)的基本组成包括输入层、隐藏层、输出层。
而卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,又叫下采样层)。
卷积层:通过在原始图像上平移来提取特征,每一个特征就是一个特征映射
池化层:通过特征后稀疏参数来减少学习的参数,降低网络的复杂度,(最大池化和平均池化)
3、卷积层
定义过滤器(观察窗口):权重矩阵
- 个数
- 大小(一般是奇数1*1,3*3,5*5)
- 步长:每次移动的像素数量
- 零填充
1通道 1过滤器 1步长:进行线性运算(对应位置相乘再相加)
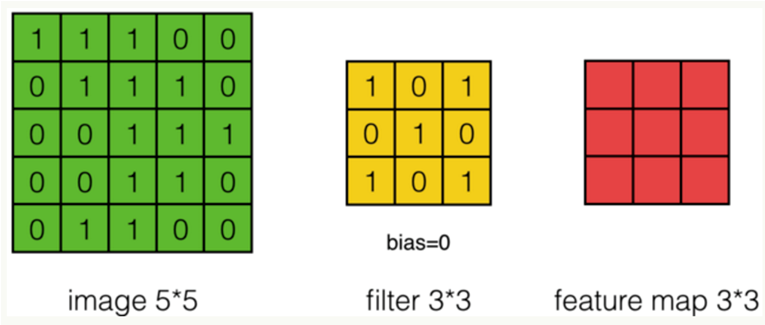
步长为2时:
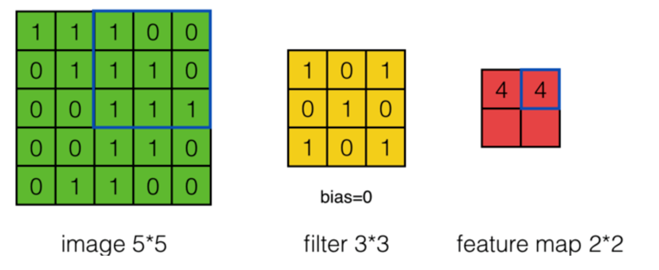
过滤器移动越过图片大小边界解决方法:
a. 不越过,直接停止观察
b. 零填充
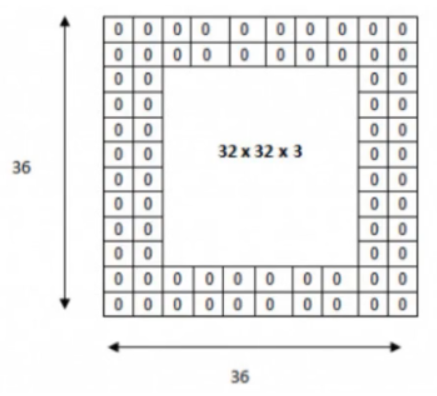
卷积核在提取特征映射时的动作称之为padding(零填充),由于移动步长不一定能整出整张图的像素宽度。其中有两种方式,SAME和VALID
SAME:越过边缘取样,取样的面积和输入图像的像素宽度一致
VALID:不越过边缘取样,取样的面积小于输入人的图像的像素宽度
多通道图片(彩色图片):多个过滤器(27个权重)
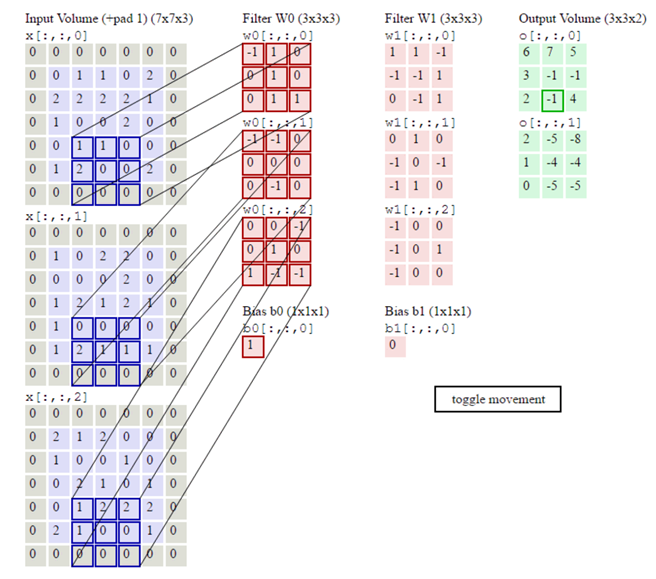
三组权重分别相乘相加,然后三组之和再加权重,就是最终的结果
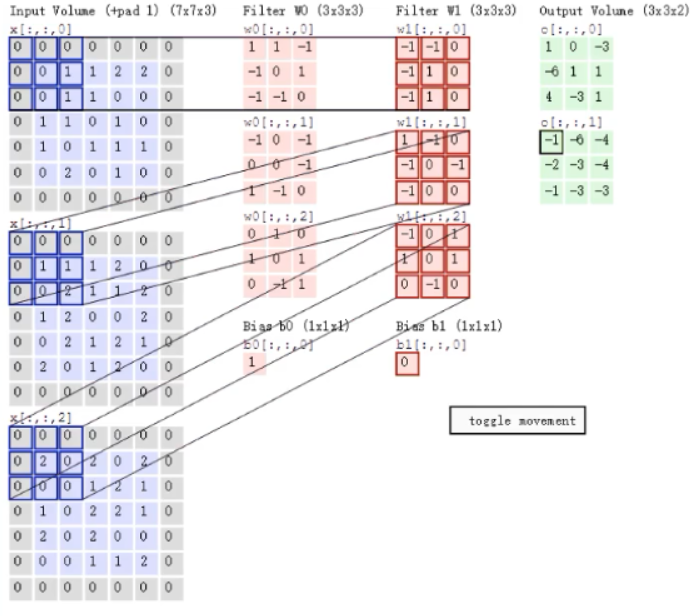
两组权重得出了两个结果

如:
输入体积 28, 28, 1
卷积层:100个filter, 5*5 步长2 零填充padding=1
输出的体积:
H2 = (28 - 5 + 2*2)/ 1 + 1 = 28
W2 = (28 - 5 + 2*2)/ 1 + 1 = 28
D2 = 100
输出结果:28, 28, 100
在tensorflow中只要指定SAME方式零填充,输入的大小和输出的大小相等
4、激活层与池化层
激活函数的作用是增加了网络的非线性分割能力
激活函数Relu:f(u) = max(0, x)
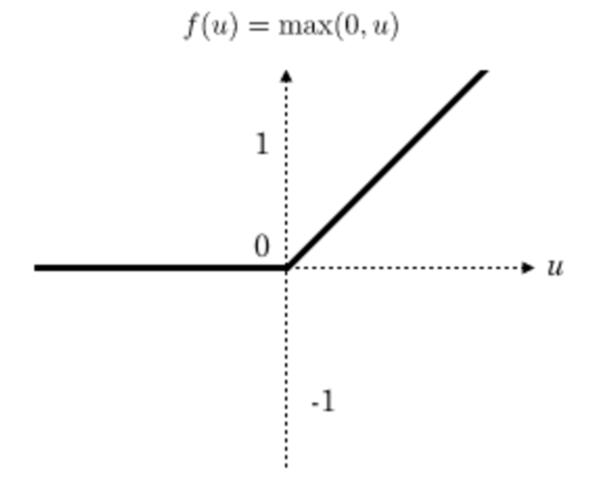
比之前使用的sigmoid,tanh要好
采用sigmoid等函数,反向传播求误差梯度时,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多
对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度爆炸的情况(求不出权重和偏置)
池化层计算
Pooling层主要的作用是特征提取,通过去掉Feature Map中不重要的样本,进一步减少参数数量。Pooling的方法很多,最常用的是Max Pooling。
池化层也有filter和stride
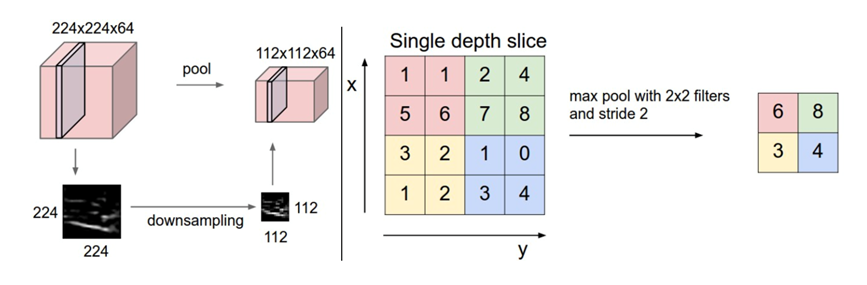
全连接层
前面的卷积和池化相当于做特征工程,后面的全连接相当于做特征加权。
最后的全连接层在整个卷积神经网络中起到“分类器”的作用。

h1 = (200-5+1*2)/2 + 1 = 99.5 = 99
w1 = (200-5+2)/2 + 1 = 99.5 = 99
h2 = (99-3+0)/1 +1 = 97
w2 = 97
h3 = (97-3+1*2)/1 + 1 = 97
w3 = 97
5、卷积神经网络API
卷积层
tf.nn.conv2d(input, filter, strides=, padding=, name=None)
- 计算给定4-D input和filter张量的2维卷积
- input:给定的输入张量,具有[batch,heigth,width,channel],类型为float32,64
- filter:指定过滤器的大小,[filter_height, filter_width, in_channels, out_channels],输出通道即过滤器个数
- strides:strides = [1, stride, stride, 1], 步长
- padding:“SAME”, “VALID”,使用的填充算法的类型,一般使用“SAME”
- 其中”VALID”表示滑动超出部分舍弃,“SAME”表示填充,使得变化后height,width一样大
- api没有提供设置0填充padding是多少,而是根据上面公式自动求的
激活函数
tf.nn.relu(features, name=None)
- features:卷积后加上偏置的结果
- return:结果
池化层
tf.nn.max_pool(value, ksize=, strides=, padding=,name=None)
- 输入上执行最大池数
- value:4-D Tensor形状[batch, height, width, channels]
- ksize:池化窗口大小,[1, ksize, ksize, 1]
- strides:步长大小,[1,strides,strides,1]
- padding:“SAME”, “VALID”,使用的填充算法的类型,使用“SAME”
6、卷积神经网络识别手写数字
图片形状:[None, 28, 28, 1]
卷积层1:
- 卷积(32个filter<有32个bias>,5*5,stride=1,padding=“SAME”):输入[None, 28, 28, 1],输出[None, 28, 28, 32]
- 激活:不改变大小[None, 28, 28, 32]
- 池化:2*2,stride=2,padding=“SAME”:输出[None, 14, 14, 32]
卷积层2:
- 卷积(64个filter<有64个bias>,5*5,stride=1,padding=“SAME”):输出[None, 14, 14, 64]
- 激活:[None, 14, 14, 64]
- 池化:2*2,stride=2,padding=“SAME”:输出[None, 7, 7, 64]
全连接层FC:
- [None, 7, 7, 64]-->形状改变[None, 7*7*64] * [7*7*64, 10] = [None, 10]
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data def conv_fc(): # 获取真实数据 mnist = input_data.read_data_sets("./data/mnist/input_data/", one_hot=True) # 定义模型 x, y_true, y_predict = model() # 进行交叉熵损失计算:求出所有样本的交叉熵损失然后求平均值 with tf.variable_scope("loss"): loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict)) # 梯度下降优化 with tf.variable_scope("optimizer"): train_op = tf.train.GradientDescentOptimizer(0.0001).minimize(loss) # 计算准确率 with tf.variable_scope("acc"): # 比较最大值的列索引是否相等 equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1)) # 样本中只有1和0,所以可以拿所有1相加除以总样本数得出准确率 accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32)) # 定义初始化变量的op init_op = tf.global_variables_initializer() # 开启会话运行 with tf.Session() as sess: sess.run(init_op) # 循环去训练 for i in range(1000): # 取出真实存在的特征值和目标值 mnist_x, mnist_y = mnist.train.next_batch(50) # 运行训练 sess.run(train_op, feed_dict={x: mnist_x, y_true: mnist_y}) print("训练第%d步,准确率为:%f" % (i, sess.run(accuracy, feed_dict={x: mnist_x, y_true: mnist_y}))) return None def model(): """ 自定义的卷积模型 :return: """ # 1 准备占位符 x = [None, 724] y_true=[None, 10] with tf.variable_scope("data"): x = tf.placeholder(tf.float32, [None, 784]) y_true = tf.placeholder(tf.int32, [None, 10]) # 2 卷积层1 with tf.variable_scope("conv1"): # 初始化权重和偏置,[5*5*1],32个,strides=1,32个偏置 w_conv1 = weight_variables([5, 5, 1, 32]) b_conv1 = bias_variables([32]) # 对x进行形状的改变 [None, 784]-->[None, 28, 28, 1] x_reshape = tf.reshape(x, [-1, 28, 28, 1]) # 改变形状时不知道形状填-1,不能填None # 卷积:[None, 28, 28, 1]-->[None, 28, 28, 32],relu激活 x_relu1 = tf.nn.relu(tf.nn.conv2d(x_reshape, w_conv1, strides=[1,1,1,1], padding="SAME") + b_conv1) # 池化:2*2,strides=2 [None,28,28,32]-->[None,14,14,32] x_pool1 = tf.nn.max_pool(x_relu1, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME") # 3 卷积层2 with tf.variable_scope("conv2"): # [5*5*32](32个通道),64个filter,strides=1,64个偏置 w_conv2 = weight_variables([5, 5, 32, 64]) b_conv2 = bias_variables([64]) # 卷积,激活:[None,14,14,32]-->[None,14,14,64] x_relu2 = tf.nn.relu(tf.nn.conv2d(x_pool1, w_conv2, strides=[1,1,1,1], padding="SAME") + b_conv2) # 池化 2*2 strides=2 --> [None,7,7,64] x_pool2 = tf.nn.max_pool(x_relu2, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME") # 4 全连接层:[None,7,7,64]-->[None,7*7*64] * [7*7*64,10] = [None, 10] with tf.variable_scope("fc"): # 随机初始化权重和偏置 w_fc = weight_variables([7*7*64, 10]) b_fc = bias_variables([10]) # 修改形状 x_fc_reshape = tf.reshape(x_pool2, [-1, 7*7*64]) # 矩阵运算得出每个样本的10个结果 y_predict = tf.matmul(x_fc_reshape, w_fc) + b_fc return x, y_true, y_predict # 定义初始化权重的函数 def weight_variables(shape): w = tf.Variable(tf.random_normal(shape=shape, mean=0.0, stddev=1.0)) return w # 定义初始化偏置的函数 def bias_variables(shape): b = tf.Variable(tf.constant(0.0, shape=shape)) return b if __name__ == '__main__': conv_fc()