


一、决策树与随机森林
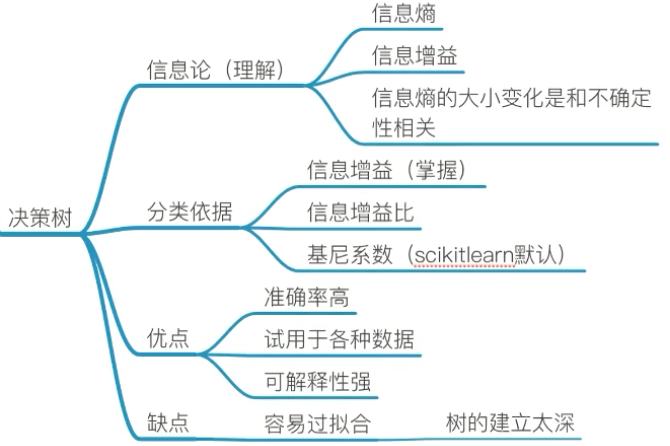
1、信息论基础
香农:奠定了现代信息论基础,定义信息的单位比特。
32支球队,预测世界杯冠军,不知道任何信息的情况下,使用二分法最少需要猜5次。(log32=5)
5 = - (1/32log1/32 + 1/32log1/32 + ...+ 1/32log1/32)
而在开放一些信息后(如前10次比赛的情况或者已知一些球队的获胜概率),“谁是世界杯冠军”的信息量应该比5比特少。
香农指出,它的准确信息量应该是:
![]()
如 5 > - (1/4log1/4 + 1/8log1/8 + ...+ 1/6log1/6) 信息熵减少了
信息熵 H:单位为比特
![]()
当32支球队夺冠几率相同时,对应的信息熵为5比特。
信息和消除不确定性是相联系的,不确定性下降,信息熵也下降。
所以在决策树中,减少的信息熵越多的特征,越先判断。
决策树的划分依据之一:信息增益,表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差:
![]()
如上例中开放一些信息后,减少的信息熵的大小。
信息增益的计算:

如下例:


下面这个式子更好理解:

信息增益最大的,选为最有效特征。
信息增益是决策树的分类依据之一。
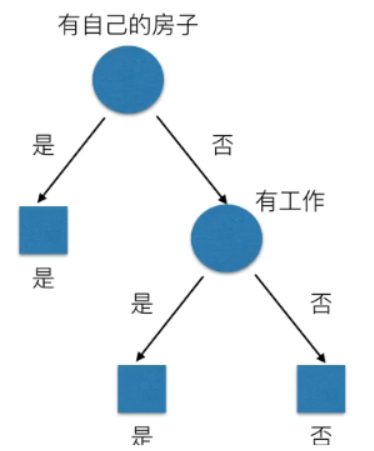
2、决策树
常见决策树使用的算法:
ID3:信息增益最大的准则。
C4.5:信息增益比最大的准则。
CART:
- 回归树:平方误差最小。
- 分类树:基尼系数最小。(基尼系数的划分更仔细,一般用这个)
class sklearn.tree.DecisionTreeClassifier(criterion="gini", max_depth=None, random_state=None)
- 决策树分类器
- criterion默认是基尼系数,也可以选择信息增益的熵 “entropy”
- max_depth:树的深度大小
- random_state:随机树种子
- decision_path() :返回决策树的路径
案例:

步骤:
- pd读取数据
- 选择有影响的特征,处理缺失值
- 进行特征工程,pd转换字典,特征抽取
- x_train.to_dict(orient="records")
- 决策树估计器流程
数据地址:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt
import pandas as pd from sklearn.feature_extraction import DictVectorizer from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier def decision(): """ 决策树 :return: None """ # 获取数据 titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt") # 处理数据,找出特征值和目标值 x = titan[['pclass', 'age', 'sex']] y = titan['survived'] # 缺失值处理 x['age'].fillna(x['age'].mean(), inplace=True) print(x) # 分割数据 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) # 特征工程 dict = DictVectorizer(sparse=False) x_train = dict.fit_transform(x_train.to_dict(orient="records")) x_test = dict.fit_transform(x_test.to_dict(orient="records")) print(dict.get_feature_names()) print(x_train) # 用决策树进行分类 dec = DecisionTreeClassifier() dec.fit(x_train, y_train) print("预测的准确率:", dec.score(x_test, y_test)) return None if __name__ == '__main__': decision()
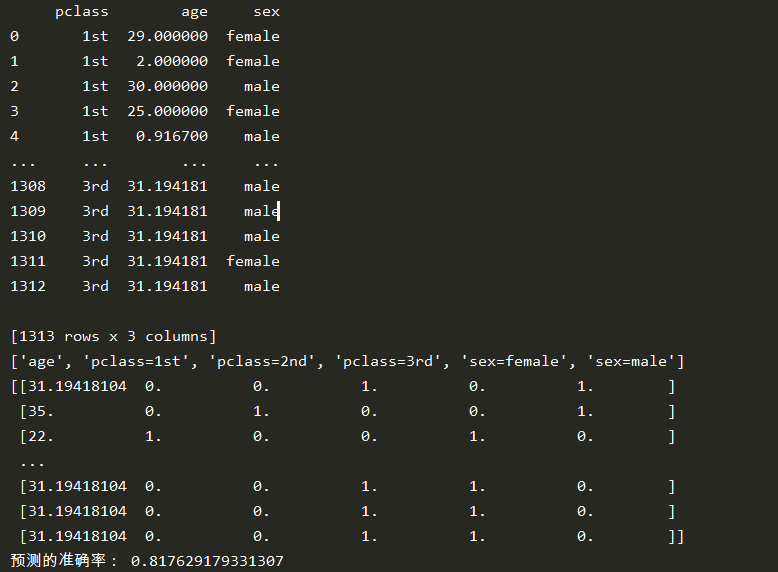
决策树的结构、本地保存:
① sklearn.tree.export_graphviz() 该函数能够导出DOT格式
tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
# 导出决策树的结构 export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', '一等座', '二等座', '三等座', '女性', '男性'])
② 工具:(能够将dot文件转换为pdf、png)
安装graphviz
ubuntu:sudo apt-get install graphviz Mac:brew install graphviz
③ 运行命令
然后我们运行这个命令
$ dot -Tpng tree.dot -o tree.png
决策树的优缺点
优点:
- 简单的理解和解释,树木可视化。
- 需要很少的数据准备,其他技术通常需要数据归一化
缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成
改进:
- 剪枝cart算法(决策树API中已经实现)
- 随机森林
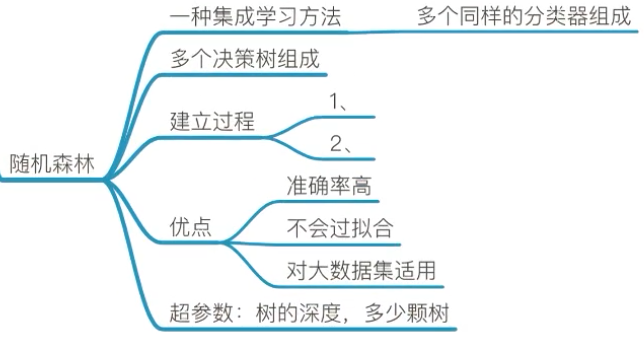
3、随机森林
集成学习方法:集成学习通过建立几个模型的组合来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
随机森林:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林建立多个决策树过程: N个样本 M个特征
单个树建立过程:
① 随机在N个样本中选择一个样本,重复N次,样本有可能重复;
② 随机在M个特征中选出m个特征,
建立10棵决策树,样本、特征大多不一样(随机有放回的抽样)
学习算法:
根据下列算法而建造每棵树:
用N来表示训练用例(样本)的个数,M表示特征数目。
输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
集成学习API:
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None)
- 随机森林分类器
- n_estimators:integer,optional(default = 10) 森林里的树木数量
- criteria:string,可选(default =“gini”)分割特征的测量方法
- max_depth:integer或None,可选(默认=无)树的最大深度
- bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
- max_features="auto" 每个决策树的最大特征数量,可以为auto,sqrt,log2,即取sqrt(总特征数)个特征,auto=sqrt
随机森林的超参数有:n_estimators决策树的数量、max_depth每棵树的深度限制
预测泰坦尼克号生存人数:
import pandas as pd from sklearn.feature_extraction import DictVectorizer from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV def decision(): """ 决策树 :return: None """ # 获取数据 titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt") # 处理数据,找出特征值和目标值 x = titan[['pclass', 'age', 'sex']] y = titan['survived'] # 缺失值处理 x['age'].fillna(x['age'].mean(), inplace=True) # 分割数据 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) # 特征工程 dict = DictVectorizer(sparse=False) x_train = dict.fit_transform(x_train.to_dict(orient="records")) x_test = dict.fit_transform(x_test.to_dict(orient="records")) # 随机森林进行预测,超参数调优 rf = RandomForestClassifier() # 网格搜索交叉验证 param = {"n_estimators":[120, 200, 300, 500, 800, 1200], "max_depth":[5, 8, 15, 25, 30]} # 以上这些值都是常用的,它们在网格搜索中两两组合 gc = GridSearchCV(rf, param_grid=param, cv=4) gc.fit(x_train, y_train) print("准确率:", gc.score(x_test, y_test)) print("查看选择的参数模型:", gc.best_params_) return None if __name__ == '__main__': decision()

随机森林的优点:
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上(样本大、特征大)
- 能够处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性
- 对于缺省值问题也能够获得很好得结果
二、线性回归
1、线性回归
试图学得一个通过属性的线性组合来进行预测的函数:
𝑓(𝑥)=𝑤1𝑥1+𝑤2𝑥2+…+𝑤𝑑𝑥𝑑+𝑏
w为权重,b称为偏置项,可以理解为:𝑤0×1
如的房子的面积与价格的关系:
import matplotlib.pyplot as plt plt.figure(figsize=(10, 10)) plt.scatter([60, 72, 75, 80, 83], [126, 151.2, 157.5, 168, 174.3]) plt.show()
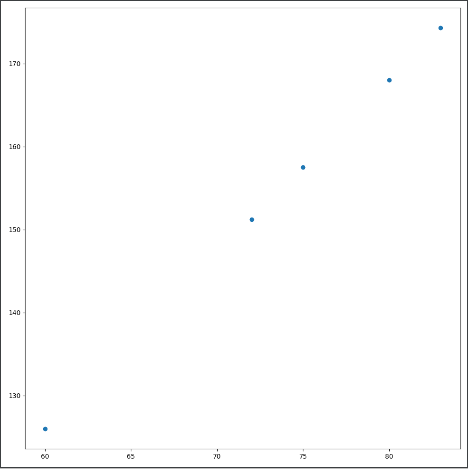
定义:线性回归通过一个或者多个自变量与因变量之间之间进行建模的回归分析。其中特点为一个或多个称为回归系数的模型参数的线性组合
多元线性回归:涉及到的变量两个或两个以上
![]()
其中w, x为矩阵: 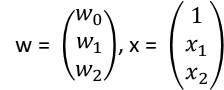
预测结果与真实值有一定的误差。
损失函数:误差大小
yi为第𝑖个训练样本的真实值,hw(xi)为第𝑖个训练样本特征值组合预测函数
总损失定义为: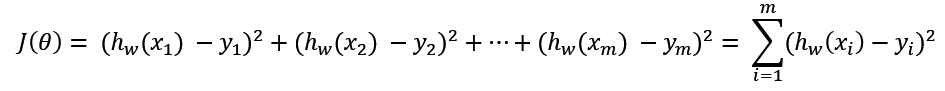
又称最小二乘法
如何求解模型中的w,使得损失最小?目的是找到最小损失对应的w值。
2、正规方程
求解: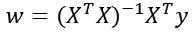
𝑋为特征值矩阵,𝑦为目标值矩阵
缺点:当特征过于复杂,求解速度太慢
对于复杂的算法,不能使用正规方程求解(逻辑回归等)
一般不用正规方程的方法来求解
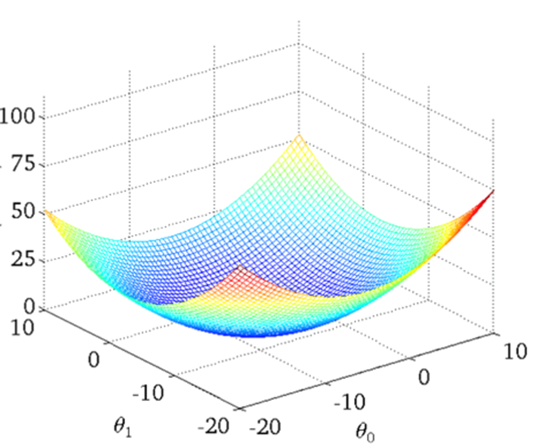 直接求解到最小值
直接求解到最小值
3、梯度下降
以单变量中的w1,w0为例:y=w1*x+w0
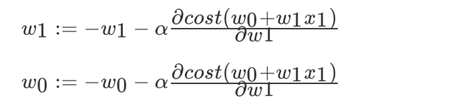
α为学习速率,需要手动指定,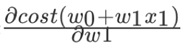 表示方向。
表示方向。
沿着这个函数下降的方向找,最后就能找到山谷的最低点,然后更新W值。
面对训练数据规模十分庞大的任务,使用梯度下降。
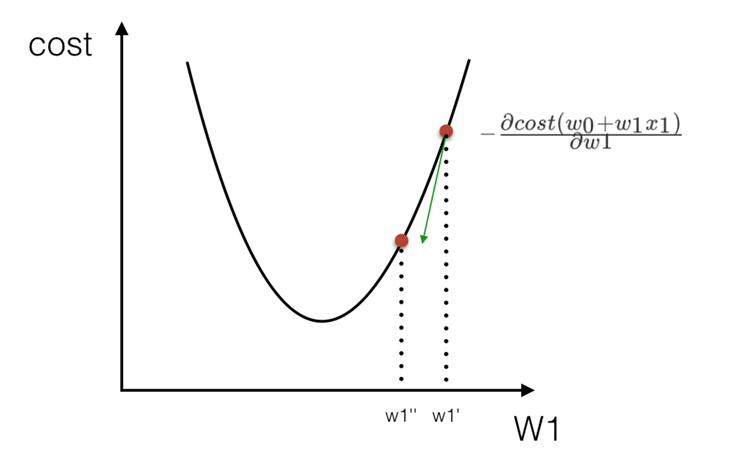
小结
线性回归:
策略:最小二乘法计算误差平方和
优化:正规方程、梯度下降
4、正规方程、梯度下降API
sklearn.linear_model.LinearRegression() 正规方程
- 普通最小二乘线性回归
- coef_:回归系数
sklearn.linear_model.SGDRegressor( ) 梯度下降
- 通过使用SGD最小化线性模型
- coef_:回归系数
线性回归需要标准化处理。
波士顿房价数据案例:
① 波士顿地区房价数据获取
② 波士顿地区房价数据分割
③ 训练与测试数据标准化处理
④ 使用最简单的线性回归模型LinearRegression和梯度下降估计SGDRegressor对房价进行预测
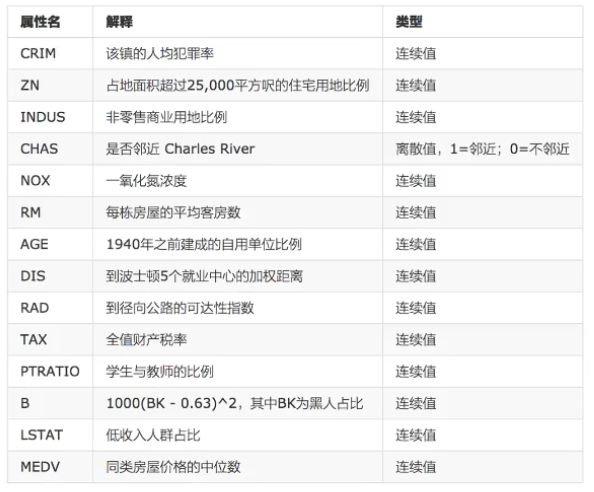
from sklearn.datasets import load_boston from sklearn.linear_model import LinearRegression, SGDRegressor from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler def linear(): """ 线性回归预测房价 :return: None """ # 获取数据 lb = load_boston() # 分割数据集 x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25) # 标准化:线性回归特征值和目标值都要处理 # 要实例化两个标准化API(因为目标值只有一列,n个特征值计算出来的n个平均值和方差无法用于目标值) std_x = StandardScaler() x_train = std_x.fit_transform(x_train) # x_train本来就是二维数组不用转 x_test = std_x.transform(x_test) std_y = StandardScaler() y_train = std_y.fit_transform(y_train.reshape(-1, 1)) # 0.19版本转换器要求传入参数必须转成二维数组 y_test = std_y.transform(y_test.reshape(-1, 1)) # estimator预测 # 正规方程求解 lr = LinearRegression() lr.fit(x_train, y_train) print(lr.coef_) # 权重参数 y_pred = lr.predict(x_test) print(std_y.inverse_transform(y_pred)) # 转换 print("准确率:", lr.score(x_test, y_test)) # 梯度下降预测 sgd = SGDRegressor() sgd.fit(x_train, y_train) print(sgd.coef_) y_pred = sgd.predict(x_test) print(std_y.inverse_transform(y_pred)) print("准确率:", sgd.score(x_test, y_test)) return None if __name__ == '__main__': linear()
5、回归性能评估
均方误差(Mean Squared Error,MSE):
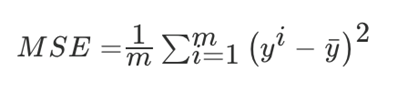
![]()
sklearn.metrics.mean_squared_error
mean_squared_error(y_true, y_pred)
- 均方误差回归损失
- y_true:真实值
- y_pred:预测值
- return:浮点数结果
- 真实值预测值都是标准化之前的值
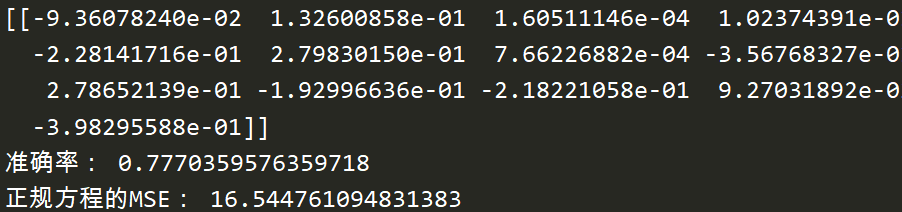
from sklearn.datasets import load_boston from sklearn.linear_model import LinearRegression, SGDRegressor from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import mean_squared_error def linear(): """ 线性回归预测房价 :return: None """ # 获取数据 lb = load_boston() # 分割数据集 x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25) # 标准化:线性回归特征值和目标值都要处理 # 要实例化两个标准化API(因为目标值只有一列,n个特征值计算出来的n个平均值和方差无法用于目标值) std_x = StandardScaler() x_train = std_x.fit_transform(x_train) # x_train本来就是二维数组不用转 x_test = std_x.transform(x_test) std_y = StandardScaler() y_train = std_y.fit_transform(y_train.reshape(-1, 1)) # 0.19版本转换器要求传入参数必须转成二维数组 y_test = std_y.transform(y_test.reshape(-1, 1)) # estimator预测 # 正规方程求解 lr = LinearRegression() lr.fit(x_train, y_train) print(lr.coef_) # 权重参数 y_pred = lr.predict(x_test) # print(std_y.inverse_transform(y_pred)) # 转换 print("准确率:", lr.score(x_test, y_test)) print("正规方程的MSE:", mean_squared_error(std_y.inverse_transform(y_test), std_y.inverse_transform(y_pred))) # 梯度下降预测 sgd = SGDRegressor() sgd.fit(x_train, y_train) print(sgd.coef_) y_pred = sgd.predict(x_test) # print(std_y.inverse_transform(y_pred)) print("准确率:", sgd.score(x_test, y_test)) print("梯度下降的MSE:", mean_squared_error(std_y.inverse_transform(y_test), std_y.inverse_transform(y_pred))) return None if __name__ == '__main__': linear()

方法对比:
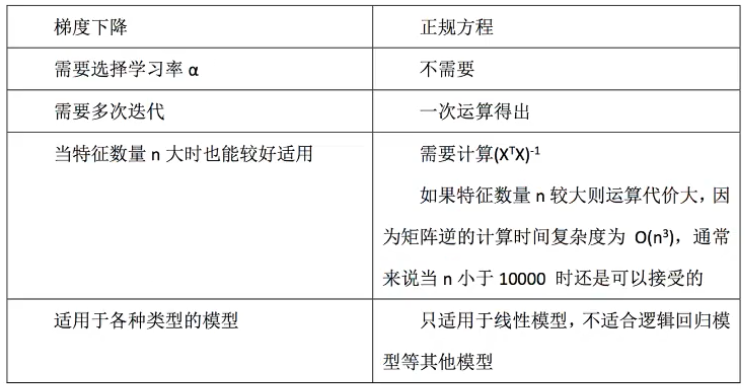
特点:线性回归器是最为简单、易用的回归模型。从某种程度上限制了使用,尽管如此,在不知道特征之间关系的前提下,我们仍然使用线性回归器作为大多数系统的首要选择。
小规模数据:LinearRegression(不能解决拟合问题)以及其它
大规模数据:SGDRegressor
6、过拟合、欠拟合
问题:训练数据训练的很好,误差也不大,为什么在测试集上面有问题呢?
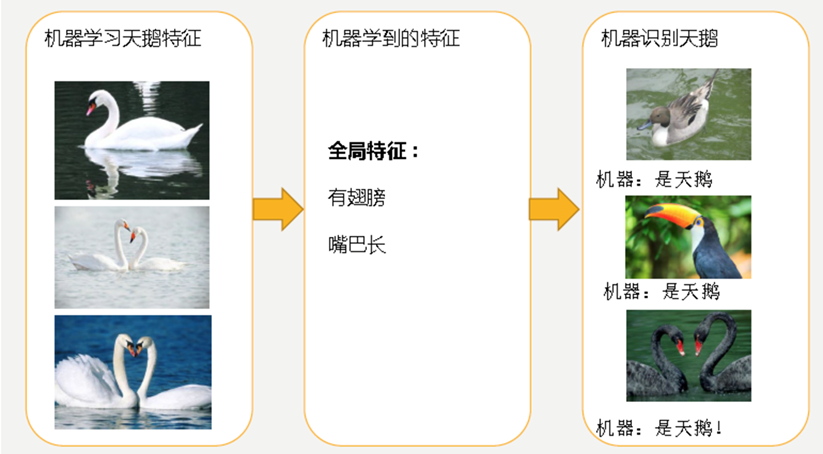
经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的。简单的认为有这些特征的都是天鹅。因为机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅。
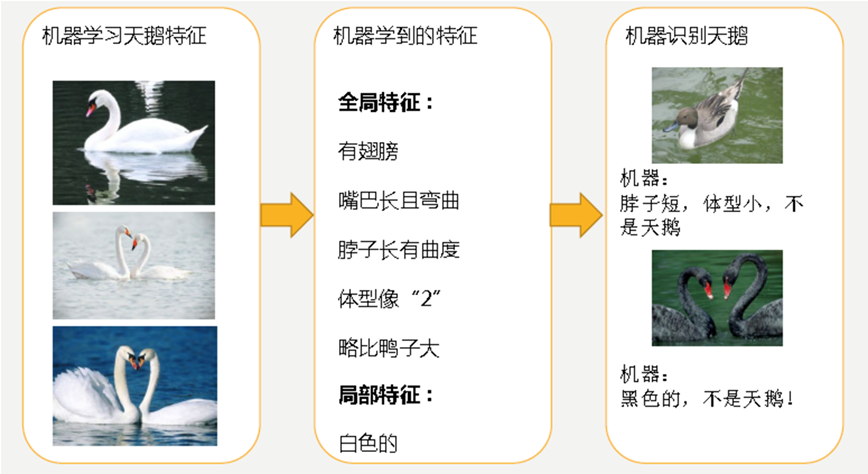
机器通过这些图片来学习天鹅的特征,经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的弯曲的,天鹅的脖子是长长的有点曲度,天鹅的整个体型像一个"2"且略大于鸭子。这时候机器已经基本能区别天鹅和其他动物了。但是机器在训练集学习的太好了,很不巧已有的天鹅图片全是白天鹅的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅。
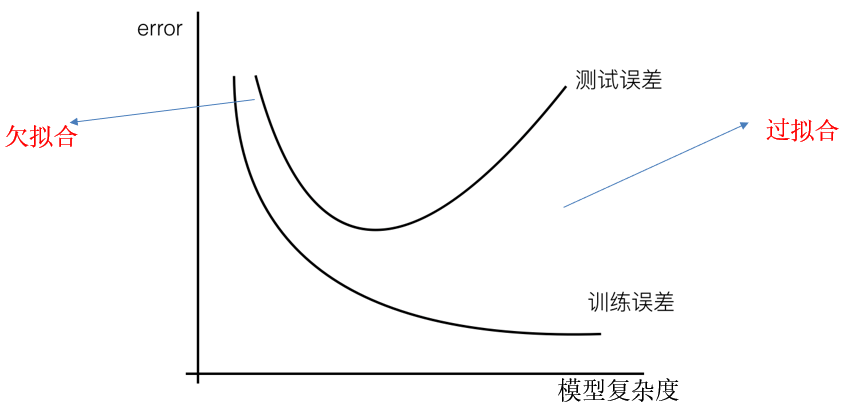
过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
欠拟合:一个假设在训练数据上不能获得更好的拟合, 但是在训练数据外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
对线性模型进行训练学习会变成复杂模型:
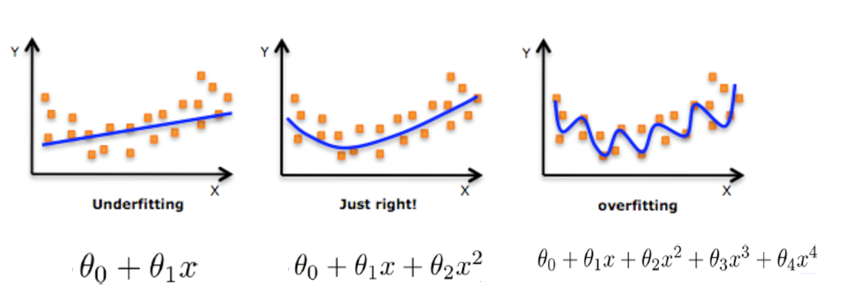
模型复杂的原因:数据的特征和目标值之间的关系不仅仅是线性关系。
欠拟合:
原因:学习到数据的特征过少
解决办法:增加数据的特征数量
过拟合:
原因:原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点
解决办法:
- 进行特征选择,消除关联性大的特征(很难做)
- 交叉验证(让所有数据都有过训练)(交叉验证训练集,根据结果现象可以看出过拟合或欠拟合)
- 正则化
L2正则化进行特征选择:解决过拟合

作用:可以使得W的每个元素都很小,都接近于0(不知道哪个特征是高次的复杂特征,就将前面的权重减小)
优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象
7、岭回归
线性回归为了把所有训练数据表现好,容易出现权重过大过拟合。
带有正则化的线性回归:岭回归
sklearn.linear_model.Ridge
sklearn.linear_model.Ridge(alpha=1.0)
- 具有l2正则化的线性最小二乘法
- alpha:正则化力度(超参数)(默认1.0,一般可以取0~1、1~10)
- coef_:回归系数
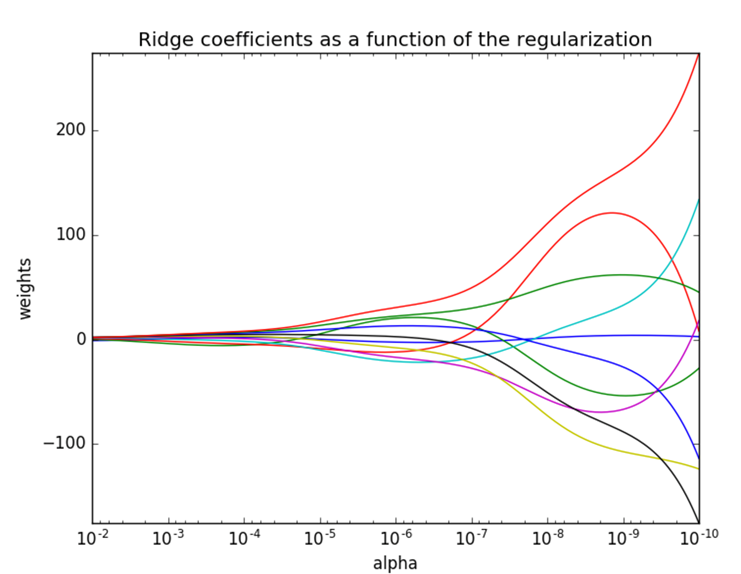
正则化力度越大,权重越接近于0,模型越简单(但也不能过于简单)
# 岭回归 rd = Ridge() rd.fit(x_train, y_train) print(rd.coef_) y_pred = rd.predict(x_test) print(std_y.inverse_transform(y_pred)) print("准确率:", rd.score(x_test, y_test)) print("岭回归的MSE:", mean_squared_error(std_y.inverse_transform(y_test), std_y.inverse_transform(y_pred)))
岭回归得到的回归系数更符合实际,更可靠。另外,能让估计参数的波动范围变小,变的更稳定。在存在病态数据偏多的研究中有较大的实用价值。
8、模型的保存与加载
sklearn模型的保存与加载:
from sklearn.externals import joblib
保存:joblib.dump(rf, 'test.pkl')
加载:estimator = joblib.load('test.pkl')
# 正规方程求解 lr = LinearRegression() lr.fit(x_train, y_train) print(lr.coef_) # 权重参数 # 保存训练好的模型 joblib.dump(lr, './tmp/lr.pkl')
