


三、数据提取方法
1、基本概念
数据提取就是从响应中获取我们想要的的数据的过程
数据分类:
非结构化数据:HTML等
处理方法:正则表达式、xpath
结构化数据:json、xml等
处理方法:转化为Python数据类型
2、正则表达式复习
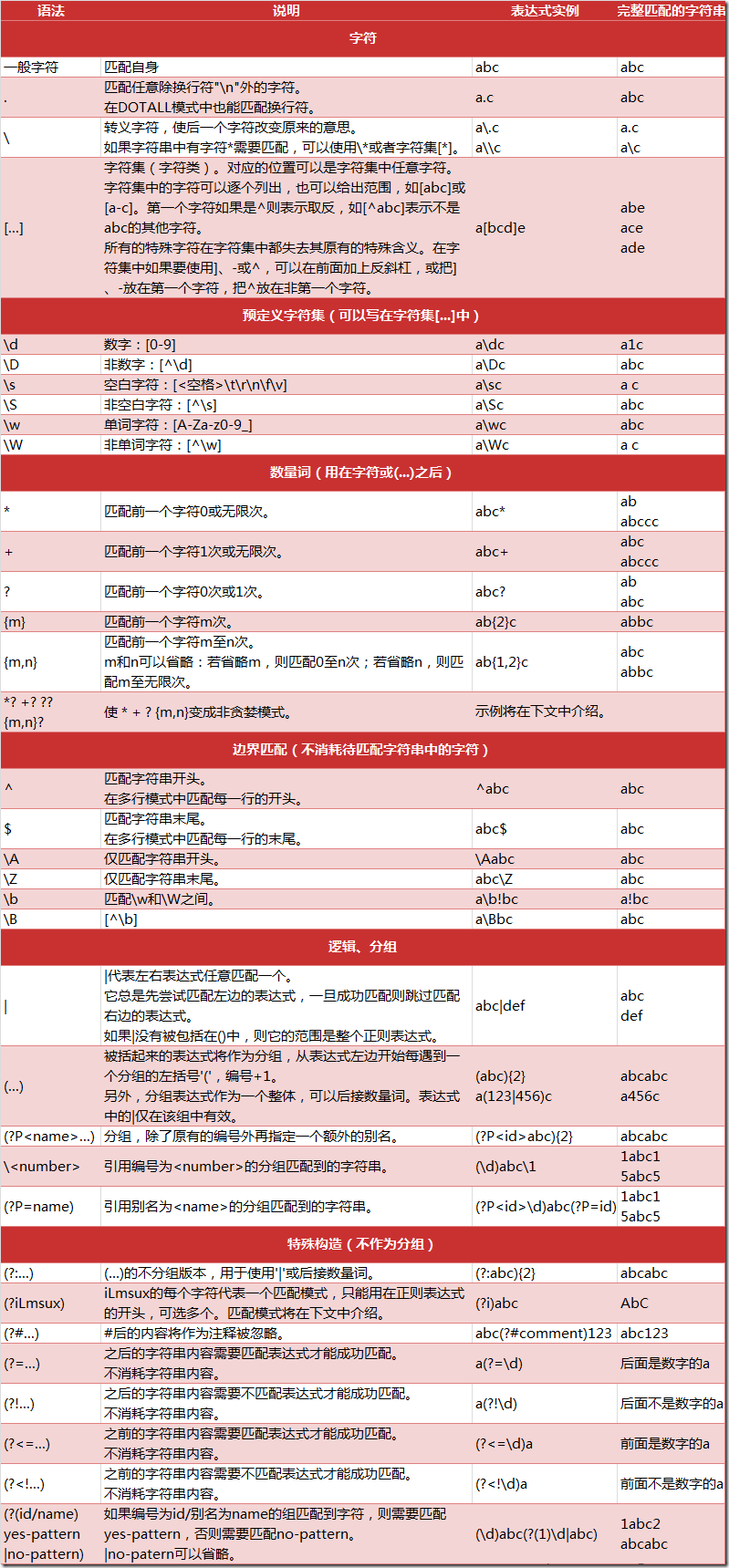
. 匹配 \n:
In [2]: re.findall(".","\n") Out[2]: [] In [3]: re.findall(".","\n",re.DOTALL) Out[3]: ['\n'] In [4]: re.findall(".","\n",re.S) Out[4]: ['\n']
转义符号:
In [5]: re.findall("\.",".") Out[5]: ['.']
[ ]只能匹配其中一个字符:
In [6]: re.findall("a[bcd]e","abe") Out[6]: ['abe'] In [7]: re.findall("a[bcd]e","abce") Out[7]: []
In [8]: re.findall("a[bcd]+e","abce") Out[8]: ['abce']
非贪婪:
没匹配空格
In [19]: re.findall('<.+?>',a) Out[19]: ['<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />', '<meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。">', '<meta name="keywords" content="豆瓣,广播,登陆豆瓣">']
贪婪
In [24]: re.findall('<.+>',a,re.S) Out[24]: ['<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />\n<meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。">\n<meta name="keywords" content="豆瓣,广播,登陆豆瓣">']
非贪婪
In [25]: re.findall('<.+?>',a,re.S) Out[25]: ['<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />', '<meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。">', '<meta name="keywords" content="豆瓣,广播,登陆豆瓣">']
替换:
In [27]: b = "special flavor1234" In [28]: re.sub("\d","_",b) Out[28]: 'special flavor____'
compile提高效率
效率低
In [29]: re.sub("\d+","",b) Out[29]: 'special flavor'
传入正则 In [30]: p = re.compile("\d") In [31]: p.findall(b) Out[31]: ['1', '2', '3', '4'] In [32]: p.sub("",b) Out[32]: 'special flavor'
参数要放到compile
In [33]: p = re.compile(".",re.S) In [34]: p.findall("\n") Out[34]: ['\n']
原始字符串r
In [38]: a = "a\nb" In [39]: len(a) Out[39]: 3 In [40]: a = r"a\nb" In [41]: len(a) Out[41]: 4
In [43]: r"a\nb" Out[43]: 'a\\nb'
正则前加r的好处是,忽略转义符号的影响,使得前后一致
In [44]: re.findall("a\nb","a\nb") Out[44]: ['a\nb'] In [45]: re.findall(r"a\nb","a\nb") Out[45]: ['a\nb'] In [46]: re.findall(r"a\nb","a\\nb") Out[46]: [] In [47]: re.findall(r"a\\nb","a\\nb") Out[47]: ['a\\nb']
比如操作Windows文件对文件名中的 \ 可以加 r 处理
()起到过滤的效果,ab起到定位的效果
In [50]: re.findall("a(.*?)b","iuwrajkjsb") Out[50]: ['jkjs']
3、正则表达式爬虫案例
爬取36kr网站数据
import requests import re import json class ReSpider: def __init__(self): self.start_url = "https://36kr.com/" self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"} def parse_url(self, url): response = requests.get(url, headers=self.headers) return response.content.decode() def get_content_list(self, html_str): re_str = r"<a class=\"article-item-title weight-bold.*?rel=\"noopener noreferrer\">(.*?)</a>" content_list = re.findall(re_str, html_str, re.S) return content_list def save_content_list(self, content_list): with open("duanzi_list.txt", "a", encoding='utf-8') as f: for content in content_list: f.write(json.dumps(content, ensure_ascii=False)) f.write('\n') print("保存成功") def run(self): # 实现主要逻辑 # 发送请求 获取响应 html_str = self.parse_url(self.start_url) # 提取数据 content_list = self.get_content_list(html_str) # 保存 self.save_content_list(content_list) if __name__ == '__main__': rs = ReSpider() rs.run()
内涵段子
# coding=utf-8 import requests import re import json class Neihan: def __init__(self): self.start_url = "http://neihanshequ.com/" self.next_url_temp = "http://neihanshequ.com/joke/?is_json=1&app_name=neihanshequ_web&max_time={}" self.headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} def parse_url(self,url):#发送请求 print(url) response = requests.get(url,headers=self.headers) return response.content.decode() def get_first_page_content_list(self,html_str): #提取第一页的数据 content_list = re.findall(r"<h1 class=\"title\">.*?<p>(.*?)</p>",html_str,re.S) max_time = re.findall("max_time: '(.*?)',",html_str)[0] return content_list,max_time def save_content_list(self,content_list): #保存 with open("neihan.txt","a",encoding="utf-8") as f: for content in content_list: f.write(json.dumps(content,ensure_ascii=False)) f.write("\n") print("保存成功") def get_content_list(self,json_str): #提取从第二页开始的json中的数据 dict_ret = json.loads(json_str) data = dict_ret["data"]["data"] content_list = [i["group"]["content"] for i in data] max_time = dict_ret["data"]["max_time"] has_more = dict_ret["data"]["has_more"] return content_list,max_time,has_more def run(self):#实现主要逻辑 #1.start_url #2.发送请求,获取响应 html_str = self.parse_url(self.start_url) #3.提取数据 content_lsit,max_time = self.get_first_page_content_list(html_str) #4.保存 self.save_content_list(content_lsit) has_more = True #有第二页 while has_more: #5.构造下一页的url地址 next_url = self.next_url_temp.format(max_time) #6.发送请求,获取响应 json_str = self.parse_url(next_url) #7.提取数据,提取max_time content_lsit,max_time,has_more = self.get_content_list(json_str) #8.保存 self.save_content_list(content_lsit) #9.循环5-8步 if __name__ == '__main__': neihan = Neihan() neihan.run()
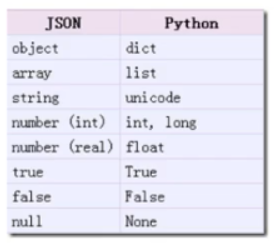
4、json
json是一种轻量级的数据交换格式,适用于如前端后端数据交互等场景
(一般可以在网页的手机版中找到json,网页中的数据不一定都来自json,有可能来自js生成)
import json import requests from pprint import pprint url = "https://36kr.com/pp/api/aggregation-entity?type=web_latest_article&b_id=71663&per_page=10" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"} response = requests.get(url, headers=headers) json_str = response.content.decode() # 把json类型转化为python类型(字典) ret1 = json.loads(json_str) print(type(ret1)) pprint(ret1) # pretty print 使输出看起来更好看 # 把python类型转化为json字符串 with open("31kr.txt", "w", encoding='utf-8') as f: # 1.字符串才能写入 # 2.ensure_ascii默认以ascii编码来转换,因此要改成false # 3.默认json字符串为一行,indent使得在保存时每一级会有2个空格的缩进 # 4.使用str() eval()都不能完美的转换 f.write(json.dumps(ret1, ensure_ascii=False, indent=2))
json使用注意点:
json中字符串都是双引号引起来的
如果不是双引号,可以使用eval来实现简单的字符串和Python类型的转换
如果字符串太复杂,可使用replace替换成双引号
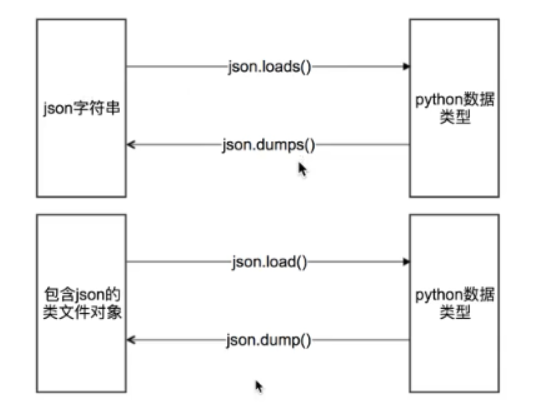
类文件对象:具有read或write方法的对象就是类文件对象
# 使用json.load提取类文件对象中的数据 with open("31kr.txt", "r", encoding='utf-8') as f: ret2 = json.load(f) print(ret2) # json.dump能够把python类型放入类文件对象中 with open("32kr.txt", "w", encoding='utf-8') as f: json.dump(ret1, f, ensure_ascii=False, indent=2)
36kr新闻抓取
import re import requests import json url = "https://36kr.com" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"} html_str = requests.get(url, headers=headers).content.decode() ret = re.findall("\"homeData\":(.*?),\"channel\"", html_str)[0] # with open("1.txt", "w", encoding='utf-8') as f: # f.write(ret) # json格式错误,先写入文件查看,在右下角定位到报错的列 content = json.loads(ret) print(content)
5、豆瓣爬虫练习
(老师的例子,现在的url无法实现爬取)
import requests import json class DoubanSpider(object): def __init__(self): self.url_temp = "https://m.douban.com/rexxar/api/v2/subject_collection/tv_american/items?os=ios&for_mobile=1&callback=jsonp1&start={}&count=18" self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"} def parse_url(self, url): response = requests.get(url, headers=self.headers) return response.content.decode() def get_content_list(self, json_str): ret_dict = json.loads(json_str) content_list = ret_dict['subject_objection_items'] total = ret_dict['total'] return content_list, total def save_content(self, content_list): with open("douban.txt", "a", encoding='utf-8') as f: for content in content_list: f.write(json.dumps(content)) f.write("\n") def run(self): num = 0 total = 100 # 先给一个值,假设有第一页 while num < total+18: # 准备url url = self.url_temp.format(num) # 发送请求,获取响应 json_str = self.parse_url(url) # 提取数据 content_list, total = self.get_content_list(json_str) # 保存 self.save_content(content_list) # 循环结束方法1 # if len(content_list) < 18: # break # 构造下一页的url地址,进入循环 num += 18 if __name__ == '__main__': ds = DoubanSpider() ds.run()
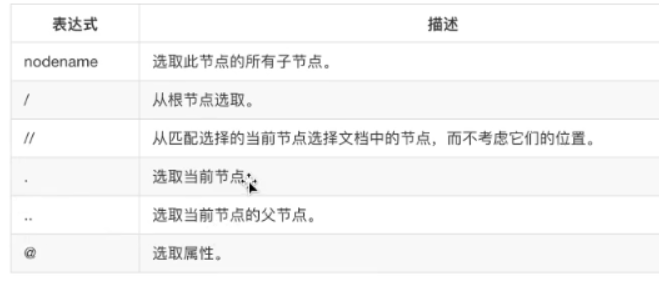
6、XPATH和XML
xpath是一门在HTML/XML文档中查找信息的语言,利用xpath,可以快速定位特定元素
xpath使用路径表达式来选区XML文档中的节点或者节点集,和电脑文件系统中的表达式比较相似。
从标签中提取文本
/html/head/title/text()
获取标签的属性
/html/head/link/@href
直接选择文档中所有li标签,而不考虑它们的位置
//li
选择特定id的ul
//ul[@id="detail-list"]/li
直接选中li中的文本而不用一层一层选
//ul[@id="detail-list"]/li//p/text()
li下任何一个a标签
li//a
获取a下的所有标签的文本
a//text()
获取指定文本内容的标签
//a[text()="下一页"]/@href
