


一、GIL(全局解释器锁)
先看几个例子:
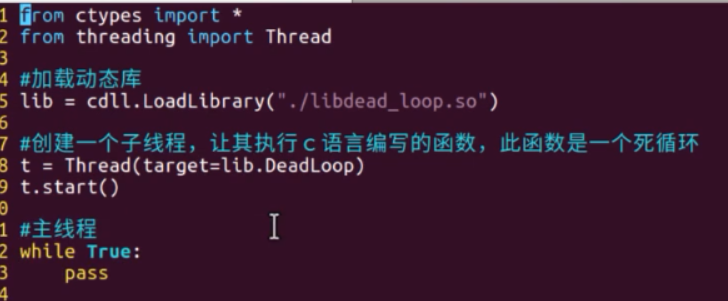
主线程死循环,占满CPU:
while True: pass
import threading # 子线程死循环 def test(): while True: pass t = threading.Thread(target=test) t.start() # 主线程死循环 while True: pass
import multiprocessing # 子进程死循环 def test(): while True: pass t = multiprocessing.Process(target=test) t.start() # 主进程死循环 while True: pass
对比发现,以上程序对双核CPU的资源占用率,
单线程达到了单核100%
多线程达到了两个核50%
多进程达到了两个核100%
原因就是GIL使得多线程实际上同一时刻只有一个线程可以执行代码
面试题:
描述Python GIL的概念, 以及它对python多线程的影响?编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因。
- Python语言和GIL没有半毛钱关系。仅仅是由于历史原因在Cpython虚拟机(解释器),难以移除GIL,而官网推荐使用cpython。
- GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。
- 线程释放GIL锁的情况: 在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL,但在执行完毕后,必须重新获取GIL Python 3.x使用计时器(执行时间达到阈值后,当前线程释放GIL)或Python 2.x,tickets计数达到100
- 多线程爬取比单线程性能有提升,因为遇到IO阻塞会自动释放GIL锁
- 如果使用cpython解释器,有时候使用多进程效率更高,可以真正的利用多核(对于计算密集型程序使用多进程,对于io密集型程序使用多线程或协程)
怎么克服GIL带来的问题:
1.不使用cpython解释器
2.使用C语言来解决GIL问题
二、深拷贝和浅拷贝
1、
浅拷贝是对于一个对象的顶层拷贝
通俗的理解是:拷贝了引用,并没有拷贝内容
In [1]: a = [11,22,33] In [2]: b = a In [3]: b Out[3]: [11, 22, 33]
在Python中仅仅是b指向了a的内存空间,复制的是引用
In [17]: import copy In [18]: a = [11,22] In [19]: b = [33,44] In [20]: c = [a,b] In [21]: d = c In [22]: e = copy.copy(c) In [23]: d Out[23]: [[11, 22], [33, 44]] In [24]: e Out[24]: [[11, 22], [33, 44]] In [25]: id(c) Out[25]: 140452590668232 In [26]: id(e) Out[26]: 140452590810248 In [27]: id(c[0]) Out[27]: 140452606284296 In [28]: id(e[0]) Out[28]: 140452606284296
浅拷贝,只会复制最顶层的那个列表
2、
深拷贝是对于一个对象所有层次的拷贝(递归)
In [4]: import copy In [5]: a = [11,22,33] In [6]: c = copy.deepcopy(a) In [7]: c Out[7]: [11, 22, 33] In [8]: id(a) Out[8]: 140452590668744 In [9]: id(c) Out[9]: 140452590668680
In [30]: import copy In [31]: a = [11,22] In [32]: b = [33,44] In [33]: c = [a,b] In [34]: d = copy.deepcopy(c) In [35]: d Out[35]: [[11, 22], [33, 44]] In [36]: id(d[0]) Out[36]: 140452606283336 In [37]: id(c[0]) Out[37]: 140452590665608
3、
copy和deepcopy对于可变类型,会进行浅拷贝
copy和deepcopy对于不可变类型,不会拷贝,仅仅是指向
In [1]: import copy In [2]: a = (11,22) In [3]: b = a In [4]: c = copy.copy(a) In [5]: id(a) Out[5]: 140708252019144 In [6]: id(b) Out[6]: 140708252019144 In [7]: id(c) Out[7]: 140708252019144
但是,如果元组内有可变类型的数据,deepcopy会进行深拷贝
In [8]: a = [11,22] In [9]: b = [33,44] In [10]: c = (a,b) In [11]: d = copy.deepcopy(c) In [12]: id(c) Out[12]: 140708316907976 In [13]: id(d) Out[13]: 140708252021192
4、
切片操作是浅拷贝
In [15]: a = [11,22] In [16]: b = [33,44] In [17]: c = [a,b] In [18]: d = c[:] In [19]: id(c) Out[19]: 140708236421896 In [20]: id(d) Out[20]: 140708236421192 In [21]: id(c[0]) Out[21]: 140708236511240 In [22]: id(d[0]) Out[22]: 140708236511240
5、
字典的copy方法用来拷贝字典,使用的是浅拷贝,字典中存的都是value的引用
In [24]: d = dict(name="zhangsan", age="17") In [25]: e = d.copy() In [26]: id(d) Out[26]: 140708236555272 In [27]: id(e) Out[27]: 140708236512072 In [29]: id(d["name"]) Out[29]: 140708236554736 In [30]: id(e["name"]) Out[30]: 140708236554736
6、
向函数的形参传入一个列表,对列表进行append,原列表也会被修改
如果传参时调用了deepcopy,原列表则不会变化
三、私有化
xx: 公有变量
_x: 单前置下划线,私有化属性或方法,from somemodule import *禁止导入,类对象和子类可以访问
_X的变量、函数、类在使用from xxx import *时都不会被导入
__xx:双前置下划线,私有属性,无法在外部直接访问(名字重整所以访问不到)。避免与子类中的属性命名冲突。
- 如果在子类中向
__XX赋值,那么会在子类中定义的一个与父类相同名字的属性 - 通过name mangling(名字重整(目的就是以防子类意外重写基类的方法或者属性)如:_Class__object)机制就可以访问private了。
__xx__:双前后下划线,用户名字空间的魔法对象或属性(不是私有!)例如:__init__ , 不要自己发明这样的名字
xx_:单后置下划线,用于避免与Python关键词的冲突
四、import导入模块
导入方式:
from XXX import AAA import XXX import XXX,YYY from XXX import AAA,BBB from XXX import * import XX as ZZ
as相当于定义一个变量指向加载的模块。使用了as后就只能使用别名,不能使用原名
模块搜索路径:
In [1]: import sys In [2]: sys.path Out[2]: ['', '/usr/bin', '/usr/lib/python35.zip', '/usr/lib/python3.5', '/usr/lib/python3.5/plat-x86_64-linux-gnu', '/usr/lib/python3.5/lib-dynload', '/usr/local/lib/python3.5/dist-packages', '/usr/lib/python3/dist-packages', '/usr/lib/python3/dist-packages/IPython/extensions', '/home/python/.ipython']
- 从上面列出的目录里依次查找要导入的模块文件
- ' ' 表示当前路径
- 列表中的路径的先后顺序代表了python解释器在搜索模块时的先后顺序
sys.path的到的就是一个模块搜索路径的列表,可以添加和修改:
In [4]: sys.path.append("/home/yzz/xxx") In [5]: sys.path.insert(0, "/home/yzz/aaa") In [6]: sys.path Out[6]: ['/home/yzz/aaa', '', '/usr/bin', '/usr/lib/python35.zip', '/usr/lib/python3.5', '/usr/lib/python3.5/plat-x86_64-linux-gnu', '/usr/lib/python3.5/lib-dynload', '/usr/local/lib/python3.5/dist-packages', '/usr/lib/python3/dist-packages', '/usr/lib/python3/dist-packages/IPython/extensions', '/home/python/.ipython', '/home/yzz/xxx']
import默认防止模块重复导入,
如果一个模块在导入后又被修改,那么之前导入的模块还是修改之前的内容,
即使再次import,也不会生效。
这时就需要使用reload
import aa from imp import reload reload(aa)
五、封装继承多态
1、封装
好处:
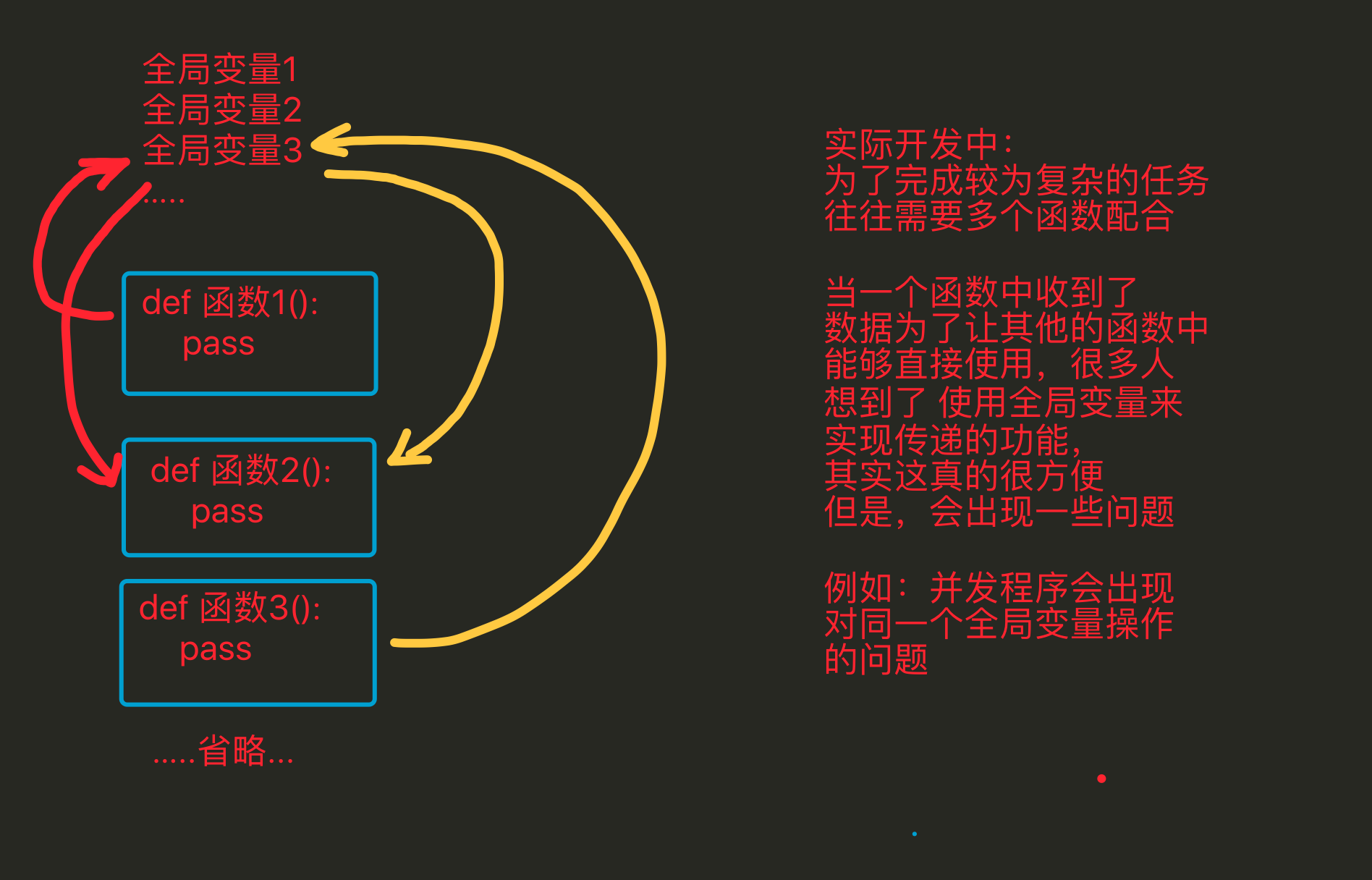
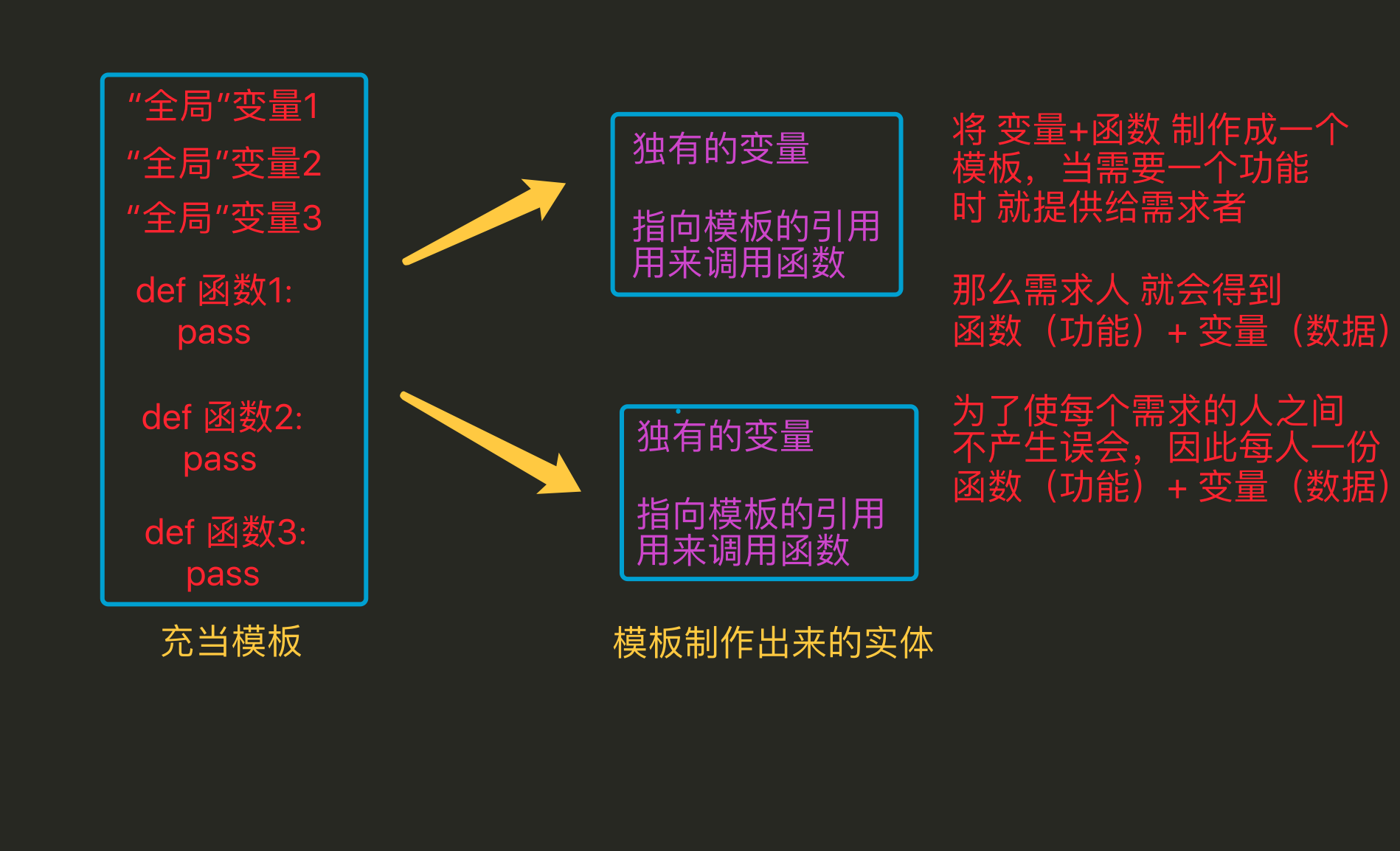
- 在使用面向过程编程时,当需要对数据处理时,需要考虑用哪个模板中哪个函数来进行操作,但是当用面向对象编程时,因为已经将数据存储到了这个独立的空间中,这个独立的空间(即对象)中通过一个特殊的变量(__class__)能够获取到类(模板),而且这个类中的方法是有一定数量的,与此类无关的将不会出现在本类中,因此需要对数据处理时,可以很快速的定位到需要的方法是谁 这样更方便
- 全局变量是只能有1份的,多很多个函数需要多个备份时,往往需要利用其它的变量来进行储存;而通过封装 会将用来存储数据的这个变量 变为了对象中的一个“全局”变量,只要对象不一样那么这个变量就可以再有1份,所以这样更方便
- 代码划分更清晰
可以使用 对象名.__class__ 查看方法,使用 对象名.__dict__ 查看属性
2、继承

好处:
- 能够提升代码的重用率,即开发一个类,可以在多个子功能中直接使用
- 继承能够有效的进行代码的管理,当某个类有问题只要修改这个类就行,而其继承这个类的子类往往不需要就修改
3、多态
class MiniOS(object): """MiniOS 操作系统类 """ def __init__(self, name): self.name = name self.apps = [] # 安装的应用程序名称列表 def __str__(self): return "%s 安装的软件列表为 %s" % (self.name, str(self.apps)) def install_app(self, app): # 判断是否已经安装了软件 if app.name in self.apps: print("已经安装了 %s,无需再次安装" % app.name) else: app.install() self.apps.append(app.name) class App(object): def __init__(self, name, version, desc): self.name = name self.version = version self.desc = desc def __str__(self): return "%s 的当前版本是 %s - %s" % (self.name, self.version, self.desc) def install(self): print("将 %s [%s] 的执行程序复制到程序目录..." % (self.name, self.version)) class PyCharm(App): pass class Chrome(App): def install(self): print("正在解压缩安装程序...") super().install() linux = MiniOS("Linux") print(linux) pycharm = PyCharm("PyCharm", "1.0", "python 开发的 IDE 环境") chrome = Chrome("Chrome", "2.0", "谷歌浏览器") linux.install_app(pycharm) linux.install_app(chrome) linux.install_app(chrome) print(linux)
4、多继承和MRO
print("******多继承使用类名.__init__ 发生的状态******") class Parent(object): def __init__(self, name): print('parent的init开始被调用') self.name = name print('parent的init结束被调用') class Son1(Parent): def __init__(self, name, age): print('Son1的init开始被调用') self.age = age Parent.__init__(self, name) print('Son1的init结束被调用') class Son2(Parent): def __init__(self, name, gender): print('Son2的init开始被调用') self.gender = gender Parent.__init__(self, name) print('Son2的init结束被调用') class Grandson(Son1, Son2): def __init__(self, name, age, gender): print('Grandson的init开始被调用') Son1.__init__(self, name, age) # 单独调用父类的初始化方法 Son2.__init__(self, name, gender) print('Grandson的init结束被调用') gs = Grandson('grandson', 12, '男') print('姓名:', gs.name) print('年龄:', gs.age) print('性别:', gs.gender) print("******多继承使用类名.__init__ 发生的状态******\n\n")
******多继承使用类名.__init__ 发生的状态****** Grandson的init开始被调用 Son1的init开始被调用 parent的init开始被调用 parent的init结束被调用 Son1的init结束被调用 Son2的init开始被调用 parent的init开始被调用 parent的init结束被调用 Son2的init结束被调用 Grandson的init结束被调用 姓名: grandson 年龄: 12 性别: 男 ******多继承使用类名.__init__ 发生的状态******
使用 父类名.super(参数要有self,传父类所需的参数)
print("******多继承使用super().__init__ 发生的状态******") class Parent(object): def __init__(self, name, *args, **kwargs): # 为避免多继承报错,使用不定长参数,接受参数 print('parent的init开始被调用') self.name = name print('parent的init结束被调用') class Son1(Parent): def __init__(self, name, age, *args, **kwargs): # 为避免多继承报错,使用不定长参数,接受参数 print('Son1的init开始被调用') self.age = age super().__init__(name, *args, **kwargs) # 为避免多继承报错,使用不定长参数,接受参数 print('Son1的init结束被调用') class Son2(Parent): def __init__(self, name, gender, *args, **kwargs): # 为避免多继承报错,使用不定长参数,接受参数 print('Son2的init开始被调用') self.gender = gender super().__init__(name, *args, **kwargs) # 为避免多继承报错,使用不定长参数,接受参数 print('Son2的init结束被调用') class Grandson(Son1, Son2): def __init__(self, name, age, gender): print('Grandson的init开始被调用') # 多继承时,相对于使用类名.__init__方法,要把每个父类全部写一遍 # 而super只用一句话,执行了全部父类的方法,这也是为何多继承需要全部传参的一个原因 # super(Grandson, self).__init__(name, age, gender) 这么写效果是一样的,会拿着grandson到mro中匹配 super().__init__(name, age, gender) print('Grandson的init结束被调用') print(Grandson.__mro__) gs = Grandson('grandson', 12, '男') print('姓名:', gs.name) print('年龄:', gs.age) print('性别:', gs.gender) print("******多继承使用super().__init__ 发生的状态******\n\n")
******多继承使用super().__init__ 发生的状态****** (<class '__main__.Grandson'>, <class '__main__.Son1'>, <class '__main__.Son2'>, <class '__main__.Parent'>, <class 'object'>) Grandson的init开始被调用 Son1的init开始被调用 Son2的init开始被调用 parent的init开始被调用 parent的init结束被调用 Son2的init结束被调用 Son1的init结束被调用 Grandson的init结束被调用 姓名: grandson 年龄: 12 性别: 男 ******多继承使用super().__init__ 发生的状态******
使用 子类名.__mro__ 打印MRO,super会按照MRO的顺序调用
以上2个代码执行的结果不同:
如果2个子类中都继承了父类,当在子类中通过父类名调用时,parent被执行了2次
如果2个子类中都继承了父类,当在子类中通过super调用时,parent被执行了1次
super().__init__相对于类名.__init__,在单继承上用法基本无差
但在多继承上有区别,super方法能保证每个父类的方法只会执行一次,而使用类名的方法会导致方法被执行多次,具体看前面的输出结果
多继承时,使用super方法,对父类的传参数,应该是由于python中super的算法导致的原因,必须把参数全部传递,否则会报错
单继承时,使用super方法,则不能全部传递,只能传父类方法所需的参数,否则会报错
多继承时,相对于使用类名.__init__方法,要把每个父类全部写一遍, 而使用super方法,只需写一句话便执行了全部父类的方法,这也是为何多继承需要全部传参的一个原因
class Parent(object): x = 1 class Child1(Parent): pass class Child2(Parent): pass print(Parent.x, Child1.x, Child2.x) Child1.x = 2 print(Parent.x, Child1.x, Child2.x) Parent.x = 3 print(Parent.x, Child1.x, Child2.x)
1 1 1 1 2 1 3 2 3
继承不是复制,子类从父类中取值
如果任何子类重写了x的值(例如,我们执行语句 Child1.x = 2),该值仅仅在子类中被改变
当我们执行语句 Parent.x = 3,这个改变会影响到任何未重写该值的子类当中的值。
六、类的方法和属性
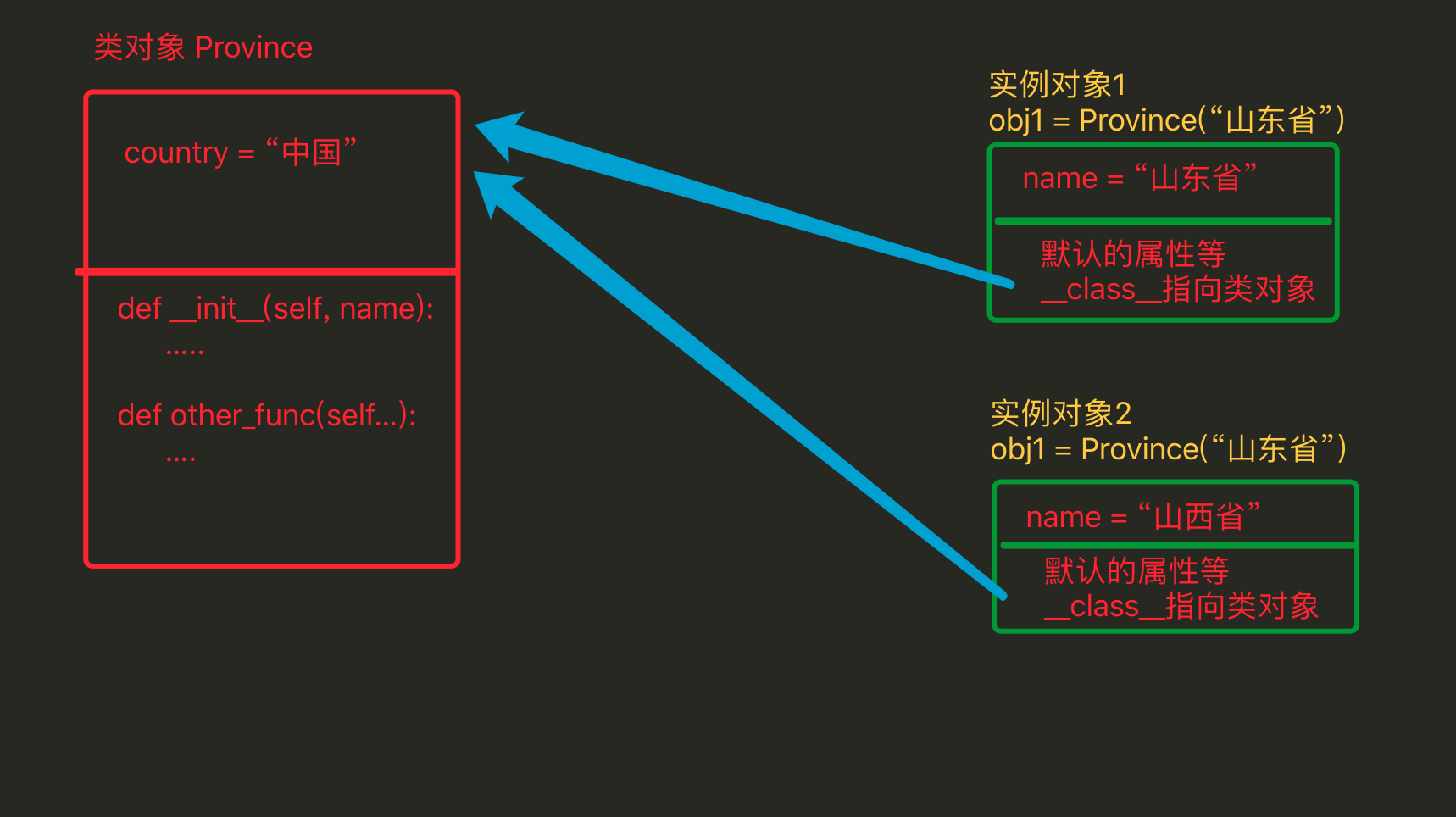
1、类属性和实例属性
- 实例属性属于对象,实例属性在每个对象中都要保存一份
- 类属性属于类,类属性在内存中只保存一份
class Province(object): # 类属性 country = '中国' def __init__(self, name): # 实例属性 self.name = name # 创建一个实例对象 obj = Province('山东省') # 直接访问实例属性 print(obj.name) # 直接访问类属性 Province.country
类本身也是一个对象
实例对象中的__class__指向类对象
想要用obj1修改country的值:
ojb1.country = "XXX" # 不能修改,只会创建一个新的属性
obj1.__class__.country = "YYY" # 可以修改
实际中最好通过类方法来修改
2、实例方法、静态方法、类方法
- 实例方法:由对象调用;至少一个self参数;执行实例方法时,自动将调用该方法的对象赋值给self;
- 类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类赋值给cls;
- 静态方法:由类调用;无默认参数;
class Foo(object): def __init__(self, name): self.name = name def ord_func(self): """ 定义实例方法,至少有一个self参数 """ # print(self.name) print('实例方法') @classmethod def class_func(cls): """ 定义类方法,至少有一个cls参数 """ print('类方法') @staticmethod def static_func(): """ 定义静态方法 ,无默认参数""" print('静态方法') f = Foo("中国") # 调用实例方法 f.ord_func() # 调用类方法 Foo.class_func() # 调用静态方法 Foo.static_func()
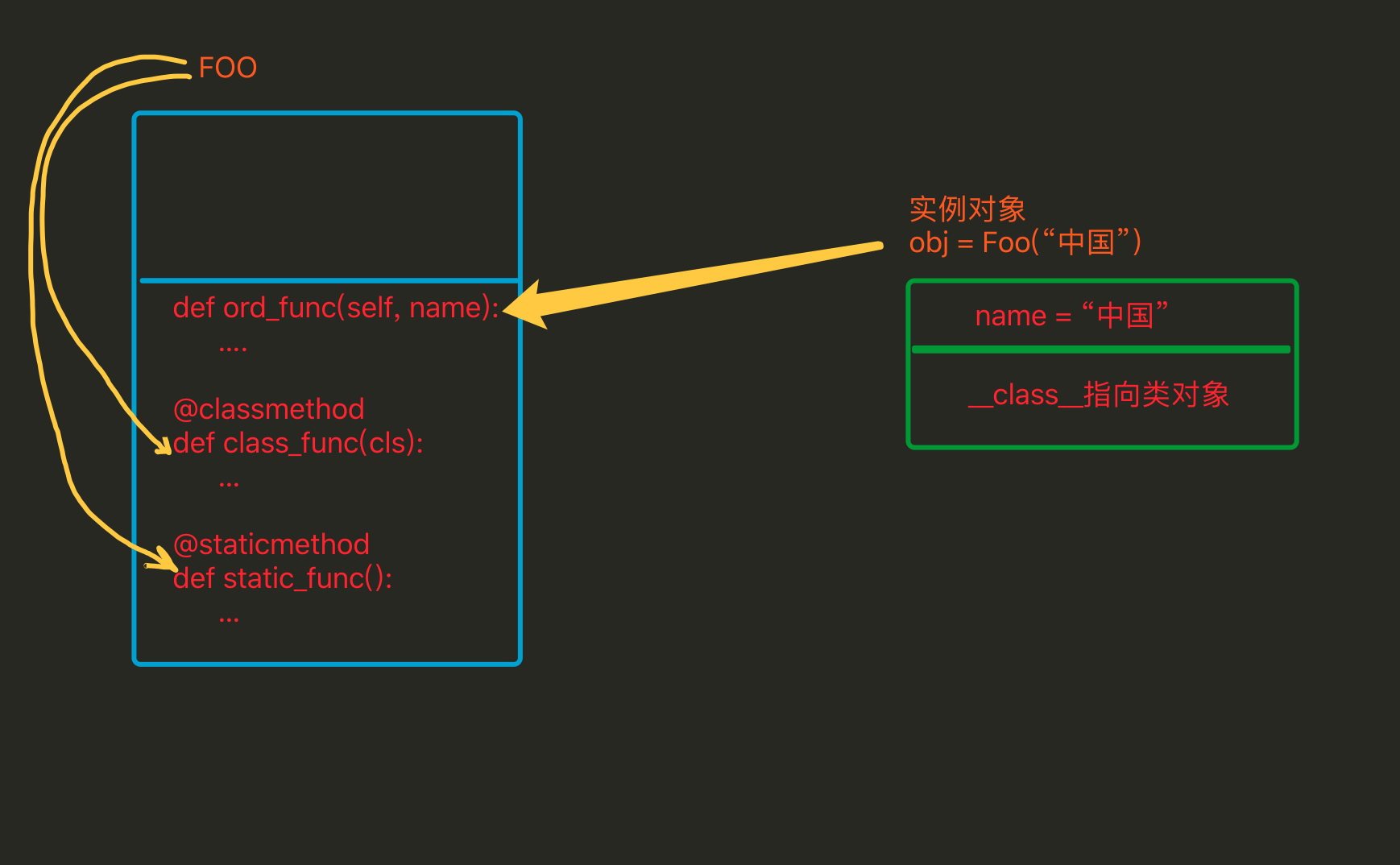
相同点:对于所有的方法而言,均属于类,所以 在内存中也只保存一份
不同点:方法调用者不同、调用方法时自动传入的参数不同。
3、property属性
Python的property属性的功能是:property属性内部进行一系列的逻辑计算,最终将计算结果返回。
class Foo: def func(self): pass # 定义property属性,在实例方法的基础上增加一个@property装饰器,并且仅有一个self参数 @property def prop(self): return 100 # ############### 调用 ############### foo_obj = Foo() foo_obj.func() # 调用实例方法 foo_obj.prop # 调用property属性和调用实例属性的格式一样
例:
class Pager: def __init__(self, current_page): self.current_page = current_page self.per_items = 10 @property def start(self): return (self.current_page-1)*self.per_items+1 @property def end(self): return self.current_page*self.per_items p = Pager(4) print(p.start) print(p.end)
31 40
property两种定义方式
(1)装饰器方式:在实例方法上应用装饰器
经典类(Python2不继承object的类):具有一种property装饰器
经典类中的属性只有一种访问方式,其对应被 @property 修饰的方法
class Goods: @property def price(self): return 199 g = Goods() print(g.price)
新式类(Python3中的类):具有三种property装饰器
新式类中的属性有三种访问方式,并分别对应了三个被@property、@方法名.setter、@方法名.deleter修饰的方法
class Goods(object): def __init__(self): self.original_price = 100 self.discount = 0.3 @property def price(self): return self.original_price * self.discount @price.setter def price(self, value): self.original_price = value @price.deleter def price(self): del self.original_price g = Goods() print(g.price) # 获取商品价格 g.price = 200 # 修改商品原价 print(g.price) del g.price # 删除商品原价
(2)类属性方式:创建值为property对象的类属性
property方法中有个四个参数:
- 第一个参数是方法名,调用 对象.属性 时自动触发执行方法
- 第二个参数是方法名,调用 对象.属性 = XXX 时自动触发执行方法
- 第三个参数是方法名,调用 del 对象.属性 时自动触发执行方法
- 第四个参数是字符串,调用 对象.属性.__doc__ ,此参数是该属性的描述信息
class Foo(object): def get_bar(self): print("--getter--") return 'china' def set_bar(self, value): print("--setter--") return "set value:" + value def del_bar(self): print("--deleter--") return 'china' BAR = property(get_bar, set_bar, del_bar, "description") f = Foo() print(f.BAR) # 自动调用第一个参数中定义的方法:get_bar f.BAR = 'england' # 自动调用第二个参数中定义的方法:set_bar方法 print(f.BAR.__doc__) # 自动获取第四个参数中设置的值:description del f.BAR # 自动调用第三个参数中定义的方法:del_bar方法
通过使用property属性,能够简化调用者在获取数据的流程
4、私有属性和名字重整
Python的私有属性实际上是进行了名字重整
In [1]: class Test(object): ...: def __init__(self,name): ...: self.__name = name ...: In [2]: t = Test("china") In [3]: t.__dict__ Out[3]: {'_Test__name': 'china'} In [4]: t._Test__name Out[4]: 'china'
5、魔法属性
__doc__:表示类的描述信息,有两种查看方法
n [7]: class D(object): ...: """ ...: iqjrvvkjdb ...: 123456 ...: kjtufgnxmvg ...: """ ...: pass ...: In [8]: help(D) In [9]: D.__doc__
__module__ 表示当前操作的对象在那个模块
__class__ 表示当前操作的对象的类是什么
test.py class Person(object): def __init__(self): self.name = 'laowang'
main.py from test import Person obj = Person() print(obj.__module__) # 输出 test 即:输出模块 print(obj.__class__) # 输出 test.Person 即:输出类
__init__:初始化方法,通过类创建对象时,自动触发执行
不能说成构造方法,还要先调用__new__
__del__:当对象在内存中被释放时,自动触发执行
此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,__del__的调用由解释器在进行垃圾回收时自动触发执行。
__call__:对象后面加括号,触发执行
class Foo: def __init__(self): pass def __call__(self, *args, **kwargs): print('__call__') obj = Foo() # 执行 __init__ obj() # 执行 __call__
__dict__:查看类或对象中的所有属性
类的实例属性属于对象;类中的类属性和方法等属于类;
__str__:在打印对象时,输出该方法的返回值
__getitem__:获取数据
__setitem__:设置数据
__delitem__:删除数据
class Foo(object): def __init__(self): self.names = {} def __getitem__(self, key): print('__getitem__', key) return self.names[key] def __setitem__(self, key, value): print('__setitem__', key, value) self.names[key] = value def __delitem__(self, key): print('__delitem__', key) del self.names[key] obj = Foo() obj['k'] = "laowang" # 自动触发执行 __setitem__ result = obj['k'] # 自动触发执行 __getitem__ print(result) del obj['k'] # 自动触发执行 __delitem__
__getslice__
__setslice__
__delslice__
用于分片操作
class Foo(object): def __getslice__(self, i, j): print('__getslice__', i, j) def __setslice__(self, i, j, sequence): print('__setslice__', i, j) def __delslice__(self, i, j): print('__delslice__', i, j) obj = Foo() obj[-1:1] # 自动触发执行 __getslice__ obj[0:1] = [11,22,33,44] # 自动触发执行 __setslice__ del obj[0:2] # 自动触发执行 __delslice__
列表切片可以直接设置值:
In [8]: nums = [x for x in range(10)] In [9]: nums[:3] Out[9]: [0, 1, 2] In [10]: nums[:3] = [11,22,33] In [11]: nums Out[11]: [11, 22, 33, 3, 4, 5, 6, 7, 8, 9] In [12]: nums[:3] = [111] In [13]: nums Out[13]: [111, 3, 4, 5, 6, 7, 8, 9] In [14]: nums[:3] = [11,22,33,44,55] In [15]: nums Out[15]: [11, 22, 33, 44, 55, 5, 6, 7, 8, 9]
6、with和上下文管理器
with的使用场景:
对于系统资源如文件、数据库连接、socket 而言,应用程序打开这些资源并执行完业务逻辑之后,必须做的一件事就是要关闭(断开)该资源。
如果连接数过多或者打开文件过多而没有及时关闭的话,系统就会出现错误。
def test(): f = open('output.txt', 'w') try: f.write("123456") except IOError: print("io异常") finally: # 无论是否产生异常都会执行的代码 f.close()
改进版:使用with,更加优雅简洁
def test(): with open('output.txt', 'w') as f: f.write("123456")
任何实现了 __enter__() 和 __exit__() 方法的对象都可称之为上下文管理器,上下文管理器对象可以使用 with 关键字。
__enter__() 方法返回资源对象,这里就是你将要打开的那个文件对象,__exit__() 方法处理一些清除工作。
使用with时会先调用__enter__,使用结束后会自动调用__exit__。
class File(object): def __init__(self, file_name, mode): self.file_name = file_name self.mode = mode def __enter__(self): print("--enter--") self.f = open(self.file_name, self.mode) return self.f def __exit__(self, *args): print("--exit--") self.f.close() with File("input.txt", 'w') as f: f.read()
Python 提供了 with 语法用于简化资源操作的后续清除操作,是 try/finally 的替代方法,实现原理建立在上下文管理器之上。
此外,Python 还提供了一个 contextmanager 的装饰器,更进一步简化了上下文管理器的实现方式。
通过 yield 将函数分割成两部分,yield 之前的语句在 __enter__ 方法中执行,yield 之后的语句在 __exit__ 方法中执行。
紧跟在 yield 后面的值是函数的返回值。
from contextlib import contextmanager @contextmanager def my_open(path, mode): f = open(path, mode) yield f f.close() with my_open('123,txt', 'w') as f: f.write("123")
