


一、正则表达式
1、re模块
# 导入re模块 import re # 使用match方法进行匹配操作 result = re.match(正则表达式,要匹配的字符串) # 如果上一步匹配到数据的话,可以使用group方法来提取数据 result.group()
import re # 若没有返回值,说明匹配不成功 res = re.match(r"hell", "hello world") print(res) # 提取数据 print(res.group())
2、匹配单个字符
| 字符 | 功能 |
|---|---|
| . | 匹配任意1个字符(除了\n) |
| [ ] | 匹配[ ]中列举的字符 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即 空格,tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、_ |
| \W | 匹配非单词字符 |
import re # \d匹配一位数字 res = re.match(r"速度与激情\d", "速度与激情1") print(res.group()) res = re.match(r"速度与激情[12345678]", "速度与激情9") print(res) res = re.match(r"速度与激情[1-8]", "速度与激情88") print(res.group()) res = re.match(r"速度与激情[1-36-8]", "速度与激情5") print(res) res = re.match(r"速度与激情[1-8abcd]", "速度与激情a") print(res.group()) res = re.match(r"速度与激情[1-8a-zA-Z]", "速度与激情X") print(res.group()) # \w匹配单词字符 res = re.match(r"速度与激情\w", "速度与激情s") print(res.group()) # \w现在也支持中文日文字符,因此要慎用 res = re.match(r"速度与激情\w", "速度与激情_") print(res.group()) # \s匹配空白字符 res = re.match(r"速度与激情\s\d", "速度与激情 1") print(res.group()) res = re.match(r"速度与激情.", "速度与激情$") print(res.group())
3、匹配多个字符
| 字符 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次 |
import re # 可以匹配1-2位数字 res = re.match(r"嫦娥\d{1,2}号", "嫦娥3号") print(res.group()) # 可以匹配一到两位数字 res = re.match(r"嫦娥\d{1,2}", "嫦娥45号") print(res.group()) # 手机号码必须11位 res = re.match(r"\d{11}", "13633576869") print(res.group()) # ?前一个字符出现1次或0次 res = re.match(r"021-?\d{8}", "021-12345678") print(res.group()) res = re.match(r"010-?\d{8}", "01012345678") print(res.group()) html_content = """kahfibdfv jskb4658jvd 12564897 hk78945wkvjvbfnjkb""" # *前一个字符出现1次或无限次 res = re.match(r".*", html_content) print(res.group()) # 让.包括空白字符 res = re.match(r".*", html_content, re.S) print(res.group()) # +至少有一个字符 res = re.match(r".+", "") print(res)
4、判断一个变量名是否有效
import re names = ["_name", "name3#", "32iu", "ret_name", "a", "yu&*ji"] for name in names: res = re.match(r"[a-zA-Z_][a-zA-Z0-9_]*", name) if res: print("变量名%s符合要求,通过正则匹配出来的数据是%s" % (name, res.group())) else: print("变量名%s非法" % name)
变量名_name符合要求,通过正则匹配出来的数据是_name 变量名name3#符合要求,通过正则匹配出来的数据是name3 变量名32iu非法 变量名ret_name符合要求,通过正则匹配出来的数据是ret_name 变量名a符合要求,通过正则匹配出来的数据是a 变量名yu&*ji符合要求,通过正则匹配出来的数据是yu
5、匹配开头结尾
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
import re names = ["_name", "name3#", "32iu", "ret_name", "a", "yu&*ji"] for name in names: # ^...$ 表示从头到尾判断 res = re.match(r"^[a-zA-Z_][a-zA-Z0-9_]*$", name) if res: print("变量名%s符合要求,通过正则匹配出来的数据是%s" % (name, res.group())) else: print("变量名%s非法" % name)
6、匹配163邮箱、转义
import re def main(): email = input("输入邮箱地址:") res = re.match(r"[a-zA-Z0-9_]{4,20}@163\.com$", email) if res: print("%s符合要求" % email) else: print("%s不符合要求" % email) if __name__ == '__main__': main()
如果在正则表达式中需要用到某些普通字符,需要在前面加上一个反斜杠 \ 进行转义
7、分组
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
\num |
引用分组num匹配到的字符串 |
(?P<name>) |
分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
import re def main(): email = input("请输入邮箱地址:") res = re.match(r"[a-zA-Z0-9_]{4,20}@(163|126|google|qq)\.com$", email) if res: print("%s符合规范" % email) else: print("%s不符合规范" % email) if __name__ == "__main__": main()
import re def main(): email = input("请输入邮箱地址:") res = re.match(r"([a-zA-Z0-9_]{4,20})@(163|126|google|qq)\.com$", email) print(res.group()) # ()中的数据可以用group来取(比如用来统计各种邮箱注册人数) print(res.group(1)) print(res.group(2)) if __name__ == "__main__": main()
请输入邮箱地址:yzz1234@126.com yzz1234@126.com yzz1234 126
引用分组中的字符串:
import re html_content = "<h1>hahaha</h1>" # \1 使标签与第一个括号中匹配(取分组中的值) ret = re.match(r"<(\w*)>.*</\1>", html_content) print(ret.group(1))
html_content = "<body><h1>hahaha</h1></body>" ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>", html_content) print(ret.group(1)) print(ret.group(2))
分组起名:
import re html_content = "<body><h1>hahaha</h1></body>" # (?P<分组名> 分组内容) # (?P=分组名 分组内容) ret = re.match(r"<(?P<p1>\w*)><(?P<p2>\w*)>.*</(?P=p2)></(?P=p1)>", html_content) print(ret.group())
8、re模块的高级用法
search不用从头开始匹配,返回最先匹配到的值
import re ret = re.search(r"\d+", "阅读数 9999") print(ret.group())
findall可以返回所有匹配的值
# 返回一个列表 ret = re.findall(r"\d+", "python = 1000, c = 990, c++ = 1234") print(ret)
['1000', '990', '1234']
sub可以将匹配到的数据进行替换
# 替换匹配到的数据 ret = re.sub(r"\d+", "000", "python=111") print(ret)
python=000
使用函数对取到的数据进行处理:
import re def add(res): num = res.group() num = int(num) + 1 return str(num) ret = re.sub(r"\d+", add, "python=990") print(ret)
split切割字符串
# 根据匹配切割字符串,返回一个列表 ret = re.split(r":| ", "info:xh age:21") print(ret)
['info', 'xh', 'age', '21']
去掉HTML标签提取文本(简单的数据清洗)
import re html_content = """<div> <p>岗位职责:</p> <p>完成推荐算法、数据统计、接口、后台等服务器端相关工作</p> <p><br></p> <p>必备要求:</p> <p>良好的自我驱动力和职业素养,工作积极主动、结果导向</p> <p> <br></p> <p>技术要求:</p> <p>1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式</p> <p>2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架</p> <p>3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种<br></p> <p>4、掌握NoSQL、MQ,熟练使用对应技术解决方案</p> <p>5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js</p> <p> <br></p> <p>加分项:</p> <p>大数据,数理统计,机器学习,sklearn,高性能,大并发。</p> </div>""" ret = re.sub(r"<\w*>|</\w*>|&.*;", "", html_content) print(ret)
[^>]*表示任意个不是>的字符:
<[^>]*>| |\n
9、贪婪与非贪婪
Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;
非贪婪则相反,总是尝试匹配尽可能少的字符。
在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
>>> s="This is a number 234-235-22-423" >>> r=re.match(".+(\d+-\d+-\d+-\d+)",s) >>> r.group(1) '4-235-22-423' >>> r=re.match(".+?(\d+-\d+-\d+-\d+)",s) >>> r.group(1) '234-235-22-423'
正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串
在我们上面的例子里面,“.+”会从字符串的启始处抓取满足模式的最长字符,其中包括我们想得到的第一个整型字段的中的大部分。
“\d+”只需一位字符就可以匹配,所以它匹配了数字“4”,而“.+”则匹配了从字符串起始到这个第一位数字4之前的所有字符。
>>> re.match(r"aa(\d+)","aa2343ddd").group(1) '2343' >>> re.match(r"aa(\d+?)","aa2343ddd").group(1) '2' >>> re.match(r"aa(\d+)ddd","aa2343ddd").group(1) '2343' >>> re.match(r"aa(\d+?)ddd","aa2343ddd").group(1) '2343'
提取URL地址:
test_str = '<img data-original="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" style="display: inline;">' re.search(r"https://.*?\.jpg", test_str)
10、r的作用
>>> mm = "c:\\a\\b\\c" >>> mm 'c:\\a\\b\\c' >>> print(mm) c:\a\b\c >>> re.match("c:\\\\",mm).group() 'c:\\' >>> ret = re.match("c:\\\\",mm).group() >>> print(ret) c:\ >>> ret = re.match("c:\\\\a",mm).group() >>> print(ret) c:\a >>> ret = re.match(r"c:\\a",mm).group() >>> print(ret) c:\a >>> ret = re.match(r"c:\a",mm).group() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'NoneType' object has no attribute 'group'
Python中字符串前面加上 r 表示原生字符串,
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>>> ret = re.match(r"c:\\a",mm).group() >>> print(ret) c:\a
二、HTTP服务器
1、HTTP协议
超文本传输协议HTTP,基于TCP

浏览器向服务器发送的格式:
GET /a/b/c/1.html HTTP/1.1 Host: 127.0.0.1:8080 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9
服务器向浏览器回送的格式:HTTP响应分为Header和Body两部分,中间有一个空行隔开
HTTP/1.1 200 OK Bdpagetype: 1 Bdqid: 0xa8f8670b0003b743 Cache-Control: private Connection: Keep-Alive Content-Encoding: gzip Content-Type: text/html Cxy_all: baidu+c0211afc00e8843fed94a6ee19c14580 Date: Thu, 18 Jul 2019 14:02:24 GMT Expires: Thu, 18 Jul 2019 14:01:35 GMT Server: BWS/1.1 Set-Cookie: delPer=0; path=/; domain=.baidu.com Set-Cookie: BDSVRTM=0; path=/ Set-Cookie: BD_HOME=0; path=/ Set-Cookie: H_PS_PSSID=1458_21079_29522_29520_28518_29099_28835_29220_26350_29460; path=/; domain=.baidu.com Strict-Transport-Security: max-age=172800 Vary: Accept-Encoding X-Ua-Compatible: IE=Edge,chrome=1 Transfer-Encoding: chunked
<h1>hahaha</h1>
2、返回固定页面的HTTP服务器
import socket def service_client(client_socket, client_addr): # 接收浏览器发来的请求 request = client_socket.recv(1024) print(request) # 返回http格式的数据给浏览器 # 浏览器无法解析\n,应该写成\r\n response = "HTTP/1.1 200 ok\r\n" response += "\r\n" response += "<h1>hello world</h1>" client_socket.send(response.encode('utf-8')) client_socket.close() def main(): # 创建套接字 tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 绑定 tcp_socket.bind(('', 9876)) # 监听 tcp_socket.listen(128) while True: # 等待客户端链接 client_socket, client_addr = tcp_socket.accept() # 为这个客户端服务 service_client(client_socket, client_addr) tcp_socket.close() if __name__ == "__main__": main()
3、tcp三次握手、四次挥手
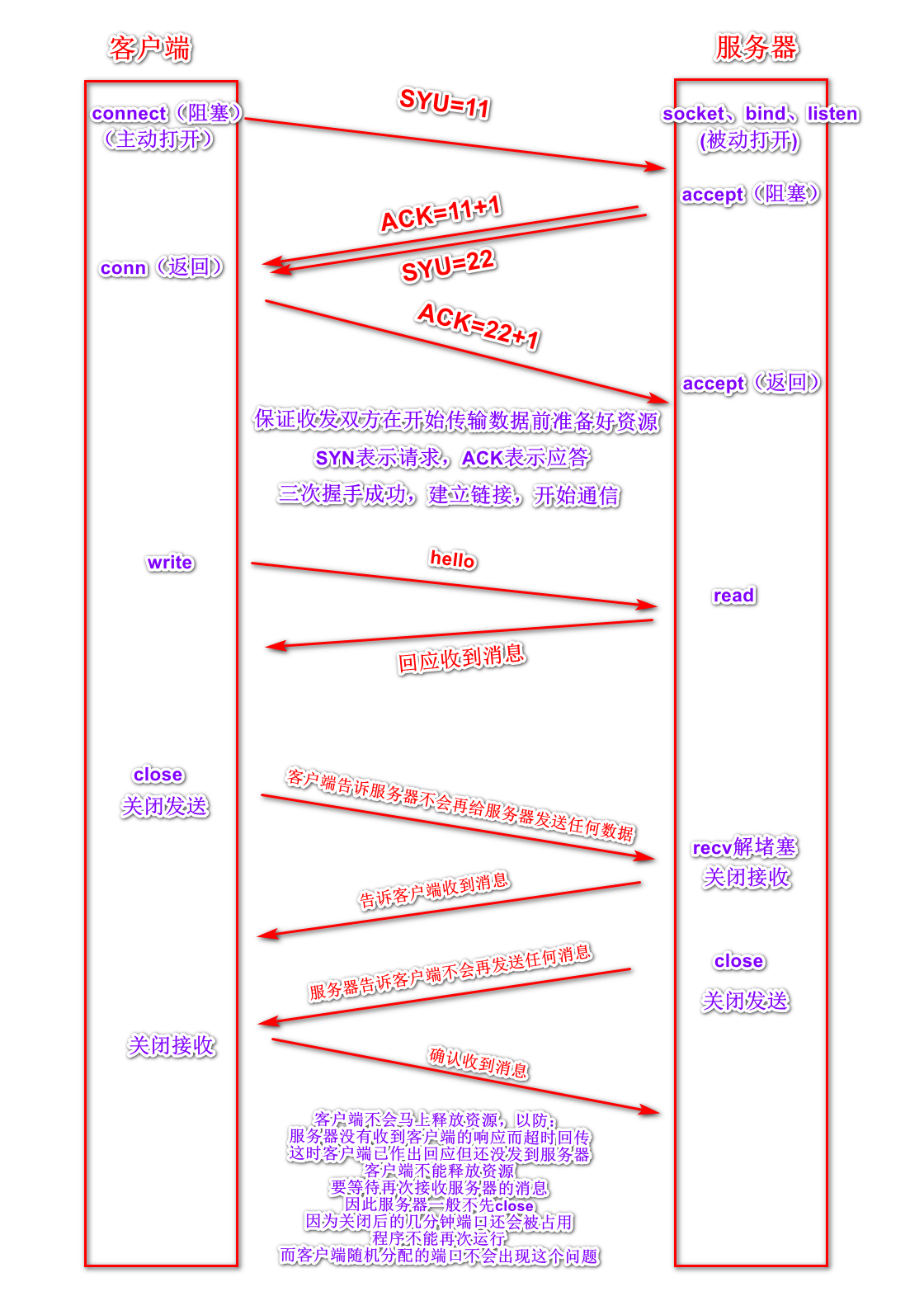
import socket def service_client(client_socket, client_addr): # 接收浏览器发来的请求 request = client_socket.recv(1024) print(request) # 返回http格式的数据给浏览器 # 浏览器无法解析\n,应该写成\r\n response = "HTTP/1.1 200 ok\r\n" response += "\r\n" response += "<h1>hello world</h1>" client_socket.send(response.encode('utf-8')) client_socket.close() def main(): # 创建套接字 tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 设置当服务器先close 即服务器端4次挥手之后资源能够立即释放,这样就保证了,下次运行程序时 可以立即绑定7788端口 tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 绑定 tcp_socket.bind(('', 9876)) # 监听 tcp_socket.listen(128) while True: # 等待客户端链接 client_socket, client_addr = tcp_socket.accept() # 为这个客户端服务 service_client(client_socket, client_addr) tcp_socket.close() if __name__ == "__main__": main()
4、返回浏览器需要的页面
import socket import re def service(client_socket): # 解码成字符串 request = client_socket.recv(1024).decode('utf-8') print(request) # 按行切割 request_lines = request.splitlines() # 正则:可以有1到多个不是/的字符,然后从/开始一直匹配到空格停下 ret = re.match(r"[^/]+(/[^ ]*)", request_lines[0]) # 正则匹配成功,就提取出文件地址 if ret: file_name = ret.group(1) # print(file_name) if file_name == "/": file_name = "/index.html" try: f = open("./html" + file_name, "rb") except: # 如果打开文件失败,返回错误代码 response = "HTTP/1.1 404 NOT FOUND\r\n" response += "\r\n" response += "----file not found----" client_socket.send(response.encode('utf-8')) else: # else:没有异常才会执行的代码 # 字符串和二进制不能直接加,html_content不能和response直接加 html_content = f.read() f.close() response = "HTTP/1.1 200 ok\r\n" response += "\r\n" client_socket.send(response.encode('utf-8')) client_socket.send(html_content) client_socket.close() def main(): tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) tcp_socket.bind(('', 7788)) tcp_socket.listen(128) while True: client_socket, client_addr = tcp_socket.accept() service(client_socket) tcp_socket.close() if __name__ == '__main__': main()
5、多进程实现http服务器
import socket import re import multiprocessing def service(client_socket): request = client_socket.recv(1024).decode('utf-8') request_lines = request.splitlines() ret = re.match(r"[^/]+(/[^ ]*)", request_lines[0]) if ret: file_name = ret.group(1) if file_name == "/": file_name = "/index.html" try: f = open("html" + file_name, 'rb') except: response = "HTTP/1.1 404 NOT FOUND\r\n" response += "\r\n" response += "----404 not found----" client_socket.send(response.encode('utf-8')) else: response = "HTTP/1.1 200 OK\r\n" response += "\r\n" html_content = f.read() f.close() client_socket.send(response.encode('utf-8')) client_socket.send(html_content) client_socket.close() def main(): tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) tcp_socket.bind(('', 7788)) tcp_socket.listen(128) while True: client_socket, client_addr = tcp_socket.accept() p = multiprocessing.Process(target=service, args=(client_socket,)) p.start() # 子进程会把主进程所有资源复制一份 # 因此只有在主进程和子进程都关闭了资源,资源才会真正的关闭 client_socket.close() tcp_socket.close() if __name__ == '__main__': main()
6、多线程实现http服务器
import socket import re import threading def service(client_socket): request = client_socket.recv(1024).decode('utf-8') request_lines = request.splitlines() ret = re.match(r"[^/]+(/[^ ]*)", request_lines[0]) if ret: file_name = ret.group(1) if file_name == "/": file_name = "/index.html" try: f = open("html" + file_name, 'rb') except: response = "HTTP/1.1 404 NOT FOUND\r\n" response += "\r\n" response += "----404 not found----" client_socket.send(response.encode('utf-8')) else: response = "HTTP/1.1 200 OK\r\n" response += "\r\n" html_content = f.read() f.close() client_socket.send(response.encode('utf-8')) client_socket.send(html_content) client_socket.close() def main(): tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) tcp_socket.bind(('', 7788)) tcp_socket.listen(128) while True: client_socket, client_addr = tcp_socket.accept() t = threading.Thread(target=service, args=(client_socket,)) t.start() # 多线程之间共享资源,在主进程关闭资源会出错 # client_socket.close() tcp_socket.close() if __name__ == '__main__': main()
7、gevent实现http服务器
import socket import re import gevent from gevent import monkey monkey.patch_all() def service(client_socket): request = client_socket.recv(1024).decode('utf-8') request_lines = request.splitlines() ret = re.match(r"[^/]+(/[^ ]*)", request_lines[0]) if ret: file_name = ret.group(1) if file_name == "/": file_name = "/index.html" try: f = open("html" + file_name, 'rb') except: response = "HTTP/1.1 404 NOT FOUND\r\n" response += "\r\n" response += "----404 not found----" client_socket.send(response.encode('utf-8')) else: response = "HTTP/1.1 200 OK\r\n" response += "\r\n" html_content = f.read() f.close() client_socket.send(response.encode('utf-8')) client_socket.send(html_content) client_socket.close() def main(): tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) tcp_socket.bind(('', 7788)) tcp_socket.listen(128) while True: client_socket, client_addr = tcp_socket.accept() gevent.spawn(service, client_socket) tcp_socket.close() if __name__ == '__main__': main()
8、单进程、单线程、非堵塞
单进程、单线程中要有多个套接字,但是在遇到accept、recv时线程会堵塞
tcp_socket.setblocking(False) # 设置套接字为非堵塞的方式
accept、recv没有收到数据立即会产生异常
import socket import time def main(): tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_socket.setblocking(False) # 设置套接字为非堵塞的方式 tcp_socket.bind(('', 7788)) tcp_socket.listen(128) client_socket_list = list() while True: time.sleep(0.5) try: client_socket, client_addr = tcp_socket.accept() except Exception as ret: print("---没有新的客户端到来---") else: print("---来了一个新客户端---") client_socket.setblocking(False) # 设置套接字为非堵塞的方式 client_socket_list.append(client_socket) for client_socket in client_socket_list: try: recv_data = client_socket.recv(1024) except Exception as ret: print("---这个客户端没有发来数据---") else: if recv_data: # 对方发送过来数据 pass else: # 对方调用close,导致了recv返回空值 client_socket_list.remove(client_socket) client_socket.close() print("---客户端已经关闭---") if __name__ == '__main__': main()
同时为三个客户端服务:

gevent就是利用类似的原理实现的并行。
9、长链接和短链接
HTTP1.0使用的是短连接,HTTP1.1使用的是长链接
TCP在真正的读写操作之前,server与client之间必须建立一个连接,当读写操作完成后,双方不再需要这个连接时它们可以释放这个连接,
连接的建立通过三次握手,释放则需要四次握手,所以说每个连接的建立都是需要资源消耗和时间消耗的。
TCP短连接:
client 向 server 发起连接请求
server 接到请求,双方建立连接
client 向 server 发送消息
server 回应 client
一次读写完成,此时双方任何一个都可以发起 close 操作(一般是 client 先发起)
短连接一般只会在 client/server 间传递一次读写操作!

TCP长连接:
client 向 server 发起连接
server 接到请求,双方建立连接
client 向 server 发送消息
server 回应 client
一次读写完成,连接不关闭
后续读写操作...
长时间操作结束之后client发起关闭请求

长连接可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户来说,较适用长连接。
client与server之间的连接如果一直不关闭的话,会存在一个问题,
随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,
如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致server端服务受损;
如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个蛋疼的客户端连累后端服务。
短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。但如果客户请求频繁,将在TCP的建立和关闭操作上浪费时间和带宽。
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。
每个TCP连接都需要三次握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,
所以每个操作完后都不断开,再次处理时直接发送数据包就OK了,不用建立TCP连接。
如数据库的连接用长连接,如果用短连接频繁的通信会造成socket错误,而且频繁的socket创建也是对资源的浪费。
WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,
如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那后果可想而知。所以并发量大,但每个用户无需频繁操作情况下需用短连好。
10、单进程、单线程、非堵塞、长链接的HTTP服务器
import socket import re def service(client_socket, request): request_list = request.splitlines() ret = re.match(r"[^/]+(/[^ ]*)", request_list[0]) file_name = "" if ret: file_name = ret.group(1) if file_name == "/": file_name = "/index.html" try: f = open("./html" + file_name, 'rb') except: response = "HTTP/1.1 404 NOT FOUND\r\n" response += "\r\n" response += "---404 not found---" client_socket.send(response.encode('utf-8')) else: html_content = f.read() f.close() response = "HTTP/1.1 200 ok\r\n" # 告诉浏览器数据长度,浏览器接收完数据会主动发送下一次请求 response += "Content-Length:%d" % len(html_content) response += "\r\n" client_socket.send(response.encode('utf-8')) client_socket.send(html_content) def main(): tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_socket.bind(('', 7788)) tcp_socket.listen(128) tcp_socket.setblocking(False) client_socket_list = list() while True: try: client_socket, client_addr = tcp_socket.accept() except Exception as ret: pass else: client_socket.setblocking(False) client_socket_list.append(client_socket) for client_socket in client_socket_list: try: recv_content = client_socket.recv(1024).decode('utf-8') except Exception as ret: pass else: if recv_content: service(client_socket, recv_content) else: # 不在service中关闭,而是在接收到的数据为空时再关闭,实现长连接 client_socket_list.remove(client_socket) client_socket.close() tcp_socket.close() if __name__ == "__main__": main()
11、epoll
nginx、apache服务器使用的都是epoll实现
非堵塞实现:绿色为列表,黄色为client_socket,应用程序来检测哪个socket可以收数据,socket要copy到kernel中运行

epoll实现:绿色为操作系统内核与应用程序共用的空间,让操作系统来监测套接字的文件描述符,提高了执行效率
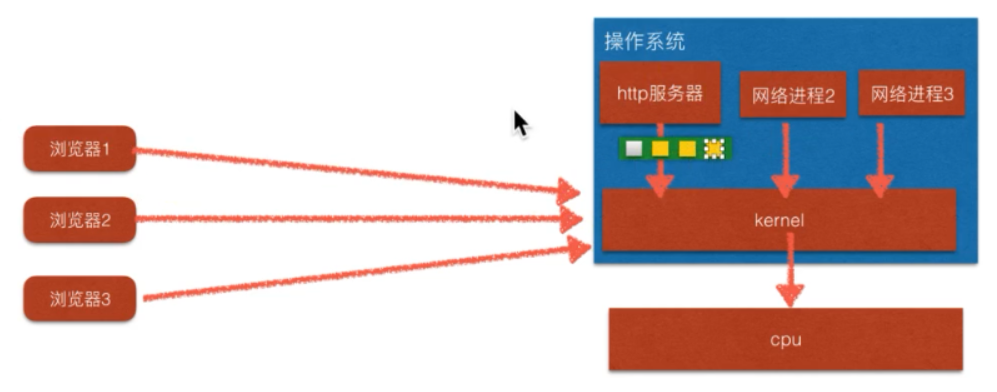
epoll采用事件通知的方式(哪个套接字有数据处理哪个),而不是轮询的方式(遍历列表)
通过共享内存和时间通知,保证了epoll的高效率。
epoll在Linux中的实现过程:
https://blog.csdn.net/xiajun07061225/article/details/9250579
(1)使用了内存映射(mmap)技术
(2)采用基于事件的就绪通知方式
I/O 多路复用的特点:
通过一种机制使一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,epoll()函数就可以返回。 所以, IO多路复用,本质上不会有并发的功能,因为任何时候还是只有一个进程或线程进行工作,它之所以能提高效率是因为select\epoll 把进来的socket放到他们的 '监视' 列表里面,当任何socket有可读可写数据立马处理,那如果select\epoll 手里同时检测着很多socket, 一有动静马上返回给进程处理,总比一个一个socket过来,阻塞等待,处理高效率。
当然也可以多线程/多进程方式,一个连接过来开一个进程/线程处理,这样消耗的内存和进程切换页会耗掉更多的系统资源。 所以我们可以结合IO多路复用和多进程/多线程 来高性能并发,IO复用负责提高接受socket的通知效率,收到请求后,交给进程池/线程池来处理逻辑。
import socket import re import select def service(client_socket, request): request_list = request.splitlines() ret = re.match(r"[^/]+(/[^ ]*)", request_list[0]) file_name = "" if ret: file_name = ret.group(1) if file_name == "/": file_name = "/index.html" try: f = open("./html" + file_name, 'rb') except: response = "HTTP/1.1 404 NOT FOUND\r\n" response += "\r\n" response += "---404 not found---" client_socket.send(response.encode('utf-8')) else: html_content = f.read() f.close() response = "HTTP/1.1 200 ok\r\n" # 告诉浏览器数据长度,浏览器接收完数据会主动发送下一次请求 response += "Content-Length:%d\r\n" % len(html_content) response += "\r\n" client_socket.send(response.encode('utf-8')) client_socket.send(html_content) def main(): tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) tcp_socket.bind(('', 7788)) tcp_socket.listen(128) tcp_socket.setblocking(False) # 创建一个epoll对象 epl = select.epoll() # 将监听套接字对应的fd注册到epoll中 # fileno得到套接字对应的文件描述符(fd) # EPOLLIN表示监测套接字是否有输入 epl.register(tcp_socket.fileno(), select.EPOLLIN) # 记录文件描述符对应的套接字对象 fd_event_dict = dict() while True: # poll默认会堵塞,直到os监测到数据到来,通过事件通知方式告诉这个程序,此时才会解堵塞 fd_event_list = epl.poll() # [(fd, event), (套接字对应的文件描述符, 文件描述符对应的事件 例如可以调用recv接收)] for fd, event in fd_event_list: if fd == tcp_socket.fileno(): # tcp_socket收到链接请求 client_socket, client_addr = tcp_socket.accept() # 注册新套接字 epl.register(client_socket.fileno(), select.EPOLLIN) fd_event_dict[client_socket.fileno()] = client_socket elif event == select.EPOLLIN: # 判断已经链接的客户端是否有数据发送过来 recv_content = fd_event_dict[fd].recv(1024).decode('utf-8') if recv_content: service(fd_event_dict[fd], recv_content) else: fd_event_dict[fd].close() # 从共享内存中取出客户socket epl.unregister(fd) # 从字典中删除socket del fd_event_dict[fd] tcp_socket.close() if __name__ == "__main__": main()
三、网络通信过程
1、TCP/IP协议
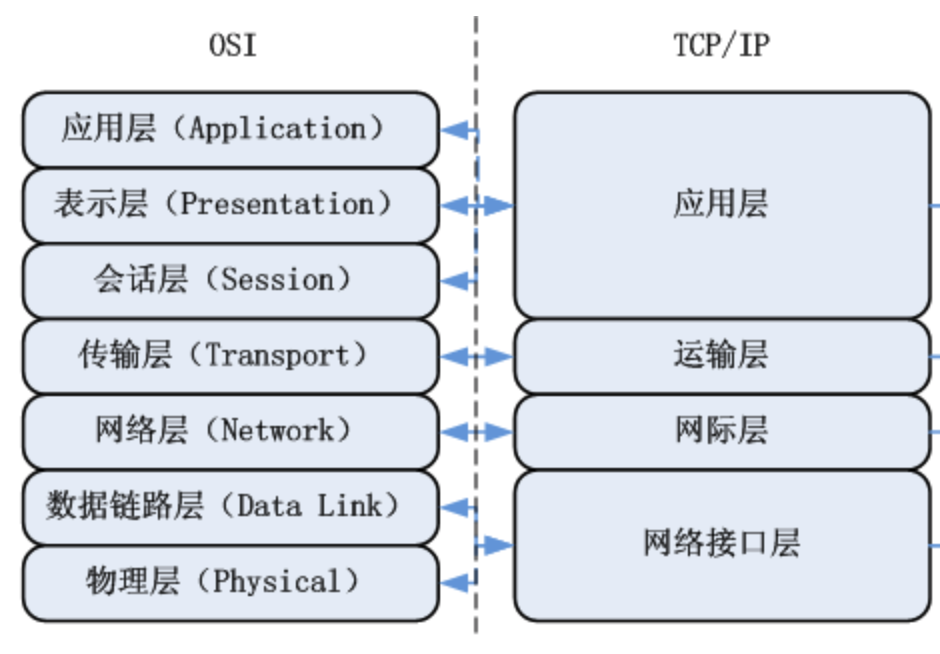
互联网协议包含了上百种协议标准,但是最重要的两个协议是TCP和IP协议,所以,大家把互联网的协议简称TCP/IP协议(族)
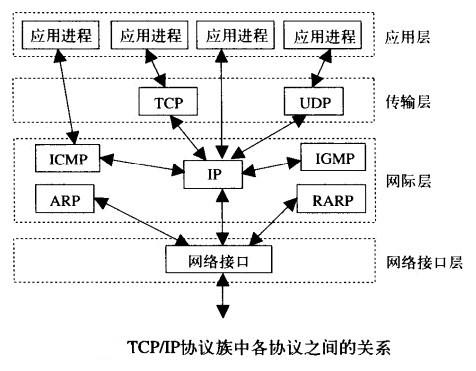
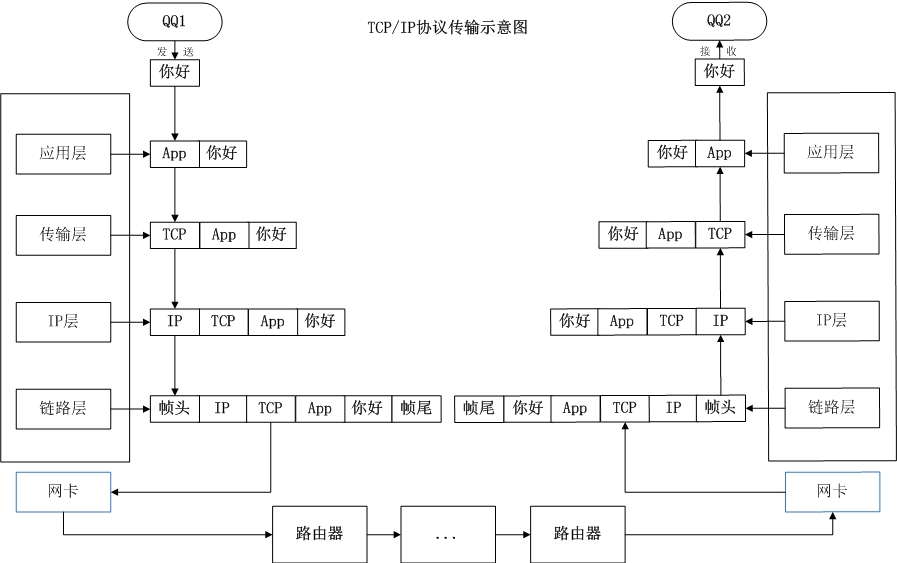
网际层也称为:网络层;网络接口层也称为:链路层
2、wireshark抓包工具
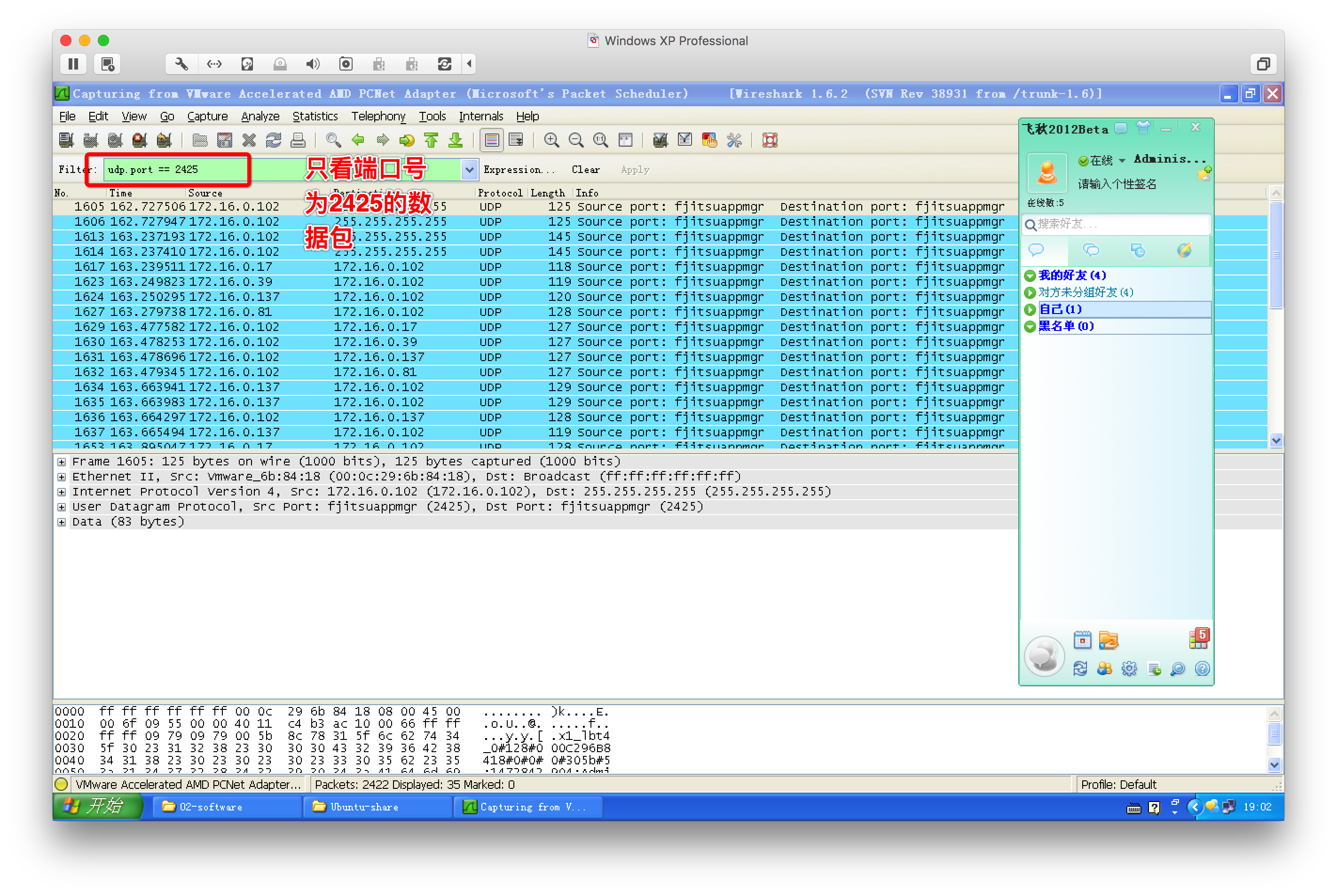
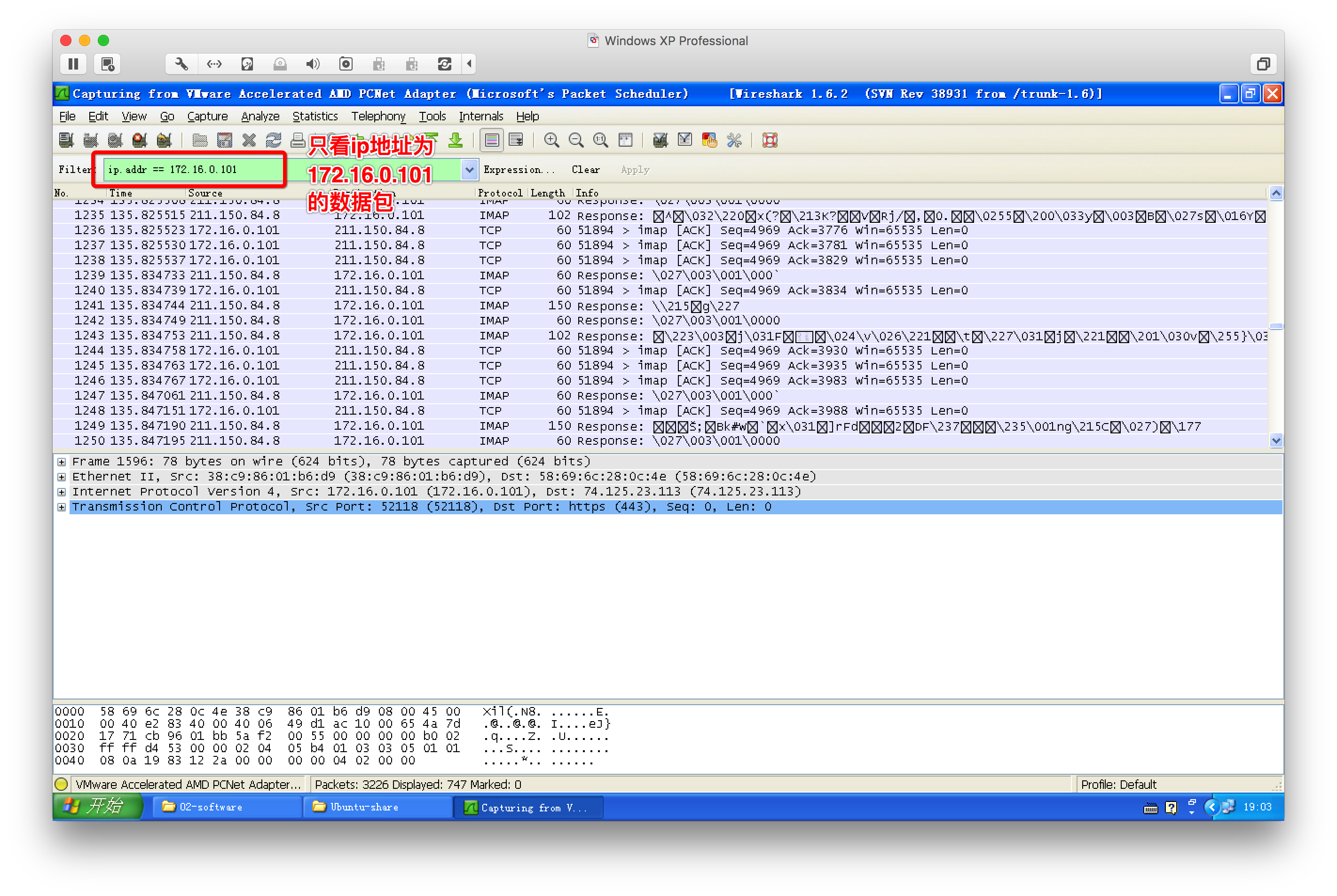
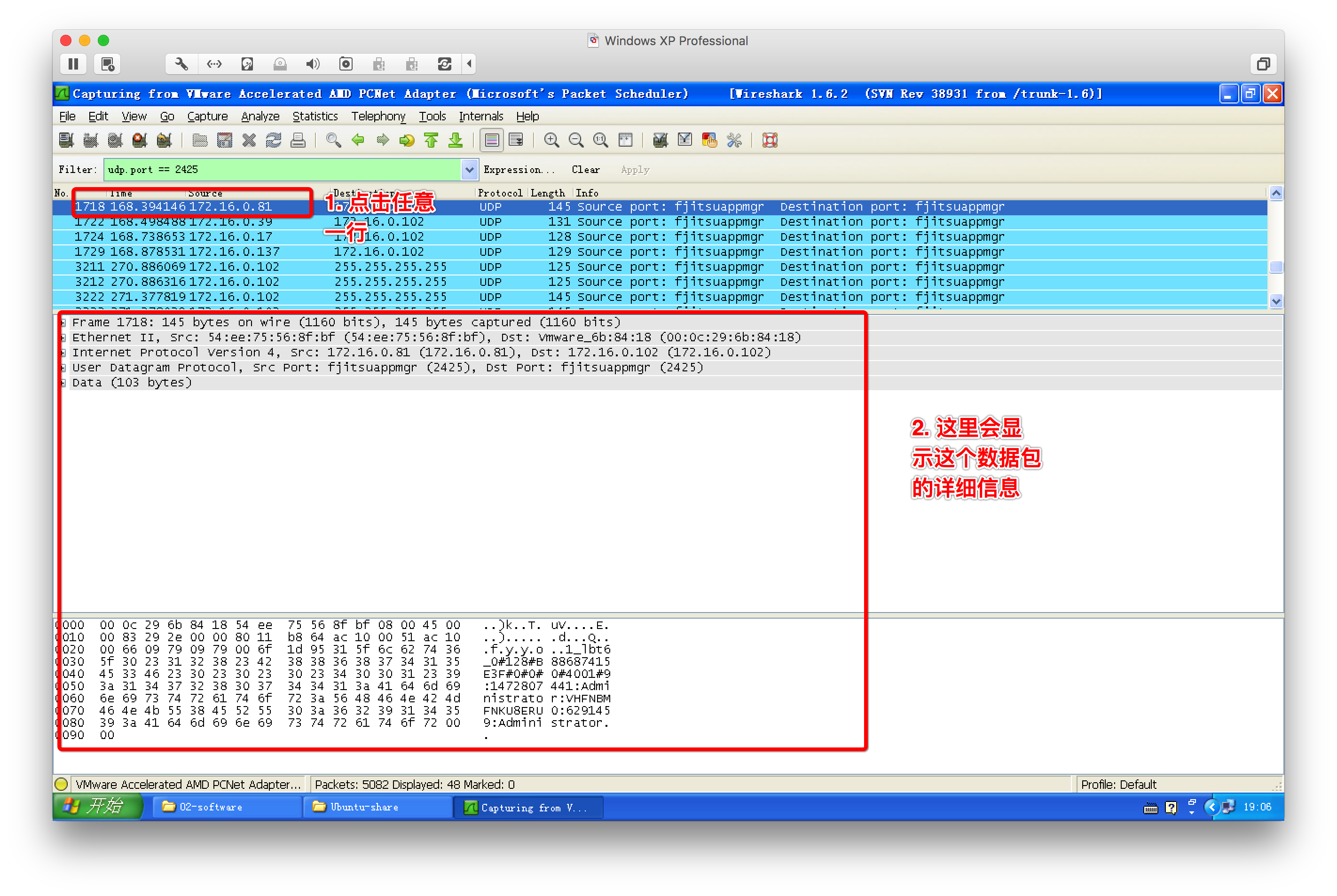
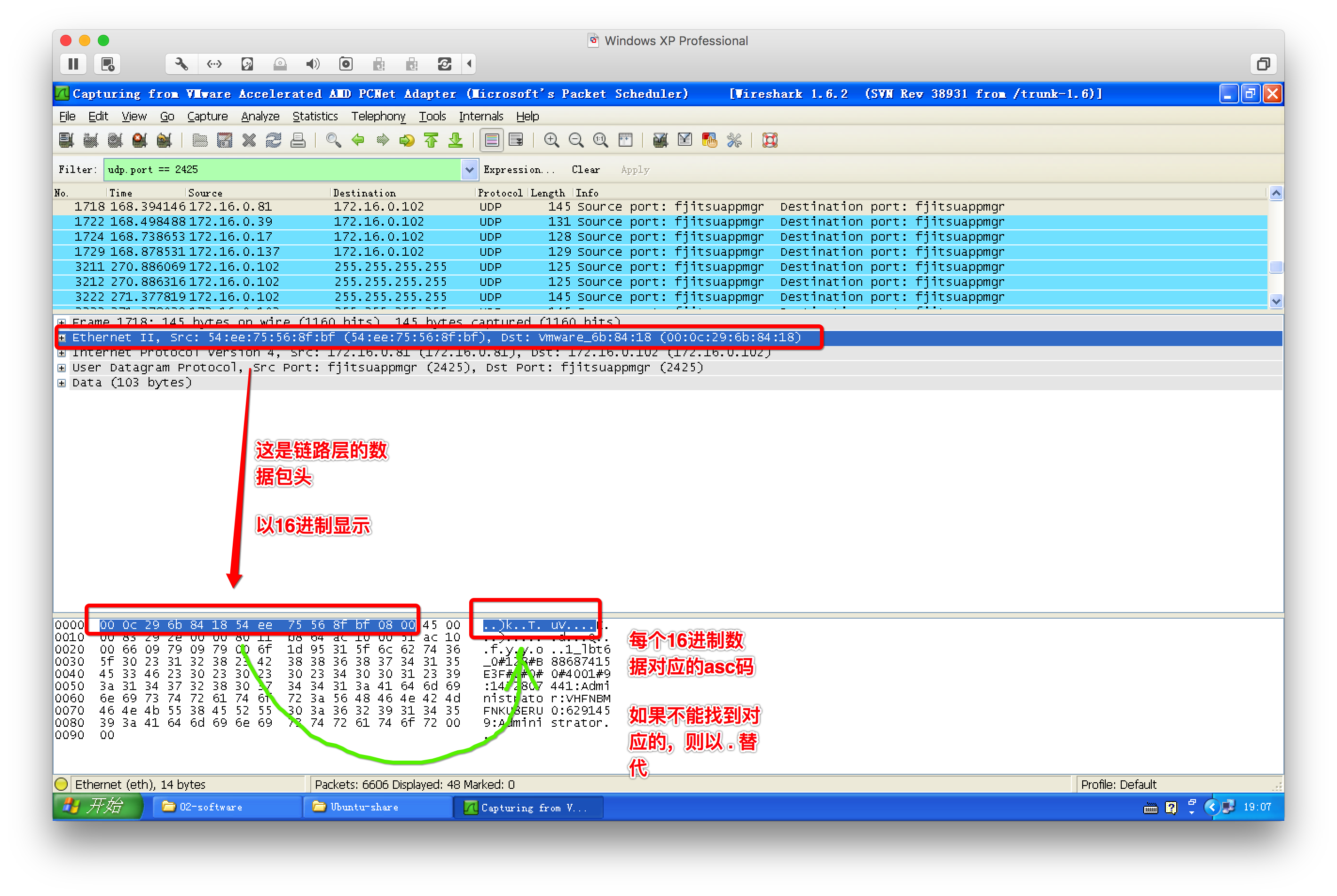
3、网络通信过程
(1)2台电脑的网络
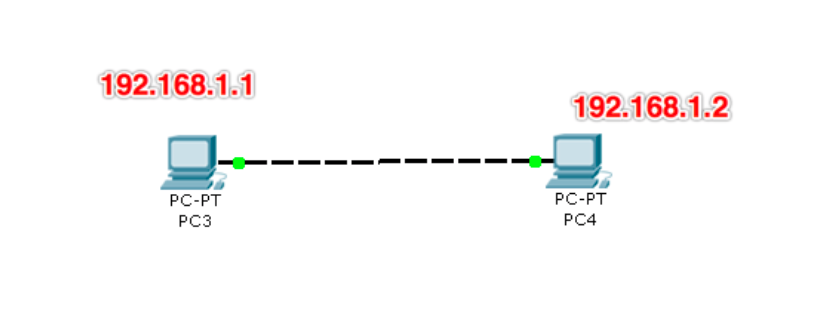
如果两台电脑之间通过网线连接是可以直接通信的,但是需要提前设置好ip地址以及网络掩码
(子网掩码用来确定IP地址中谁是网络号谁是主机号,也就相当于确定IP地址的类型,如255.255.255.0)
(通过子网掩码和IP确定网络号:按位与)

并且ip地址需要控制在同一网段内,例如 一台为192.168.1.1另一台为192.168.1.2则可以进行通信
(2)使用集线器Hub组成一个网络
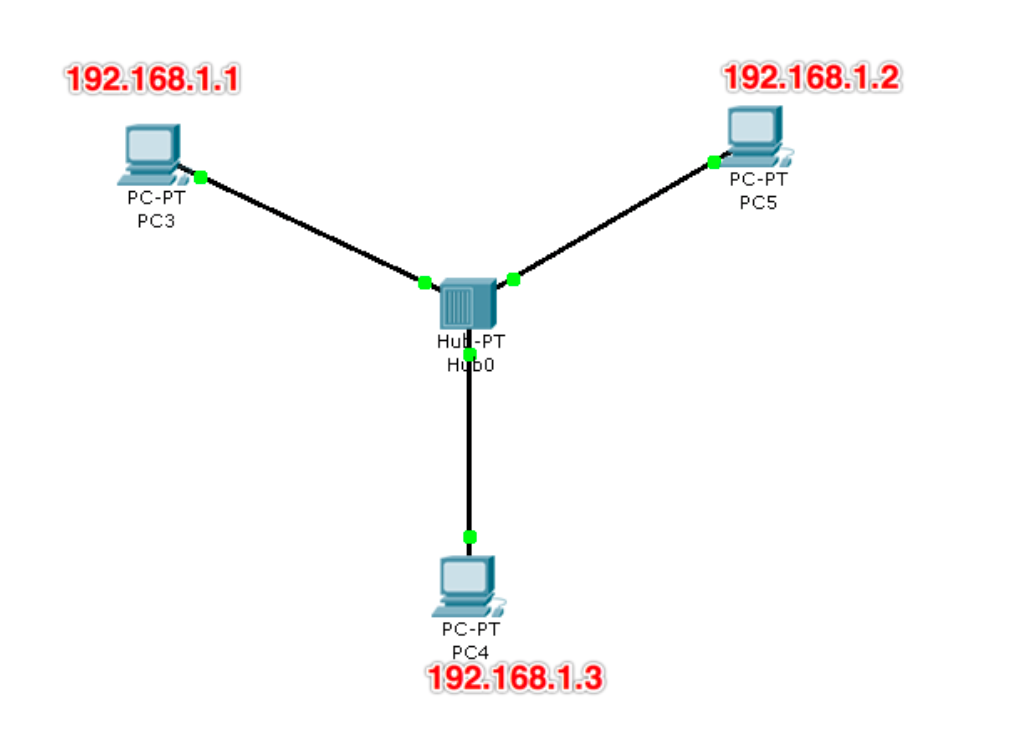
当有多台电脑需要组成一个网时,那么可以通过集线器(Hub)将其链接在一起
一般情况下集线器的接口较少
集线器有个缺点,它以广播的方式进行发送任何数据,即如果集线器接收到来自A电脑的数据本来是想转发给B电脑,如果此时它还连接着另外两台电脑C、D,那么它会把这个数据给每个电脑都发送一份,因此会导致网络拥堵
(3)使用交换机组成一个网络
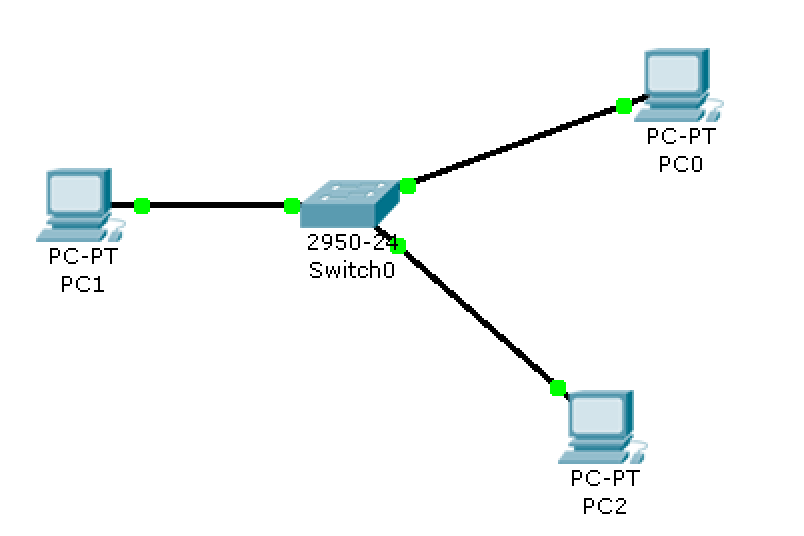
克服了集线器以广播发送数据的缺点,当需要广播的时候发送广播,当需要单播的时候又能够以单播的方式进行发送
它已经替代了之前的集线器
企业中就是用交换机来完成多台电脑设备的链接成网络的
交换机怎么实现单播:
根据ARP协议(arp -a 命令可以查看 电脑中保存的 所有通讯过的IP的MAC地址)通过MAC地址找到网络中的某台机器
Mac地址唯一对应一个网卡
第一次怎么知道对方MAC地址:
所有网卡都有一个通用的MAC地址ff.ff.ff.ff.ff.ff,通过广播,把自己的 MAC地址 和 请求得到对方Mac的信息 发给想要通信的电脑
顺利通过数据链路层的检测后,网络层会拒绝错误的IP
(4)使用路由器连接多个网络
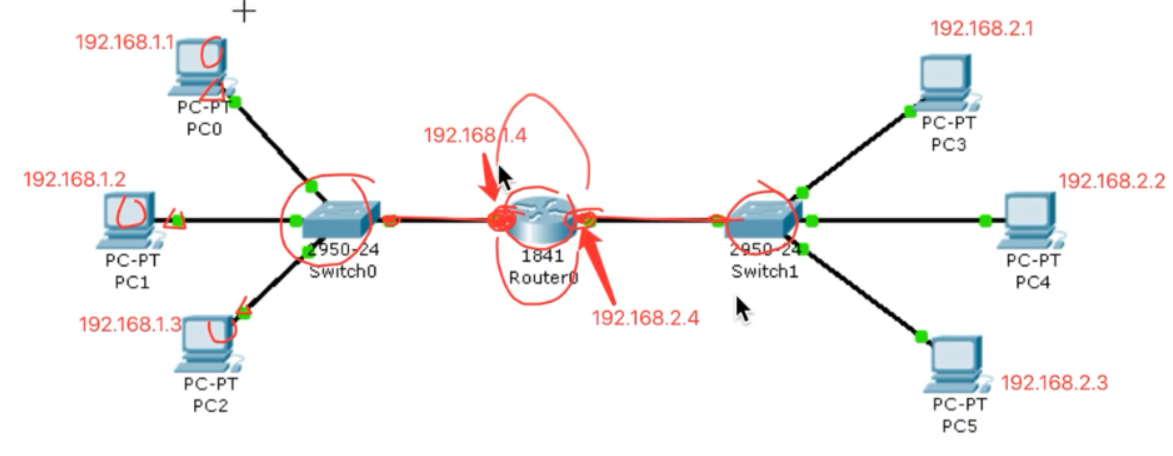
网关:具有转发数据能力的设备(一般是路由器,路由器中至少有两个网卡)
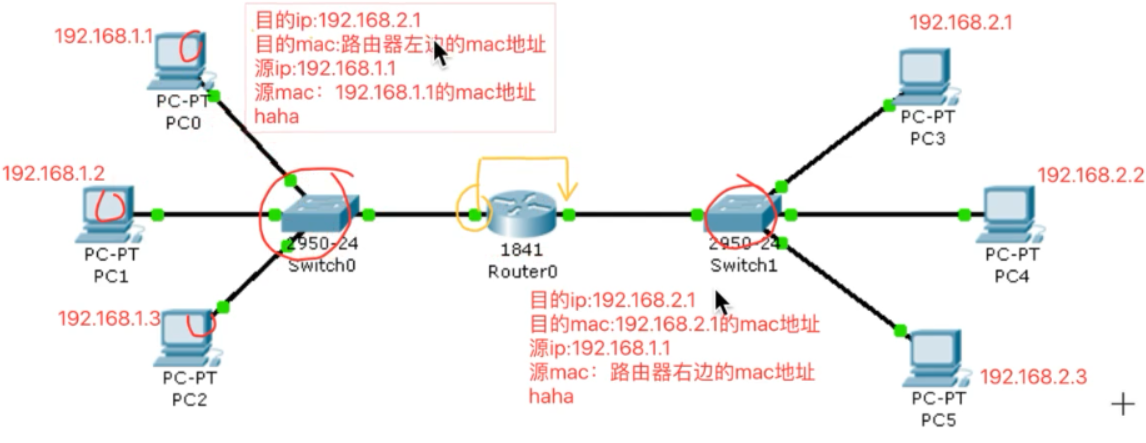
整个传输过程中IP不变,Mac地址一直在变化
(5)网络通信过程
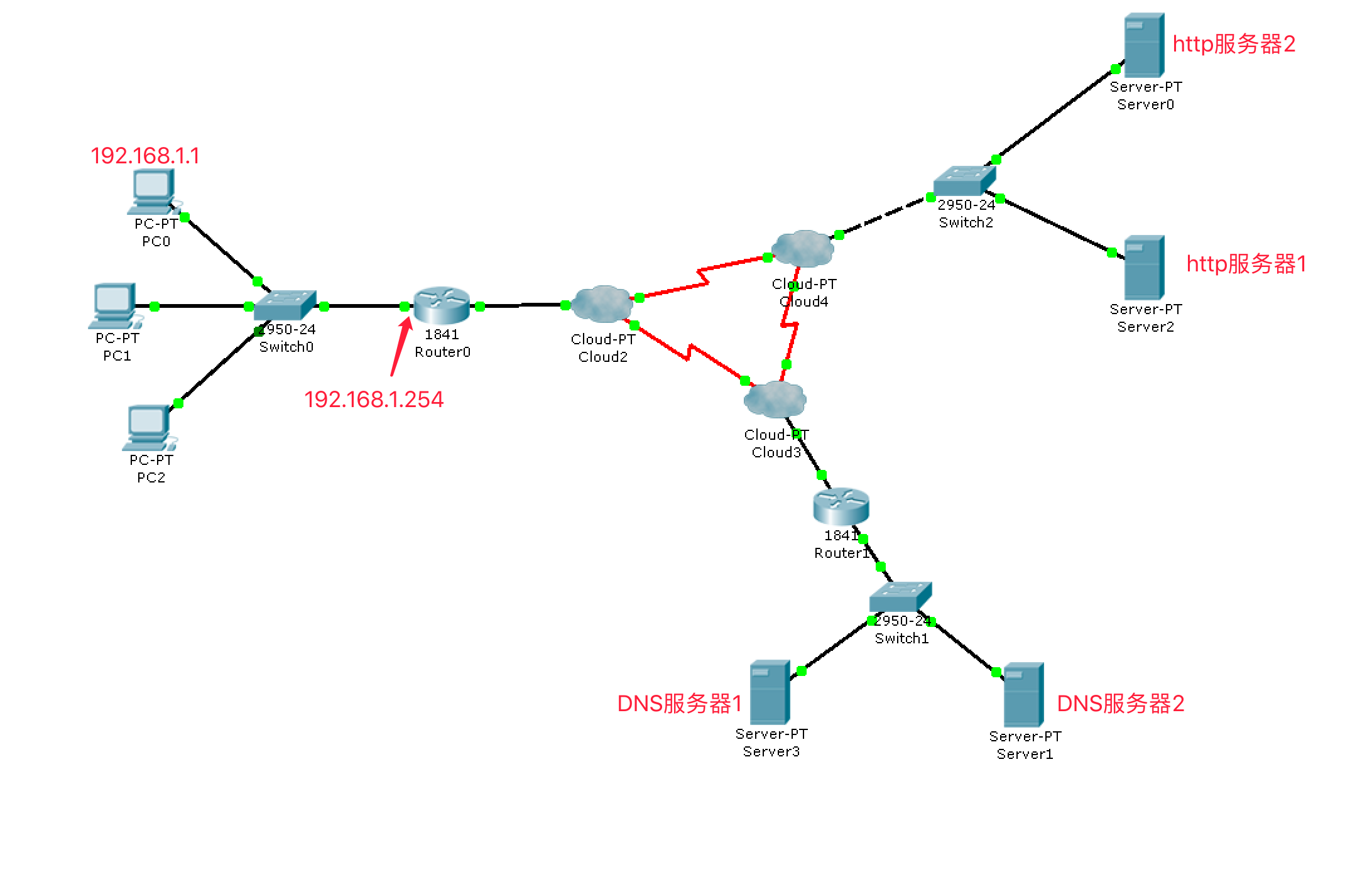
将域名发送给DNS服务器进行解析
向服务器发送TCP三次握手
发送HTTP的请求数据以及等待服务器的应答
发送TCP的四次挥手
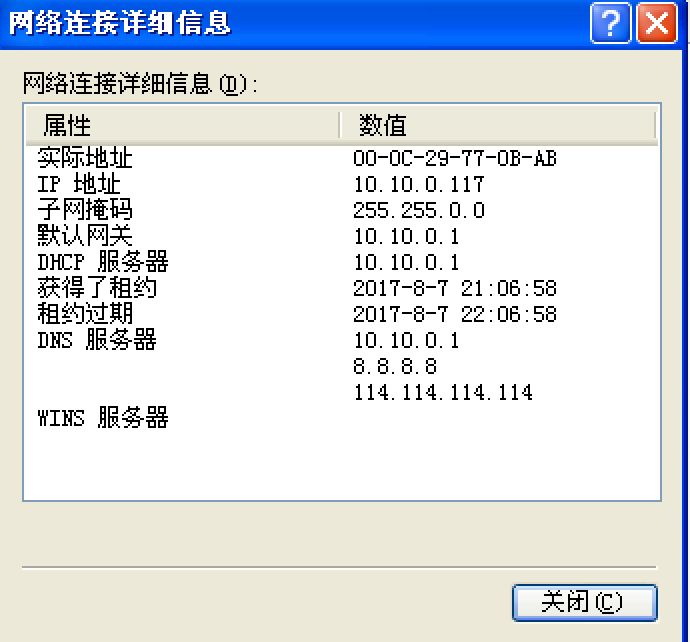
- MAC地址:在设备与设备之间数据通信时用来标记收发双方(网卡的序列号)
- IP地址:在逻辑上标记一台电脑,用来指引数据包的收发方向(相当于电脑的序列号)(实际全球IP已经分配完了)
- 网络掩码:用来区分ip地址的网络号和主机号(IP地址的种类)
- 默认网关:当需要发送的数据包的目的ip不在本网段内时,就会发送给默认的一台电脑,成为网关(一般为路由器的IP)
- 集线器:已过时,用来连接多台电脑,缺点:每次收发数据都进行广播,网络会变的拥堵
- 交换机:集线器的升级版,有学习功能知道需要发送给哪台设备,根据需要进行单播、广播
- 路由器:连接多个不同的网段,让他们之间可以进行收发数据,每次收到数据后,ip不变,但是MAC地址会变化(多台路由器之间根据路由发现协议来通信)
- DNS:用来解析出IP(类似电话簿)
- http服务器:提供浏览器能够访问到的数据
