


一、线程
1、没有多任务的程序
import time def sing(): for i in range(5): print("啊啊啊啊~~%d" % i) time.sleep(1) def dance(): for i in range(5): print("当当当当~~%d" % i) time.sleep(1) def main(): sing() dance() if __name__ == "__main__": main()
并发:指的是任务数多于cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
并行:指的是任务数小于等于cpu核数,即任务真的是一起执行的
2、线程
python的thread模块是比较底层的模块,python的threading模块是对thread做了一些包装的,可以更加方便的被使用
import time import threading def sing(): for i in range(5): print("啊啊啊啊~~%d" % i) time.sleep(1) def dance(): for i in range(5): print("当当当当~~%d" % i) time.sleep(1) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() if __name__ == "__main__": main()
使用了多线程并发的操作,花费时间要短很多
当调用start()时,才会真正的创建线程,并且开始执行
主线程会等待所有的子线程结束后才结束
线程执行顺序是不确定的,可以通过延时的方式保证顺序执行
import threading import time def sing(): for i in range(4): print("啊啊啊啊~~%s" % i) time.sleep(1) def dance(): for i in range(8): print("当当当当~~%s" % i) time.sleep(1) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() while True: time.sleep(1) # 每秒查看一次正在运行的线程 print(threading.enumerate()) if __name__ == '__main__': main()
if len(threading.enumerate()) <= 1: break
3、通过继承Thread类来完成创建线程
import threading import time class MyThread(threading.Thread): def run(self): # 必须有run方法 for i in range(5): time.sleep(1) msg = "i'm " + self.name + " @" + str(i) # name表示当前线程的名字,str()把i转成string类型才能拼接 print(msg) def main(): t = MyThread() t.start() if __name__ == '__main__': main()
4、多线程共享全局变量
所有子线程和主线程共享全局变量
import threading import time g_num = 100 def test1(): global g_num g_num += 1 print("----in test1 g_num = %d ----" % g_num) def test2(): print("----in test2 g_num = %d ----" % g_num) def main(): t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) t1.start() time.sleep(1) t2.start() time.sleep(1) print("----in main g_num = %d ----" % g_num) if __name__ == '__main__': main()
传递参数:列表当做实参传递到线程中
import threading import time def test1(temp): temp.append(33) print("----in test1 temp = %s ----" % str(temp)) def test2(temp): print("----in test2 temp = %s ----" % str(temp)) g_nums = [11, 22] def main(): # target指定这个线程去哪个函数执行代码 # args指定调用函数时传递的数据,单个参数要加逗号 t1 = threading.Thread(target=test1, args=(g_nums,)) t2 = threading.Thread(target=test2, args=(g_nums,)) t1.start() time.sleep(1) t2.start() time.sleep(1) print("----in main g_nums = %s ----" % str(g_nums)) if __name__ == '__main__': main()
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据
缺点就是,线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)
5、资源竞争与同步
import threading import time g_num = 0 def test1(num): global g_num for i in range(num): g_num += 1 print("----in test1 g_num = %d ----" % g_num) def test2(num): global g_num for i in range(num): g_num += 1 print("----in test2 g_num = %d ----" % g_num) def main(): t1 = threading.Thread(target=test1, args=(1000000,)) t2 = threading.Thread(target=test2, args=(1000000,)) t1.start() t2.start() # 等待两个线程执行完毕 time.sleep(5) print("----in main g_num = %d ----" % g_num) if __name__ == '__main__': main()
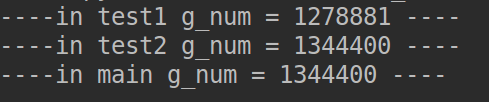
如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确
假设两个线程t1和t2都要对全局变量g_num(默认是0)进行加1运算,t1和t2都各对g_num加10次,g_num的最终的结果应该为20。但是由于是多线程同时操作,有可能出现下面情况:
- 在g_num=0时,t1取得g_num=0。此时系统把t1调度为”sleeping”状态,把t2转换为”running”状态,t2也获得g_num=0
- 然后t2对得到的值进行加1并赋给g_num,使得g_num=1
- 然后系统又把t2调度为”sleeping”,把t1转为”running”。线程t1又把它之前得到的0加1后赋值给g_num。
- 这样导致虽然t1和t2都对g_num加1,但结果仍然是g_num=1
同步的概念:同步就是协同步调,按预定的先后次序进行运行。如:你说完,我再说。
"同"字从字面上容易理解为一起动作。其实不是,"同"字应是指协同、协助、互相配合。
如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B执行,再将结果给A;A再继续操作。
对于刚刚提出的那个计算错误的问题,可以通过线程同步来进行解决,思路如下:
- 系统调用t1,然后获取到g_num的值为0,此时上一把锁,即不允许其他线程操作g_num
- t1对g_num的值进行+1
- t1解锁,此时g_num的值为1,其他的线程就可以使用g_num了,而且是g_num的值不是0而是1
- 同理其他线程在对g_num进行修改时,都要先上锁,处理完后再解锁,在上锁的整个过程中不允许其他线程访问,就保证了数据的正确性
6、互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
threading模块中定义了Lock类,可以方便的处理锁定:
# 创建锁 mutex = threading.Lock() # 锁定 mutex.acquire() # 释放 mutex.release()
- 如果这个锁之前是没有上锁的,那么acquire不会堵塞
- 如果在调用acquire对这个锁上锁之前 它已经被 其他线程上了锁,那么此时acquire会堵塞,直到这个锁被解锁为止
import threading import time g_num = 0 def test1(num): global g_num # 上锁,如果之前没有被上锁,此时上锁成功 # 如果上锁之前已经上过锁,那么此时堵塞,直到这个锁被解开 for i in range(num): mutex.acquire() g_num += 1 mutex.release() print("----in test1 g_num = %d ----" % g_num) def test2(num): global g_num for i in range(num): mutex.acquire() g_num += 1 mutex.release() print("----in test2 g_num = %d ----" % g_num) # 创建一个互斥锁,默认是没有上锁的 mutex = threading.Lock() def main(): t1 = threading.Thread(target=test1, args=(1000000,)) t2 = threading.Thread(target=test2, args=(1000000,)) t1.start() t2.start() time.sleep(3) print("----in main g_num = %d ----" % g_num) if __name__ == '__main__': main()
7、死锁与银行家算法
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
死锁案例:
import threading import time class MyThreadA(threading.Thread): def run(self): mutexA.acquire() print("1 start") time.sleep(1) mutexB.acquire() print("1 end") mutexB.release() mutexA.release() class MyThreadB(threading.Thread): def run(self): mutexB.acquire() print("2 start") time.sleep(1) mutexA.acquire() print("2 end") mutexA.release() mutexB.release() mutexA = threading.Lock() mutexB = threading.Lock() def main(): t1 = MyThreadA() t2 = MyThreadB() t1.start() t2.start() if __name__ == '__main__': main()
银行家算法:
[背景知识]
一个银行家如何将一定数目的资金安全地借给若干个客户,使这些客户既能借到钱完成要干的事,同时银行家又能收回全部资金而不至于破产,这就是银行家问题。这个问题同操作系统中资源分配问题十分相似:银行家就像一个操作系统,客户就像运行的进程,银行家的资金就是系统的资源。
[问题的描述]
一个银行家拥有一定数量的资金,有若干个客户要贷款。每个客户须在一开始就声明他所需贷款的总额。若该客户贷款总额不超过银行家的资金总数,银行家可以接收客户的要求。客户贷款是以每次一个资金单位(如1万RMB等)的方式进行的,客户在借满所需的全部单位款额之前可能会等待,但银行家须保证这种等待是有限的,可完成的。
例如:有三个客户C1,C2,C3,向银行家借款,该银行家的资金总额为10个资金单位,其中C1客户要借9各资金单位,C2客户要借3个资金单位,C3客户要借8个资金单位,总计20个资金单位。某一时刻的状态如图所示。
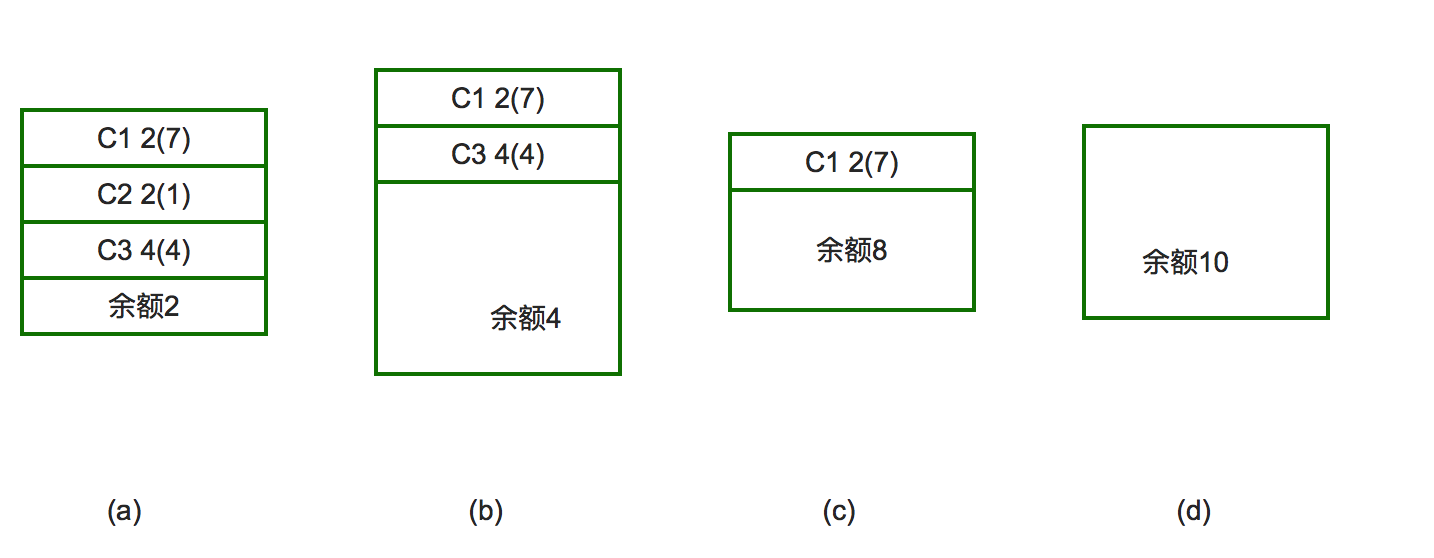
对于a图的状态,按照安全序列的要求,我们选的第一个客户应满足该客户所需的贷款小于等于银行家当前所剩余的钱款,可以看出只有C2客户能被满足:C2客户需1个资金单位,小银行家手中的2个资金单位,于是银行家把1个资金单位借给C2客户,使之完成工作并归还所借的3个资金单位的钱,进入b图。同理,银行家把4个资金单位借给C3客户,使其完成工作,在c图中,只剩一个客户C1,它需7个资金单位,这时银行家有8个资金单位,所以C1也能顺利借到钱并完成工作。最后(见图d)银行家收回全部10个资金单位,保证不赔本。那麽客户序列{C1,C2,C3}就是个安全序列,按照这个序列贷款,银行家才是安全的。否则的话,若在图b状态时,银行家把手中的4个资金单位借给了C1,则出现不安全状态:这时C1,C3均不能完成工作,而银行家手中又没有钱了,系统陷入僵持局面,银行家也不能收回投资。
综上所述,银行家算法是从当前状态出发,逐个按安全序列检查各客户谁能完成其工作,然后假定其完成工作且归还全部贷款,再进而检查下一个能完成工作的客户,......。如果所有客户都能完成工作,则找到一个安全序列,银行家才是安全的。
此外,还可以通过 添加超时时间 的方法解决死锁
8、udp聊天器(多线程版)
import socket import threading def receive(udp_socket): while True: recv_data = udp_socket.recvfrom(1024) print(recv_data[0].decode('gbk')) def send(udp_socket): while True: send_data = input() udp_socket.sendto(send_data.encode('gbk'), ('192.168.0.105', 8080)) def main(): udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) udp_socket.bind(('', 9876)) recv_thread = threading.Thread(target=receive, args=(udp_socket, )) send_thread = threading.Thread(target=send, args=(udp_socket, )) recv_thread.start() send_thread.start() if __name__ == '__main__': main()
不能写udp_socket.close() 否则随着主进程的执行会关闭套接字,出现错误
二、进程
1、进程及状态
程序:例如xxx.py这是程序,是一个静态的
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
不仅可以通过线程完成多任务,进程也是可以的
工作中,任务数往往大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致了有了不同的状态
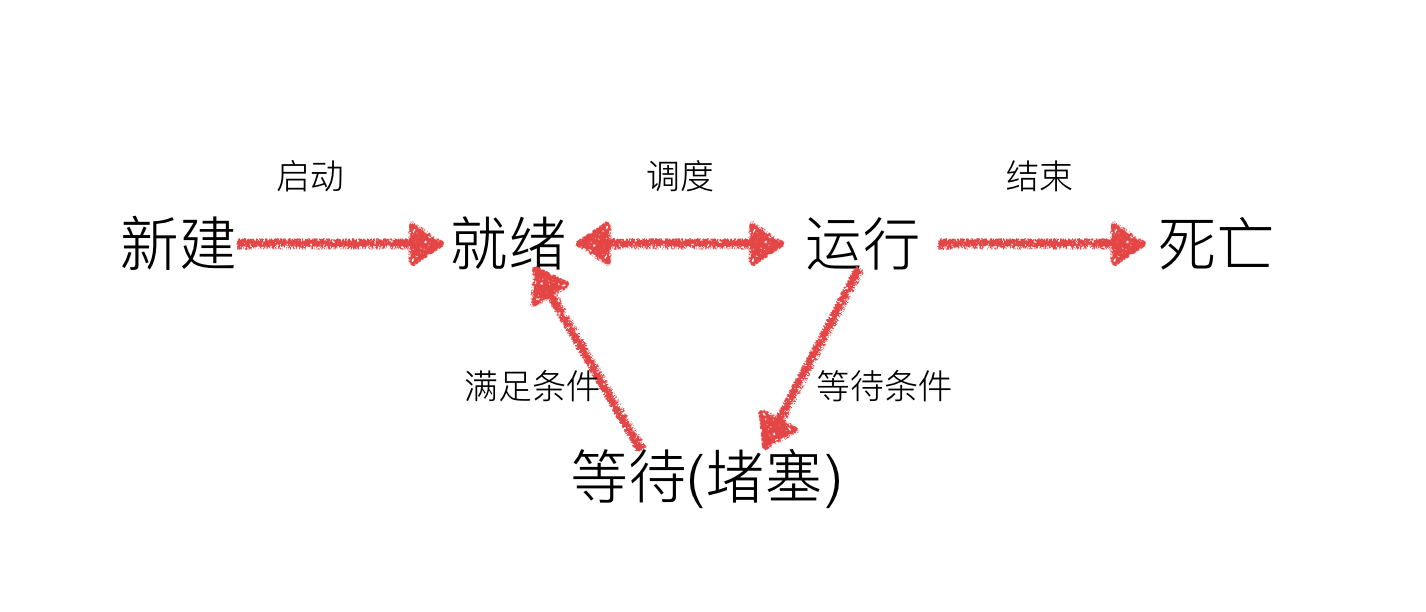
就绪态:运行的条件都已经满足,正在等在cpu执行
执行态:cpu正在执行其功能
等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
2、进程的创建
multiprocessing模块就是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情
import multiprocessing import time def test1(): for i in range(5): print("t1:%d" % i) time.sleep(1) def test2(): for i in range(5): print("t2:%d" % i) time.sleep(1) def main(): p1 = multiprocessing.Process(target=test1) p2 = multiprocessing.Process(target=test2) p1.start() p2.start() if __name__ == '__main__': main()
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动
Process语法结构:
Process([group [, target [, name [, args [, kwargs]]]]])
- target:如果传递了函数的引用,可以任务这个子进程就执行这里的代码
- args:给target指定的函数传递的参数,以元组的方式传递
- kwargs:给target指定的函数传递命名参数
- name:给进程设定一个名字,可以不设定
- group:指定进程组,大多数情况下用不到
Process创建的实例对象的常用方法:
- start():启动子进程实例(创建子进程)
- is_alive():判断进程子进程是否还在活着
- join([timeout]):是否等待子进程执行结束,或等待多少秒
- terminate():不管任务是否完成,立即终止子进程
Process创建的实例对象的常用属性:
- name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
- pid:当前进程的pid(进程号)
注意:
每个进程都会占用一份资源
进程间不共享全局变量
3、线程与进程对比
进程,能够完成多任务,比如 在一台电脑上能够同时运行多个QQ
线程,能够完成多任务,比如 一个QQ中的多个聊天窗口
进程是系统进行资源分配和调度的一个独立单位.
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
一个程序至少有一个进程,一个进程至少有一个线程.
线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
线程不能够独立执行,必须依存在进程中
可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
4、进程间通信 Queue
可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue是一个消息列队程序
import multiprocessing q = multiprocessing.Queue(3) # 最多接收三条put消息 q.put("1") q.put(2) # 队列已满会堵塞 q.put_nowait([3, 4]) # 队列已满就会报错 print(q.full()) # 判断消息队列是否已满 q.get() q.get() print(q.qsize()) # 返回当前队列包含的消息数量 q.get() print(q.empty()) # 判断是否为空
import multiprocessing import time def download(q): """从网上下载数据""" data = [11, 22, 33] for temp in data: q.put(temp) time.sleep(1) print("下载器已经下完数据并存入队列中") def analyse(q): """分析数据""" while True: temp = q.get() print(temp) if q.empty(): break def main(): # 创建一个队列 q = multiprocessing.Queue(3) p1 = multiprocessing.Process(target=download, args=(q, )) p2 = multiprocessing.Process(target=analyse, args=(q, )) p1.start() p1.join() # 等待子进程结束 p2.start() if __name__ == '__main__': main()
5、进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务,请看下面的实例:
from multiprocessing import Pool import os import time import random def worker(msg): t_start = time.time() print("%s开始执行,进程号为%d" % (msg,os.getpid())) # random.random()随机生成0~1之间的浮点数 time.sleep(random.random()*2) t_stop = time.time() print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start)) po = Pool(3) # 定义一个进程池,最大进程数3 for i in range(0,10): # Pool().apply_async(要调用的目标,(传递给目标的参数元祖,)) # 每次循环将会用空闲出来的子进程去调用目标 po.apply_async(worker,(i,)) print("----start----") po.close() # 关闭进程池,关闭后po不再接收新的请求 po.join() # 等待po中所有子进程执行完成,必须放在close语句之后 print("-----end-----")
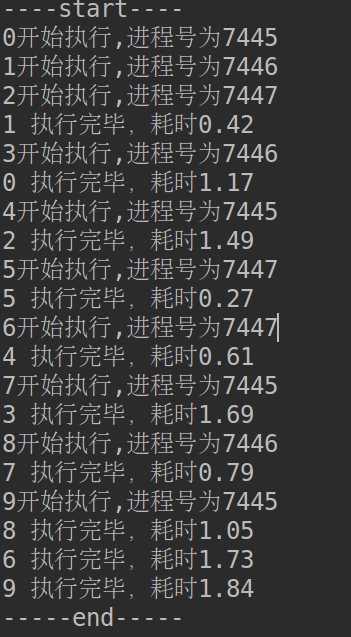
6、文件夹copy器(多进程版)
import os import multiprocessing def copy_file(file_name, old_folder_name, new_folder_name): """完成文件的拷贝""" print("拷贝文件:从%s到%s 文件名是%s" % (old_folder_name, new_folder_name, file_name)) old_f = open(old_folder_name + '/' + file_name, 'rb') new_f = open(new_folder_name + '/' + file_name, 'wb') content = old_f.read() new_f.write(content) old_f.close() new_f.close() def main(): # 1.输入文件夹名字 old_folder_name = input("请输入要拷贝的文件夹名:") # 2.创建一个新文件夹 try: new_folder_name = old_folder_name + "[副本]" os.mkdir(new_folder_name) except: pass # 3.获取文件夹中所有文件名 listdir() file_names = os.listdir(old_folder_name) print(file_names) # 4.创建进程池 po = multiprocessing.Pool(5) # 5.向进程池中添加拷贝文件的任务 for file_name in file_names: po.apply_async(copy_file, args=(file_name, old_folder_name, new_folder_name)) po.close() po.join() if __name__ == '__main__': main()
显示进度条:
使用Manager().Queue()方法
import os import multiprocessing def copy_file(queue, file_name, old_folder_name, new_folder_name): """完成文件的拷贝""" # print("拷贝文件:从%s到%s 文件名是%s" % (old_folder_name, new_folder_name, file_name)) old_f = open(old_folder_name + '/' + file_name, 'rb') new_f = open(new_folder_name + '/' + file_name, 'wb') content = old_f.read() new_f.write(content) old_f.close() new_f.close() # 如果拷贝完文件,就向队列中写入一个消息 queue.put(file_name) def main(): # 1.输入文件夹名字 old_folder_name = input("请输入要拷贝的文件夹名:") # 2.创建一个新文件夹 try: new_folder_name = old_folder_name + "[副本]" os.mkdir(new_folder_name) except: pass # 3.获取文件夹中所有文件名 listdir() file_names = os.listdir(old_folder_name) print(file_names) # 4.创建进程池 po = multiprocessing.Pool(5) # 5.创建队列 queue = multiprocessing.Manager().Queue() # 6.向进程池中添加拷贝文件的任务 for file_name in file_names: po.apply_async(copy_file, args=(queue, file_name, old_folder_name, new_folder_name)) po.close() # po.join() file_num = len(file_names) copy_finish_num = 0 while True: file_name = queue.get() copy_finish_num += 1 # print("拷贝完成:%s" % file_name) # \r在Linux中表示返回到当行的最开始位置 # 视觉上只打印一行,且百分比不断变化 print("\r拷贝的进度为: %.2f %%" % (copy_finish_num*100/file_num), end="") # 拷贝成功的文件数>=总文件数,退出循环 if copy_finish_num >= file_num: break # 最后再打印一个换行 print("") if __name__ == '__main__': main()
三、协程
1、迭代器
迭代是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
迭代器只能往前不会后退。
我们已经知道可以对list、tuple、str等类型的数据使用for...in...的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫迭代。
我们把可以通过for...in...这类语句迭代读取一条数据供我们使用的对象称之为可迭代对象(Iterable)
我们可以通过iter()函数获取这些可迭代对象的迭代器。然后我们可以对获取到的迭代器不断使用next()函数来获取下一条数据。
iter()函数实际上就是调用了可迭代对象的__iter__方法。
int不是iterable:
In [1]: for i in 100: ...: print(i) ...: --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-1-cd23493a453a> in <module>() ----> 1 for i in 100: 2 print(i) 3 TypeError: 'int' object is not iterable
可以使用 isinstance() 判断一个对象是否是 Iterable 对象:
In [1]: from collections import Iterable In [2]: isinstance([11,22,33], Iterable) Out[2]: True In [3]: isinstance("yrtieow", Iterable) Out[3]: True In [4]: isinstance(123, Iterable) Out[4]: False

有__iter__方法,就是可迭代对象
__iter__返回一个迭代器
from collections import Iterable from collections import Iterator class Classmate(object): def __init__(self): self.names = list() def add(self, name): self.names.append(name) def __iter__(self): """想要一个对象成为Iterable,必须实现iter方法""" return ClassIterable(self) class ClassIterable(object): def __init__(self, obj): self.obj = obj self.current_num = 0 def __iter__(self): pass def __next__(self): # for循环次数应当等于列表元素个数 if self.current_num < len(self.obj.names): ret = self.obj.names[self.current_num] # 每次for循环下标加1 self.current_num += 1 return ret else: # 结束for循环 raise StopIteration cm = Classmate() cm.add("yy") cm.add("pp") cm.add("cc") print("判断cm是否是可迭代的对象:", isinstance(cm, Iterable)) cm_iterator = iter(cm) print("判断iter返回值是否是迭代器:", isinstance(cm_iterator, Iterator)) for name in cm: print(name)
改进:
class Classmate(object): def __init__(self): self.names = list() self.current_num = 0 def add(self, name): self.names.append(name) def __iter__(self): return self def __next__(self): if self.current_num < len(self.names): ret = self.names[self.current_num] self.current_num += 1 return ret else: # 结束for循环 raise StopIteration cm = Classmate() cm.add("11") cm.add("22") cm.add("33") # 1.判断是否是可迭代对象(有__iter__方法) # 2.__iter__返回迭代器对象 # 3.迭代器调用__next__方法 for name in cm: print(name)
迭代器应用:
我们发现迭代器最核心的功能就是可以通过next()函数的调用来返回下一个数据值。如果每次返回的数据值不是在一个已有的数据集合中读取的,而是通过程序按照一定的规律计算生成的,那么也就意味着可以不用再依赖一个已有的数据集合,也就是说不用再将所有要迭代的数据都一次性缓存下来供后续依次读取,这样可以节省大量的存储(内存)空间。
如range(10)函数在Python2中返回 [1,2,3,4,5,6,7,8,9,10],而在Python2中的xrange()与Python3中的range(),在需要时才会分配空间。
用列表存储的方式遍历斐波那契数列:
nums = list() i = 0 j = 1 n = 0 while n < 10: nums.append(i) i, j = j, i+j n += 1 print(nums)
用迭代器遍历迭代斐波那契数列的前n个数:
class Fibonacci(object): def __init__(self, n): self.i = 0 self.j = 1 self.n = n self.fin_num = 0 def __iter__(self): return self def __next__(self): if self.fin_num < self.n: ret = self.i self.i, self.j = self.j, (self.i+self.j) self.fin_num += 1 return ret else: raise StopIteration f = Fibonacci(10) for num in f: print(num)
除了for循环,在类型转换时也会用到迭代器:
In [5]: a = [11,22,33] In [6]: tuple(a) Out[6]: (11, 22, 33)
2、生成器
利用迭代器,我们可以在每次迭代获取数据(通过next()方法)时按照特定的规律进行生成。
但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。
为了达到记录当前状态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器(generator)。
生成器是一类特殊的迭代器。
要创建一个生成器,有很多种方法。第一种方法很简单,只要把一个列表生成式的 [ ] 改成 ( )
[]返回的是生成的数据,而()返回的是生成数据的方式
对于生成器,我们可以按照迭代器的使用方法来使用,即可以通过next()函数、for循环、list()等方法使用。
In [2]: nums = [i for i in range(10)] In [3]: nums Out[3]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] In [5]: nums = [i*2 for i in range(10)] In [6]: nums Out[6]: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
In [7]: nums = (i*2 for i in range(10)) In [8]: nums Out[8]: <generator object <genexpr> at 0x7f23a48c8a40> In [9]: for num in nums: ...: print(num) ...: 0 2 4 6 8 10 12 14 16 18
In [13]: iter(nums) Out[13]: <generator object <genexpr> at 0x7f23a48c8a40> In [14]: nums = (i*2 for i in range(10)) In [15]: next(nums) Out[15]: 0 In [16]: iter(nums) Out[16]: <generator object <genexpr> at 0x7f23a406b1a8> In [17]: next(nums) Out[17]: 2
3、创建生成器
通过函数生成斐波那契数列:
def create_num(all_num): a, b = 0, 1 finish_num = 0 while finish_num < all_num: print(a) # 打印输出 a, b = b, (a+b) finish_num += 1 create_num(10)
通过生成器生成斐波那契数列:
def create_num(all_num): a, b = 0, 1 finish_num = 0 while finish_num < all_num: yield a # 如果一个函数中有yield,那么这个函数就成了一个生成器的模板 a, b = b, (a+b) finish_num += 1 # 创建一个生成器对象 obj = create_num(10) # 生成器是一种特殊的迭代器 # yield的值会被返回给i,然后停在yield,等待下一次next for i in obj: print(i)
通过异常判断生成器已结束:
def create_num(n): a, b = 0, 1 current_num = 0 while current_num < n: yield a a, b = b, a+b current_num += 1 return "---ok---" obj = create_num(20) while True: try: ret = next(obj) print(ret) except Exception as ret: print(ret.value) # 打印ok break
通过send唤醒生成器:
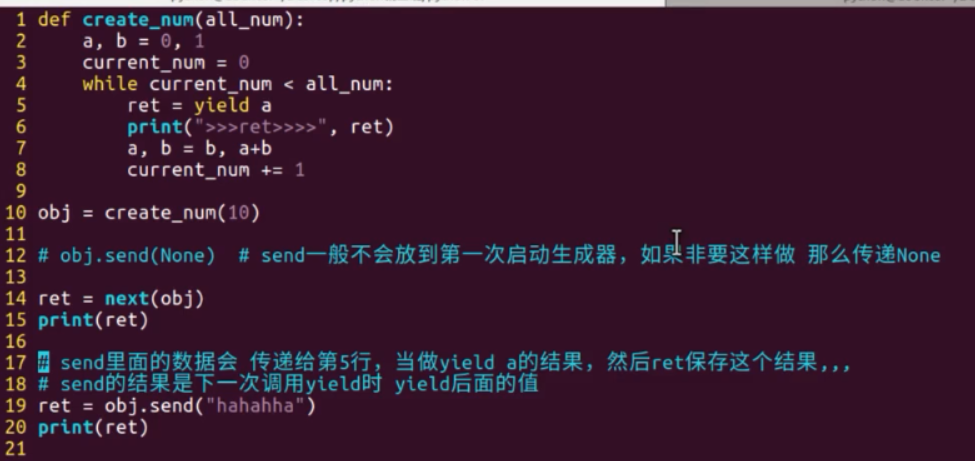
def create_num(n): a, b = 0, 1 current_num = 0 while current_num < n: ret = yield a print(">>>ret:", ret) a, b = b, a+b current_num += 1 return "---ok---" obj = create_num(10) ret = next(obj) print(ret) ret = obj.send(None) print(ret) ret = obj.send("haha") print(ret)
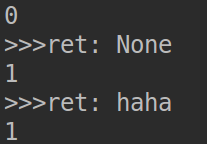
yield的结果传给函数外的ret
send的结果传给循环内的ret
4、使用yield实现多任务
协程,实现并发,效率比线程更高
import time def func1(): while True: print("-----1-----") time.sleep(0.1) yield def func2(): while True: print("-----2-----") time.sleep(0.1) yield def main(): t1 = func1() t2 = func2() while True: next(t1) next(t2) if __name__ == '__main__': main()
协程,又称微线程,纤程。英文名Coroutine。
协程是python中另外一种实现多任务的方式,只不过比线程占用更小执行单元(理解为需要的资源)。 为啥说它是一个执行单元,因为它自带CPU上下文。这样只要在合适的时机, 我们可以把一个协程 切换到另一个协程。 只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的。
通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定
协程和线程差异:
在实现多任务时, 线程切换从系统层面远不止保存和恢复 CPU上下文这么简单。 操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。 所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住
5、使用greenlet、gevent完成多任务
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单(不用一个个手动创建生成器分配任务)
安装greenlet:
sudo pip3 install greenlet
使用greenlet:
import time from greenlet import greenlet def test1(): while True: print("----1----") gl2.switch() time.sleep(0.1) def test2(): while True: print("----2----") gl1.switch() time.sleep(0.1) gl1 = greenlet(test1) gl2 = greenlet(test2) gl1.switch()
greenlet已经实现了协程,但是还需要人工切换比较麻烦,python还提供了一个比greenlet更强大的并且能够自动切换任务的模块gevent。
gevent的原理是当一个greenlet遇到 IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到 IO 操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO
安装gevent:
sudo pip3 install gevent
使用gevent:
import gevent import time def f(n): for i in range(n): print(gevent.getcurrent(), i) # 协程的意义就是利用等待的时间来进行其他操作 # time.sleep(0.5) 但是所有的延时操作都要使用gevent提供的 gevent.sleep(0.5) g1 = gevent.spawn(f, 5) g2 = gevent.spawn(f, 5) g3 = gevent.spawn(f, 5) g1.join() g2.join() g3.join()
使用monkey给程序打补丁:
import gevent import time from gevent import monkey # 有耗时操作时需要,将程序中用到的耗时操作的代码,换为gevent中自己实现的模块 monkey.patch_all() def f1(n): for i in range(n): print(gevent.getcurrent(), i) time.sleep(0.5) def f2(n): for i in range(n): print(gevent.getcurrent(), i) time.sleep(0.5) def f3(n): for i in range(n): print(gevent.getcurrent(), i) time.sleep(0.5) g1 = gevent.spawn(f1, 5) g2 = gevent.spawn(f2, 5) g3 = gevent.spawn(f3, 5) g1.join() g2.join() g3.join()
简化join:这个是最常用的写法
import gevent import time from gevent import monkey monkey.patch_all() def f(n): for i in range(n): print(gevent.getcurrent(), i) time.sleep(0.5) gevent.joinall([ gevent.spawn(f, 5), gevent.spawn(f, 5), gevent.spawn(f, 5), ])
6、并发下载器
urllib.request的使用:
In [1]: import urllib.request In [2]: urllib.request.urlopen("http://www.baidu.com") Out[2]: <http.client.HTTPResponse at 0x7fd1655ac1d0> In [3]: req = urllib.request.urlopen("http://www.baidu.com") In [4]: req.read()
图片下载器:
import urllib.request def main(): req = urllib.request.urlopen("https://t1.huanqiucdn.cn/5bd3e0af959ff4995130cc40f0f28694.jpg") img_content = req.read() with open("1.jpg", "wb") as f: f.write(img_content) if __name__ == "__main__": main()
并发的图片下载器:
import urllib.request import gevent from gevent import monkey monkey.patch_all() def downloader(img_name, img_url): req = urllib.request.urlopen(img_url) img_content = req.read() with open(img_name, "wb") as f: f.write(img_content) def main(): gevent.joinall([ gevent.spawn(downloader, "1.jpg", "https://t1.huanqiucdn.cn/5bd3e0af959ff4995130cc40f0f28694.jpg"), gevent.spawn(downloader, "2.jpg", "https://t1.huanqiucdn.cn/5e6c8634e7100fa1702b4cf28180a629.jpg"), ]) if __name__ == "__main__": main()
7、进程、线程、协程对比
进程是资源分配的单位
线程是操作系统调度的单位
进程切换需要的资源很最大,效率很低
线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
协程切换任务资源很小,效率高
多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发
