
机器学习(二)
LSTM#
严格的来说,LSTM只能理解输入的实数,一种将符号转化为数字的方法是基于每个符号出现的频率为其分配一个对应的整数,例如,有112个不同的符号,就建立 [「,」: 0 ] [「the」: 1 ], …, [「council」: 37 ],…,[「spoke」= 111 ]的词典,而为了解码LSTM的输出,同时也生成了逆序字典。
类似的,预测值也是一个唯一的整数值与逆序字典中预测符号的索引相对应例如,如果预测值是37,预测符号便是council。输出的生成看起来似乎简单,但实际上LSTM为下一个符号生成了一个含有112个元素的预测概率分量,并用Softmax()函数归一化,有着最高概率的元素便是逆序字典中预测符号的索引值(例如一个One-hot向量)。
反向传播算法#
反向传播算法实现了一个迭代的过程,在每次迭代的开始,首先需要选取一小部分训练数据,这一小部分数据叫做一个batch,这个batch的样例会通过前向传播算法得到神经网络模型的预测结果,因为训练的数据都是有正确答案标注的,所以可以计算出当前神经网络模型的预测答案与正确答案之间的差距,最后基于这预测值和真实值之间的差距,反向传播算法会相应更新神经网络参数的取值,使得这个batch上神经网络模型的预测结果与真是答案更加接近。
假设用θ表示神经网络中的参数,J(θ)表示在给定的参数取值下,训练数据集上损失函数的大小,那么整个优化过程可以抽象为寻找一个参数θ,使得J(θ)最小,因为目前没有一个通用的方法可以对任意损失函数直接求解最佳的参数取值,所以在实践中,梯度下降算法是最常用的神经网络优化方法,梯度下降算法会迭代式更新参数θ,不断沿着梯度的反方向让参数朝着总损失更小的方向更新,如下图所示:
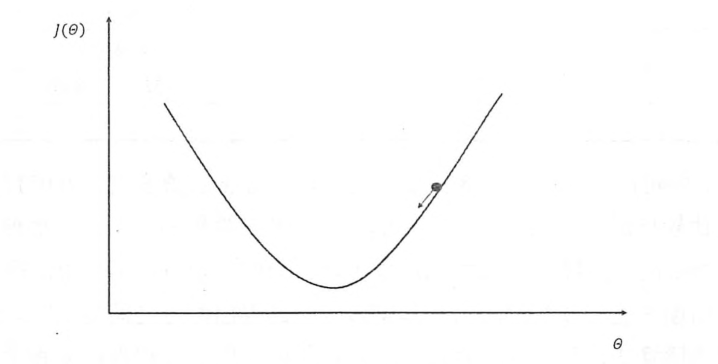
其中x轴表示参数θ的取值,y轴表示损失函数J(θ)的值,图上的曲线表示了在参数θ取值不同时,对应损失函数J(θ)的大小,假设当前的参数和损失值对应途中小黑圆点的位置那么梯度下降算法会将参数向x轴左侧移动,从而使得小圆点朝着箭头的方向移动,参数的梯度可以通过求偏导的方式计算,对于参数θ,其梯度就是对J(θ)求θ的偏导,有了梯度,还需要顶一个学习率n,来定义每次参数更新的幅度,从直观上理解,可以认为学习率定义的就是每次参数移动的幅度,通过参数的梯度和学习率,参数更新的公式为:
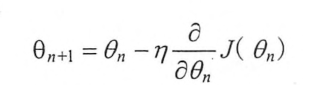
假设要通过梯度下降算法来优化参数x,得到损失函数J(x)=x^2 的值尽量小,梯度下降算法的第一步需要随机产生一个参数x的初始值,然后再通过梯度和学习率来更新参数x的取值,在这样例中,参数x的梯度为2x,那么使用梯度下降算法每次对参数x的更新公式为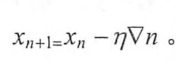
,假设参数的初始值为5,学习率为0.3,那么这个优化过程可以总结为:
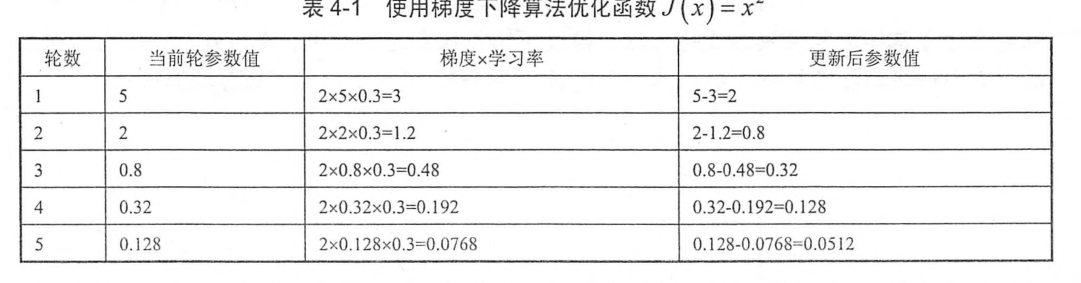
可以看出,经过5次迭代之后,参数x的值和参数最优值已经比较接近了。
梯度下降算法并不能保证被优化的函数达到全局最优解,如在局部损失函数的偏导为0,于是参数就不会进一步更新, 因此参数的初始值会很大程度影响最后得到的结果,只有当损失函数为凸函数时,梯度下降算法才能保证达到全局最优解。
损失函数和Softmax回归和MSE#
在得到一个batch的前向传播结果之后,需要定义一个损失函数来刻画当前的预测值和真是答案之间的差距,然后才能通过反向传播算法来调整神经网络参数的取值使得差距可以被缩小。
通过神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数,对于每个样例,神经网络可以得到一个n维数组作为输出结果,数组中的每一个维度对应一个类别,在理想情况下,如果一个样本属于类别k,那么这个类别所对应的输出节点的输出值应该为1,而其他节点的输出都为0,以识别数字为1为例,神经网络的输出结果越接近[0,1,0,0,0,0,0,0,0]越好。交叉熵是常用的评判方法之一:
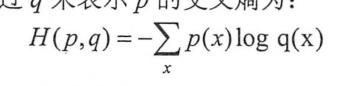
交叉熵刻画了两个概率分本之间的距离,它是分类问题总使用比较广的一种损失函数。交叉熵刻画的是两个概率分布之间的距离,然后神经元的输出却不一定是一个概率分布,概率分布刻画了不同事件发生的概率。当事件总数是有限的情况下,概率函数p(X=x)满足: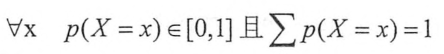 。
。
也就是说,任意事件发生的概率都在0和1之间,且总有某一个事件发生。如果将分类问题中,一个样例属于某一个类别,看成一个概率事件,那么训练数据的正确答案就符合一个概率分布,因为事件,一个样例属于不正确的类别,的概率为0,而一个样例属于正确的类别的概率为1,如何将神经网络前向传播得到的结果也变成概率分布呢,Softmax回归也就是一个非常常用的方法。
Softmax回归本身可以作为一个学习算法来优化分类结果,但在tensorflow中,softmax回归的参数被去掉了,它只是一层额外的处理层,将神经网络的输出变成一个概率分布,原始神经网络的输出被用作置信度来生成新的输出 ,而新的输出满足概率分布的所有要求,这个新的输出可以理解为经过神经网络的推导,一个样例为不同类别的概率分别是多大,这样就把神经网络的输出变成一个概率分布,从而才能通过交叉熵来计算预测的概率分布和真是答案的概率分布之间的距离。交叉熵函数不是对称的,它刻画的是通过概率分布q来表达概率分布p的困难程度,因为正确答案是希望得到的结果,所以当交叉熵作为神经网络的损失函数时,p代表的是正确答案,q代表的是预测值,交叉熵刻画的是两个概率分布的距离,也就是说交叉熵越小,两个概率分布越接近。假如有一个三分类问题,某个样例的正确答案是(1,0,0),某模型经过Softmax回归之后的预测答案是(0.5,0.4,0.1),那么这个预测和正确答案之间的交叉熵是:
H((1,0,0),(0.5.,0.4,0.1))=-(1log0.5+0log0.4+0log0.1)=0.3左右
如果另一个模型的预测是(0.8,0.1,0.1),那么预测值和正确答案之间的交叉熵是:
H((1,0,0),(0.8,0.8,0.1))=-(1log0.8+0log0.1+0log0.1)=0.1左右
从直观上很容易的知道第二个预测答案要优于第一个,通过交叉熵计算得到的结果也是一致的
与分类问题不同,回归问题解决的是对具体数值的预测,比如房价预测,销售预测等都是回归问题,这些问题需要预测的不是一个事先定义好的类别,而是一个任意实数,解决回归问题的神经网络一把只有一个输出节点,这个节点的输出值就是预测值,对于回归问题,最常用的损失函数是均方误差MSE:
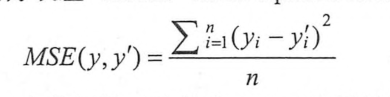
其中yi为一个batch中第i个数据的正确答案,而yi'神经网络给出的预测值。tensorflow中通过tf.square(y_-y)函数来实现均方误差。其中y代表了神经网络的输出答案,y_代表了标准答案,这里的减法操作是两个矩阵对应元素的减法。
指数衰减法#
在训练神经网络时,通过设置学习率控制参数更新的速度,学习率决定了参数每次更新的幅度,如果幅度过大,那么可能导致参数在极优值的两侧来回移动,而不会收敛到一个极小值,相反,当学习率过小时,虽然保证收敛性,但是这会大大降低优化速度,为了解决学习率的问题,tensrflow提供了解决学习率设置的方法————指数衰减法。tf.train.exponential_decay函数实现了指数衰减学习率,通过这个函数,可以使用较大的学习率快速得到一个比较优的解,然后随着迭代逐渐减小学习率。expone_decay函数会指数级别减小学习率:

每一轮优化时使用的学习率=事先设定的初始学习率*衰减系数^(完整速度/衰减速度),可以设置函数中的straicase选择不同的衰减方式,为False时,这时学习率随迭代轮数变化趋势如图灰色曲线所示,为True时,global_setp/decay_steps会被转化为整数,使得学习率成为一个阶梯函数,如黑色曲线所示
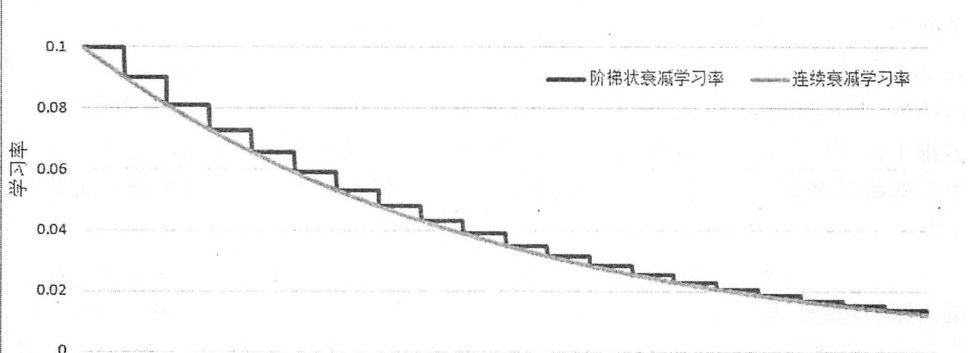
黑色曲线所示的情况下,decay_setps通常代表了完整的使用一遍训练数据所需要的迭代轮数,这迭代轮数也就是总训练样本除以每一个batch中的训练样本数。这种设置的应用场景是每完整的走完一遍训练数据,学习率就减少一次,这可以使得训练数据集中的所有数据对模型训练有相等的作用,当使用连续的指数衰减学习率时,不同的训练数据有不同的学习率,当学习率减小时,对应的训练数据对模型训练结果的影响也就小了。
一般来说初始学习率,衰减系数和衰减速度都是根据经验设置的,损失函数下降的速度和迭代结束之后总损失的大小没有必然的联系,不能通过前几轮损失函数下降的速度来比较不同神经网络的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号