


扫描特定网站(页)的更新链接(附完整源码下载)
闲暇时间经常登录小说网站和论坛(比如啃书),翻看自己感兴趣的连载小说。时常会碰到以下问题:
1、要打开网页花时间查找自己感兴趣的链接,耗时又无聊啊
2、某天比较忙或出差较长一段时间,没空去浏览或保存自己感兴趣的小说链接
3、其他原因
开发一个小工具解决上述问题那就完事大吉了
,废话少说,直接上图。
#获取更新界面:




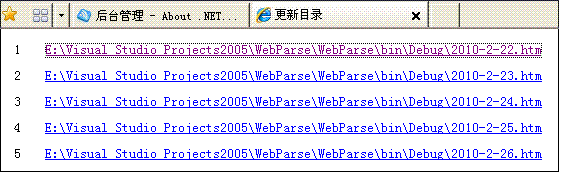
#获取的更新总目录(按日期排列):
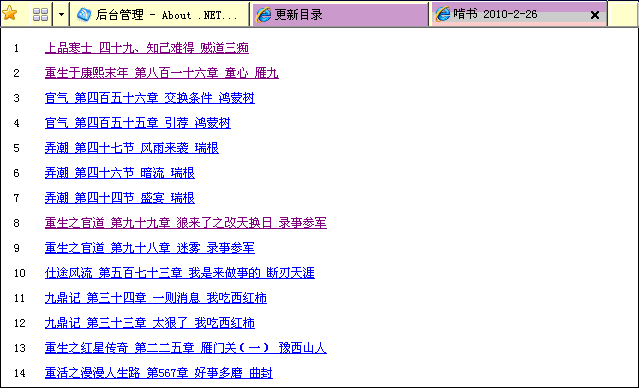
###获取的每日更新列表(也可按更新时间排列):
开发思路:
1、抓取网页(首页)、获取网页的不同页数和内容;
2、根据配置列表(感兴趣的小说名称,见下载包的booklist.txt文件)构建正则表达式,结合网页的数据结构,分析网页,获取感兴趣的链接;
3、生成更新总目录的html文件,生成当天更新列表的html文件;
4、建立windows服务项目,部署后台定时扫描网页,并同时可保存每日更新;
6、打开更新总目录的html文件,享受连载小说
。
具体可参见源代码,欢迎感兴趣的朋友交流和拍砖...................
源代码包括完整的核心类库项目、winForm测试项目、windows服务项目。
下载路径:
