表连接的优化(五)
---
title: 不懂SQL优化?那你就OUT了(五)
MySQL如何优化--表连接
date: 2018-11-24
categories: 数据库优化
---

上一遍我们讨论了where 子句的优化,这一遍我们来讨论一下表连接的优化
我们知道在数据库中表连接有两种方式:
1. 内连接(inner join)
2. 外连接(左外连接(left join), 右外连接(right join),全外连接(full join-->mysql 不支持全外连接)
### 什么是表连接
表连接就是指将多个表联合在一起实现查询。
###表连接的原理
表连接采用的是<font style="color:coral">笛卡尔乘积</font>,称之为横向连接.
### 笛卡尔乘积
笛卡尔乘积:是指将多张表的所有数据相连,最后连接的结果数为多张表数量的乘积。
例如:这里有一张学生信息表(3条数据) 和 一张班级表(4条数据)
表连接是采用笛卡尔乘积的原理,所以两张表相连的结果 应该为 3 * 4 等于 12 条数据,
###表连接的语法:
select 列名列表 from 表1 (inner | left | right )join 表2 on 过滤条件 (inner|left|right)join 表3 on 过滤条件... ###内连接和外连接的区别
内连接:
内连接被称为普通连接或者自然连接,内连接是从结果表中删除与其他被连接表中没有匹配行的所有行。
(注意:内连接可能会丢失信息)
如图:

左外连接:
左外连接的结果集包括 left outer join子句中指定的左表的所有行,而不仅仅是连接列所匹配的行。 如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
注:
写在 左边的表 叫做 左表
写在 右边的表 叫做 右表
如图:

右外连接:
右外连接是左外连接的反向连接,将返回右表的所有行。 如果右表的某行在左表中没有匹配行,则将为左表返回空值.
如图:

全外连接:(mysql 不支持)
全外连接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表 列 包含空值。如果表之间有匹配行,则整个结果集包含基表的数据值。
如图:
###MySQL的JOIN实现原理
> 在MySQL中,只有一种Join算法,就是大名鼎鼎的Nested Loop Join(嵌套循环连接),他没有其他很多数据库所提供的Hash Join,也没有Sort Merge Join。顾名思义,Nested Loop Join 实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与Join,则再通过前两个表的Join 结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复。
>
>
> —— 摘自《MySQL 性能调优与架构设计》
## 如何优化表连接
1.经常在连接的列上,也是外键上创建索引,可以加快连接的速度;
例如:两张表,学生表和班级表
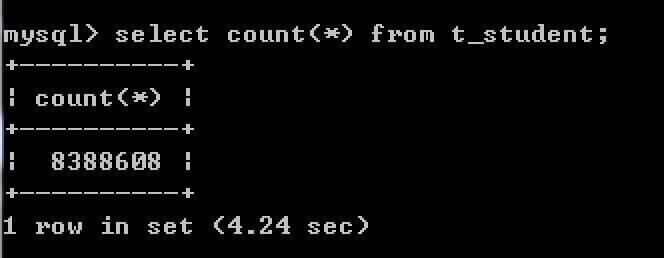
学生表中有 8388608 条数据

班级表中有 4条数据
未加索引时:
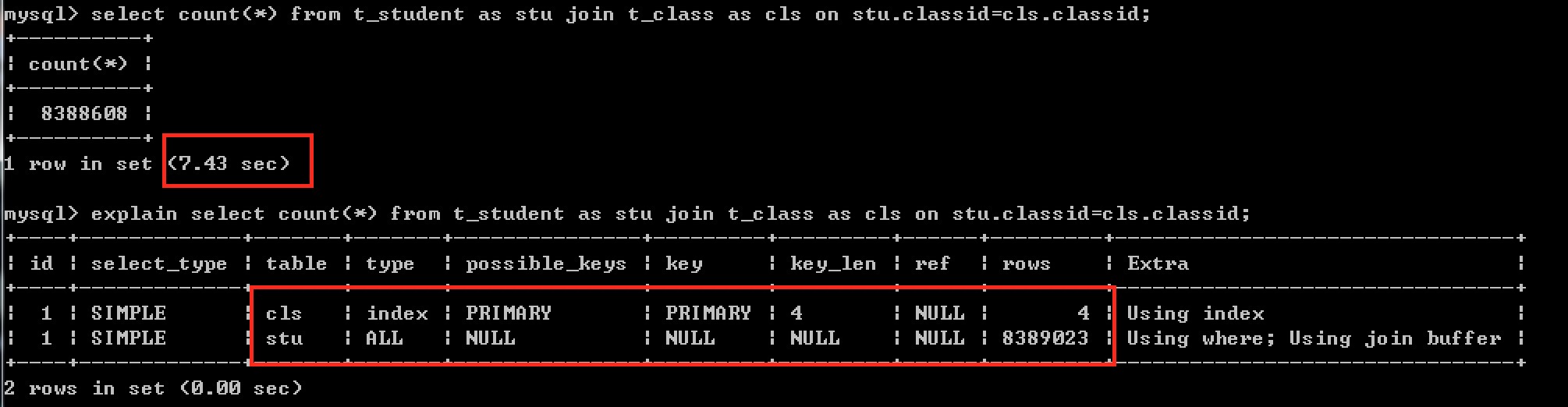
从结果看:
执行时间为: 7.43sec
对学生表进行了全表扫描(需要优化),扫描数据:8389023条
加上索引以后:


从结果看:
执行时间为: 4.56sec(效率提高了 2.87 s)
对学生表的也使用了索引,由全表扫描变成了ref,并且扫描数量为:41945, 查询效率明显提高了很多。
2. 驱动表的选择非常重要,驱动表的数据小可以显著降低扫描的行数,条件中尽量能够过滤一些行将驱动表变得小一点,用小表去驱动大表。
一般情况下参与联合查询的两张表都会一大一小,如果是内连接(join),在没有其他过滤条件的情况下MySQL会选择<font style="color:coral">小表(数据少的表)</font>作为驱动表, 如果是左外连接(left join)mysql会选择左边的表为驱动表,如果是右外连接(right join)则以右边的表作为驱动表。
如图1:(内连接)

从图1可以看出,mysql在做联合查询的时候,首先扫描的班级表,会自动选择小表(班级表(4条数据)为驱动表, 扫描班级表4条数据,然后在扫描学生表 41945 条数据。
如图2:(左外连接)

从图2可以看出,mysql在做左外连接查询的时候,会选择左边的表(学生表(8388608条数据)为驱动表。
首先扫描学生表 8389023条数据,再扫描班级班表 4 条数据。
如图3(右外连接)

从图3可以看出,mysql在做又外连接查询的时候,会选择右边的表(班级表)为驱动表。
首先扫描班级表 4 条数据,再扫描学生表 41945 条数据。
MySQL在执行join时会把join分为system/const/eq_ref/ref/range/index/ALL等好几类,连接的效率从前往后依次递减。
3.left join/right join和inner join时,尽量用inner join避免外联结和null,如果where条件中含有右表的非空条件(除开is null),则left join语句等同于join语句,可直接改写成join语句。
如图4:(left join)

从结果中看出,首先扫描的学生表,再是班级表,最后是教师表。
如果where条件中含有右表的非空条件,则left join语句等同于join语句,可直接改写成join语句。
如图5:


从上面的结果看,两句sql语句的执行计划是一样的。
4.在mysql的 left join 中条件放在 on 后面和在 where 后面是不同的
ON 条件(“A LEFT JOIN B ON 条件表达式”中的ON)用来决定如何从 B 表中检索数据行。
如果 B 表中没有任何一行数据匹配 ON 的条件,将会额外生成一行所有列为 NULL 的数据。
在连接匹配阶段 WHERE 子句的条件都不会被使用,<font style="color:coral">仅在匹配阶段完成以后,WHERE 子句条件才会被使用</font>。
ON/And: 使用And时,不论如何,左边主表都完全显示,辅表显示符合ON条件的那条数据,其他行辅表数据都为NULL
关键字 Where 是针对 所有表连接匹配数据以后,where条件将会从满足on 匹配条件的数据中再检索一次。
**条件写在不同的位置,得到的结果可能会不同,这一点要注意。**
例如:
**条件写 on 后面 (由于数据较多,我只截取前10条数据)**

显示左表所有的数据,在班级表中没有匹配的,都显示为null;
**条件写 where 后面 (由于数据较多,我只截取前10条数据)**

没有显示学生表中所有的数据,只是显示班级一的学生的信息,条件写在where后面,是在表连接匹配数据后,在进行了一次数据的检索。
On和Where都是作为条件约束来过滤数据,我们应该尽量在on过滤条件是尽可能多的匹配满足条件,然后减少where子句的检索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号