


深度学习图像分类处理学习笔记
在B站上看了一个叫霹雳吧啦Wz的up主的视频,把深度学习图像处理的一些方法按照提出时间总结的很详细,有原理有代码,看完真的想给大佬跪下;
兄弟们都看起来,有些东西记不住,这是我看视频的一些笔记;
连接:https://space.bilibili.com/18161609/video?tid=0&page=3&keyword=&order=pubdate
1.卷积神经网络:输入层,卷积层,池化层,全连接层
2.AlexNet(2012):
(1)首次使用GPU
(2)使用ReLU激活函数代替原本的Sigmoid和Tanh
(3)LRN局部相应归一化
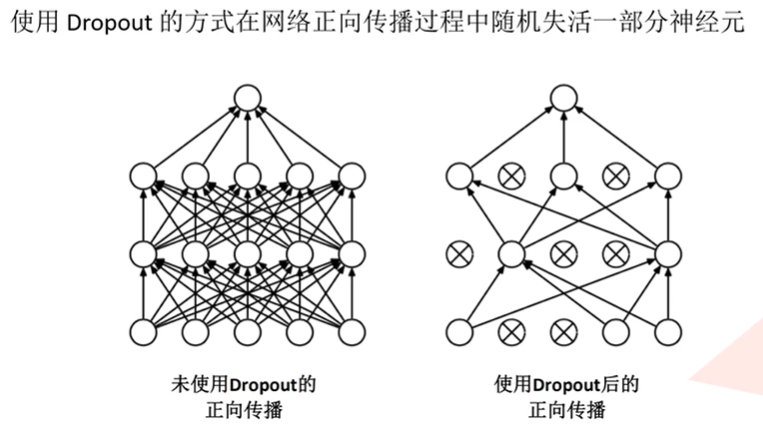
(4)全连接层使用Dropout随机失活神经元,减少过拟合
3.VGG(2014):
感受野:决定某一层输出结果中一个元素所对应的输入层的区域大小,即输出feature map上的一个单元对应输入层上的区域的大小。
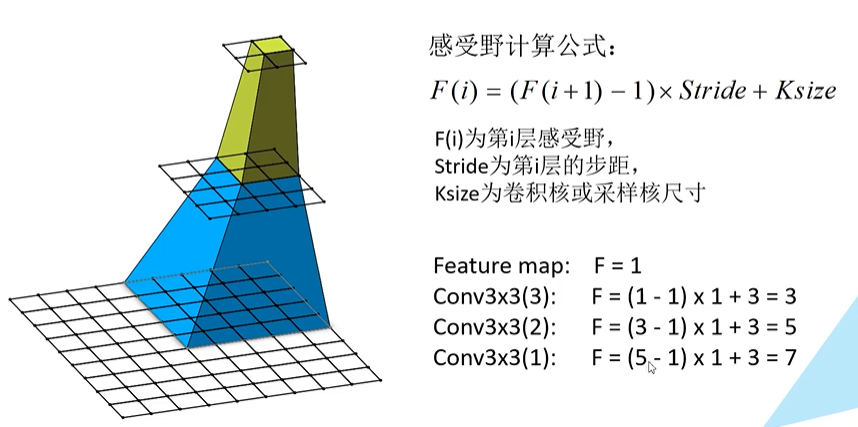
使用两个堆叠的3*3卷积核代替一个5*5的卷积核,使用三个3*3的卷积核代替一个7*7的卷积核;这样可以减少所需参数
4.GoogleLeNet(2014):
(1)引入了inception结构(可以融合不同尺度的特征信息)
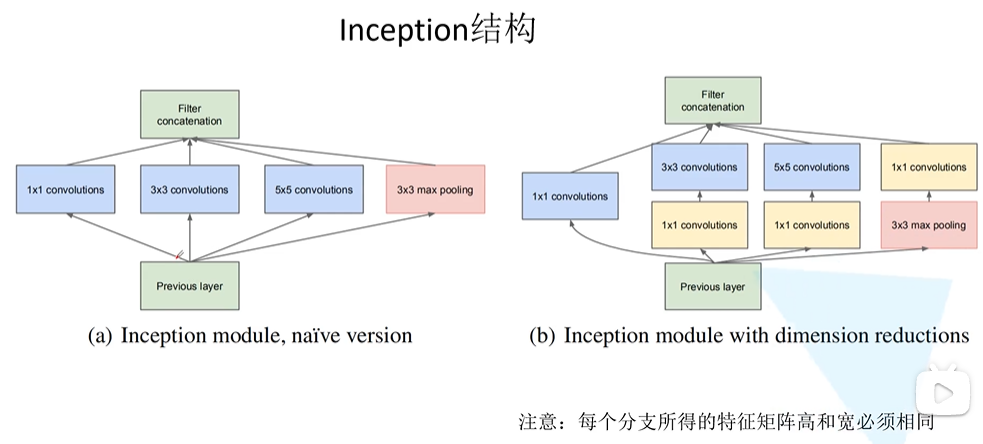
之前都是串行结构,inception是并行结构
(2)使用1*1卷积核进行降维以及映射处理
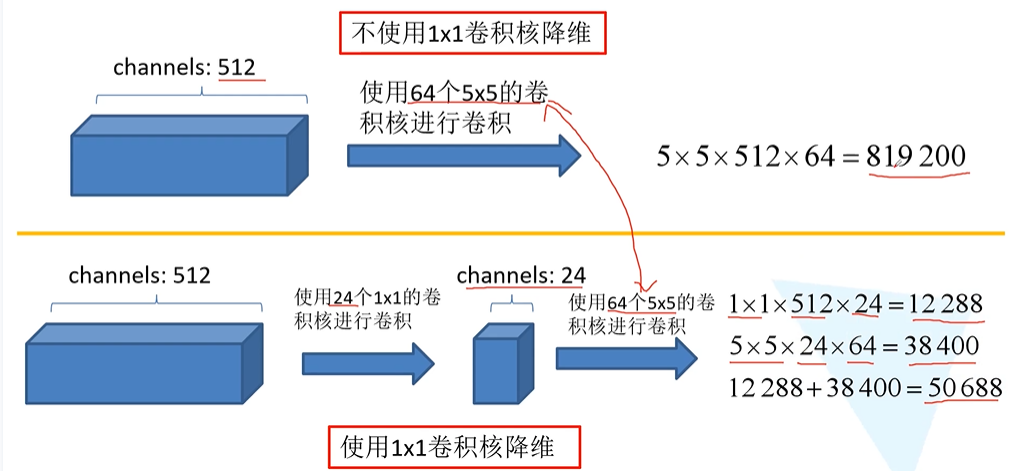
右侧使用1*1卷积核是为了进行降维处理,减少所需参数
(3)添加两个辅助分类器帮助训练(有三个输出层)
(4)丢弃全连接层,使用平均池化层(大大减少模型参数)
参数数量为VGG的20分之一
5.ResNet(2015):
(1)超深的网络结构(超过1000层)
随着网络层数的增加会产生的问题:a.梯度消失或梯度爆炸 b.退化问题
网络每向前一层,都会乘以一个小于1的误差梯度,就会越来越趋近于0,会导致梯度消失,反过来,每层梯度如果大于一,则会导致梯度爆炸
a的解决方法:对数据进行标准化处理;权重初始化;Batch Normalization
b的解决方法:使用残差结构即residual模块
(2)提出residual模块
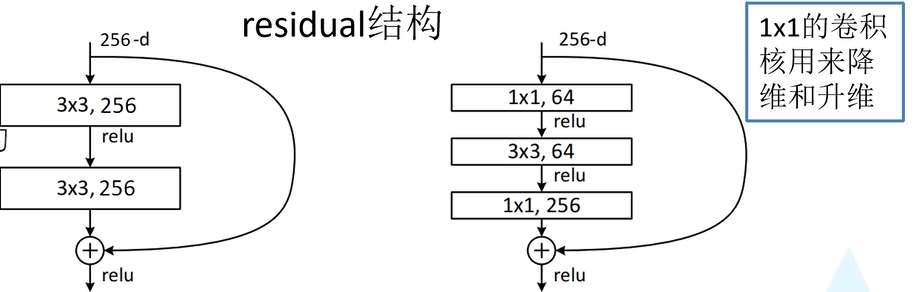
主分支与输出的shortcut的输出特征矩阵shape必须相同
(3)使用Batch Normalization加速训练(丢弃dropout,加速网络的收敛并提高准确率)
作者博客讲解:https://blog.csdn.net/qq_37541097/article/details/104434557
目的是使一批feature map满足均值为0,方差为1
6.MobileNetV1
专注于移动端或者嵌入式设备的轻量CNN网络,在准确率小幅下降的前提下大大减少模型的参数与计算量
(1)Depthwise Convolution(大大减少计算量和参数数量)
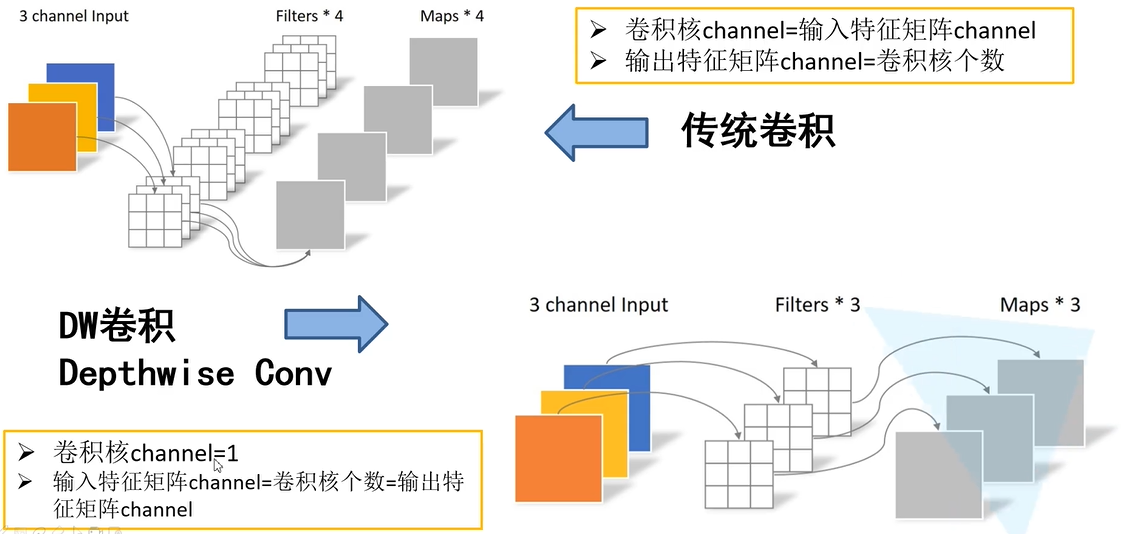
深度可分离卷积
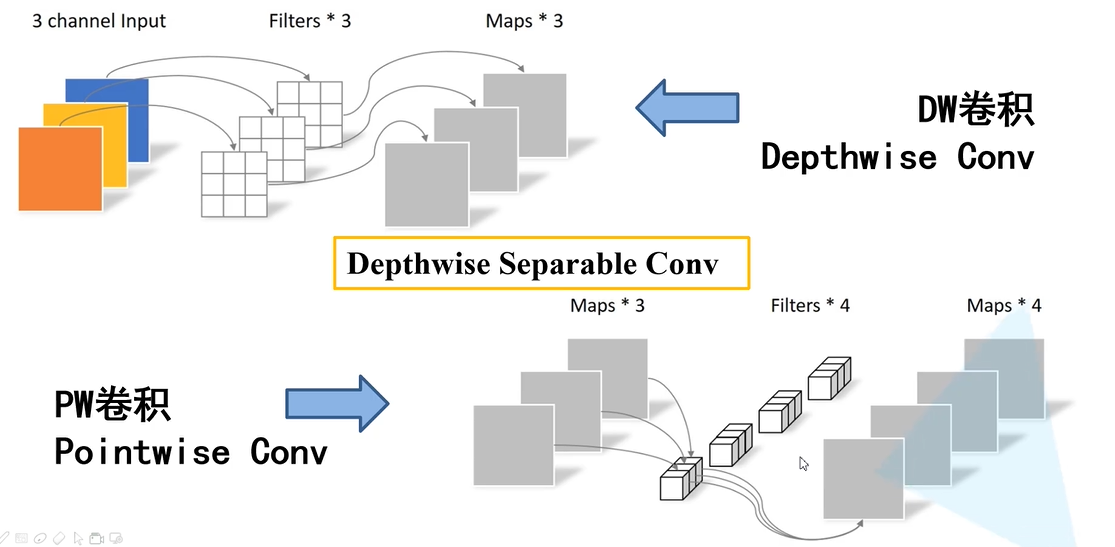
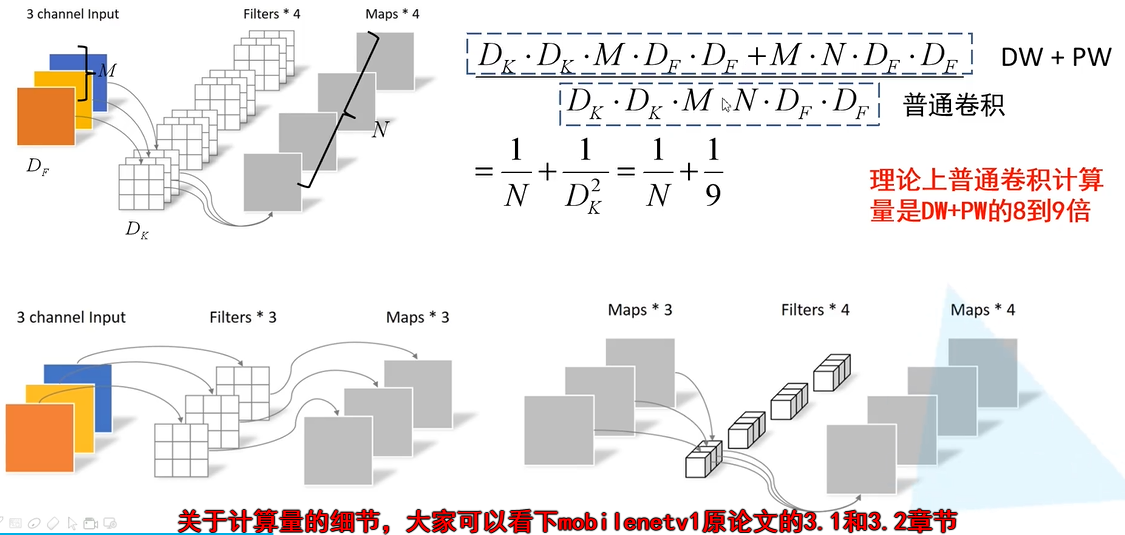
(2)增加超参数α(卷积层卷积核个数)、β(输入图像大小)
不足Depthwise部分的卷积核容易废掉,即卷积核参数大部分为0
7.MobileNetV2(2018)
相比与V1准确率更高,模型更小
(1)Inverted Residual(倒残差结构)
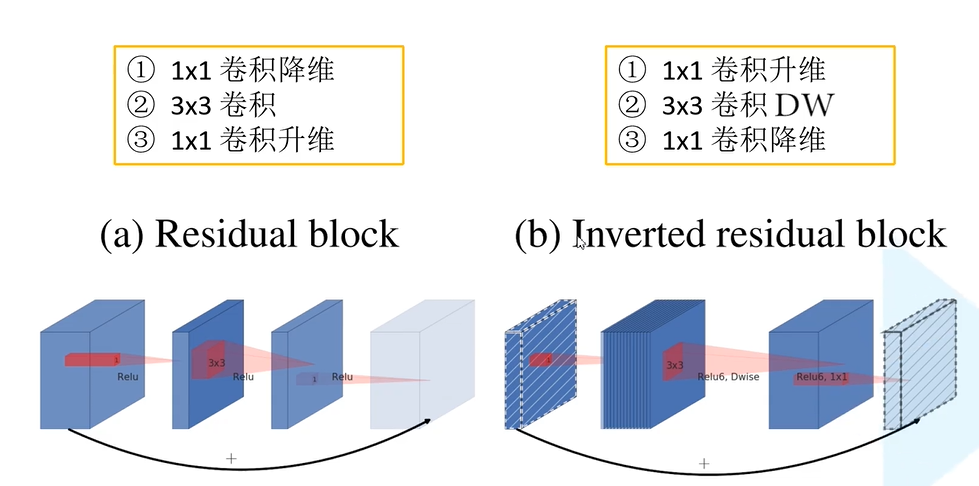
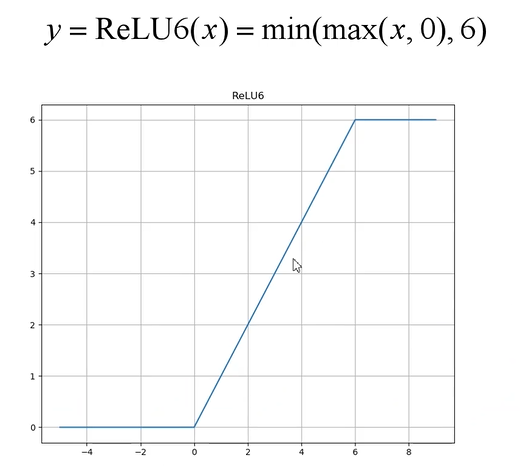
使用的激活函数为ReLU6激活函数:
(2)Linear Bottlenecks
对于倒残差结构的最后一个卷积层,激活函数不适用ReLU6,而是使用Linear Bottlenecks来代替。

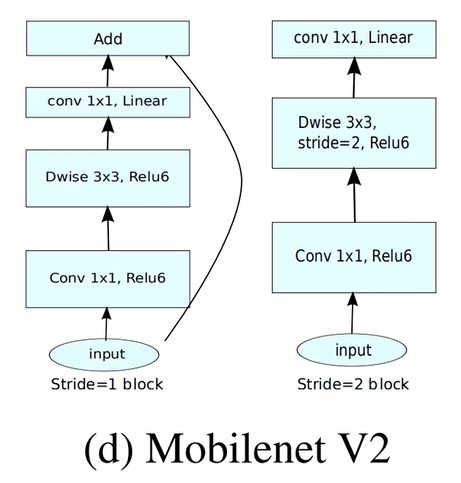
当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接。

