
TCP粘包和拆包
学习起因
本来学过计算机网络的,但是印象中好像又没学过(可能是因为不用考),所以面试问到还是一脸懵...........
TCP粘包
定义
TCP在传输字节流时,发送方发送的若干包数据到达接收方时粘成了一个包,从接受方来看就是前一包数据的尾紧接着后一包数据的头。起因存在于发送方也存在于接收方。
起因
发送方造成:TCP默认使用Nagle算法(主要作用:减少网络中报文段的数量),具体做两件事:1)只有上一个分组得到确认,才会发送下一个分组(如果报文长度超过1460就直接发出,不等待确认)。2)收集多个小分组,在一个确认到来时一起发送。相当于如发送报文的大小小于发送缓冲区大小,发送缓冲区将多次写入的数据一次发送出去。
接收方造成:接受数据的应用层没有及时将接受缓冲区的内容读取(TCP将接收的数据存入缓冲区中,由应用程序去缓冲区获取数据,而不是直接发送给应用进程)。
解决方案
发送方:关闭TCP使用Nagle算法,使用TCP_NODELAY选项关闭算法。而接收方没有办法处理粘包现象,只能将问题交由应用层处理。
应用层:在应用层层面解决问题的话,不仅解决接收方粘包问题,还能解决发送方粘包问题。解决方案:循环解决,读完一条数据,再读取下一条数据,直到所有数据都被处理完成。如何将每条数据分割开来:1)格式化数据:每条数据都由固定的数据格式(开始符和结束符),但是要保证数据里面没有开始符和结束符。2)发送长度:每条数据前用4个字节来表示数据的长度,应用层可根据这个长度来判断开始位置和结束位置。
TCP拆包
定义
如果数据包长度太大,超过MSS(最大TCP报文长度,不包括TCP和IP的首部)的长度,TCP就会将报文分开传输,这样就会造成一个完整的数据报文在传输过程中被分成了几部分,这就是拆包。
起因
发送方:1)应用层程序写入数据时的数据大于套接字缓冲区的的大小。2)TCP报文长度-TCP首部长度大于MSS时,将发生拆包。
解决方案
应用层:在应用层层面解决问题的话,不仅解决接收方粘包问题,还能解决发送方粘包问题。解决方案:循环解决,读完一条数据,再读取下一条数据,直到所有数据都被处理完成。如何将每条数据分割开来:1)格式化数据:每条数据都由固定的数据格式(开始符和结束符),但是要保证数据里面没有开始符和结束符。2)发送长度:每条数据前用4个字节来表示数据的长度,应用层可根据这个长度来判断开始位置和结束位置。
注意
粘包和拆包只发生于使用TCP传输方式,不存在于UDP传输方式,因为TCP是面向流传输的,而UDP是面向消息传输的,这就决定了TCP在传输过程中将上层传输的报文视作流数据,每个流数据可能包含上层的几个报文,而TCP报文首部又没有区分每个报文的标记,(比如起始标记和结束标记,包长度等),这就决定了TCP可能会产生粘包和拆包的现象。UDP每次传输都是一个消息一个消息地传输,而接收方每次也只接收一个消息,而UDP首部也是有着包长度来作为每个消息包的长度,以此对每个消息包进行区分。
UDP首部
首部8个字节,源端口和目标端口各占2个字节,UDP报文长度占2个字节,检验和占2个字节。此处引用《图解TCP/IP》的UDP报文首部组成图。
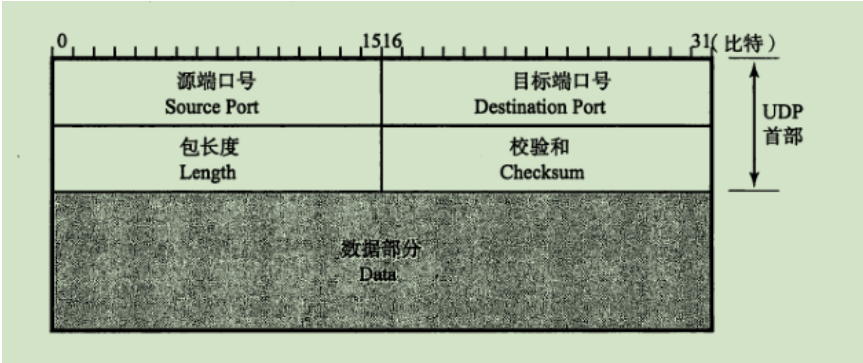
包长度可看出每个UDP数据包的最大长度可为2^16-1字节,所以UDP最大可传输的数据长度为2^16-1-8(UDP首部长度)-20(IP首部长度)
检验和的作用是判断数据是否发生错误,如果发生错误就将包丢掉,但不提供差错恢复的能力。
TCP首部

源端口和目标端口:各占两个字节,分别写入源端口和目标端口。
序号:占4字节,范围位[0-2^32-1],共2^32个序号,序号增加到2^32-1后,下一个序号就又回到0了。TCP面向字节流传输,每一个TPC连接传输的字节流中的每一个字节都按顺序编号。整个要传送的字节流的起始位置在建立连接时就设置了、首部中的序号代表的就说传送字节流的第一个字节的序号,例如,一个字节的序号为301,而发送的数据长度为100,即最后一个字节序号为400,所以如果有下一个报文段,那么数据序号应该从401开始。
确认号:占4个字节,期望收到对方下一个报文段的第一个数据字节的序号。例如,B发送给A的最后一个字节的序号为400,那么A就希望B下一次发送的数据的第一个字节的序号为401。所以ack就为401。
数据偏移:占4位,表示数据起始段到TCP报文起始处的长度,也就是TCP首部长度。因为首部中还有不确定长度的选项字段,所以数据偏移很有必要。而且只有4位说明能表示的最大长度为15,但不是15字节,因为数据偏移的单位是4字节,所以4*15为60,首部最多为60字节,所以选项长度不能超过40字节。
保留:占6位,保留为今后使用。
接下来是6个标志位。
紧急URG:当URG字段为1时,表明紧急指针字段有效。用来告诉系统此报文有紧急数据,需要优先发送(相当于高优先级的数据),而不要按照原来的排队顺序发送。当URG设置为1时,发送方应用进程就把紧急数据插入到本报文数据的最前面,而在紧急数据后面的还是普通数据,如果URG不设置为1,紧急数据就会按顺序排在普通数据后,没有插入的操作。
ACK:仅当ACK=1时确认号字段才有效。TCP规定建立连接后所有传送的报文的ACK都必须为1。
推送PSH:当两个进程相互通信时,如果一端的应用进程希望在键入一个命令后立即能收到对方的回复。发送方将PSH置为1,并立即创建一个报文段发送出去,接收方在收到PSH=1的报文段后,会尽快交付上层应用,而不会等缓冲区填满再交付。
复位RST:当RST=1时,表明TCP连接中发生了严重错误,必须释放连接,然后重新建立传输连接,RST置为1还用来拒绝一个非法的报文段,或拒绝打开一个连接。
同步SYN:在建立连接时用来同步序号。当SYN为1,ACK为为0时,表明这是一个连接请求报文段,对方若同意建立连接就发送一个SYN=1,ACK=1的接受连接报文。
终止FIN:用来释放一个连接。当FIN=1时,表明此报文段的发送数据已发送完毕,并要求释放传输连接。
窗口:占2个字节,用来告诉发送方自己能接收多大的数据,比如此时确认序号为701,窗口值为1000,那么就相当于告诉发送方,下一个发送的数据第一个字节的序号应该是701,只能接收到1700。所以窗口值是可以动态变化的。
检验和:占2个字节,检验和字段检验范围包括首部和数据两部分。
紧急指针:占2个字节,紧急指针仅在URG=1时才有意义,它指出本报文段中紧急数据的字节数(紧急数据后就是普通数据)。指出紧急数据的末尾在报文段中的位置,即使窗口为0时也可以发送紧急数据。
TCP Option
每个选项的开始都是1个Byte的kind字段,说明选项的类型,Kind为0/1的时候,选项只占1个Byte,其他选项在kind字段后面还有len字节,说明总长度包括kind和len的字节。看下图

从图中我们可以看到
0. 代表选项表结束
1.代表无操作
2.代表MSS
3.代表窗口扩大银子
8.代表时间戳
其他的kind值为4/5/6/7 四个选项被称为选择ACK及回显选项,目前回显选项已经被时间戳给代替!
引用https://blog.csdn.net/wdscq1234/article/details/52423272

