
【学习笔记】生成对抗网络
举个简单例子来形象描述一下 Generative adversarial network:MNIST 是手写数字数据集,我们可以训练一个检测器来检测给定图片是 UGC/PGC 还是 AIGC。生成对抗网络在训练检测器的同时训练了生成器。
过程若干轮,每轮都一样:用生成器的原始随即参数生成 \(m\) 个图,混上 \(m\) 个真实的图,贴上标签给检测器拿去训练;训练完检测器之后可以得到损失函数再训练生成器。
生成AIGC图像骗检测器的原始方法是 VAE,Encoder 输出 \(\sigma_i,m_i\) ,另外找一组 \(e_i\) ,将 \(\sigma_i\times e_i+m_i\) 传入 Decoder。目标是最小化函数 \(\sum\limits_{i} e^{\sigma_i}-(1+\sigma_i)+m_i^2\) (防止\(\sigma_i=0,m_i\) 表示原数据的情况),至于为什么是这个函数这里不会证明
上面题到的骗检测器本质上就是 Maximum Likelihood Estimation,可能可以理解成拟合离散分布或者连续曲线。
定义 Likelihood 为 \(\displaystyle{\prod P_G(x_i,\theta)}\) 取对数之后再把观测值的求和变成求 \(\displaystyle\arg\max\limits_{\theta} E_{x\sim P_{data}}[\log P_G(x;\theta)]\)
等价转换为下式(观测点的平均近似估计为全局期望)
最后一项之和 \(P_{data}\) 有关,是另外添上去的。但是这样可以变成 KL 散度(相对熵,离散形式为 \(\displaystyle D_{KL}(P||Q)=\sum_{x}P(x)\log\left(\dfrac{P(x)}{Q(x)}\right)\),给我的感受就是两个随机变量分布的“距离”)
但是 \(\theta\) 很难搞,所以用 Neural Network 训练,把原来的 Gaussian Mixture Model(可以理解为若干正态分布的线性组合) 作为模型输入,输出的东西扔到 Decoder 得到 output
从训练角度来讲就是你把期望值用 decoder 逆向计算出来 output 的期望值再计算损失函数,反向传播。
但是 decoder 逆向计算是很复杂的,于是引入一个 Discriminator(可以被理解为类似 checker 的东西)来决断搞出来的分布是不是好使。此时可以形成了有向图结构且处处可微,那么可以反向传播。
至此我们有一个 Discriminator 一个 Generateor ,目的是训练一个 Generator 出来。 形式化的讲,我们要求出 \(G^{*}=\arg \min\limits_{G}\left(\max\limits_{D}V(G,D)\right)\),其中 \(\displaystyle V(G,D)=E_{x\sim P_{data}}[\log D(x)]+E_{x\sim P_{G}}[\log(1-D(x))]\) ,我们将证明 \(V(G,D)\) 可以作为损失函数在网络中发挥作用。
当 \(G\) 固定时,将 \(V(G,D)\) 写成关于 \(D\) 的函数:
给 \(D\) 加一个 sigmoid 就可以实现 \(0\le\arg\min\limits_{D}V(G,D)\le1\) 咯
回代并展开得到
另外引入 \(\rm{JSD(P||Q)}=\frac12\left(KL(P||\frac{P+Q}2)+KL(Q||\frac{P+Q}2)\right)\) (不难发现这是一个 \(P,Q\) 地位相同的函数),于是上式转化成
根据 \(\rm{JSD}\) 函数的性质,如果 \(P_G(x)\cap P_{data}(x)=0\) 则结果是 \(\log 2\),如果 \(P_{G}=P_{data}\) 那么结果是 \(0\) 其它情况下 \(0<\rm{JSD}(P_{data}||P_G)<\log2\)
那么这时候全局最优解唯一并以常量形式存在且可以被取到(\(P_G=P_{data}\)),所以我们的网络训练可以把最小化 \(V(G,D)\) 作为目标。下图还证明了该梯度下降可以收敛到最优解

更新网络的方式为 \(\theta_{G_{i+1}}\leftarrow \theta_{G_i}-\eta\frac{\delta V(G_{i},D_{i+1})}{\delta G_i}\),这时候有个问题就是 \(G_{i+1}\) 和 \(G_i\) 的最大值取值点发生了变化,不一定能满足 \(\arg\max\limits_{D} V(G_{i+1},D)<\arg\max\limits_{D} V(G_i,D)\) 。不过普通网络梯度下降的时候也会遇到损失函数不减反增的问题,不妨先暂时搁置
注意到上面的计算中我们将 \(P_{data}\) 和 \(P_G\) 视为了连续函数,在实现中我们还是用观测点来近似全局期望,形式化的就是从 \(P_{data}\) 和 \(P_G\) 中分别选择 \(m\) 个点 \((x_1\dots x_m),(x'_1,\dots x'_m)\),\(\rm{maximize}\ V'=\frac1{m}\left(\sum\limits_{i=1}^m log D(x_i)+log[1-D(x'_i)]\right)\)
注意这时候我们找到的不是真实的 \(\max V(G,D)\) 而是一个 \(V(G,D)\) 的下界
总结来说算法流程本质上是下图:

实际代码书写的时候说要把 \(V(G,D)\) 改写成 \(\frac1m\sum\limits_{i=1}^m-\log(x'_i)\) ,原因是保证在 \(x_i\) 比较小的时候(接近于 \(0\) )梯度会更大一些。
另外显然的问题就是 Loss function 可能会趋近于 \(0\) 。因为选 \(m\) 个点有多少能选到交集里面是很不确定的(或者说概率很小的),所以可以大幅削弱 discriminator 来避免 overfitting;或者说向 discriminatior 的输入中加入额外的人工噪声/给标签加噪声(remember,noise decay over time)。
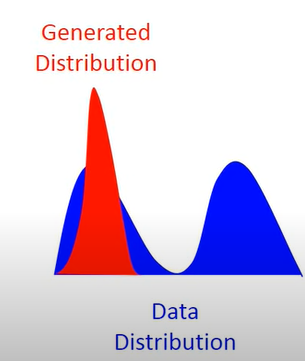
还有一个问题是ModeCollapse(你不知到模型不能做什么),直观的:
据说还有 Conditional GAN/WGAN。别急,让我学了再更

 浙公网安备 33010602011771号
浙公网安备 33010602011771号