
引用 EAGLE/EAGLE2 的文章汇总
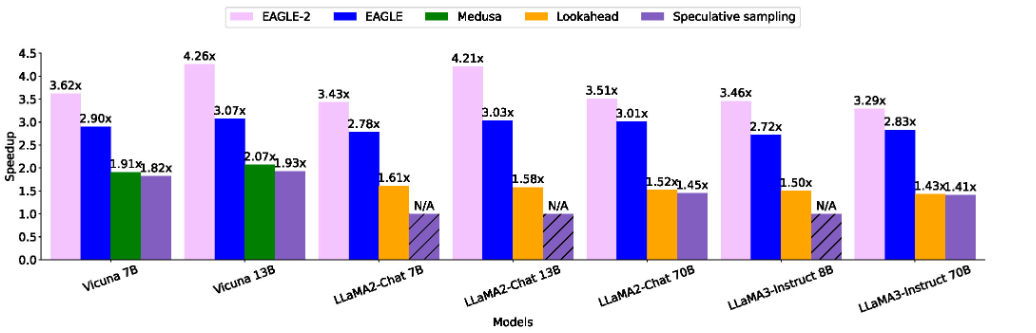
这张图是 eagle 和 previous approaches 的加速效果对比。
引用 eagle 的文章也可以被分成很多类,它们引用 eagle/eagle2 的侧重点也很多样。有不少文章是把 eagle 和 eagle2 作为 speculative decoding 的示例,这种不再在这里列出了。有些文章我读完之后会在下面有一些注解,比如算法流程的简述。
paper 的 motivation 可能大不相同,有的 motivation 我也有共鸣,我也觉得这里也可以优化。另外一些我觉得就很牵强。不可以单看这些 motivation 引出的做法,否则会摸不到门路,形成一种“魔改”的错误印象。我觉得大伙的工作都是有清晰的来龙去脉的。
针对 draft tree 的优化
https://arxiv.org/pdf/2406.17276
https://arxiv.org/abs/2412.12639
https://arxiv.org/abs/2411.10666
https://arxiv.org/pdf/2409.00142v1
https://arxiv.org/pdf/2412.18910
主要解决的是 draft tree 深度需要人工设定的问题。于是这篇文章引入了一个能预测 optimal draft tree depth 的模块。收集数据,训练的手法没有门槛。确实有很小幅度的优化。
early exiting
https://arxiv.org/pdf/2404.18911
deployment practice 的经验
似乎有这么一个想法:把 base model 放到云上,把 draft model 放到端测实现端云协同??
https://arxiv.org/pdf/2406.14066
在实际的在线 LLM 服务系统(包括持续批处理)中部署推测解码并不总能带来性能提升——在高请求率或低推测准确率的情况下,推测解码可能会导致延迟反而增加。此外,不同系统负载下并没有一种适用于所有工作负载的最佳推测长度。另一个问题是投机采样可能在 inference batch_size 不为 1 时表现不佳(countinuous batching)。
于是这个文章引入 goodput 的指标,它被定义为每秒生成的词元数。与传统的吞吐量不同,有效吞吐量仅衡量那些被目标模型验证并生成的词元。这篇文章的方法先估计 goodput,然后通过 goodput 来决定每个请求在投机采样中的 depth 超参数的值。
https://arxiv.org/pdf/2407.01955
不同的 base model,不同的下游任务,每个都训练 draft model,开销太大。本文主要优化这个部分。但是和 eagle 关系不大,我没有仔细看
https://arxiv.org/pdf/2412.18106 https://arxiv.org/pdf/2410.21340 只把 eagle 当作投机采样的一个例子,于是先不看了。
multi draft model
https://arxiv.org/pdf/2408.08470 Context-Aware Assistant Selection。如果现在有多个 draft model 的生成结果,高效根据上下文对生成结果进行选择,该文章认为这是一个决策问题。于是可以通过 RL 的方法来进行一些实验。
https://neurips2024-enlsp.github.io/papers/paper_53.pdf
我们的方法采用多臂赌博(multi-armed bandit)采样策略,在不同草拟模型之间动态分配计算资源,从而提升整体生成性能。
draft model 训练
这部分优化主要关注了:
- draft model 本身的速度
- draft model 和 base model 的对齐程度
对投机采样方法的影响。似乎都 explicitly 提升了性能。如果有时间了后面可以仔细读读这几篇文章的内容。
https://neurips2024-enlsp.github.io/papers/paper_68.pdf 使用 diffusion model 当作 draft model。但是 introduction 部分逻辑没有建立好,不知道为啥用 diffusion
https://arxiv.org/pdf/2403.09919v4 用标准的 RNN 当作 draft model,为什么跑起来比 eagle 快呢?这个得仔细分析分析。
https://arxiv.org/abs/2411.11055
https://arxiv.org/pdf/2412.00061
https://arxiv.org/pdf/2408.15562
https://arxiv.org/pdf/2408.08146 使用 GAN 的思想来训练 draft model
https://arxiv.org/pdf/2408.15766
https://arxiv.org/pdf/2410.03804
现有的投机采样方法存在一些架构上的局限性,包括部分可观测性和缺乏策略性。
部分可观测性发生在较小的(草拟)模型无法完全获取LLM状态信息时,从而导致次优的预测。
训练过程中缺乏策略性的问题是因为较小的模型通常在理想条件下训练,假设输入是完美的。但这与实际场景不符,因为小模型自己会生成部分输入。我们用小模型草拟新的词元的时间越长,分布偏移就越大,与训练环境的差距也越大。(从 exposure bias 的角度来理解,有点意思)
具体做法没看。
fun fact,这篇文章一作邮箱太魔怔了。
投机采样中的 temperature
https://arxiv.org/abs/2410.10141
draft tree mask
https://arxiv.org/pdf/2409.10644
没太看懂这篇文章的方法,但是感觉应该没啥用,也不太重要。
侧重于硬件
https://arxiv.org/abs/2412.18934
https://arxiv.org/abs/2405.18628
https://arxiv.org/pdf/2405.20314
不需要 draft model 的方法
https://arxiv.org/pdf/2407.12021
把使用小模型进行投机采样,变成了使用 MCTS 和 n-gram 等统计方法进行投机采样。那么可想而知,它不需要微调小模型,不需要除了基座模型之外的显存开销。效率比 eagle 差很多。
https://arxiv.org/pdf/2404.18911
这篇文章主打不需要 train draft model、不需要 Base model 之外的显存开销。
该方法针对输入引导的任务,包括代码编辑、文本编辑、摘要生成等,由于其输出与输入存在大量重叠的特性(明示缺少泛化性),PLD 直接选择 prompt 里面的 token 作为 draft token(根据 cosine similiarity 去 retrieve)。有点乐。
https://arxiv.org/pdf/2408.08696
观察到解码过程中生成的候选标记很可能在未来序列中重复出现,我们提出了标记回收(Token Recycling)。该方法将候选标记存储在一个邻接矩阵中,并在矩阵上使用类似于广度优先搜索(BFS)的算法构建草稿树(draft tree)。随后,通过树注意机制(tree attention)对草稿树进行验证。解码过程中生成的新候选标记将用于更新矩阵。
https://arxiv.org/pdf/2403.18647
在词表里面引入 4 个 special tokens。推理时把第 i 个 special token 的 next token prediction 结果当作第深度为 i 的 draft tree 上的节点。再做一次 base model 前向传播,来进行验证和接受。这种方法是稳赚不赔的,因为两次 base model 前向传播生成了 2+k 个 token。很有意思的做法!
https://arxiv.org/pdf/2411.03786 这个也是不训练 draft model,没细看
https://assets.amazon.science/45/72/4848937d41b0b152ab24f1ca7d41/snakes-and-ladders-accelerating-state-space-model-inference-with-speculative-decoding.pdf 把 draft model 从 transformer 换成一个状态空间模型。但是我不动 state space model,先鸽了
https://openreview.net/pdf?id=rk2L9YGDi2



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律