
2024-03-18 闲话
今天听了 [FAI] UMich 胡威 | 神经网络表示中的隐藏结构
【Neural Collapse】
假设我们的神经网络在经过映射 之后再经过 Linear + softmax 得到输出,考虑经过 映射后的 representation。如果是分类任务(总共 类),那么会根据 input 的 label 聚合到 个点。同时这些点有非常好的特征,其两两之间夹角 满足
这个结论是对大量实验数据进行可视化得到的,现在的研究行至:
记原先的 Loss function 为 ,因为神经网络( )的表现能力很强,所以可以将 换成 ,这样就不用对 进行研究了。
最后的结论是在这个 setting 下确实会收敛到 个点,它们之间的夹角也满足上面说的性质。但是这个 drawback 也太显然了,怎么能忽略 呢?
不难发现这个研究至此都认为 representation 和 label 极度相关,但是这和 input 到底有没有关系呢?那么 UMich 老师的研究的 motivation 便是这样的。
实验的做法就是构造 label 和 input 的 mismatch,在 CIFAR-10 中将两个类的图片混合成一个类。结果确实是 collapse 到了 5 个点。但是把聚合到一起的点(下文称其为一个集合里面的点)拉出来再做 visualization,效果是这样的:(这里我们仍然认为每个集合里面的点 label 相同,我们只是将点附上了颜色)
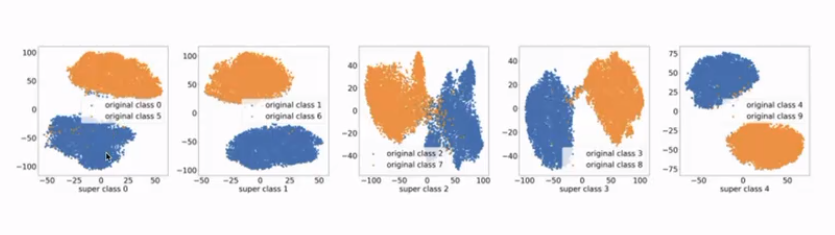
其实不同 label 的 feature 信息还是保留到 representation 里面。这个发现的作用是我们可以通过聚类恢复原有的 label,再拿来训练 Linear 层并进行 softmax,最后 test accuracy 能做到和原始给 10 个 label 几乎相同。这样的话 supervision 中提供的信息量可以折半。
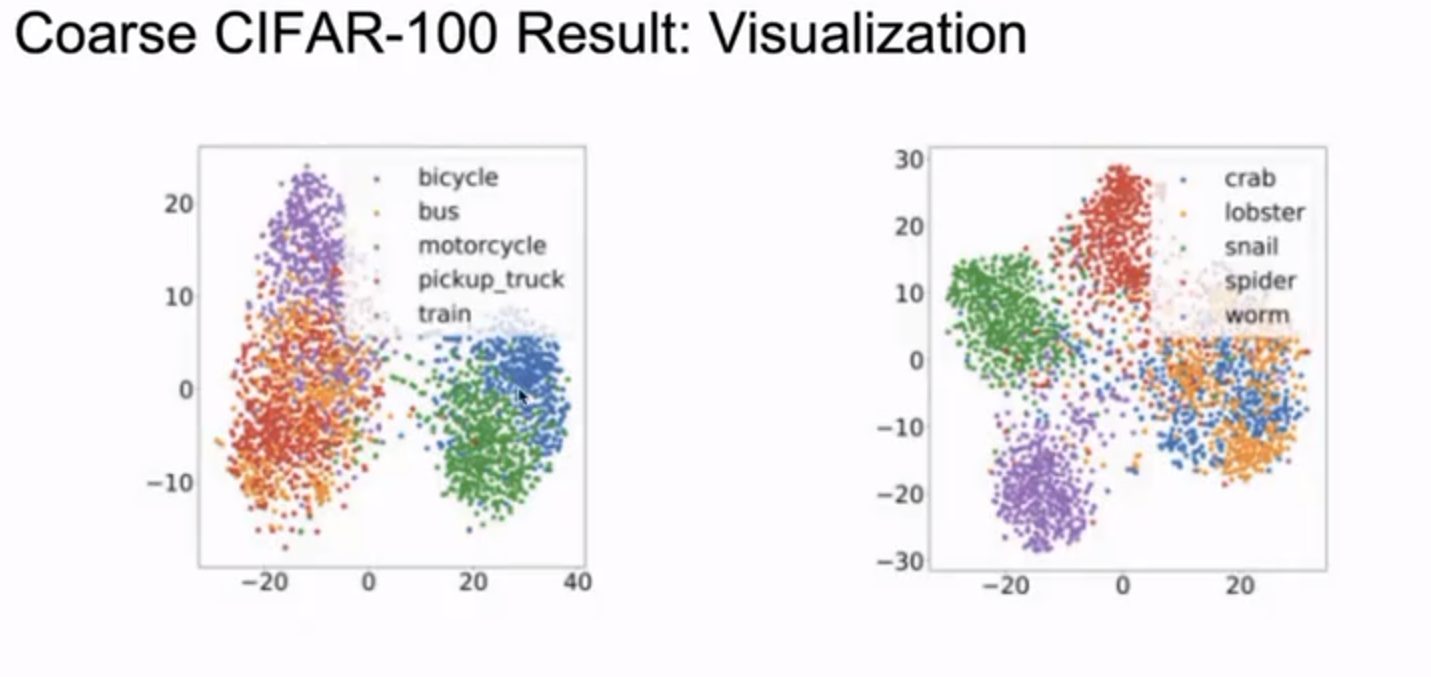
后面开展了 “semantic similarity 是否对子结构中的聚合有影响” 的研究,利用了 CIFAR-100 中的 super class 将图片 label 合并,下图是某个 super class 可视化之后的结果。感觉上还是可解释的。
有一个蒸馏算法应用了这个结论,将 teacher model 的 linear+softmax 层之前的 representation 提取出来,然后进行 linear projection。motivation 是通过投影轴进行信息提取,并构造一些 pseudo subclass(在原先分类任务的 class 变成了 super class),通过 linear + softmax 得到在这些伪分类上的概率,拿去给学生模型学习。学生模型拟合 subclass 结果之后再将这些结果合并(进行 构造 subclass 过程的逆过程)得到真正分类任务的标签概率。
这个方法能 work 的原因,按照我的理解是,它把 feature 具体化(subclass)再聚类了。
【(linear) mode connectivity】
假设 是分别针对某一任务分别训练的两个(结构相同,只是训练过程不同)神经网络(已经收敛,test accuracy 都是最好的),那么在某些 condition 下,模型 也能达到差不多高的 test accuracy。这其实表明两个模型所收敛到的 minima 是(在高维空间中是)相连的。
有两种方法可以实现这样的 connectivity:
-
将 训练 个 epoch(据说 ),然后令 (拷贝一份),再用不同的训练方法训练 直到收敛
-
训练 ,令 。再将 中每层的 neuron 重新排列来实现 层间 neuron 的 matching,数学上来讲就是最小化:
- weight matching:, 表示网络层数, 表示置换矩阵,我的理解是有 个位置是
- activation matching:, 表示网络层数, 表示置换矩阵, 和 的区别顾名思义,一个是经过 activation function 之后的表示,一个是参数。
这里不难有个 motivation 是将 modelwise 的 connectivity 强化到 layerwise 的 connectivity,结论是:新模型每层 feature representation 可以通过两个模型线性插值得到,那么可以认为新模型和原来两个模型效果相同。另有两页 slide:

上面主要是讲了 L(linear)L(layer)F(feature)C(connectivity) 的两个条件,下面讲了 LLFC 和 permutation method(第二个方法) 之间的关系。

有两个感受:第一是关注 input feature 是非常重要的,将 input feature 和 hidden representation 联系起来有些奇效;第二是理论还是太难了,感觉 paper 有大量放缩凑系数。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律