
今天你刷知乎了吗?
本文旨在通过刷知乎夯实基础知识。
-
从根本上,知识蒸馏是要寻求最小复杂度表示,本身这是个好问题。deep network is a memory and it stores information by its shape. 知识蒸馏问我们,如何最有效的记录一个深度网络构建的形状。这是一个物理上和计算上非常非常fundamental的问题。
剪枝可能更符合这个气质。本质上剪枝蒸馏量化,都是在做知识迁移的工作,都可以是研究从大到小。这里面似乎只有蒸馏,未必一定是从大到小,它可以是跨模态的,可以是跨结构的。
-
p 值
定义;假设检验中,假设 “零假设为真时”观测到的,“至少与实际观测样本相同”的样本(比实际样本更为极端)的概率。
举例子:现在有一颗硬币,判断其是否能等概率投出正反面。假设是硬币公平。这就是在做假设实验。硬币公平,被称为零假设。
投十次,正面八次,这个“八次”是实际观察样本。至少与实际观察样本相同,指一侧比另一侧至少多 6 次,比如正面 0、1、2、8、9、10 次。可以在硬币扔出正反概率相同的 setting 下算出来这样的事件的发生概率,这就是 p 值。
所以 p 值建立在问题 setting,假设内容,观测样本 三者之上。那么 p 值越小,说明零假设更有可能不成立。一般认为 则 zero hypothesis 不成立。
-
batch normalization
你现在有一个 batch 的 , 为 batch size,令 。batch normalization 得到的结果就是 。
是一个极小的常数,为了避免除 0(类似二分的 eps),
不是超参数,但是不是 。
why batch normalization?
大概是我们希望使用一些非线性的激活函数对数据进行拟合。比如使用 。但是在 back propagation 的过程中如果大量数据落到趋近于 的地方,导数是非常小的。通过观察函数图像可以知道, 在 附近导数线性。那么我们需要一种方法使得数据集中到 的较小的一个邻域。于是使用 batch normalization。
why ?
据说是一种对数据过于集中的 trade off,防止激活函数变成 y=x。但是这样的描述太过于哲学了。
How to normalize queries?
对所有查询进行 normalization 即可。
-
proximal policy optimization
我们知道 policy gradient 的做法是每次重新对数据采样,然后迭代 state value 和 action value 这两个网络
但是每次迭代的采样数据只能使用一次这有很大浪费。所以我们希望通过一种方式把之前的采样数据也拿进来用。
做法就是使用 对每个步骤赋权加到损失中。在单步迭代中,因为要加权所以我们并不希望两个 policy 的差异太大(因为我们仍然是通过采样衡量,我们不希望采样落在特殊的位置),那么还引入了散度惩罚,即在 loss 中加入 。这里 是一个不断更新的参数,可以看看伪代码。
在 loss 的计算中有 A 函数,这个就是 和根据 trajectory 上 reward discount 出来的结果的差值。

因为 openai 论文没有好看的伪代码,所以只能找了一张网图
RLHF on Language model 是指能 generate context 的 model 视为 policy,将模型生成 token 视为 action 。reward 是通过一个 Human Feedback 训练的打分 LLM 给出的,同时还要和 PPO 一样加入 KL 散度避免偏移过大。
不过有些 LLM 的训练使用的是 actor-critic。
-
beam search
这个是在 youtube 上看的,也姑且记录到这里。理论上应该写一份代码的,但是我实在是太过于颓废了。
在词语接龙得到 output 的过程中我们往往是保留概率最大的一个 word 将它传入语言模型中做下一个词语的预测。但是 beam search 不一样,它选择保留概率最大的 B 个结果,将这 B 个结果传入语言模型中做预测之后得到 B 乘 词表大小个概率,再取 B 个继续预测。
-
nucleus sampling
Beam search degenerates and starts repeating. If you see a fragment repeats 2-3 times,it has very high probability to keep repeating.
解决方案是随机采样。但是随机采样有一个问题就是长尾分布。比如在选择 next token 的时候有很多在 vocabulary set 中的 token 的 probability 是非常小的。将 token 按照概率从高到低排序,保留最高的 且 概率加和超过 P%(比如 90%) 的若干 token 并重新赋权值。
再根据这个过程把 beam search 的保留 top-k 变成进行 truncated 采样即可。
-
RARR
其实很容易根据 LLM 生成 token 的原理知道为什么会出现幻觉。它本质上还是一个从 corpus 学概率分布,所以共现就会导致更多的链接,甚至它是错误的。
检验语言模型的输出是否正确的一种方法。pipeline 如下。
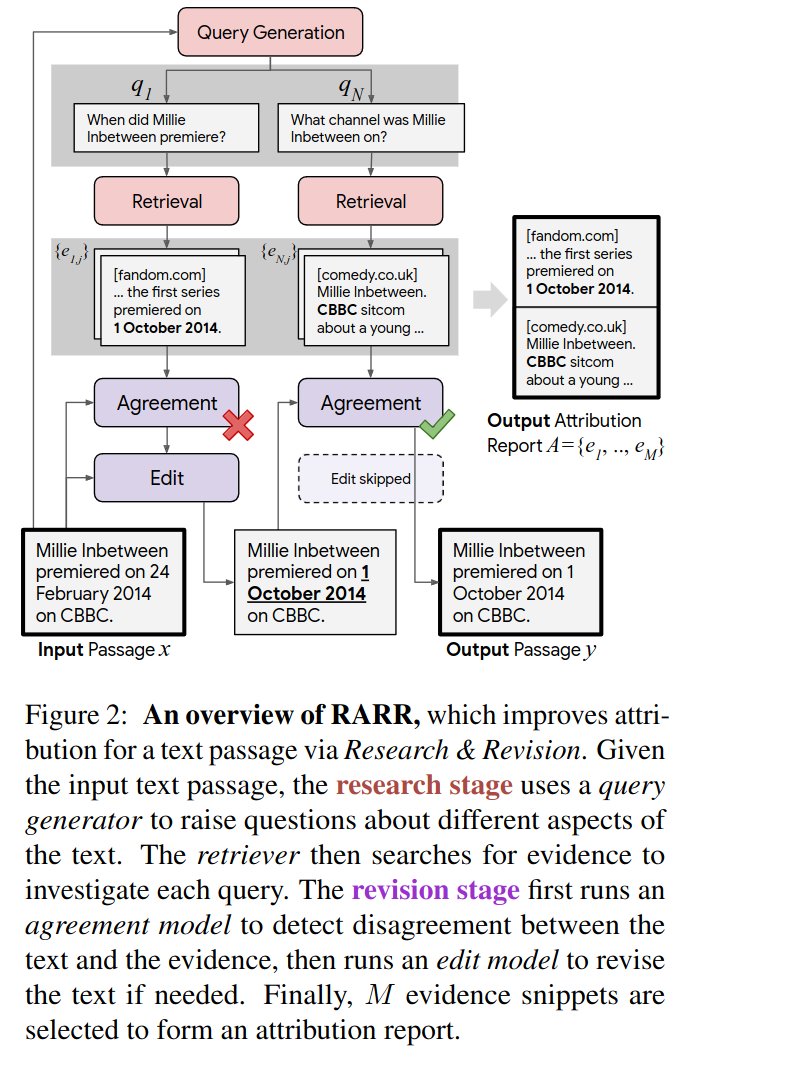
这里 input passage x 表示 Language Model 最初始的生成,然后我们试图生成一些能上网搜索的“问题”并从网络文档中找到相关的源文档。经过 retriever 之后我们使用 agreement model 来对它进行一些修改,然后继续把修改过的结果当成输入继续走流程,直到无法修改。
文章 github 代码里面 retriever 是 bing和来自hugging face 的passageranker,agreement model 是 openai key ,可谓是科技改变生活



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律