
面向对象编程:第四单元博客作业
第四单元博客作业
本单元两次作业的架构设计
第1次作业
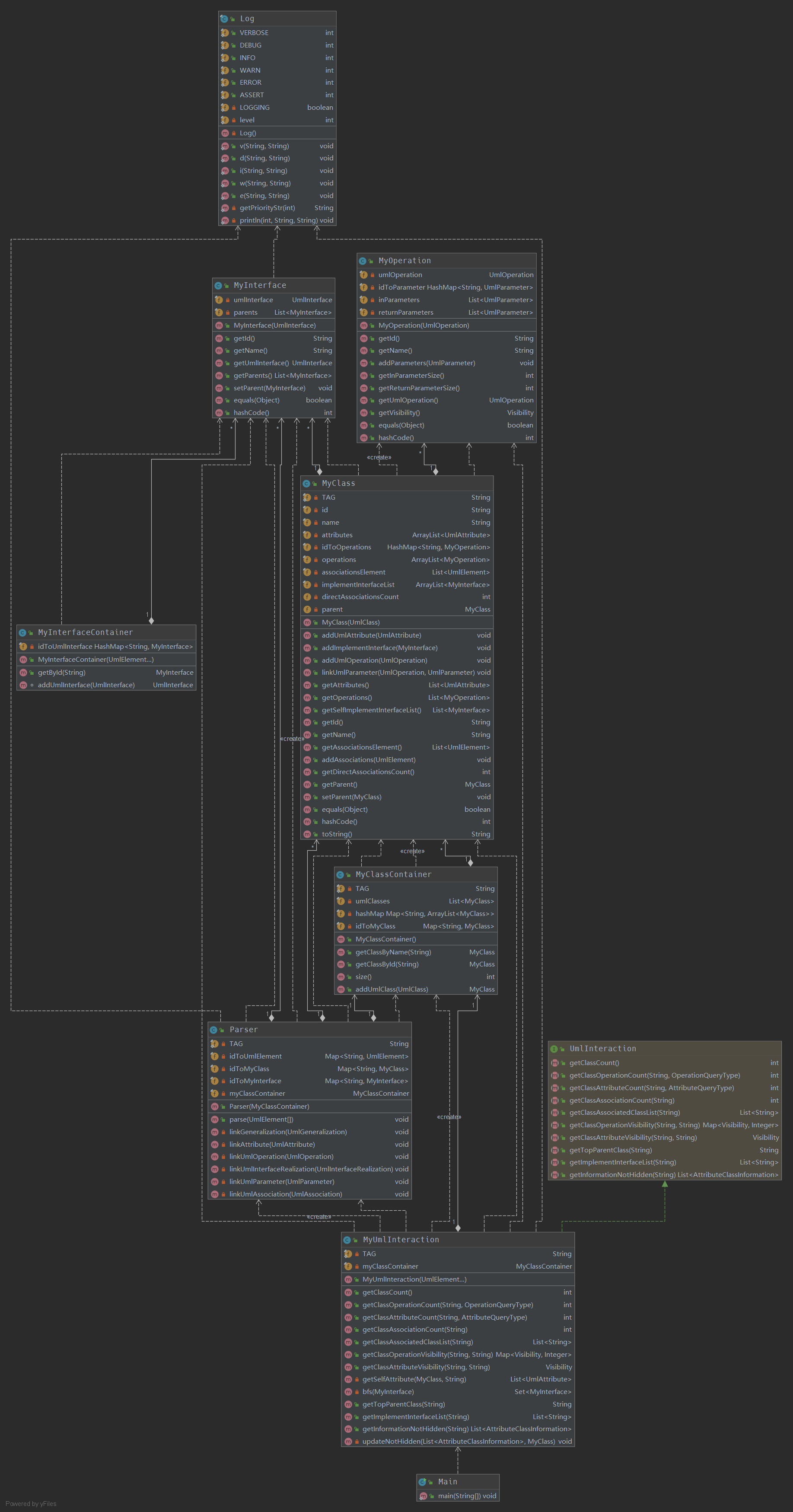
本次架构分为以下几个部分。
基础部分
官方输入接口提供的UmlClass等只提供了元素的id,name,类型等信息,不能方便地查询对应的信息。
因此,分别封装了UmlClass,UmlInterface,UmlOperation.
类MyClass封装了UmlClass,存放class信息、父类、实现的接口、属性、操作、关联。
类MyInterface和以上类似。
MyOperation,存放operation和对应的参数。
容器
由于需要根据类名查询相应的类,需要容器提供根据名字查询元素的方法。
解析器
这部分的代码主要将分散的元素建立联系。
交互接口
主要实现交互接口的方法。
第2次作业
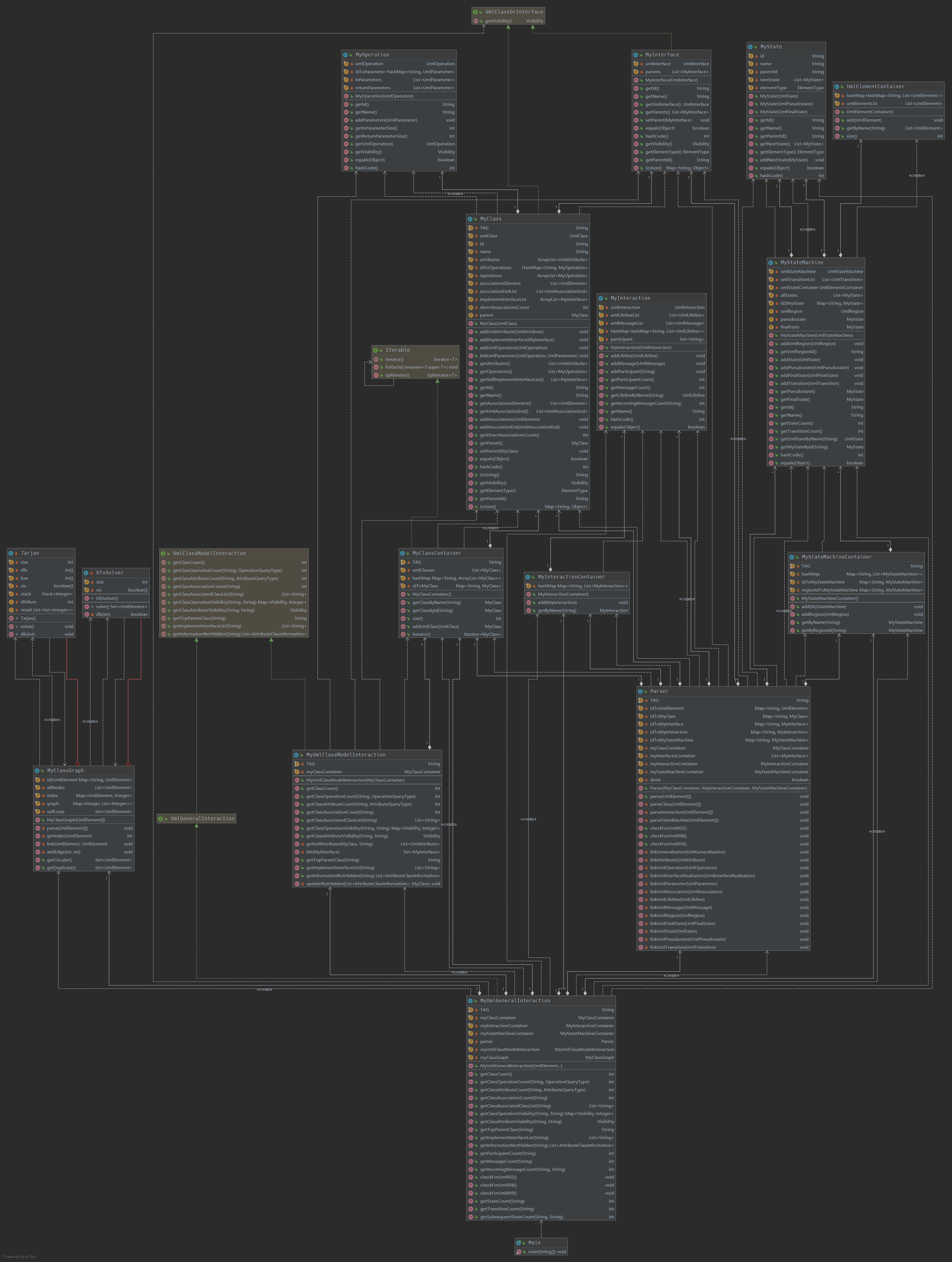
总体架构基本不变。
相比上次,增加了容器,存储顺序图、状态机。
MyInteraction ,存储顺序图信息和对应的lifeline, message等。
MyStateMachine ,存储状态图信息和对应的state, transition。
MyState 存储状态信息和后继状态。
规则检查
本次作业依次需要检查以下规则:
R001:针对下面给定的模型元素容器,不能含有重名的成员
- 针对类图中的类(UMLClass),其成员属性(UMLAttribute)和关联对端所连接的UMLAssociationEnd不能有重名
R002:不能有循环继承
- 只考虑类的继承关系、类和接口之间实现关系,以及接口之间的继承关系。所谓循环继承,就是按照继承关系形成了环。
R003:任何一个类或接口不能重复继承另外一个接口
- 该规则考虑类之间的继承关系、接口之间的继承关系,以及类对接口的实现关系,包括直接继承或间接继承。
第1条规则:查询并统计容器里的元素。
第2和第3条规则:使用图论算法。增加MyClassGraph类用于规则检查。将元素组织成图:类或接口作为节点,接口实现关系、继承关系作为有向边,建立有向图。使用tarjan算法求出循环继承,使用广度优先遍历判断是否有重复继承。
架构设计及OO方法理解的演进
架构设计
Unit 1
第1单元总体架构为解析器、因子、项、表达式。但是由于每次作业需要解析的表达式定义不同,需要重写解析器。
Unit 2
主要架构为生产者-消费者模型。
但是这一单元笔者未能设计良好的架构,导致每次作业都要推翻原来的架构,代码复杂度上升。
Unit 3
架构设计:路径MyPath、容器MyPathContainer、图MyGraph、算法和底层图、MyRailwaySystem
不足之处在于,没有将图的底层结构、建模过程、算法分离,导致单个类复杂度过高。官方的参考程序使用了工厂模式,将建模过程分离出来,值得借鉴。
Unit 4
架构设计:以上已经说明,不再重复。
面向对象方法
在实现算法的代码中,面向过程的写法仍然存在,但是应用面向对象的方法,实现代码重用、降低单个模块的复杂度。从这4个单元下来,笔者深刻体会到面向对象方法比纯粹的面向过程相比,有很大的进步,体现在封装、复用等方面。
测试理解与实践的演进
Unit 1
这一单元的测试以黑盒测试为主。数据生成器的编写用到了递归下降。
SinFactor := 'sin' '(' Factor ')' ('^' Number)?
CosFactor := 'cos' '(' Factor ')' ('^' Number)?
PowerFactor := 'x' ('^' Number)?
ConstFactor := Number
ExpressionFactor := '(' Expression ')'
Factor := PowerFactor
| SinFactor
| Cos
| ExpressionFactor
| ConstFactor
Term := Factor ('*' Factor)*
| '+' Factor ('*' Factor)*
| '-' Factor ('*' Factor)*
Expression := ('-'|'+')? Term ('-'|'+' Term)*
使用sympy比较输出的表达式是否正确。
另外,对于格式错误的输入判断,笔者测试了\f,\v等空白字符。同时,使用Python生成较长的表达式,用来测试使用复杂正则表达式来匹配整个字符串的程序。由于Java的正则表达式使用了NFA,在正则表达式过于复杂的情况下,会发生栈溢出。
Unit 2
这一部分的测试仍然是黑盒测试。但是,由于在没有发生线程竞争的情况下,很容易保证正确性,笔者没有编写输出检查器。这一单元的bug最主要是线程安全的问题,有可能出现的情况是程序死循环、死锁或提早退出。所以笔者只检查了程序的运行情况;由于线程安全问题难以重现,需要改变CPU频率等运行环境并重复测试同一组数据。事实证明这样简单的测试还是令人满意的,在互测环节发现了一些线程安全的问题。
Unit 3
这一单元是JML的使用,笔者能够找到的开源JML工具链,暂时只有Openjml能兼容JAVA 8。然而OPENJML尚不成熟,在检查复杂程序时会出现内部错误。使用jmlunitng自动生成的测试代码只检查非常普遍的边界,例如int的最大值和最小值,忽视了JML规格。
所以这一单元的本地测试笔者使用了Junit单元测试+黑盒测试。
互测环节,仍然使用黑盒测试。编写数据生成器比较简单。但是,编写检验输出是否正确的程序,相当于重写一遍作业,无法保证正确性。因此,笔者用python编写了数据生成器,使用的测试方法是,将组内的程序放在一起,输入同一组数据,比较输出是否相同。如果出现不同或超过规定的cpu时间,那么一定有错误。
缺点是没法保证正确性;由于输入数据较为复杂,在测试数据组数较少的情况,难以全面覆盖,效率低下。
以本单元最后一次作业为例子,笔者编写了如下的bash脚本,事先将程序编译打包为jar,使用100组随机数据进行测试,耗时2-3小时:
export CLASSPATH=specs-homework-3-1.3-raw-jar-with-dependencies.jar:jfxrt.jar
for cnt in `seq 100`
do
echo testing $cnt
python3 gen.py > in.txt
for i in Assassin Berserker Caster Lancer Rider Saber
do
ulimit -S -t 35
echo $i
case $i in
Assassin)
java -cp $i.jar:$CLASSPATH worknine.Main < in.txt > $i.out;;
Berserker)
java -cp $i.jar:$CLASSPATH homework.Main < in.txt > $i.out;;
Caster)
java -cp $i.jar:$CLASSPATH subway.Main < in.txt > $i.out;;
Rider)
java -cp $i.jar:$CLASSPATH MainClass < in.txt > $i.out;;
*)
java -cp $i.jar:$CLASSPATH Main < in.txt > $i.out;;
esac
ulimit -S -t unlimited
done
for i in Assassin Berserker Caster Lancer Rider Saber
do
diff -u Caster.out $i.out > /dev/null
if [ $? -ne 0 ]
then
cp in.txt in_$cnt.txt
echo $cnt $i failed
fi
done
done
Unit 4
这一单元的本地测试笔者没有使用单元测试。由于UML结构复杂,笔者并没有写数据生成器,而是手动构造数据。
经验教训是测试的时候,不能忽视coverage,这可以避免一些低级错误。笔者在最后一次作业中,误将InteractionDuplicatedException写成InteractionNotFoundException,然而在本地测试中没有测试充分,未能发现这个bug。
总结
总的来说,这4个单元下来,测试的方法都是以黑盒测试为主,使用单元测试尽可能保证测试全面。
自己的课程收获
首先是代码能力的提升。每次作业,代码量都在500行以上,最后一次作业的代码量甚至达到了2000行,对编码能力提出了很高的要求。
最大的收获是,面向过程、面向对象、函数式编程等编程思想,对笔者来说是分析、解决问题的不同角度,而不是对立关系。
其中,SOLID原则对设计合理的代码架构帮助很大,很大程度上增强了可拓展性、降低了debug的复杂度。
另外,从数据流的角度,笔者也使用了Java 8的stream来简化代码,替换掉复杂的循环。
给课程的改进建议
关于课程
- 关于指导书和作业要求细节,希望在公布之前就确定好细节问题,而不是等同学反馈问题后再修改作业要求
- 希望能够通过其他途径(例如电子邮件)通知学生,而不是只通过课程网站这个单一渠道。
- 希望课程组能够和其他课程(例如:操作系统、组合数学)协调,合理安排作业的时间节点,降低同学们在其他课程的压力。
- 希望实验课和理论课的时间错开,而不是上午理论课,当天下午实验课。
关于课程网站
- 希望Markdown编辑器支持表格等功能。
- UI方面建议将
所有实验和所有作业位置对调。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号