
excel 中怎么让两列姓名相同排序(转)
如图,A列B列不动,C列和D列行值不变,以A列姓名为主让C列姓名和A列相同姓名的对齐(行),D行跟着C行不变。
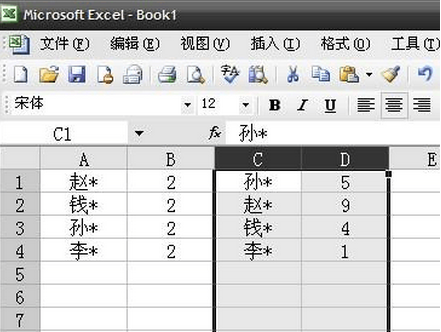
在E1输入公式=MATCH(C1,A:A,0)然后下拉,接著选中C,D,E列,以E列为标准升序排列即可
转自:https://wenku.baidu.com/view/b7f6198058fb770bf68a5559.html
pandas实现方法:


1 #! /usr/bin/env python 2 #-*- coding:utf8 -*- 3 import pandas as pd 4 from pandas import DataFrame 5 import numpy as np 6 pd.set_option('display.height',10000) 7 pd.set_option('display.max_rows',5000) 8 pd.set_option('display.max_columns',5000) 9 pd.set_option('display.width',10000) 10 df = pd.read_excel(r"F:\test.xlsx") 11 col_n = ['C','D'] 12 col_A = ['A','B'] 13 CD = pd.DataFrame(df,columns = col_n) 14 AB = pd.DataFrame(df,columns = col_A) 15 # print(CD) 16 # print(AB) 17 fi =pd.merge(AB,CD,left_on='A',right_on='C',how='left') 18 print(fi) 19 20 zn=fi[fi.isnull().values==True] 21 print(zn.fillna(0))
改进版
1 #! /usr/bin/env python 2 #-*- coding:utf8 -*- 3 import pandas as pd 4 from locale import * 5 from pandas import DataFrame 6 import numpy as np 7 writer = pd.ExcelWriter('output.xlsx') 8 pd.set_option('display.height',10000) 9 pd.set_option('display.max_rows',5000) 10 pd.set_option('display.max_columns',5000) 11 pd.set_option('display.width',10000) 12 df = pd.read_excel(r"F:\test.xlsx", thousands=',') 13 print(df.info()) 14 # df = pd.read_excel(r"F:\test.xlsx") 15 col_A = ['A','B'] 16 col_n = ['C','D'] 17 print(df) 18 AB = pd.DataFrame(df,columns = col_A) 19 CD = pd.DataFrame(df,columns = col_n) 20 21 fi =pd.merge(AB,CD,left_on='A',right_on='C',how='left') 22 23 # fi['E']=fi.apply(lambda x: (x['D'] - x['B'])/x['D']*100, axis=1).round(2) 24 25 # fi['E']=fi.apply(lambda x: format((x['D'] - x['B'])/x['D'],'.2%'), axis=1) 26 27 # fi['E']=(fi.D-fi.B) 28 # fi['F']=((fi.D-fi.B)/fi.D*100) 29 fi=fi.assign(E=fi.B-fi.D,F=((fi.B-fi.D)/fi.B)*100).round(2) 30 # fi=fi.assign(E=fi.B-fi.D,F=((fi.B-fi.D)/fi.B)) 31 32 def number_to_flag(number): 33 if number > 0: 34 return '↑' 35 elif number == 0: 36 return '=' 37 else: 38 return '↓' 39 40 fi =fi.sort_values(by=['F'],ascending=False) #升序 41 42 fi['G'] =fi['F'].map(number_to_flag) 43 44 fi['E'] = fi['E'].astype('str').str.replace("-","") 45 fi['F'] = fi['F'].astype('str').str.replace("-","") 46 fi['F'] = fi.F + '%' 47 fi=fi.dropna(axis=0) 48 fi=fi[ ~ fi['F'].str.contains('0.0') ] 49 fi['E'] = fi['E'].astype('float64') 50 print(fi) 51 print(fi.dtypes) 52 fi.to_excel(writer) 53 writer.save()
最终版
1 #! /usr/bin/env python 2 #-*- coding:utf8 -*- 3 import sys 4 reload(sys) 5 sys.setdefaultencoding('gbk') 6 from locale import * 7 from pandas import DataFrame 8 import pandas as pd 9 import numpy as np 10 writer = pd.ExcelWriter('output.xlsx') 11 pd.set_option('display.height',10000) 12 pd.set_option('display.max_rows',5000) 13 pd.set_option('display.max_columns',5000) 14 pd.set_option('display.width',10000) 15 df = pd.read_excel(r"F:\test.xlsx") 16 pd.options.display.float_format = '{:,}'.format 17 18 print(df.info()) 19 # df = pd.read_excel(r"F:\test.xlsx") 20 col_A = ['A','B'] 21 col_n = ['C','D'] 22 23 AB = pd.DataFrame(df,columns = col_A) 24 CD = pd.DataFrame(df,columns = col_n) 25 26 fi =pd.merge(AB,CD,left_on='A',right_on='C',how='left') 27 28 # fi['E']=fi.apply(lambda x: (x['D'] - x['B'])/x['D']*100, axis=1).round(2) 29 30 # fi['E']=fi.apply(lambda x: format((x['D'] - x['B'])/x['D'],'.2%'), axis=1) 31 32 # fi['E']=(fi.D-fi.B) 33 # fi['F']=((fi.D-fi.B)/fi.D*100) 34 fi=fi.assign(E=fi.B-fi.D,F=((fi.B-fi.D)/fi.B)*100).round(2) 35 # fi=fi.assign(E=fi.B-fi.D,F=((fi.B-fi.D)/fi.B)) 36 37 def number_to_flag(number): 38 if number > 0: 39 return '↓' 40 elif number == 0: 41 return '=' 42 else: 43 return '↑' 44 45 fi =fi.sort_values(by=['F'],ascending=False) #升序 46 47 fi['G'] =fi['F'].map(number_to_flag) 48 49 fi['E'] = fi['E'].astype('str').str.replace("-","") 50 fi['F'] = fi['F'].astype('str').str.replace("-","") 51 fi['F'] = fi.F + '%' 52 fi=fi.dropna(axis=0) 53 54 fi=fi[ ~ fi['F'].str.contains('0.0') ] 55 fi['E'] = fi['E'].astype('float64') 56 fi['B'] = fi['B'].astype('float64') 57 58 print(fi) 59 # print(fi.dtypes) 60 fi.to_excel(writer) 61 writer.save() 62 # fi.to_html('files.html',escape=False,index=False,sparsify=True,border=1,index_names=False,header=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号